(Review cs231n) CNN in Practice
Make the most of your data
Data augmentation

加载图像后,对图像做一些变化,这些变换不改变图像的标签。
通过各种变换人为的增大数据集,可以避免过拟合提高模型的性能,最简单的数据增强就是横向翻转。
1. horizontal flips

2. random crops and scales
对图像进行随机的尺度和位置上选择图像截图;缩放到CNN需要的图像大小最为新的数据集。

使用随机裁剪和缩放来训练模型的时候,用整幅图像来测试算法并不合理,因此在测试阶段,要准备一些
固定的截图,并用这些数据来测试算法,非常常见的作法是选取图像的10个截图(左上角、右上角、下面两个角和中间部分的截图,并把这五个图进行翻转)。
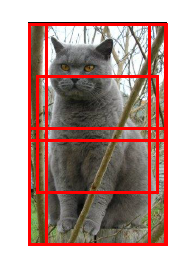
Resnet在测试阶段进行多尺度的变换
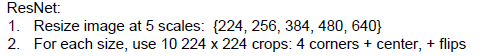
3.color jitter
一种简单的方法就是改变对比度

复杂的方法就是:对训练集所有像素做主成分分析(PCA),每个像素是一个长度为3的向量(RGB),当我们遍历所有像素后,得到主要颜色有哪些,然后PCA给出颜色空间中3个主要的颜色方向,表明数据集中颜色在哪个方向上变换最为剧烈,做数据增强,根据这些颜色的主成分来决定新产生的颜色。
4.add extra noise
增加随机噪声扰乱网络,包括BN、Minibatch,dropout弱化了噪声的影响,在BN中保留了均值。
在前向传播时随机增加噪声,在测试的时候弱化噪声影响。
Transfer learning
对于数据量较小,只能把手头的网络当作一个特征提取器,imagenet最后一层是softmax,用一个满足自己需求的线性分类器来代替这个softmax, 其他层不变,只训练这个顶层,类似于只训练一个线性分类器。
类似于:你只要把训练集产生的所有特征存在硬盘上。
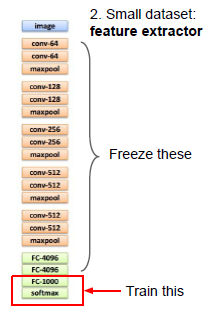
数据量较多的话:可以训练更复杂的网络,在最后几层去训练,得到feature map,最后的几层重新初始化,前面的freeze部分不变初始化。

微调finetuning的建议:
第一种是学习率为0的固定层。
第二种是从头开始初始化的层,一般学习率高一些,1/10吧。
第三种是预训练网络中的中间层,要在优化和finetuning中学习,这些中间层的学习率很小,1/100.
微调的muti-stages 建议:
第一步是把网络固定,只训练最后几层,当最后几层快要收敛后,再对这些(包括要训练的中间层进行fineturing)。
由于刚刚初始化,所以梯度会很大,可以先开始固定中间层,等着最后层收敛;或者两个阶段使用不同的学习率。
微调这种迁移学习,当原来网络是类似类型的数据训练出来的时候,微调效果高。
迁移学习的建议

对于MRI数据集,高阶特征可能是针对某种图像的分类,低阶特征是边缘一类的特征,这些低阶特征很容易迁移到非图像数据上面去,
All about convolutions
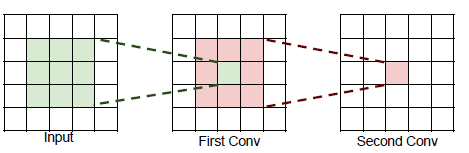
堆叠两个3*3的卷积,得到一个神经元等于一个5*5的卷积;
堆叠三个3*3的卷积,得到一个神经元等于一个7*7的卷积;
一个7*7的卷积和堆叠三个3*3的卷积在参数规模上的区别:

3*3的三个卷积更好。

3*3的三个卷积比大卷积更少的计算。

比较神奇的结构,1*1的卷积减小了深度上的体积,在空间上有相同的尺寸,要做一个3*3的降维卷积
再做一个1*1的卷积回到原来的深度。
作用:
1*1的卷积减小深度上的维度叫做“bottleneck”,就像将一个多层的全连接层遍历每个数据通道

