jmeter的几种参数化方式
在用到jmeter工具时,无论做接口测试还是性能测试,参数化都是一个必须掌握且非常有用的知识点。参数化的使用场景,例如:
1)多个请求都是同一个ip地址,若服务器地址更换了,则脚本需要更改每个请求的ip
2)注册账号,不允许账号重复;想批量注册用户时
3)模拟多个用户登录,需要用到不同用户信息登录时
4)上一个请求的输出结果用于下一个请求的参数传入,例如登录获取到的token信息,用于提交账单请求的参数调用
在jmeter中,通过${变量名}来获取参数值。
1、用户定义的变量
1)线程组右键添加-->配置元件-->用户定义的变量,出现如下设置页面后
输入名称、值;注意:名称可以自定义设置

2)然后将设置后的变量名称,在注册、登录、充值请求中进行参数化引用${ip}、${phone}
注意:引用的参数名跟用户定义变量设置的名称必须保持一致
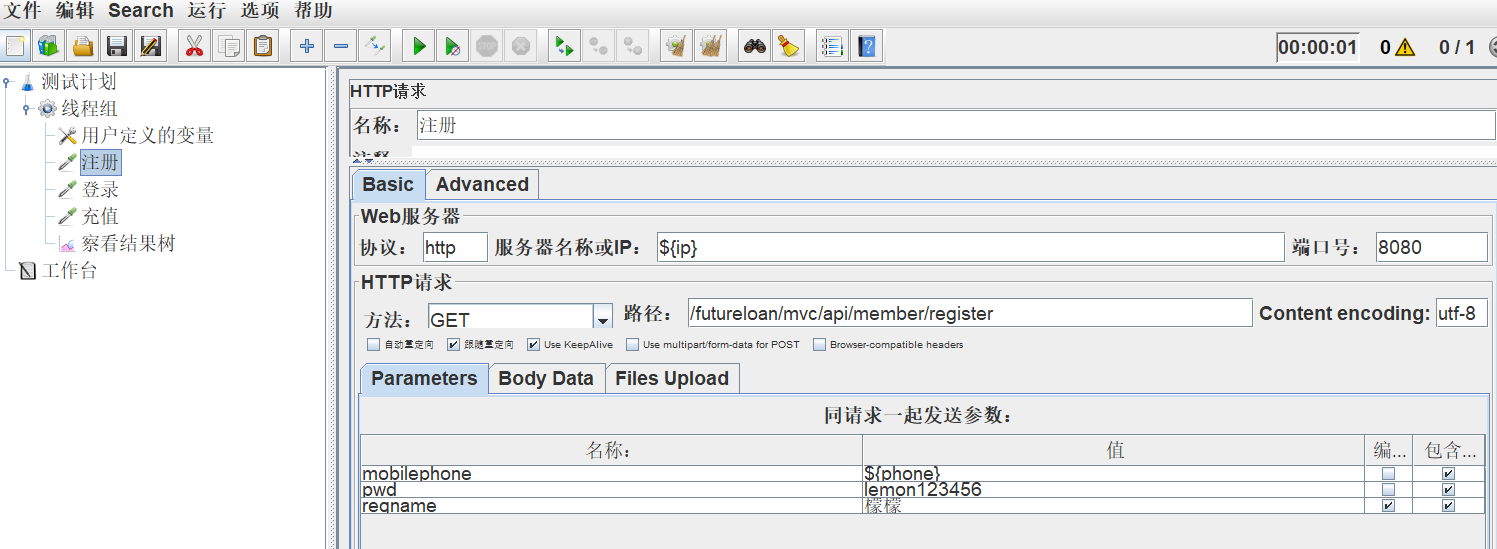
3)点击运行,查看结果树,显示成功
2、函数助手获取参数值
1)选择菜单栏 选项-->函数助手对话框,弹出函数助手框,功能下面有多个函数可供选择,我们主要看下__RandomString,其他可以自行了解下哟
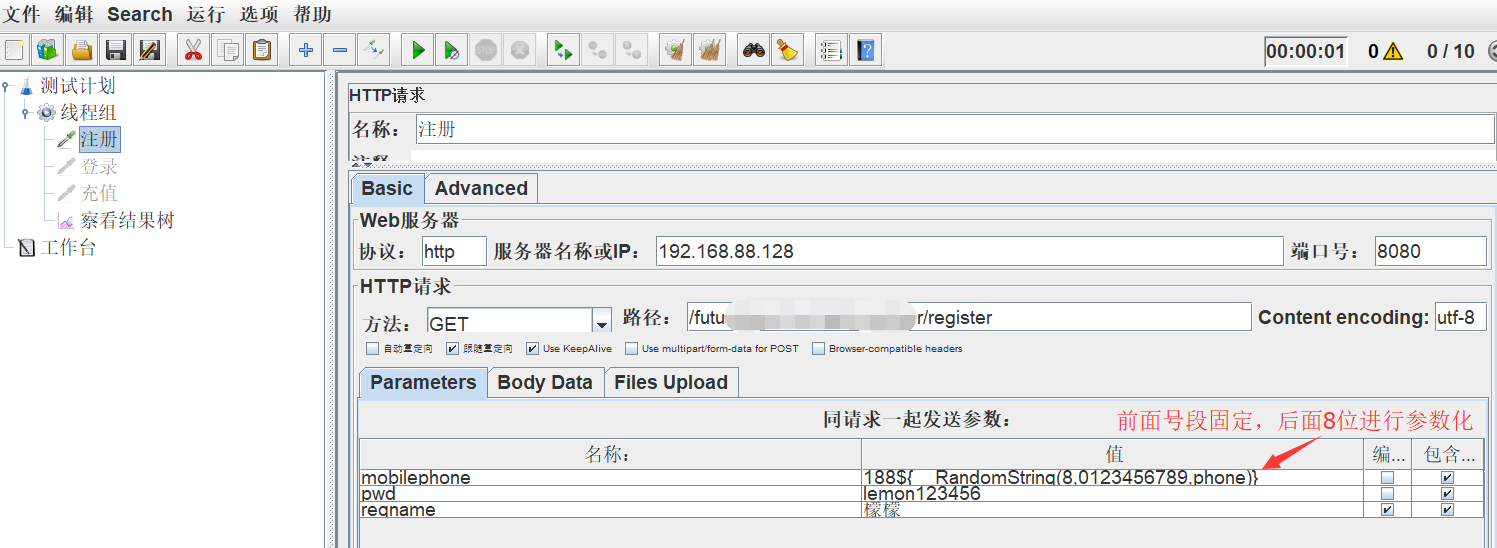
2)要进行多个账号注册(比如10个用户),注册信息要求手机号mobilephone不能重复;所以可以这么来思考,手机号前3位号段固定,那就对手机号后8位进行随机,页面设置如下:
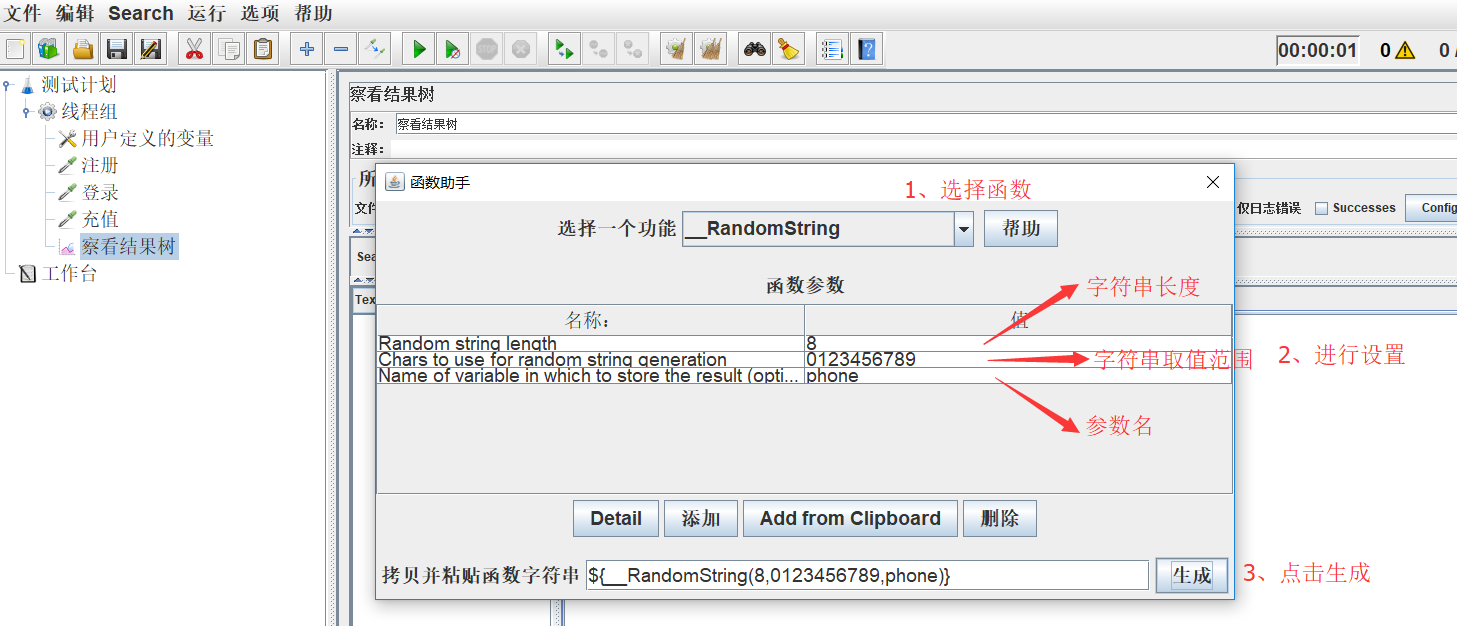
3)拷贝生成的函数字符串,粘贴进行参数引用
4)设置线程组线程数为10,模拟10个虚拟用户的注册
