【scarpy】笔记三:实战一
一、前提
我们开始爬虫前,基本按照以下步骤来做:
1.爬虫步骤:新建项目,明确爬虫目标,制作爬虫,存储爬虫内容

二、实战(已豆瓣为例子)
2.1 创建项目
1.打开pycharm -> 点开terminal (或者命令行都可以)输入
scrapy startproject douban
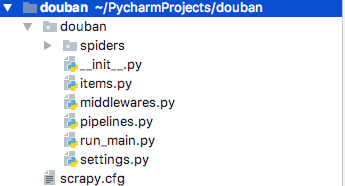
2.导入 douban scrapy项目,项目结构如下
--spiders 爬虫主文件,爬虫文件在这个里面编写
--items 数据结构文件,封装提取的文件字段,保存爬取到的数据的容器
--settings 项目设置文件
--pipelines 项目中的pipelines文件
2.2 分析网站
->需求:
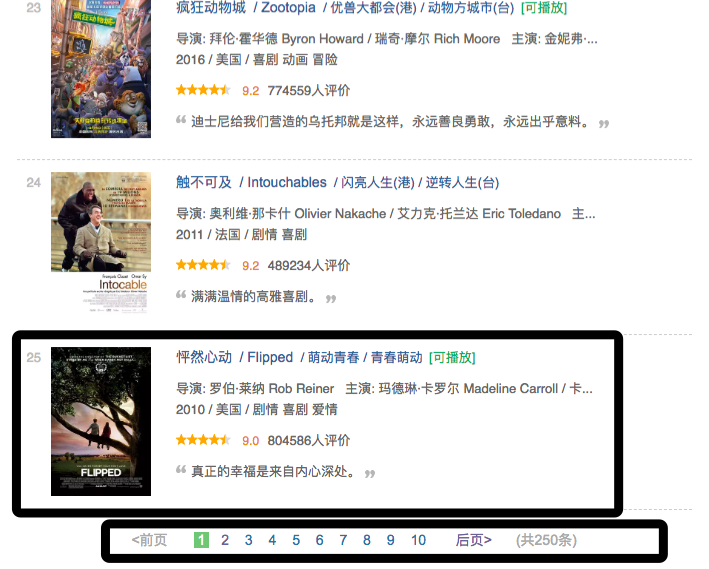
1.目标站点:https://movie.douban.com/top250
2.获取第一页 所有电影对应的编号,电影名称,星级,评论,介绍
3.获取所有页数的 电影信息
2.3 步骤
1.编辑items.py
数据结构文件,简单的理解成,爬取的数据都存在这里面,要单独定义个字段以字典的形式去存储
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#序号
serial_number = scrapy.Field()
#电影名称
movie_name = scrapy.Field()
#电影介绍
movie_introduce = scrapy.Field()
#星级
movie_start = scrapy.Field()
#电影评论数
movie_evaluate = scrapy.Field()
#电影描述
movie_describe = scrapy.Field()
2.编辑settings.py,编辑 USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
3.在spiders下面新增douban_spider.py
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名
name = 'douban_spider'
#允许爬虫的域名
allowed_domains = ['movie.douban.com']
#入口url,放到调度器里->到引擎->到下载器->返回到scarpy
start_urls = ['http://movie.douban.com/top250']
print(response.text)
def parse(self, response):
print(response.text)
4.我们来运行一下,打开pycharm-terminal-输入scrapy crawl douban_spider
5.但是每次输入的话,都很麻烦,我们新建一个run_main.py,每次运行这个文件就可以了
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
6.获取单个页面信息代码
知识点:
1.用xpath解析网页
2..extract() 通过xpath获取的是selector,我们在通过extract()方法得到内容 extract_first(),获取第一个内容
3.yield 返回内容
def parse(self, response):
#单个页面的电影列表
movie_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for i_item in movie_list:
#声明item.py方法
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//span[@class='title']/text()").extract_first()
douban_item['movie_introduce'] = i_item.xpath(".//div[@class='bd']//span[@class='inq']/text()").extract_first()
douban_item['movie_start'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first()
douban_item['movie_evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() content = i_item.xpath(".//div[@class='item']//div[@class ='bd']//p/text()").extract()
yield douban_item
7.获取所有的完整的页面代码
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名
name = 'douban_spider'
#允许爬虫的域名
allowed_domains = ['movie.douban.com']
#入口url,放到调度器里->到引擎->到下载器->返回到scarpy
start_urls = ['http://movie.douban.com/top250'] def parse(self, response):
movie_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//span[@class='title']/text()").extract_first()
douban_item['movie_introduce'] = i_item.xpath(".//div[@class='bd']//span[@class='inq']/text()").extract_first()
douban_item['movie_start'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first()
douban_item['movie_evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() content = i_item.xpath(".//div[@class='item']//div[@class ='bd']//p/text()").extract()
yield douban_item
#下一页的xpath
next_link = response.xpath("//*[@id='content']//span[@class='next']//link/@href").extract()
#如果是true,执行,并且回调self.parse
if next_link:
next_link = next_link[0]
print(next_link)
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
参考文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
【scarpy】笔记三:实战一的更多相关文章
- zookeeper curator ( 实战一)
目录 zookeeper 的伪集群搭建 写在前面 1.1. zookeeper 安装&配置 1.1.1. 创建数据目录和日志目录: 1.1.2. 创建myid文件 1.1.3. 创建和修改配置 ...
