分类问题的几个评价指标(Precision、Recall、F1-Score、Micro-F1、Macro-F1
轉自 https://blog.csdn.net/sinat_28576553/article/details/80258619
四个基本概念
TP、True Positive 真阳性:预测为正,实际也为正
FP、False Positive 假阳性:预测为正,实际为负
FN、False Negative 假阴性:预测与负、实际为正
TN、True Negative 真阴性:预测为负、实际也为负。
【一致判真假,预测判阴阳。】
以分类问题为例:

首先看真阳性:真阳性的定义是“预测为正,实际也是正”,这个最好理解,就是指预测正确,是哪个类就被分到哪个类。对类A而言,TP的个位数为2,对类B而言,TP的个数为2,对类C而言,TP的个数为1。
然后看假阳性,假阳性的定义是“预测为正,实际为负”,就是预测为某个类,但是实际不是。对类A而言,FP个数为0,我们预测之后,把1和2分给了A,这两个都是正确的,并不存在把不是A类的值分给A的情况。类B的FP是2,"3"和"8"都不是B类,但却分给了B,所以为假阳性。类C的假阳性个数为2。
最后看一下假阴性,假阴性的定义是“预测为负,实际为正”,对类A而言,FN为2,"3"和"4"分别预测为B和C,但是实际是A,也就是预测为负,实际为正。对类B而言,FN为1,对类C而言,FN为1。
具体情况看如下表格:
| A | B | C | 總計 | |
| TP | 2 | 2 | 1 | 5 |
| FP | 0 | 2 | 1 | 3 |
| FN | 2 | 1 | 1 | 4 |
精确率和召回率