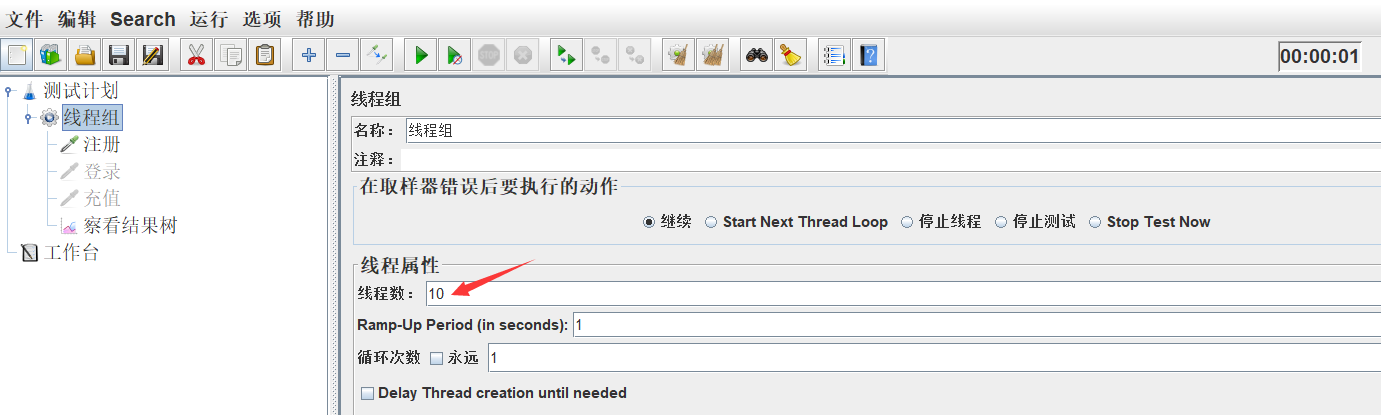
5)点击运行,查看结果树,显示成功
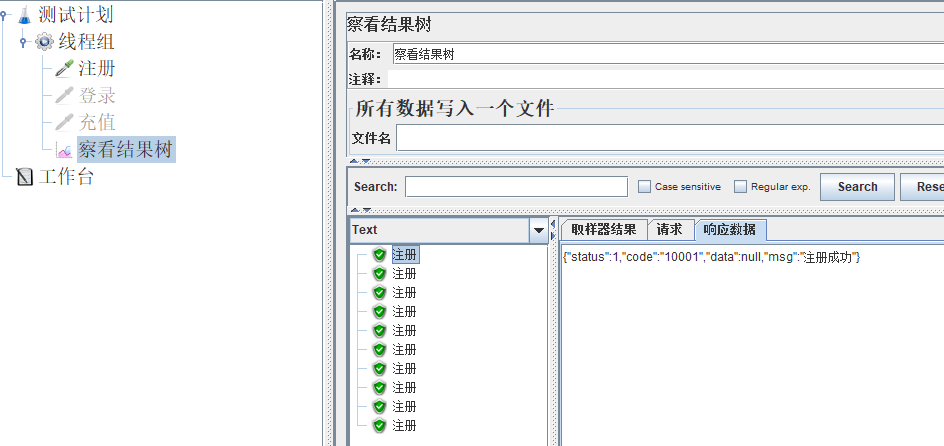
3、CSV Data Set Config获取参数值
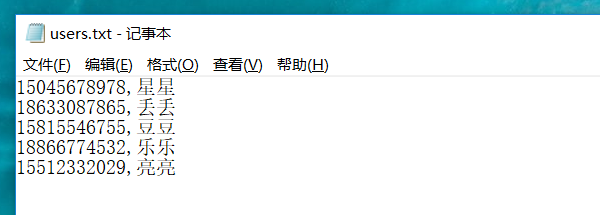
1)若需要注册的手机号不能随机,必须是用户真实提供的手机号进行注册的话,就采用以下这种方式,提前收集用户真实手机号及昵称,存放在本地txt或者CSV文件(CSV文件默认逗号隔开)
2)线程组右键添加-->配置元件-->CSV Data Set Config

- Filename:需要传入文件的完整路径。我的文件位于D盘目录下,文件名为users.txt。
- File encoding:参数文件的编码格式。可以不填。