- Netty聊天器(实战一):从0开始实战100w级流量应用
Java 聊天程序(百万级流量实战一):系统介绍 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之14 [博客园 总入口 ] 源码IDEA工程获取链接:Java 聊天室 实战 源码 写在前面 ...
- 【k8s实战一】Jenkins 部署应用到 Kubernetes
[k8s实战一]Jenkins 部署应用到 Kubernetes 01 本文主旨 目标是演示整个Jenkins从源码构建镜像到部署镜像到Kubernetes集群过程. 为了简化流程与容易重现文中效果, ...
- miniFTP项目实战一
项目简介: 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务 ...
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- 《CMake实践》笔记三:构建静态库(.a) 与 动态库(.so) 及 如何使用外部共享库和头文件
<CMake实践>笔记一:PROJECT/MESSAGE/ADD_EXECUTABLE <CMake实践>笔记二:INSTALL/CMAKE_INSTALL_PREFIX &l ...
- 【转】Delphi+Halcon实战一:两行代码识别QR二维码
Delphi+Halcon实战一:两行代码识别QR二维码 感谢网友:绝代双椒( QQ号应原作者要求隐藏了:xxxx6348)的支持 本文是绝代双椒的作品,因为最近在忙zw量化培训,和ziwang.co ...
- Mastering Web Application Development with AngularJS 读书笔记(三)
第一章笔记 (三) 一.Factories factory 方法是创建对象的另一种方式,与service相比更灵活,因为可以注册可任何任意对象创造功能.例如: myMod.factory('notif ...
- Python 学习笔记三
笔记三:函数 笔记二已取消置顶链接地址:http://www.cnblogs.com/dzzy/p/5289186.html 函数的作用: 給代码段命名,就像变量給数字命名一样 可以接收参数,像arg ...
- 《MFC游戏开发》笔记三 游戏贴图与透明特效的实现
本系列文章由七十一雾央编写,转载请注明出处. 313239 作者:七十一雾央 新浪微博:http://weibo.com/1689160943/profile?rightmod=1&wvr=5 ...
随机推荐
- 简单的Java ee思维导图
- 在servlet中跳转问题
跳转有重定向和转发 1重定向 2转发
- h264文件分析(纯c解析代码)
参考链接:1. 解析H264的SPS信息 https://blog.csdn.net/lizhijian21/article/details/80982403 2. h.2 ...
- LeetCode 102 二叉树的层次遍历
题目: 给定一个二叉树,返回其按层次遍历的节点值. (即逐层地,从左到右访问所有节点). 例如:给定二叉树: [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 ...
- pypyodbc 的坑
1, 你要先确认你自己的office的版本, 你要安装access dabase engine. 但是 sb 微软的驱动 32位的不让装, 64位的也不让装, 吐槽微软100次---MS个大SX. 最 ...
- shell中特殊位置参数变量
shell中特殊位置参数变量:$0.$n.$#.$*.$@ $0:获取当前执行shell脚本文件名,如果执行脚本包含路径,那么就包括脚本路径 $n:获取当前执行shell脚本的第n个参数值.n=1.. ...
- python常见的数据转化函数
python常用类型转换函数 函数格式 使用示例 描述 int(x [,base]) int("8") 可以转换的包括String类型和其他数字类型,但是会丢失精度 ...
- PCF学习知识
1. 去PCF官网注册一个免费账号,地址是: https://login.run.pivotal.io/login 2.安装PCF的命名,cf cli. 地址https://pivotal.io/pl ...
- gulp的使用(一)之gulp的基础了解
Gulp是一个工具.用于项目构建. Gulp简介: 多个开发者共同开发一个项目,每位开发者负责不同的模块,这就会造成一个完整的项目实际上是由许多的“代码版段”组成的: 使用less.sass等一些预处 ...
- python笔记——遇到一些报错
1.TypeError: data type not understood File "C:\Users\81476\PycharmProjects\untitled1\k-临近算法\kNN ...