C++各种优化
CSDN的博客
注\(: \ \bigoplus\)是异或的意思\((\)^\()\),\(\ll n\)为二进制左移\(n\)位,\(\gg n\)为二进制右移\(n\)位。
起因——————
中国近现代史上伟大的爱国者、伟大的革命家与改革家、伟大的民主主义者、伟大的启蒙思想家陈独秀曾经说过:
“只有两位先生才能拯救我们。”
一位叫\(T\)先生\((TLE [Time Limit Exceeded])\),另一位叫\(W\)先生\((WA[Wrong Answer])\)。
在现实中,\(WA\)可以很快改正,而\(TLE\)——


呵呵
那让我们谈谈代码中的优化
1.快速结束程序
#include<cstdlib>//所需头文件
exit(0);//退出程序,结束运行
免得退出导致超时
例如\(——\)
#include<cstdio>
void dfs5()
{
exit(0);
}
void dfs4()
{
dfs5();
}
void dfs3()
{
dfs4();
}
void dfs2()
{
dfs3();
}
void dfs1()
{
dfs2();
}
int main()
{
dfs1();
}
可以退出其他递归
2.register
\(register\)修饰符暗示编译程序相应的变量将被频繁地使用,如果可能的话,应将其保存在\(CPU\)的寄存器中,以加快其存储速度。
3.inline
\(inline\)定义的类的内联函数,函数的代码被放入符号表中,在使用时直接进行替换,(像宏一样展开),没有了调用的开销,效率也很高。
4.位运算
比加减乘除快得多
\(x\times10 \rightarrow (x\ll3)+(x\ll1)\)
\(x\neq y\)\(\rightarrow x\bigoplus y\)
\(x\neq -1 \rightarrow \sim x\)
\(x\times2 \rightarrow x\ll1\)
\(x\times2+1 \rightarrow x\ll1|1\)
\(x\div2 \rightarrow x\gg1\)
\((x+1)\%2 \rightarrow x\)^\(1\)
\(x\%2\rightarrow\)\(x\&1\)
5.少用或不用STL
这里要提到一个万恶的头文件
#include<algorithm>
其中有两个函数,叫\(max\)和\(min\)。
速度慢,是\(STL\)的天生一大劣势。
\(\max\)和\(\min\)比\(a>b?a:b\)和\(a<b?a:b\)慢好几倍
除了\(sort\)(快速排序)和\(priority\)_\(queue\)(堆排序)这种比较难不用\(STL\)的这种以外尽量少用
比如
void swap(int &x,int &y){int t=x;x=y;y=t;}
swap(a,b);
再比如
inline int mymax(int x,int y){return x>y?x:y}//等于STL的max
inline int mymin(int x,int y){return x<y?x:y}//等于STL的min
\(x>y?x:y\)意思是
如果\(x>y\)那么着整个式子表示\(x\),不然表示\(y\)。
6.快读快写
当然不能少这个啦
先给大家一个东西
准备工作
计算时间
#include<cstdio>
#include<ctime>
using namespace std;
int main()
{
clock_t start,finish;
double totaltime;
start=clock();
//....... 放代码
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
}
用于运行计算时间,精度可以自己调 (其实是抄来的)
随机数
还有随机数
#include<ctime>
#include<cstdio>
#include<algorithm>
using namespace std;
int main()
{
srand((unsigned)time(NULL));//以时间作为种子
//如果没加srand,在一次运行中就会输出一样的数
//只需写srand(time(0))
printf("%d\n",rand());
/*rand()生成随机数,上限32767,若要取a~b之间的随机数,格式为rand()%
(b-a+1)+a*/
}
超慢cin cout
乌龟都比\(cin\)和\(cout\)快,尤其是\(cin\)
除了万不得已千万别用
如习惯用了,就加上这个
ios_base::sync_with_stdio(0);
之后就不要能\(scanf\)和\(printf\)了
#include<ctime>
#include<cstdio>
#include<cstdlib>
#include<iostream>
#define R register
#define ri R int
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
int main()
{
freopen("a.out","w",stdout);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
ri x;
rep(i,1,1000000)cout<<rand()<<endl;
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为3.625000000000000000000000000000000000秒!
}
慢的抠脚
#include<ctime>
#include<cstdio>
#include<cstdlib>
#include<iostream>
#define R register
#define ri R int
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
int main()
{
freopen("a.out","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
ri x;
rep(i,1,1000000)cin>>x;
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为3.406000000000000138555833473219536245秒!