计算我们预测出来的某类样本中,有多少是被正确预测的。针对预测样本而言。

针对原先实际样本而言,有多少样本被正确的预测出来了。
套用网上的一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
精确率 = 700 / (700 +200 + 100) = 70%
召回率 = 700 / 1400 =50%
可以吧上述的例子看成分类预测问题,对于“鲤鱼来说”,TP真阳性为700,FP假阳性为300,FN假阴性为700。
Precison=TP/(TP+FP)=700(700+300)=70%
Recall=TP/(TP+FN)=700/(700+700)=50%
将上述例子,改变一下:把池子里的所有的鲤鱼、虾和鳖都一网打尽,观察这些指标的变化。
精确率 = 1400 / (1400 +300 + 300) = 70%
召回率 = 1400 / 1400 =100%
TP为1400:有1400条鲤鱼被预测出来;FP为600:有600个生物不是鲤鱼类,却被归类到鲤鱼;FN为0,鲤鱼都被归类到鲤鱼类去了,并没有归到其他类。
Precision=TP/(TP+FP)=1400/(1400+600)=70%
Recall=TP/(TP+FN)=1400/(1400)=100%
其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数。
作为预测者,我们当然是希望,Precision和Recall都保持一个较高的水准,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是正确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高,此时我们可以引出另一个评价指标—F1-Score(F-Measure)。
F1-Score
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标,用于测量不均衡数据的精度。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。(出自百度百科)
数学定义:F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。
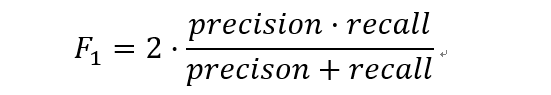
更一般的,我们定义Fβ分数为:
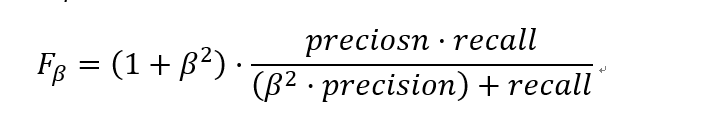
除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
Micro-F1和Macro-F1
最后看Micro-F1和Macro-F1。在第一个多标签分类任务中,可以对每个“类”,计算F1,显然我们需要把所有类的F1合并起来考虑。
这里有两种合并方式:
第一种计算出所有类别总的Precision和Recall,然后计算F1。
例如依照最上面的表格来计算:Precison=5/(5+3)=0.625,Recall=5/(5+4)=0.556,然后带入F1的公式求出F1,这种方式被称为Micro-F1微平均。
第二种方式是计算出每一个类的Precison和Recall后计算F1,最后将F1平均。
例如上式A类:P=2/(2+0)=1.0,R=2/(2+2)=0.5,F1=(2*1*0.5)/1+0.5=0.667。同理求出B类C类的F1,最后求平均值,这种范式叫做Macro-F1宏平均。
分类问题的几个评价指标(Precision、Recall、F1-Score、Micro-F1、Macro-F1的更多相关文章
- 机器学习:评价分类结果(F1 Score)
一.基础 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣? 根据具体使用场景而定: 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票:此情况下,模型精准率越高越优. ...
- 评价指标整理:Precision, Recall, F-score, TPR, FPR, TNR, FNR, AUC, Accuracy
针对二分类的结果,对模型进行评估,通常有以下几种方法: Precision.Recall.F-score(F1-measure)TPR.FPR.TNR.FNR.AUCAccuracy 真实结果 1 ...
- 机器学习:评价分类结果(Precision - Recall 的平衡、P - R 曲线)
一.Precision - Recall 的平衡 1)基础理论 调整阈值的大小,可以调节精准率和召回率的比重: 阈值:threshold,分类边界值,score > threshold 时分类为 ...
- 通过Precision/Recall判断分类结果偏差极大时算法的性能
当我们对某些问题进行分类时,真实结果的分布会有明显偏差. 例如对是否患癌症进行分类,testing set 中可能只有0.5%的人患了癌症. 此时如果直接数误分类数的话,那么一个每次都预测人没有癌症的 ...
- 深度学习分类问题中accuracy等评价指标的理解
在处理深度学习分类问题时,会用到一些评价指标,如accuracy(准确率)等.刚开始接触时会感觉有点多有点绕,不太好理解.本文写出我的理解,同时以语音唤醒(唤醒词识别)来举例,希望能加深理解这些指标. ...
- TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area,
TP Rate ,FP Rate, Precision, Recall, F-Measure, ROC Area, https://www.zhihu.com/question/30643044 T/ ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- Precision,Recall,F1的计算
Precision又叫查准率,Recall又叫查全率.这两个指标共同衡量才能评价模型输出结果. TP: 预测为1(Positive),实际也为1(Truth-预测对了) TN: 预测为0(Negati ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
随机推荐
- NOIP2007奖学金题解——洛谷1093
题目描述 某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金.期末,每个学生都有3门课的成绩:语文.数学.英语.先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高 ...
- 认识enum
今天在看别人代码的时候发现他的使用enum的方法,我是不会用的,因此记录一下. 这个是一个语音合成,今天改为使用百度的语音,可以免费支持离线.在线. 在语音合成的使用,会使用许多的词句让其合成语音,用 ...
- PC能替代服务器吗?
PC能替代服务器吗?全方位解析二者区别_华为服务器_服务器x86服务器-中关村在线http://server.zol.com.cn/536/5366835_all.html
- bind啊你返回的函数到底是个虾米
一般apply().call()和bind()会一起比较. 他们三个都是改变this对象指向的方法. apply()和cal()方法是会立即执行,apply把参数作为数组,call方法接收一个一个的参 ...
- wav文件系列_1_wav格式解读
本文介绍 wav 文件格式,主要关注该类格式的结构. 参考: [1] 以一个wav文件为实例分析wav文件格式 ( 2017.04.11 CSDN ) [2] WAV ( Wikipedia ) [3 ...
- Linux 驱动——Button驱动3(poll机制)
button_drv.c驱动文件: #include <linux/module.h>#include <linux/kernel.h>#include <linux/f ...
- JavaScript中常用的BOM对象(属性、方法)
window对象 定义: 一个浏览器窗口实例 与窗口有关的信息(应用程序编程接口) ECMAScript规定的Global对象 方法 open(url),返回标识符 引用 即将打开窗口的.(调用该引用 ...
- Checked Exceptions
记得当年在程序员杂志上看出这次访谈,10多年过去了, 这件事儿最近被重提了, 原因是 Kotlin. 1.对Checked Exceptions特性持保留态度 (译者注:在写一段程序时,如果没有用tr ...
- React生命周期简单详细理解
前言 学习React,生命周期很重要,我们了解完生命周期的各个组件,对写高性能组件会有很大的帮助. Ract生命周期 React 生命周期分为三种状态 1. 初始化 2.更新 3.销毁 初始化 1.g ...
- 对C语言指针的理解
一个小程序引发对于C语言指针的思考: #include <bits/stdc++.h> using namespace std; void my_swap (int* a,int* b) ...