- Variable Names:对应参数文件中每列的变量名,也是你要引用到请求中的参数变量名。这里第一列是手机号、第二列是昵称。变量名可以自定义。
- igonre first line(only used if Variable Names is not empty):当 CSV 文件中首行设置了变量名时,该项设为 true,此时每次请求读取文件时会自动忽略首行,直接读取第二行的数据。若首行未设置,则选择False
- Delimiter:文件中的分隔符,默认英文的逗号分隔。所以注意txt文档中每行多个参数用英文逗号分隔。
- Recycle on EOF: 设置为True后,允许重头循环取值;为False,当读取文件到结尾时,停止读取文件
- Stop Thread EOF: 当Recycle on EOF为false并且Stop Thread EOF 为true,则读完csv文件中的记录后,停止运行,线程数及执行次数无效。
- Sharing Mode:共享模式。All threads:所有线程,所有线程循环取值,线程1取第一行,线程2取下一行;Current thread group:当前线程组,各个线程组分别循环取值;Current thread:当前线程,该测试计划内的所有线程都取第一行。
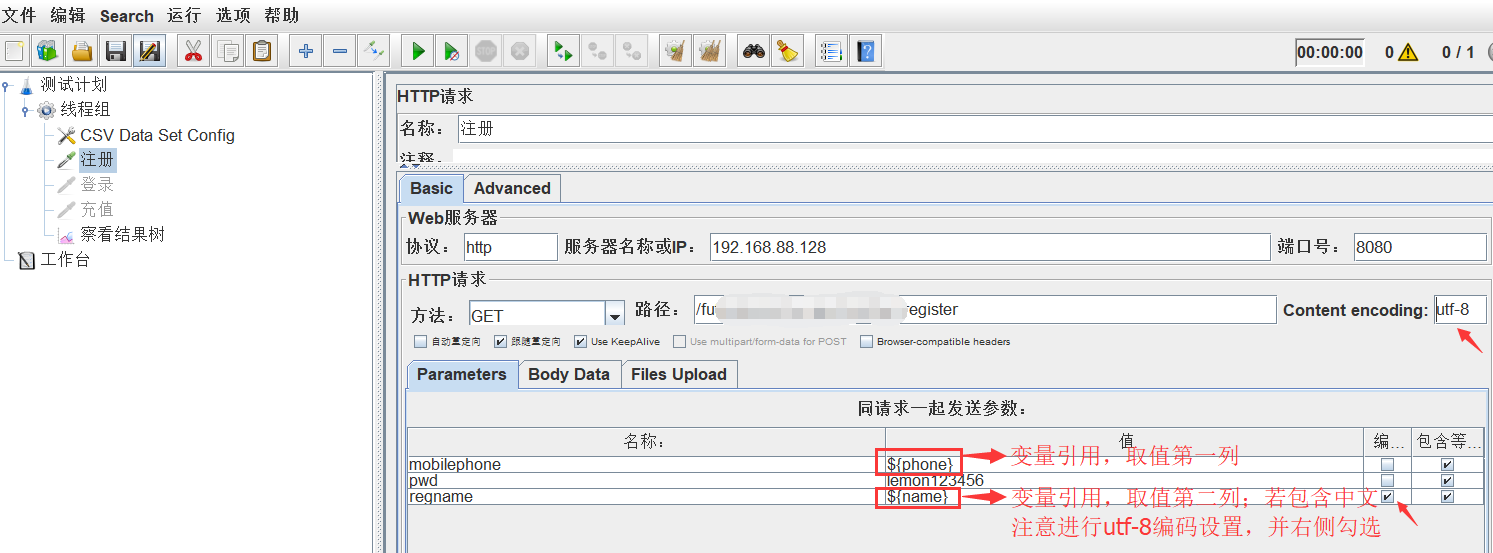
3)使用CSV Data Set Config中定义好
a、直接参数化引用
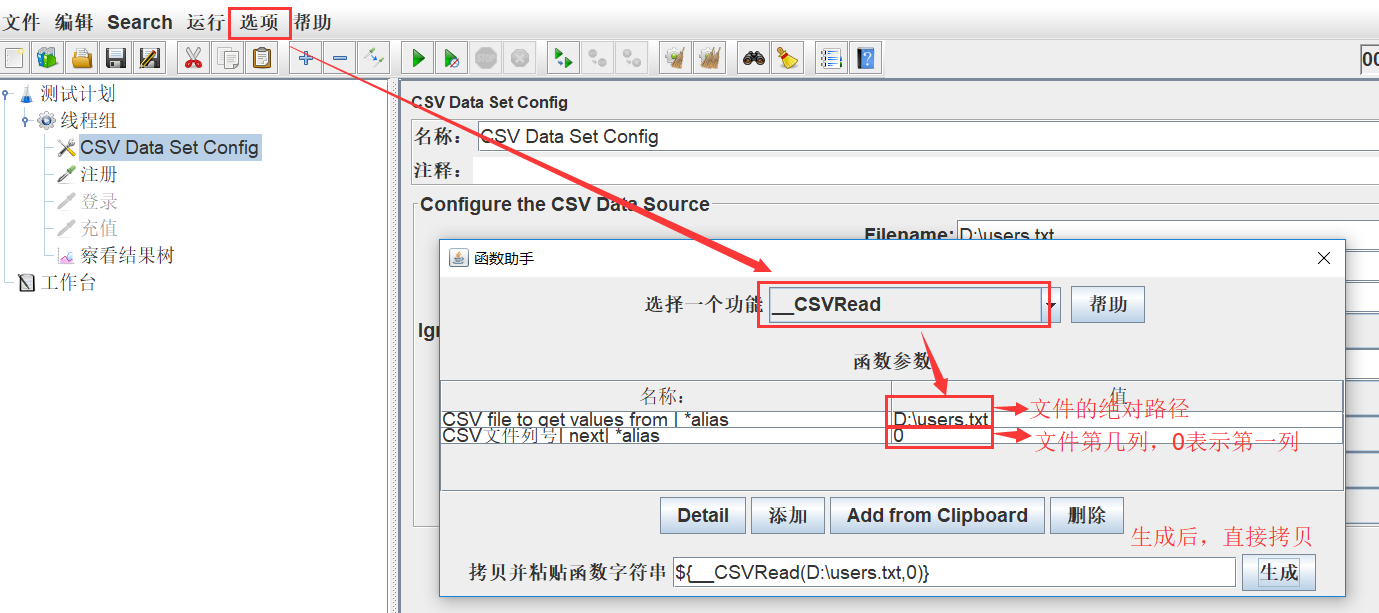
b、通过函数助手进行参数化引用
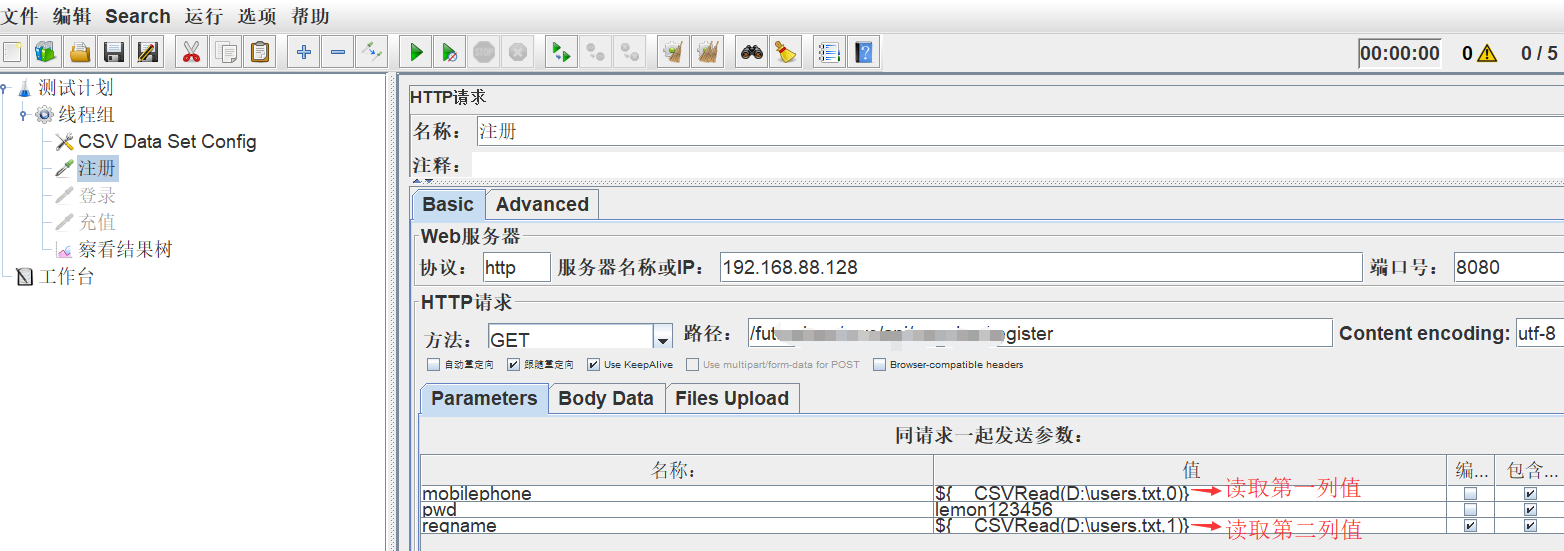
4)设置线程组中线程数为5,执行后,输出如下结果:成功

从数据库读取数据,关联的时候也会用到参数化方式,后续再抽时间整理~~
~~对该篇文章有任何想说的欢迎留言,也欢迎加右上角群号一起讨论~~
jmeter的几种参数化方式的更多相关文章
- 【Jmeter基础知识】Jmeter的三种参数化方式
JMeter的三种参数化方式包括: 1.用户参数 2.函数助手 3.CSV Data Set Config 一.用户参数 位置:添加-前置处理器-用户参数 操作:可添加多个变量或者参数 二.函数助手 ...
- jmeter的三种参数化方法
JMeter的三种参数化方式包括: 1.用户参数 2.函数助手 3.CSV Data Set Config 一.用户参数 位置:添加-前置处理器-用户参数 操作:可添加多个变量或者参数 二.函数助手 ...