}
输出
从输出讲起
我们来尝试输出\(100\)万个数字
原始输出
#include<cstdio>
#include<ctime>
#include<algorithm>
#define R register
#define ri R int
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
int main()
{
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
rep(i,1,1000000)printf("%d\n",rand());
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为3.406000000000000138555833473219536245秒!
}
初级快写
用上快写
#include<cstdio>
#include<ctime>
#include<algorithm>
#define li inline
#define gc getchar
#define pc putchar
#define R register
#define ri R int
#define rd R double
#define rb R bool
#define rc R char
#define LL long long
#define rl R LL
#define wr(n) write(n,false),pc('\n')
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
li void write(rl ans,rb bk)
{
if(ans<0)pc('-'),ans=-ans;
if(ans==0)
{
if(!bk)pc('0');
return ;
}
write(ans/10,true);
pc(ans%10^'0');
}//这里是递归式,还有不用递归式的
int main()
{
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
rep(i,1,1000000)wr(rand());
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.623999999999999999111821580299874768秒!
}
高级快写
然而还可以更快
因为\(0\)的\(ASCII\)码为\(48,9\)为\(57\)
转化为2进制为
\(110000\)
就是
\(32*1+16*1+8*0+4*0+2*0+1*0=48\)
可以用异或来加上(或消去)48,而异或比减法快得多
\(000000(0)\bigoplus110000(48)\)得到\(110000('0')\)
\(000001(1)\bigoplus110000(48)\)得到\(110001('1')\)
\(000010(2)\bigoplus110000(48)\)得到\(110010('2')\)
\(000011(3)\bigoplus110000(48)\)得到\(110011('3')\)
\(000100(4)\bigoplus110000(48)\)得到\(110100('4')\)
\(000101(5)\bigoplus110000(48)\)得到\(110101('5')\)
\(000110(6)\bigoplus110000(48)\)得到\(110110('6')\)
\(000111(7)\bigoplus110000(48)\)得到\(110111('7')\)
\(001000(8)\bigoplus110000(48)\)得到\(111000('8')\)
\(001001(9)\bigoplus110000(48)\)得到\(111001('9')\)
#include<cstdio>
#include<ctime>
#include<algorithm>
#define li inline
#define gc getchar
#define pc putchar
#define R register
#define ri R int
#define rd R double
#define rb R bool
#define rc R char
#define LL long long
#define rl R LL
#define wr(n) write(n,false),pc('\n')
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
li void write(rl ans,rb bk)
{
if(ans<0)pc('-'),ans=-ans;
if(ans==0)
{
if(!bk)pc('0');
return ;
}
write(ans/10,true);
pc(ans%10^'0');
}
int main()
{
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
rep(i,1,1000000)wr(rand());
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.577999999999999958255614274094114080秒!
}
输入
现在来看快读
原始输入
#include<cstdio>
#include<ctime>
#include<algorithm>
#define R register
#define ri R int
#define rep(a,b,c) for(ri a=b;a<=c;++a)
int main()
{
freopen("a.in","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
int a;rep(i,1,1000000)scanf("%d",&a);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为1.655999999999999916511228548188228160秒!
}
直接用\(scanf\),输入100万个数已经超时
初级快读
利用\(getchar\)比\(scanf\)快得多的特性
加上前面提到的异或的
#include<ctime>
#include<cstdio>
#include<algorithm>
#define li inline
#define gc getchar
#define R register
#define ri R int
#define rc R char
#define LL long long
#define rep(a,b,c) for(ri a=b;a<=c;++a)
li LL read()
{
ri x=0,f=1;rc ch=gc();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=gc();}
while(ch>='0'&&ch<='9')x=x*10+(ch^48),ch=gc();
return x*f;
}
int main()
{
freopen("a.in","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
int a;rep(i,1,1000000)qr(a);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.420999999999999985345056074947933666秒!
}
中级快读
然而\(x\times10\)还可以转化为\((x\ll3)+(x\ll1)\)
#include<ctime>
#include<cstdio>
#include<algorithm>
#define li inline
#define gc getchar
#define R register
#define ri R int
#define rc R char
#define LL long long
#define rep(a,b,c) for(ri a=b;a<=c;++a)
li LL read()
{
ri x=0,f=1;rc ch=gc();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=gc();}
while(ch>='0'&&ch<='9')x=(x<<3)+(x<<1)+(ch^48),ch=gc();
return x*f;
}
int main()
{
freopen("a.in","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
int a;rep(i,1,1000000)qr(a);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.406000000000000027533531010703882203秒!
