百度uid-generator源码
https://github.com/baidu/uid-generator
snowflake算法
uid-generator是基于Twitter开源的snowflake算法实现的。
snowflake将long的64位分为了3部分,时间戳、工作机器id和序列号,位数分配如下。
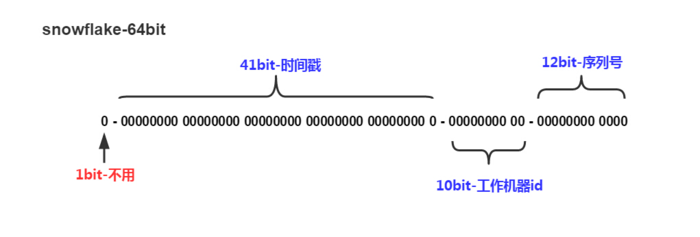
其中,时间戳部分的时间单位一般为毫秒。也就是说1台工作机器1毫秒可产生4096个id(2的12次方)。
源码实现分析
与原始的snowflake算法不同,uid-generator支持自定义时间戳、工作机器id和序列号等各部分的位数,以应用于不同场景。默认分配方式如下。

sign(1bit)
固定1bit符号标识,即生成的UID为正数。delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年(注意:1. 这里的单位是秒,而不是毫秒! 2.注意这里的用词,是“最多”可支持8.7年,为什么是“最多”,后面会讲)worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。(注意下这个地方,默认支持qps最大为8192个)
DefaultUidGenerator
DefaultUidGenerator的产生id的方法与基本上就是常见的snowflake算法实现,仅有一些不同,如以秒为为单位而不是毫秒。
DefaultUidGenerator的产生id的方法如下。

CachedUidGenerator
CachedUidGenerator支持缓存生成的id。
基本实现原理
关于CachedUidGenerator,文档上是这样介绍的。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
【采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费】

使用RingBuffer缓存生成的id。RingBuffer是个环形数组,默认大小为8192个,里面缓存着生成的id。
获取id
会从ringbuffer中拿一个id,支持并发获取
填充id
RingBuffer填充时机
程序启动时,将RingBuffer填充满,缓存着8192个id
在调用getUID()获取id时,检测到RingBuffer中的剩余id个数小于总个数的50%,将RingBuffer填充满,使其缓存8192个id
定时填充(可配置是否使用以及定时任务的周期)
【UidGenerator通过借用未来时间来解决sequence天然存在的并发限制】
因为delta seconds部分是以秒为单位的,所以1个worker 1秒内最多生成的id书为8192个(2的13次方)。
从上可知,支持的最大qps为8192,所以通过缓存id来提高吞吐量。
为什么叫借助未来时间?
因为每秒最多生成8192个id,当1秒获取id数多于8192时,RingBuffer中的id很快消耗完毕,在填充RingBuffer时,生成的id的delta seconds 部分只能使用未来的时间。
(因为使用了未来的时间来生成id,所以上面说的是,【最多】可支持约8.7年)
源码剖析
获取id
RingBuffer缓存已生成的id
(注意:这里的RingBuffer不是Disruptor框架中的RingBuffer,但是借助了很多Disruptor中RingBuffer的设计思想,比如使用缓存行填充解决伪共享问题)
RingBuffer为环形数组,默认容量为sequence可容纳的最大值(8192个),可以通过boostPower参数设置大小。
tail指针、Cursor指针用于环形数组上读写slot:
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicyCursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。

