Caffe源码阅读(1) 全连接层
Caffe源码阅读(1) 全连接层
今天看全连接层的实现。
主要看的是https://github.com/BVLC/caffe/blob/master/src/caffe/layers/inner_product_layer.cpp
主要是三个方法,setup,forward,backward
- setup 初始化网络参数,包括了w和b
- forward 前向传播的实现
- backward 后向传播的实现
setup
主体的思路,作者的注释给的很清晰。
主要是要弄清楚一些变量对应的含义
1 |
M_ 表示的样本数 |
为了打字方便,以下省略下划线,缩写为M,K,N
forward
实现的功能就是 y=wx+b
1 |
x为输入,维度 MxK |
具体到代码实现,用的是这个函数caffe_cpu_gemm,具体的函数头为
1 |
void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA, |
略长,整理它的功能其实很直观,即C←αA×B+βC
1 |
const CBLAS_TRANSPOSE TransA # A是否转置 |
从实际代码来算,全连接层的forward包括了两步:
1 |
# 这一步表示 y←wx,或者说是y←xw' |
backward
分成三步:
- 更新w
- 更新b
- 计算delta
用公式来说是下面三条: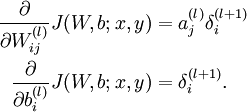
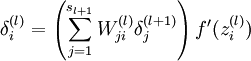
一步步来,先来第一步,更新w,对应代码是:
1 |
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1., |
对照公式,有
1 |
需要更新的w的梯度的维度是NxK |
然后是第二步,更新b,对应代码是:
1 |
caffe_cpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff, |
这里用到了caffe_cpu_gemv,简单来说跟上面的caffe_cpu_gemm类似,不过前者是计算矩阵和向量之间的乘法的(从英文命名可以分辨,v for vector, m for matrix)。函数头:
1 |
void caffe_cpu_gemv<float>(const CBLAS_TRANSPOSE TransA, const int M, |
绕回到具体的代码实现。。如何更新b?根据公式b的梯度直接就是delta
1 |
# 所以对应的代码其实就是将top_diff转置后就可以了(忽略乘上bias_multiplier这步) |
第三步是计算delta,对应公式
这里面可以忽略掉最后一项f’,因为在caffe实现中,这是由Relu layer来实现的,这里只需要实现括号里面的累加就好了,这个累加其实可以等价于矩阵乘法
1 |
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1., |
附录
又及,这里具体计算矩阵相乘用的是blas的功能,描述页面我参考的是:https://developer.apple.com/library/mac/documentation/Accelerate/Reference/BLAS_Ref/Reference/reference.html#//apple_ref/c/func/cblas_sgemm
Caffe源码阅读(1) 全连接层的更多相关文章
- caffe源码阅读
参考网址:https://www.cnblogs.com/louyihang-loves-baiyan/p/5149628.html 1.caffe代码层次熟悉blob,layer,net,solve ...
- caffe源码阅读(1)_整体框架和简介(摘录)
原文链接:https://www.zhihu.com/question/27982282 1.Caffe代码层次.回答里面有人说熟悉Blob,Layer,Net,Solver这样的几大类,我比较赞同. ...
- caffe源码阅读(1)-数据流Blob
Blob是Caffe中层之间数据流通的单位,各个layer之间的数据通过Blob传递.在看Blob源码之前,先看一下CPU和GPU内存之间的数据同步类SyncedMemory:使用GPU运算时,数据要 ...
- caffe源码阅读(3)-Datalayer
DataLayer是把数据从文件导入到网络的层,从网络定义prototxt文件可以看一下数据层定义 layer { name: "data" type: "Data&qu ...
- caffe源码阅读(2)-Layer
神经网络是由层组成的,深度神经网络就是层数多了.layer对应神经网络的层.数据以Blob的形式,在不同的layer之间流动.caffe定义的神经网络已protobuf形式定义.例如: layer { ...