}
高级快读
\(\mid\)和\(?:\)还是比\(if\)和\(\times\)快的
#include<ctime>
#include<cstdio>
#include<algorithm>
#define li inline
#define gc getchar
#define R register
#define ri R int
#define rc R char
#define LL long long
#define rep(a,b,c) for(ri a=b;a<=c;++a)
li LL read()
{
ri x=0,f=0;rc ch=gc();
while(ch<'0'||ch>'9')f|=ch=='-',ch=gc();
while(ch>='0'&&ch<='9')x=(x<<3)+(x<<1)+(ch^48),ch=gc();
return f?-x:x;
}
int main()
{
freopen("a.in","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
int a;rep(i,1,1000000)qr(a);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.406000000000000027533531010703882203秒!
}
这就差不多了
神一般的快读快写
但还有更快的
不要以为\(getchar,putchar\)是最快的,利用\(fread,fwrite\)会更快,但风险很大,很多\(oj\)上不能用,需要\(freopen\)才能使用,不会在运行是输出,全都保存在一个文件里

里面长这样

一堆乱码
不过很快
#include<cstdio>
#include<ctime>
#include<algorithm>
#define li inline
#define gc getchar
#define R register
#define ri R int
#define rd R double
#define rb R bool
#define rc R char
#define LL long long
#define rl R LL
#define wr(n) write(n,false),pcf('\n')
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
const int chargs=1000000;//要输出多少的字符,就就把这个改为多少
li void pcf(rc c)
{
static char duf[chargs],*q1=duf;
q1==duf+chargs&&fwrite(q1=duf,1,chargs,stdout),*q1++=c;
}
li void write(rl ans,rb bk)
{
if(ans<0)pcf('-'),ans=-ans;
if(ans==0)
{
if(!bk)pcf('0');
return ;
}
write(ans/10,true);
pcf(ans%10^'0');
}
int main()
{
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
rep(i,1,1000000)wr(rand());
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.265000000000000013322676295501878485秒!
}
#include<cmath>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<ctime>
#define li inline
#define gc getchar
#define R register
#define ri R int
#define rc R char
#define LL long long
#define rl R LL
#define wr(n) write(n,false),pcf('\n')
#define rep(a,b,c) for(ri a=b;a<=c;++a)
using namespace std;
const int chargs=1000000;
li char gcf()
{
static char buf[chargs],*p1=buf,*p2=buf;
return (p1==p2&&(p2=(p1=buf)+fread(buf,1,chargs,stdin),p1==p2)?EOF:*p1++);
}
li LL read()
{
rl x=0,f=0;rc ch=gc();
while(ch<'0'||ch>'9')f|=ch=='-',ch=gc();
while(ch>='0'&&ch<='9')x=(x<<3)+(x<<1)+(ch^48),ch=gc();
return f?-x:x;
}
int main()
{
freopen("a.out","r",stdin);
srand((unsigned)time(NULL));
clock_t start,finish;
double totaltime;
start=clock();
ri x;
rep(i,1,1000000)qr(x);
finish=clock();
totaltime=(double)(finish-start)/CLOCKS_PER_SEC;
printf("此程序的运行时间为%.36lf秒!\n",totaltime);
//此程序的运行时间为0.061999999999999999555910790149937384秒!