- JMeter四种参数化方式
JMeter参数化是指把固定的数据动态化,这样更贴合实际的模拟用户请求,比如模拟多个不同账号.JMeter一共有四种参数化方式,分别是: CSV Data Set Config Function He ...
- Jmeter学习笔记(十五)——常用的4种参数化方式
一.Jmeter参数化概念 当使用JMeter进行测试时,测试数据的准备是一项重要的工作.若要求每次迭代的数据不一样时,则需进行参数化,然后从参数化的文件中来读取测试数据. 参数化是自动化测试脚本的一 ...
- JMeter常用的4种参数化方式-操作解析
目录结构 一.JMeter参数化简介 1.JMeter参数化的概念 2.JMeter参数化方式之使用场景对比 二.JMeter参数化的4种主要方式-操作演练 1.User Parameters(用户参 ...
- jmeter的几种参数化使用方法
场景:在进行jmeter的接口自动化测试脚本的编写中需要使用参数化,现将接触到的几种参数化方法整理如下: 第一种: 使用“用户自定义变量”的配置元件来进行变量定义 填入变量.值.和备注就可以在后续的接 ...
- jmeter ---json几种读取方式,ArrayList循环读取
在之前写过提取json数据格式的文章,这次对jmeter读取json数据格式进行整理. 举例一个接口的response 格式如下: { "data" : { "devic ...
- jmeter的三种参数化
以FTP请求(用户.密码)为例:(其他都相同) 1.文件参数化 使用配置元件中的CSV Data Set Config 配置CSV Data Set Config: 文件中存储ftp登录的用户名和密码 ...
- Jmeter脚本两种录制方式
Jmeter 是一个非常流行的性能测试工具,虽然与LoadRunner相比有很多不足,比如:它结果分析能力没有LoadRunner详细:很它的优点也有很多: l 开源,他是一款开源的免 ...
随机推荐
- hadoop过程中遇到的错误与解决方法
本文整理了在hadoop学习过程中遇到的各种问题. windows下开发环境搭建 大部分情况下,我们都是在windows下开发,hadoop则一般部署于linux服务器(无论是CDH还是原生hadoo ...
- 拒绝QQ空间-手把手教你美化博客
为什么要美化? 博客园的主题看起来是有一些年代感了,应该是不符合当代大学生的审美了,起码我就觉得不行,所以我们要进行一些美化,但是搞技术的人的博客不应该搞得花里胡哨,最好是简洁一些(个人想法),网上有 ...
- Exp3 免杀原理与实践 20164303 景圣
Exp3 免杀原理与实践 一.实验内容 1. 正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion,自己利用shellcode编程等免杀工具或技巧 2. 通过组合 ...
- EECS 649 Introduction to Artificial Intelligence
EECS 649 Introduction to Artificial IntelligenceExamElectronic Blackboard Submission Due: April 24, ...
- NABCD原则
1.我们的产品 <随堂小测APP> 是为了解决 <老师们> 的痛苦, 2-N.他们需要 随时组织课堂测验, 但是现有的方案并没有很好地解决这些需求,3-A.我们有独特的办法 ...
- Android5.0新特性之——控件移动动画(初级)
最近开发,UI大牛们设计了好多很炫酷吊炸天的动画,不由得重新学习了一下5.0的ObjectAnimator动画. ObjectAnimator动画的原理,通过反射控件的setXXX方法,改变控件的实际 ...
- Python3 tkinter基础 Scale orient 横竖 resolution单步步长 length 长度 tickinterval 指示刻度
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- 【配置】MongoDB配置文件详细配置
# 数据文件位置 dbpath = /opt/module/mongoData # 日志文件位置 logpath = /opt/module/mongoLog/mongodb.log # 以追加方式写 ...
- 微信小程序http连接访问解决方案
HTTP + 加密 + 认证 + 完整性保护 = HTTPS,小程序考虑到信息安全的问题,选用了更为稳定安全的https 来进行信息传递. HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全 ...
- 前后端分离之【接口文档管理及数据模拟工具docdoc与dochelper】
前后端分离的常见开发方式是: 后端:接收http请求->根据请求url及params处理对应业务逻辑->将处理结果序列化为json返回 前端:发起http请求并传递相关参数->获取返 ...