使用这种结构,可以获得更小的参数规模,参数的个数和计算量直接相关,多层瓶颈结构计算起来快得多,并且有更好的非线性。
卷积的计算
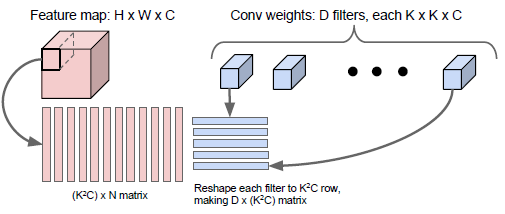
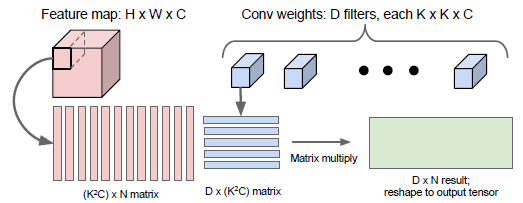
How to arrange them
How to compute them fast
Implementation details
(Review cs231n) CNN in Practice的更多相关文章
- (Review cs231n) Object Detection
目标:我们有几个类别,然后我们要在这张图中找到这些类的所有实例 解决思路:是否可以按照回归的思路进行求解呢? 但是受限制于确定的种类输出问题. 方法:分类和回归是解决问题的两个套路,我们现在对于目标的 ...
- (Review cs231n) ConvNet
概念 神经网络的深度和数据据体的深度(图像的通道数channels)要主要区分. 输入 1.得到一些数据,作为网络的输入. 2.在CNN中有filter,the size of filter is s ...
- (Review cs231n) BN and Activation Function
CNN网络的迁移学习(transfer learning) 1.在ImageNet上进行网络的预训练 2.将最上方的层,即分类器移除,然后将整个神经网络看成是固定特征提取器来训练,将这个特征提取器置于 ...
- (Review cs231n) Spatial Localization and Detection(classification and localization)
重在图像的定位和检测的内容. 一张图片中只有一种给定类别标签的对象,定位则是图像中有对象框:再这些类中,每一个训练目标都有一个类和许多的图像内部对应类的位置选框. 猜想的仅是类标签,不如说它们是位置 ...
- (Review cs231n) Training of Neural Network2
FFDNet---matlab 调用并批处理 format compact; global sigmas; % input noise level or input noise level map a ...
- (Review cs231n) Optimized Methods
Mini-batch SGD的步骤: 1.Sample a batch of data 2.Forward prop it through the graph,get loss 3.backprop ...
- (Review cs231n) The Gradient Calculation of Neural Network
前言:牵扯到较多的数学问题 原始的评分函数: 两层神经网络,经过一个激活函数: 如图所示,中间隐藏层的个数的各数为超参数: 和SVM,一个单独的线性分类器需要处理不同朝向的汽车,但是它并不能处理不同颜 ...
- (Review cs231n) Gradient Vectorized
注意: 1.每次更新,都要进行一次完整的forward和backward,想要进行更新,需要梯度,所以你需要前馈样本,马上反向求导,得到梯度,然后根据求得的梯度进行权值微调,完成权值更新. 2.前馈得 ...
- (Review cs231n) Gradient Calculation and Backward
---恢复内容开始--- 昨日之补充web. 求解下图的梯度的流动,反向更新参数的过程,表示为 输入与损失梯度的关系,借助链式法则,当前输入与损失之间的梯度关系为局部梯度乘以后一层的梯度. ---恢复 ...
随机推荐
- Mac_IntelliJ IDEA For Mac 快捷键
Mac键盘符号和修饰键说明 ⌘ Command ⇧ Shift ⌥ Option ⌃ Control ↩︎ Return/Enter ⌫ Delete ⌦ 向前删除键(Fn+Delete) ↑ 上箭头 ...
- Yarn任务提交流程(源码分析)
关键词:yarn rm mapreduce 提交 Based on Hadoop 2.7.1 JobSubmitter addMRFrameworkToDistributedCache(Configu ...
- [LeetCode] Kth Largest Element in a Stream 数据流中的第K大的元素
Design a class to find the kth largest element in a stream. Note that it is the kth largest element ...
- Red hat查找命令所属的rpm包
当安装命令软件包时,很多时候命令名不一定就是软件包的名字 如scp命令,其命令名就和软件包名字不一样,直接安装会失败: #yum install scp .... Trying other mirro ...
- JL MTK 安防网关的 wifi 吞吐测试
基本配置: 删除桥接中的 eth3 : brctl delif br0 eth3 设置eth3的ip: ifconfig eth3 192.168.1.100 开启数据转发: ech ...
- Python 学习笔记6 变量-字典
字典是python中一个十分重要的变量,他是一个可变的容器对象.通过一组key(键)和value(值)对组成一个元素. 组成形式为{'key':'value', 'key':'value'}.整个字典 ...
- idea右键没有svn选项
然后apply,当然也可以只是某些指定的文件夹.project就是当前项目,包括所有的module.
- Python reverse()方法--list
描述 reverse()方法:用于反转列表元素的排列顺序. 语法 语法格式:list.reverse() 参数 NA 返回值 无返回值 实例 #!/usr/bin/python3 a = ['abc' ...
- Elasticsearch学习笔记(七)document小结
一.生成document id 1.自动生成document id 自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能 ...
- [转]k8s核心概念
转载自 https://blog.csdn.net/real_myth/article/details/78719244 什么是kubernetes 首先,他是一个全新的基于容器技术的分布式架构领先方 ...