}
这才是快读快写的真实水平
对比
输入速度
\(cin\)运行时间为\(3.406000000000000138555833473219536245\)秒
\(scanf\)运行时间为\(1.655999999999999916511228548188228160\)秒
初级快读运行时间为\(0.420999999999999985345056074947933666\)秒
中级快读运行时间为\(0.406000000000000027533531010703882203\)秒
高级快读运行时间为\(0.406000000000000027533531010703882203\)秒
神一般的快读运行时间为\(0.061999999999999999555910790149937384\)秒
输出速度
\(cout\)运行时间为\(3.625000000000000000000000000000000000\)秒
\(printf\)运行时间为\(3.406000000000000138555833473219536245\)秒
初级快写运行时间为\(0.623999999999999999111821580299874768\)秒
高级快写运行时间为\(0.577999999999999958255614274094114080\)秒
神一般的快写运行时间为\(0.265000000000000013322676295501878485\)秒
7.小技巧
非常小的优化也不能放过
\(++i\)比\(i++\)要快一些
定义数组时,大的尽量放前面
8.const
并不是所有优化都是运行时间上的优化,打代码时间减少也算优化
\(const\)为常量,从开始就要被赋值,之后不变。
定义同样大数组时,可以先用定义一个常量,然后将常量放到数组里
例如我们要定义一堆容量为\(41000\)的数组
const int N=41000;
int a[N],b[N],c[N],d[N],e[N]/*······*/;
可节省打代码的时间。
9.宏定义
比\(const\)快,可以代替冗长的东西,比如上文提到的\(getchar\)我是用宏定义将\(getchar\)定义成\(gc\)。
上面提到\(inline\)可以像宏一样展开,就是将在下面代码出现的同样的东西转化成定义的东西
格式
#define+空格+要转化的东西+空格+被转化的东西(可以中间带空格)
例如
#define LL long long
代表将出现\(LL\)的地方转化成\(long \ long\)
是全字匹配
可以这样
#define R register
#define ri R int
不会编译错误
可以里面又带权值的东西
例如上文的\(mymax\)和\(mymin\)可以写成
inline int mymax(int x,int y){return x>y?x:y}
inline int mymin(int x,int y){return x<y?x:y}
还可以写成
#define mymax(a,b) a>b?a:b
#define mymin(a,b) a<b?a:b
举个栗子
#define mymax(a,b) a>b?a:b
#define mymin(a,b) a<b?a:b
int x,y,a,b;
a=mymax(x,y);b=mymax(x,y);
等于
a=x>y?x:y;b=x<y?x:y;
再比如
#define rep(a,b,c) for(int a=b;a<=c;++a)
rep(i,1,n)
等于
for(int i=1,i<=n;++i)
比加了\(inline\)的函数快,简单的东西可以代替。
不过,也要承担很大的风险
因为是直接展开,所以可能会因为运算符的优先级而导致错误
例如
#define po(n) 1<<n //求2的n次方
printf("%d",po(4)+1);
你希望的肯定是输出\(17,\)但是它所输出的是\(32,\)因为它展开后是
printf("%d",1<<4+1);
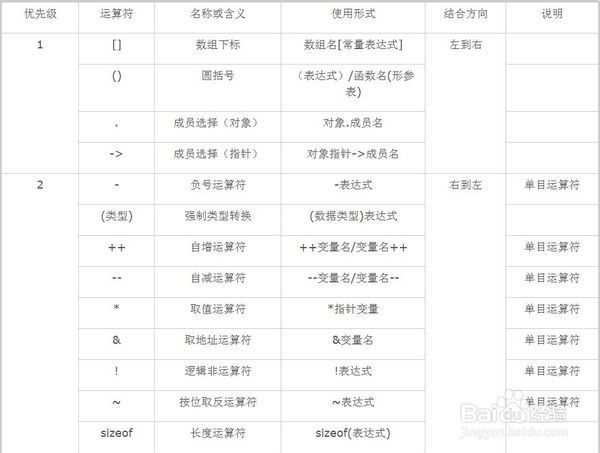
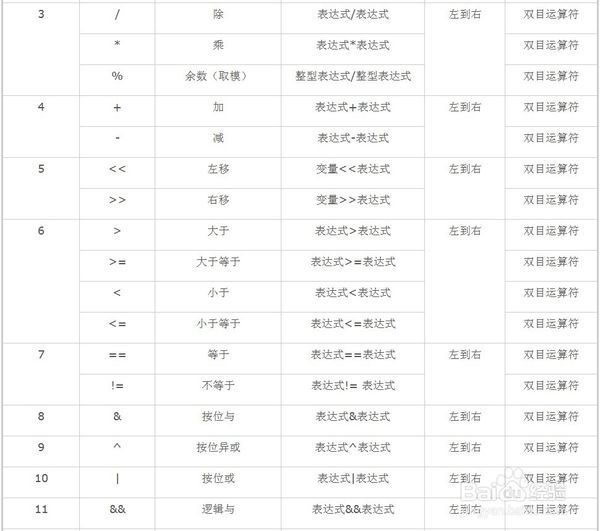
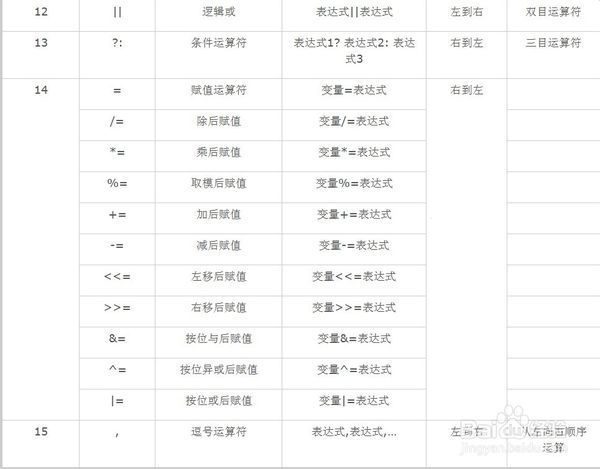
由上表得知,\(+\)的在\(\ll\)前运算
所以运算一次后就得
printf("%d",1<<5);
当然输出\(32\)啦
尽量在上面加括号
#define po(n) (1<<n)
就这样啦
C++各种优化的更多相关文章
- 关于DOM的操作以及性能优化问题-重绘重排
写在前面: 大家都知道DOM的操作很昂贵. 然后贵在什么地方呢? 一.访问DOM元素 二.修改DOM引起的重绘重排 一.访问DOM 像书上的比喻:把DOM和JavaScript(这里指ECMScri ...