- caffe源码阅读(一)convert_imageset.cpp注释
PS:本系列为本人初步学习caffe所记,由于理解尚浅,其中多有不足之处和错误之处,有待改正. 一.实现方法 首先,将文件名与它对应的标签用 std::pair 存储起来,其中first存储文件名,s ...
- caffe 源码阅读
bvlc:Berkeley Vision and Learning Center. 1. 目录结构 models(四个文件夹均有四个文件构成,deploy.prototxt, readme.md, s ...
- caffe源码 全连接层
图示全连接层 如上图所示,该全链接层输入n * 4,输出为n * 2,n为batch 该层有两个参数W和B,W为系数,B为偏置项 该层的函数为F(x) = W*x + B,则W为4 * 2的矩阵,B ...
- 源码阅读经验谈-slim,darknet,labelimg,caffe(1)
本文首先谈自己的源码阅读体验,然后给几个案例解读,选的例子都是比较简单.重在说明我琢磨的点线面源码阅读方法.我不是专业架构师,是从一个深度学习算法工程师的角度来谈的,不专业的地方请大家轻拍. 经常看别 ...
随机推荐
- [代码]--C#action和func的使用
以前我都是通过定义一个delegate来写委托的,但是最近看一些外国人写的源码都是用action和func方式来写,当时感觉对这很陌生所以看起源码也觉得陌生,所以我就花费时间来学习下这两种方式,然后发 ...
- BZOJ4448[Scoi2015]情报传递——主席树+LCA
题目描述 奈特公司是一个巨大的情报公司,它有着庞大的情报网络.情报网络中共有n名情报员.每名情报员口J-能有 若T名(可能没有)下线,除1名大头目外其余n-1名情报员有且仅有1名上线.奈特公司纪律森严 ...
- Tree 菜单 递归
转载:http://www.cnblogs.com/igoogleyou/archive/2012/12/17/treeview2.html 一,通过查询数据库的方法 ID 为主键,PID 表明数据之 ...
- Bicriterial routing 双调路径 HYSBZ - 1375(分层最短路)
Description 来越多,因此选择最佳路径是很现实的问题.城市的道路是双向的,每条道路有固定的旅行时间以及需要支付的费用.路径由连续的道路组成.总时间是各条道路旅行时间的和,总费用是各条道路所支 ...
- Sabotage UVA - 10480 (输出割边)
题意:....emm...就是一个最小割最大流,.,...用dinic跑一遍.. 然后让你输出割边,就是 u为能从起点到达的点, v为不能从起点到达的点 最后在残余路径中用dfs跑一遍 能到达的路 ...
- [luogu1962]斐波那契数列
来提供两个正确的做法: 斐波那契数列双倍项的做法(附加证明) 矩阵快速幂 一.双倍项做法 在偶然之中,在百度中翻到了有关于斐波那契数列的词条(传送门),那么我们可以发现一个这个规律$ \frac{F_ ...
- 【ARC065E】??
Description 链接 Solution 问题其实就是从一个点出发,每次可以走与其曼哈顿距离恰好为一个常数\(d\)的点 显然不可能一一走完所有的边,这样复杂度下界至少是\(O(ans)\) 我 ...
- 洛谷 P1069 细胞分裂 解题报告
P1069 细胞分裂 题目描述 \(Hanks\)博士是\(BT\) (\(Bio-Tech\),生物技术) 领域的知名专家.现在,他正在为一个细胞实验做准备工作:培养细胞样本. \(Hanks\) ...
- 教程] 《开源框架-Afinal》之FinalHttp 01一步一脚
1.FinalHttp是什么 :FinalHttp 对 HttpClient再次封装,最简洁的就是增加了许多回调的方法,对Get 和 Post 请求进行了简化.另外一点就是FinalHttp加入线程池 ...
- 常量引用 const T&
1.引用本身不是对象,只是引用对象的别名,没有内存空间产生 2.引用必须严格类型匹配 3.而常量引用 const T& 可以引用字面值常量及表达式 其实也就是右值,且常量引用的不同与T类型对象 ...