Java LinkedList源码剖析
LinkedList
总体介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
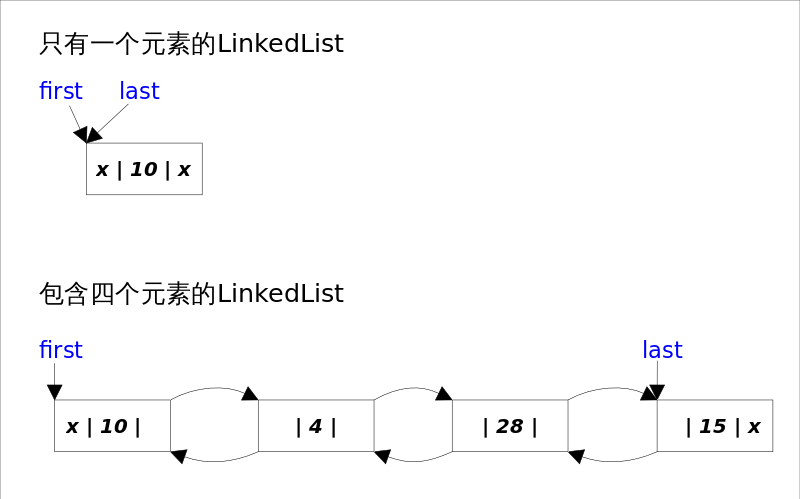
LinkedList底层通过双向链表实现,本节将着重讲解插入和删除元素时双向链表的维护过程,也即是之间解跟List接口相关的函数,而将Queue和Stack以及Deque相关的知识放在下一节讲。双向链表的每个节点用内部类Node表示。LinkedList通过first和last引用分别指向链表的第一个和最后一个元素。注意这里没有所谓的哑元,当链表为空的时候first和last都指向null。
//Node内部类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
方法剖析
add()
add()方法有两个版本,一个是add(E e),该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;另一个是add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
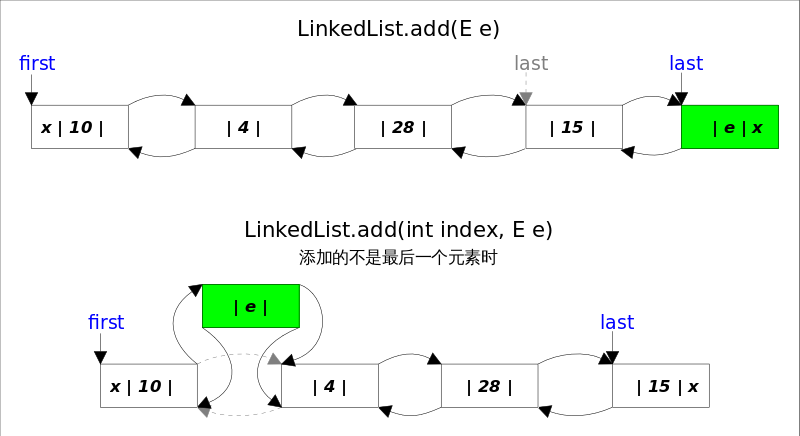
结合上图,可以看出add(E e)的逻辑非常简单。
//add(E e)
public boolean add(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;//原来链表为空,这是插入的第一个元素
else
l.next = newNode;
size++;
return true;
}
add(int index, E element)的逻辑稍显复杂,可以分成两部,1.先根据index找到要插入的位置;2.修改引用,完成插入操作。
//add(int index, E element)
public void add(int index, E element) {
checkPositionIndex(index);//index >= 0 && index <= size;
if (index == size)//插入位置是末尾,包括列表为空的情况
add(element);
else{
Node<E> succ = node(index);//1.先根据index找到要插入的位置
//2.修改引用,完成插入操作。
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)//插入位置为0
first = newNode;
else
pred.next = newNode;
size++;
}
}
上面代码中的node(int index)函数有一点小小的trick,因为链表双向的,可以从开始往后找,也可以从结尾往前找,具体朝那个方向找取决于条件index < (size >> 1),也即是index是靠近前端还是后端。
remove()
remove()方法也有两个版本,一个是删除跟指定元素相等的第一个元素remove(Object o),另一个是删除指定下标处的元素remove(int index)。
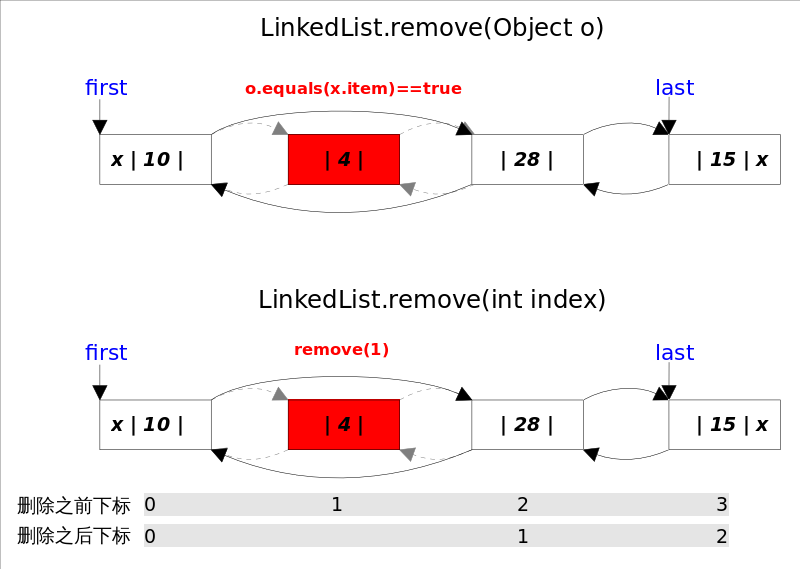
两个删除操作都要1.先找到要删除元素的引用,2.修改相关引用,完成删除操作。在寻找被删元素引用的时候remove(Object o)调用的是元素的equals方法,而remove(int index)使用的是下标计数,两种方式都是线性时间复杂度。在步骤2中,两个revome()方法都是通过unlink(Node<E> x)方法完成的。这里需要考虑删除元素是第一个或者最后一个时的边界情况。
//unlink(Node<E> x),删除一个Node
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {//删除的是第一个元素
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {//删除的是最后一个元素
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;//let GC work
size--;
return element;
}
get()
get(int index)得到指定下标处元素的引用,通过调用上文中提到的node(int index)方法实现。
public E get(int index) {
checkElementIndex(index);//index >= 0 && index < size;
return node(index).item;
}
set()
set(int index, E element)方法将指定下标处的元素修改成指定值,也是先通过node(int index)找到对应下表元素的引用,然后修改Node中item的值。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;//替换新值
return oldVal;
}
Java LinkedList源码剖析的更多相关文章
- Java LinkedList 源码剖析
