关于sql中in 和 exists 的效率问题
在用in的地方可以使用freemark标签代替,例如:
将
<#if assistantList??&& (assistantList?size > 0)>
AND (c.uid = ${uid} OR c.course_id IN (<#list assistantList as item> ${item} <#if item_has_next>,</#if></#list>))
<#else>
AND c.uid = ${uid}
</#if>
改为
<#if assistantList??&& (assistantList?size > 0)>
AND (c.uid = ${uid} OR (<#list assistantList as item>c.course_id = ${item}<#if item_has_next> OR </#if></#list>))
<#else>
AND c.uid = ${uid}
</#if>
对于in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
在网上看到很多关于sql中使用in效率低的问题,于是自己做了测试来验证是否是众人说的那样。
群众:
对于in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。 这里我找到两张表,一个是用户信息表[INDIVIDUAL] 47万条数据,一个状态类型表[STATUS] 88条数据,对应上面所述的一多一少
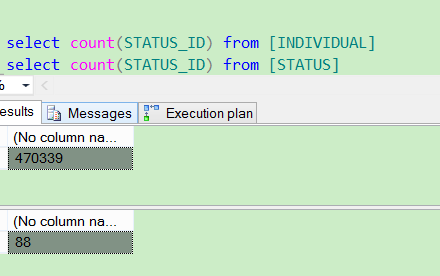
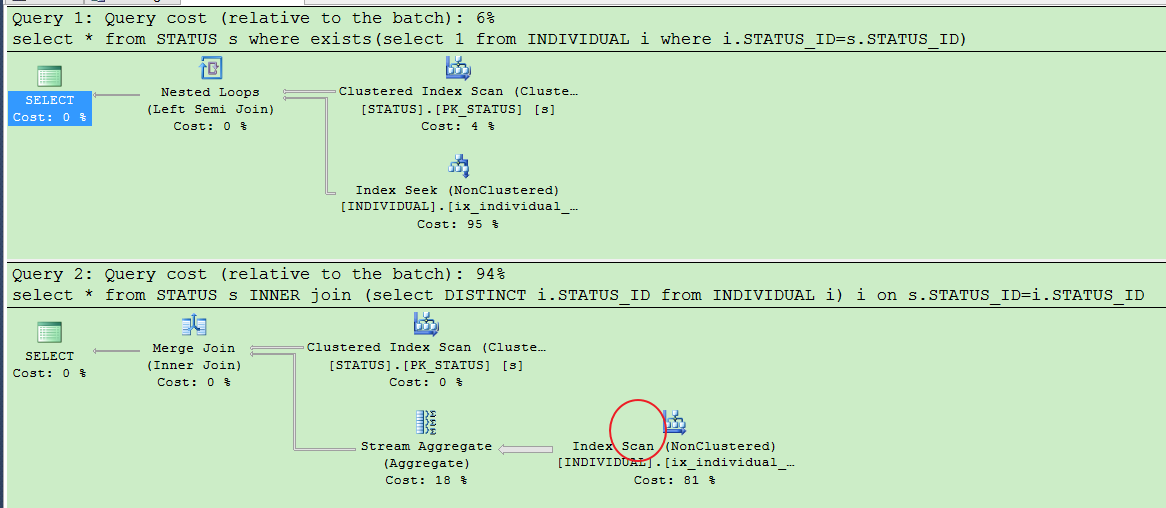
然后进行两种查询 (not exists 和 not in一组)(exists 和 in一组)
select * from STATUS s where not exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID) select * from STATUS s where s.STATUS_ID not in(select i.STATUS_ID from INDIVIDUAL i )
select * from STATUS s where exists(select 1 from INDIVIDUAL i where i.STATUS_ID=s.STATUS_ID) select * from STATUS s where s.STATUS_ID in(select i.STATUS_ID from INDIVIDUAL i )
查看执行计划后发现,结果貌似是一样的,令人意外,可能大家认为in 比较慢的原因就是 IN先执行子查询 ,但是事实并不是这样的。


但是如果你使用join,就会发现真的对用户表全盘扫描了.....
关于sql中in 和 exists 的效率问题的更多相关文章
- 关于sql中in 和 exists 的效率问题,in真的效率低吗
原文: http://www.cnblogs.com/AdamLee/p/5054674.html 在网上看到很多关于sql中使用in效率低的问题,于是自己做了测试来验证是否是众人说的那样. 群众: ...