RingBuffer填充时机
程序启动时,将RingBuffer填充满,缓存着8192个id
在调用getUID()获取id时,检测到RingBuffer中的剩余id个数小于总个数的50%,将RingBuffer填充满,使其缓存8192个id
定时填充(可配置是否使用以及定时任务的周期)
填充RingBuffer
生成id(上面代码中的uidProvider.provide调用的就是这个方法)
填充缓存行解决“伪共享”
关于伪共享,可以参考这篇文章《伪共享(false sharing),并发编程无声的性能杀手》
PaddedAtomicLong为什么要这么设计?
可以参考下面文章
一个Java对象到底占用多大内存?https://www.cnblogs.com/magialmoon/p/3757767.html
写Java也得了解CPU--伪共享 https://www.cnblogs.com/techyc/p/3625701.html
百度uid-generator源码的更多相关文章
- mybatis generator 源码学习
mybatis/generator 源码地址mybatis/parent 源码地址1. 分别点击Download ZIP下载到本地. 2. 解压generator-master.zip中的core到g ...
- mybatis generator 源码修改
项目中使用mybatis + 通用mapper,用mybatis generator生成代码时有些不方便,参考了网上的一些例子,修改mybatis genrerator的源码. 首先,下载mybati ...
- 从代码生成说起,带你深入理解 mybatis generator 源码
枯燥的任务 这一切都要从多年前说起. 那时候刚入职一家新公司,项目经理给我分配了一个比较简单的工作,为所有的数据库字段整理一张元数据表. 因为很多接手的项目文档都不全,所以需要统一整理一份基本的字典表 ...
- 百度编辑器UEditor源码模式下过滤div/style等html标签
UEditor在html代码模式下,当输入带有<div style="">.<iframe>这类带有html标签的内容时,切换为编辑器模式后,会发现输入的内 ...
- cefSharp获取百度搜索结果页面的源码
using CefSharp; using CefSharp.WinForms; using System; using System.Collections.Generic; using Syste ...
- 使用jsonp跨域调用百度js实现搜索框智能提示,并实现鼠标和键盘对弹出框里候选词的操作【附源码】
项目中常常用到搜索,特别是导航类的网站.自己做关键字搜索不太现实,直接调用百度的是最好的选择.使用jquery.ajax的jsonp方法可以异域调用到百度的js并拿到返回值,当然$.getScript ...
- 使用百度UMeditor富文本编辑器,修改自定义图片上传,修改源码
富文本编辑器,不多说了,这个大家应该都用到过,至于用到的什么版本,那就分很多种 CKEditor:很早以前叫FCK,那个时候也用过,现在改名了,比较流行的一个插件,国外很多公司在用 UEDITOR:百 ...
- C# 30分钟完成百度人脸识别——进阶篇(文末附源码)
距离上次入门篇时隔两个月才出这进阶篇,小编惭愧,对不住关注我的卡哇伊的小伙伴们,为此小编用这篇博来谢罪. 前面的准备工作我就不说了,注册百度账号api,创建web网站项目,引入动态链接库引入. 不了解 ...
- Micro Templating源码分析
关于模板,写页面的人们其实一直在用,asp.net , jsp , php, nodejs等等都有他的存在,当然那是服务端的模板. 前端模板,作为前端人员肯定是多少有接触的,Handlebars.js ...
- 【krpano】浏览点赞插件(源码+介绍+预览)
简介 最近几天研究了如何在krpano全景的基础上实现记录浏览量和点赞次数,写了一个插件,方便大家使用. 效果截图如下: 每当有用户打开该全景页面时,浏览量会自动加1: 用户可以主动点击点赞按钮,点击 ...
随机推荐
- Dart server side call dll
今天,查看文档时发现Dart运行在服务端下可以调用本地实现(C/C++ dll). 我想应该有大用处 拿出来分享! 一 先做Dart库 //sse.dart library sample_synchr ...
- python 格式化字符串"%s"%
%s 字符串 (采用str()的显示) %r 字符串 (采用repr()的显示) %c 单个字符 %b 二进制整数 %d 十进制整数 %i 十进制整数 %o ...
- iOS 崩溃分析
崩溃统计分析,在APP中是非常常见一种优化APP,发现APP的BUG的方式. 1.异常处理 可通过try catch 方式处理,如果发生异常,会走catch ,最终走fianlly.对一些我们不想他崩 ...
- iOS 开发常用链接总结
知识归纳 1.招聘一个靠谱的程序员 面试题答案 https://github.com/ChenYilong/iOSInterviewQuestions 2.中文 iOS/Mac 开发博客列表 http ...
- iOS 开发笔记-控制器翻页
找了一天,终于找到了两个能用的. 1.https://github.com/wangmchn/WMPageController 2.https://github.com/everettjf/EVTTa ...
- JAVA编程思想学习笔记7-chap19-21-斗之气7段
1.枚举 2.内置三种注解 @Override @Deprecated @SuppressWarnings 3.元注解:用于注解其它注解 4.注解处理器:通过反射 5.创建线程的两种方式 实现Runn ...
- 关于微信分享的一些心得之recommend.js(直接复制就行)
// import $ from 'jquery'import Vue from 'vue'export default function (type,title,con,img,url,) { / ...
- 记录python万恶的坑
1.PyCharm Process finished with exit code -1073741819 (0xC0000005) 解决方法:卸载h5py这个包,在装cv2的时候有可能安装了h5py ...
- grunt的用法一
grunt也是工程化管理工具之一 首先你需要全局安装grunt,打开cmd命令 cnpm install -g grunt-cli 然后在你项目目录下执行 cnpm install --save gr ...
- JavaScript原型规则和实例
var arr = [] // var arr = new Array() var obj = {} // var obj = new Object() function fn() {} // var ...