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack).这样看来,LinkedList简直就 ...
- Java ArrayList源码剖析
转自: Java ArrayList源码剖析 总体介绍 ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现.除该类未实现同步外 ...
- 转:【Java集合源码剖析】LinkedList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35787253 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- LinkedList源码剖析
LinkedList简介 LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈.队列和双端队列来使用. LinkedList同样是非线程安全 ...
- 转:【Java集合源码剖析】LinkedHashmap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/37867985 前言:有网友建议分析下LinkedHashMap的源码,于是花了一晚上时 ...
- 转:【Java集合源码剖析】ArrayList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35568011 本篇博文参加了CSDN博文大赛,如果您觉得这篇博文不错,希望您能帮我投一 ...
- Java集合源码剖析——ArrayList源码剖析
ArrayList简介 ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存. ArrayList不是线程安全的,只能用在单线程环境下,多线 ...
- 转:【Java集合源码剖析】TreeMap源码剖析
前言 本文不打算延续前几篇的风格(对所有的源码加入注释),因为要理解透TreeMap的所有源码,对博主来说,确实需要耗费大量的时间和经历,目前看来不大可能有这么多时间的投入,故这里意在通过于阅读源码对 ...
- 转:【Java集合源码剖析】Hashtable源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元 ...
随机推荐
- Android中 Application的使用
Application全局唯一,如果需要放置全局的变量,需要用到Application,类似于OC中的单例类,获者OC中的AppDelegate 第一步:创建一个AppContext继承Applica ...
- Lodash 中文文档 (v4.16.1) 手机版
http://lodash.swift.ren/ 手机扫描二维码直接进入
- [py]函数中yield多次返回,延迟计算特性-杨辉三角
搞清什么是杨辉三角 每行是一个数组, 第一行: [1] 第二行: [1, 1] 第三行: [1, 2, 2, 1] ... 画的好看点就是,不过没啥卵用 1 / \ 1 1 / \ / \ 1 2 1 ...
- os模块的使用
python编程时,经常和文件.目录打交道,这是就离不了os模块.os模块包含普遍的操作系统功能,与具体的平台无关.以下列举常用的命令 1. os.name()——判断现在正在实用的平台,Window ...
- 文件操作(CRT、C++、WIN API、MFC)
一.使用CRT函数文件操作 二.使用标准C++库 std::fstream std::string 1)std::string对象内部存储了一个C的字符串,以'\0'结尾的. 2)std::strin ...
- C/S模型之TCP群聊
说明:利用TCP协议和多线程实现群聊功能.一个服务器,多个客户端(同一个程序多次启动).客户端向服务端发送数据,由服务端进行转发到其他客户端. /服务端 // WSASever.cpp : 定义控制台 ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON SmallestRectangle1
zw版[转发·台湾nvp系列Delphi例程]HALCON SmallestRectangle1 procedure TForm1.Button1Click(Sender: TObject);var ...
- IO(字节流)
1. 字节流类以InputStream 和 OutputStream为顶层类,他们都是抽象类(abstract) 2. 最重要的两种方法是read()和write(),它们分别对数据的字节进行读写.两 ...
- [转载] My97DatePicker日历实现开始日期小于结束日期验证
<tr align='center'> <td align="right">开始日期: </td> <td align="lef ...
- Linux Touch命令的8种使用技巧
Linux touch命令不仅可以用于在Linux上创建空文件. 您可以使用它来更改现有文件的时间戳,包括其访问权限和修改时间. 本文介绍了8种可以通过Linux终端使用touch命令的方案. 我们在 ...