- SQL中如何使用EXISTS替代IN
原创作品,可以转载,但是请标注出处地址http://www.cnblogs.com/V1haoge/p/6385312.html 我们在程序中一般在做SQL优化的时候讲究使用EXISTS带替代IN的做 ...
- 问题:PLS-00204: 函数或伪列 'EXISTS' 只能在 SQL 语句中使用;结果:PL/SQL中不能用exists函数?
怎么写了一个语句带出这样的结果. 语句: if exists (select * from sysdatabases where name='omni') then 结果: ERROR 位于第 4 行 ...
- sql中in和exists效率问题 转自百度知道
in和existsin 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询. 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询 ...
- sql中in和exists的区别效率问题 转
in 和exists in是把外表和内表作hash 连接,而exists 是对外表作loop 循环,每次loop 循环再对内表进行查询. 一直以来认为exists 比in 效率高的说法是不准确的.如果 ...
- sql中in和exists的原理及使用场景。
在我们的工作中可能会遇到这样的情形: 我们需要查询a表里面的数据,但是要以b表作为约束. 举个例子,比如我们需要查询订单表中的数据,但是要以用户表为约束,也就是查询出来的订单的user_id要在用户表 ...
- SQL中IN和EXISTS用法的区别
结论 1. in()适合B表比A表数据小的情况 2. exists()适合B表比A表数据大的情况 当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用. select * fro ...
- sql中in和exists的区别
in 和exists in是把外表和内表作hash 连接,而exists 是对外表作loop 循环,每次loop 循环再对内表进行查询. 一直以来认为exists 比in 效率高的说法是不准确的.如果 ...
- SQL中IN与EXISTS的区别
1.IN子句中的子查询只能返回一个字段,不允许返回多个字段,而EXISTS可以返回多个字段 2.IN返回的是某字段的值,而EXISTS返回的则是True或False,EXISTS子句存在符合条件的结果 ...
随机推荐
- Docker ssh server
这个话题真让我气愤啊,在家里的mac上我已经全部摆平了,结果在公司的Linux上就给堵住了 原因不祥,但最后在错误提示里,有个移除(remove)信息,我照做了,就没问题了,全通了 大概是linux里 ...
- MSSqlServer 发布/订阅配置(主从同步)
背景: 1.单个独立数据库的吞吐量是有瓶颈的,那么如何解决这个瓶颈? 2.服务器直接数据如何复制.并具备一致性.可扩展性? 资源: 官方资源:https://technet.microsoft.com ...
- cocos2dx 3.x(纯代码实现弹出对话框/提示框/警告框)
头文件: // // PopAlertDialog.h // macstudycocos2dx // // Created by WangWei on 15/6/8. // // #ifndef ...
- Robot FrameWork使用中常见问题收集
1.“假死”现象 在完成一个模块的脚本编写后,多次运行没问题,但是隔了几天再来运行的时候,发现脚本运行会出现浏览器那边不动了,脚本这边的时间一直在跑. 问题原因及解决方法: 问题解决了,原因是**dr ...
- 强势龙头股的 VOLM5/35/135 走势,可作为逃顶参考
强势龙头股的 VOLM5/35/135 走势,可作为逃顶参考
- UVALi 3263 That Nice Euler Circuit(几何)
That Nice Euler Circuit [题目链接]That Nice Euler Circuit [题目类型]几何 &题解: 蓝书P260 要用欧拉定理:V+F=E+2 V是顶点数; ...
- WebSocket.之.基础入门-后端响应消息
WebSocket.之.基础入门-后端响应消息 在<WebSocket.之.基础入门-前端发送消息>的代码基础之上,进行添加代码.代码只改动了:TestSocket.java 和 inde ...
- mac install wget
没有Wget的日子是非常难过的,强大的Mac OS 下安装Wget非常简单 下载一个Wget的源码包,http://www.gnu.org/software/wget/ ftp下载地址:ftp://f ...
- install scala & spark env
安装Scala 1,到http://www.scala-lang.org/download/ 下载与Spark版本对应的Scala.Spark1.2对应于Scala2.10的版本.这里下载scala- ...
- CSS选择器的优先级及权重问题【CSS核心问题】及其它属性
1.CSS选择器优先级: !important >行间样式> id >class和属性选择器>标签选择器>通配符选择器 注意:[初级工程师水平] 2. ...