- In-Memory:内存优化表的事务处理
内存优化表(Memory-Optimized Table,简称MOT)使用乐观策略(optimistic approach)实现事务的并发控制,在读取MOT时,使用多行版本化(Multi-Row ve ...
- 试试SQLSERVER2014的内存优化表
试试SQLSERVER2014的内存优化表 SQL Server 2014中的内存引擎(代号为Hekaton)将OLTP提升到了新的高度. 现在,存储引擎已整合进当前的数据库管理系统,而使用先进内存技 ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- 前端网络、JavaScript优化以及开发小技巧
一.网络优化 YSlow有23条规则,中文可以参考这里.这几十条规则最主要是在做消除或减少不必要的网络延迟,将需要传输的数据压缩至最少. 1)合并压缩CSS.JavaScript.图片,静态资源CDN ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- 【前端性能】高性能滚动 scroll 及页面渲染优化
最近在研究页面渲染及web动画的性能问题,以及拜读<CSS SECRET>(CSS揭秘)这本大作. 本文主要想谈谈页面优化之滚动优化. 主要内容包括了为何需要优化滚动事件,滚动与页面渲染的 ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- 记一次SQLServer的分页优化兼谈谈使用Row_Number()分页存在的问题
最近有项目反应,在服务器CPU使用较高的时候,我们的事件查询页面非常的慢,查询几条记录竟然要4分钟甚至更长,而且在翻第二页的时候也是要这么多的时间,这肯定是不能接受的,也是让现场用SQLServerP ...
随机推荐
- fang
如果一件事情,大家都希望它发生,并对大家都有利益. 那么它必定会发生.
- DHCP的IP地址租约、释放
转自:https://blog.csdn.net/wangdk789/article/details/27052505 当DHCP客户端获取到一个IP地址后,并不代表可以永久使用这个地址,而是有一个使 ...
- axure原型设计
在上一个学期的学习中,我们已经初步学习了axure的使用方法,它可以为负责定义需求设计,功能和界面的人员能快速设计出所需产品. 引入:在我们想为软件设计原型的时候,纸质原型很难表达交互的界面,与此同时 ...
- python多态和规范
python规范(接口类) 接口类可以规范代码,但接口类本身是不实现的 class Payment: def pay(self,money): raise Notlmplemented class W ...
- Xcode9,cocoaPod执行pod install时报错,一行命令即可解决。
- analysed of J-SON/XML processing model Extend to java design model (J-SON/XML处理模型分析 扩展到Java设计模型 )
一.JSON和XML 1.JSON JSON(JavaScript Object Notation)一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性.可在不同平台之间进行数据交换.JSON ...
- 用redis构建分布式锁
单实例的实现 从2.6.12版本开始,redis为SET命令增加了一系列选项: EX seconds – 设置键key的过期时间,单位时秒 PX milliseconds – 设置键key的过期时间, ...
- jQuery的offset、position、scroll,元素尺寸、对象过滤、查找、文档处理
jQuery_offset和position var offset = $('.xxx').offset() console.log(offset.left.,offset.top)xxx相对于页面左 ...
- Date日期类型的绑定
自定义类型的绑定 springmvc没有提供默认的对日期类型的绑定,需要自定义日期类型的绑定 第一张图是po类中日期属性,第二张图是页面中日期属性的内容,第三张图片是访问出现400错误 因为日期的格式 ...
- Cent OS 7 安装海峰、极点五笔输入法
作为五笔输入法的玩家,输入不使用五笔比较难受:最近安装了 Cent OS 7 (带 GNOME. KDE桌面)系统,默认安装的是拼音输入法,这那受得了,赶紧上车找五笔输入法. 在此之前我查阅了百度得到 ...