Dify+DeepSeek实战教程!企业级 AI 文档库本地化部署,数据安全与智能检索我都要
上次折腾完 DeepSeek 的本地私有化部署后,心里就一直琢磨着:能不能给咱们 Rainbond 的用户再做点实用的东西?毕竟平时总收到反馈说文档查找不够方便,要是能有个 AI 文档助手该多好。正想着呢,搭建本地知识库的想法就冒了出来 —— 既能解决实际需求,又能把技术落地成真正有用的工具,这不就是两全其美的事嘛!尤其是想到企业场景里,知识库往往涉及业务流程、技术方案甚至客户数据,数据安全可是头等大事,本地化部署带来的数据不出本地、自主可控优势,简直是刚需中的刚需。
第一个跳进脑海的方案就是 Dify。作为最近一直在关注的工具,它在文档处理上的灵活性特别吸引我 —— 既能像搭积木一样定制问答逻辑,又能完美适配本地化部署环境,天生契合既要智能高效,又要安全合规的需求。于是赶紧搜了一波资料,发现确实有不少可参考的实践经验,但系统从零搭建的教程却不多。想着可能有不少朋友和我一样,既想拥有专属的知识库系统,又苦于没有清晰的入门指引,索性决定把自己的实践过程整理出来。
接下来这篇文章,就打算用最接地气的方式,手把手带你从 0 到 1 搭建一套专属的本地知识库系统。无论你是想优化企业内部文档检索(不用担心敏感数据上传云端的风险),还是像我一样想为用户打造更智能的文档服务,都能跟着步骤一步步实现。咱们不卖关子,直接上干货。
Dify
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
部署 Dify
Dify 官方提供了使用 Docker Compose 部署的方式,如下:
$ git clone https://github.com/langgenius/dify.git --branch 0.15.3
$ cd dify/docker
$ cp .env.example .env
$ docker-compose up -d
你可能会遭遇无法获取 Github 代码、Docker 镜像等问题,需要挂解决。
使用 Rainbond 部署
对于不熟悉 K8s 的伙伴,又想在 K8s 中安装 Dify,可以使用 Rainbond 来部署。Rainbond 是一个无需了解 K8s 的云原生应用管理平台,支持通过可视化界面管理容器化应用,提供应用市场一键部署、源码构建等能力,帮助用户在不接触 K8s 底层的前提下,轻松实现应用的生产级部署与运维。
免费试用 Rainbond Cloud(零门槛快速体验)
如果你想零成本快速上手云原生部署,推荐直接体验 Rainbond Cloud(点击注册 https://run.rainbond.com,新用户即享免费额度)—— 无需自备服务器或配置复杂环境,注册登录后,在云端环境中一键部署 Dify,5 分钟内即可开启 AI 应用开发。
私有化本地部署(企业级可控性首选)
如果需要将 Dify 部署在自有服务器或数据中心(满足数据本地化、合规性要求),Rainbond 提供极简私有化部署方案,无需手动编写 K8s 配置,10 分钟内即可完成生产级环境搭建:
curl -o install.sh https://get.rainbond.com && bash ./install.sh
等待几分钟后,通过 http://IP:7070 访问 Rainbond 并注册登录。
通过应用市场一键部署 Dify
创建应用并选择通过应用市场部署,在开源应用商店中搜索Dify ,点击一键安装。
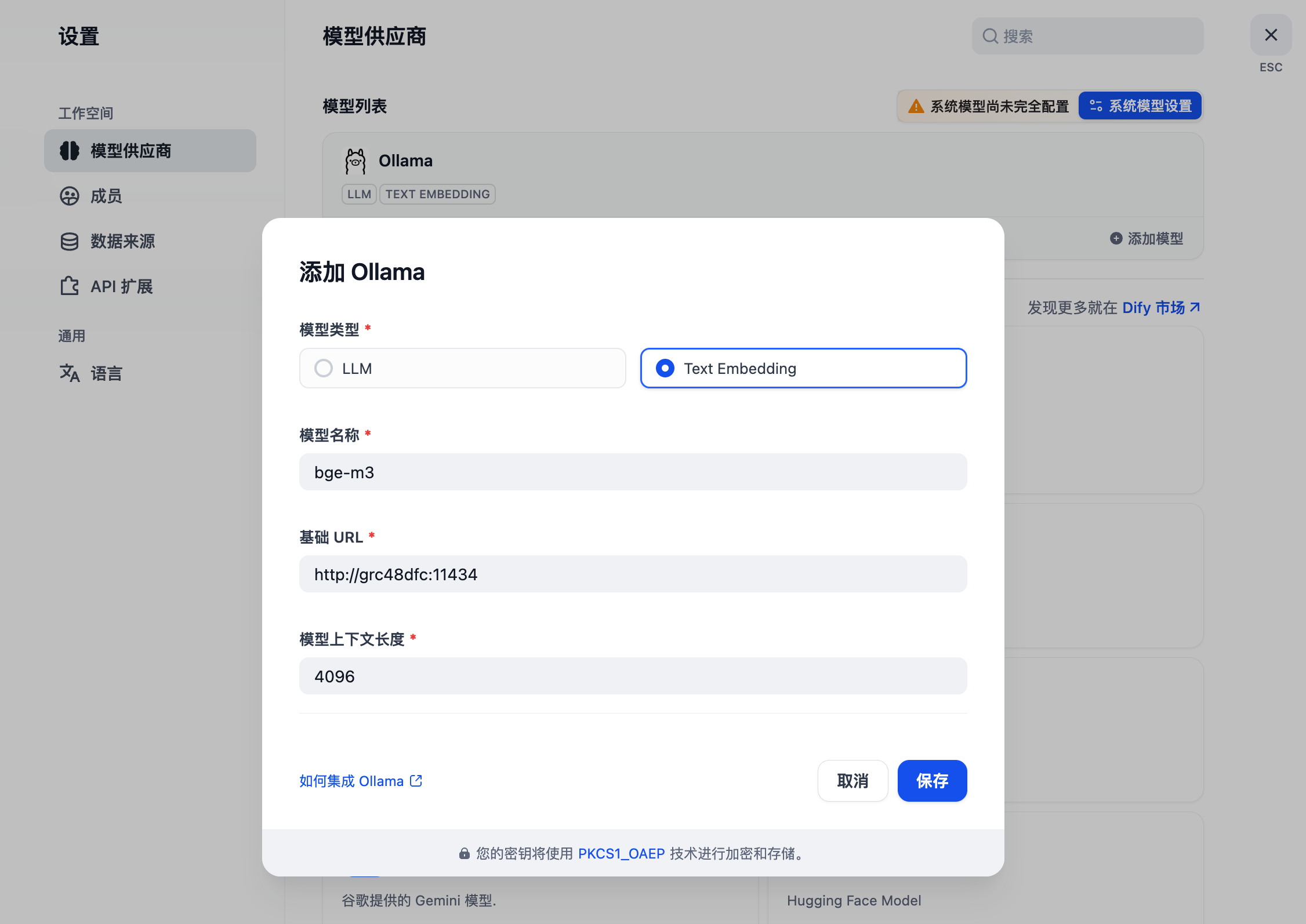
等待拓扑图中的组件颜色全部变为绿色则代表部署成功。
由于应用模板给每个组件分配的资源比较少,只能保障基本运行,在实测过程中索引 200 个文档左右 Worker 等服务就发生了 OOM。需要在安装完成后手动调整下相关组件的资源,比如 API、Worker、Plugin、Sandbox 组件的资源配额。进入到组件内 -> 伸缩,修改资源为 500m、1G ,具体根据实际情况来调整。
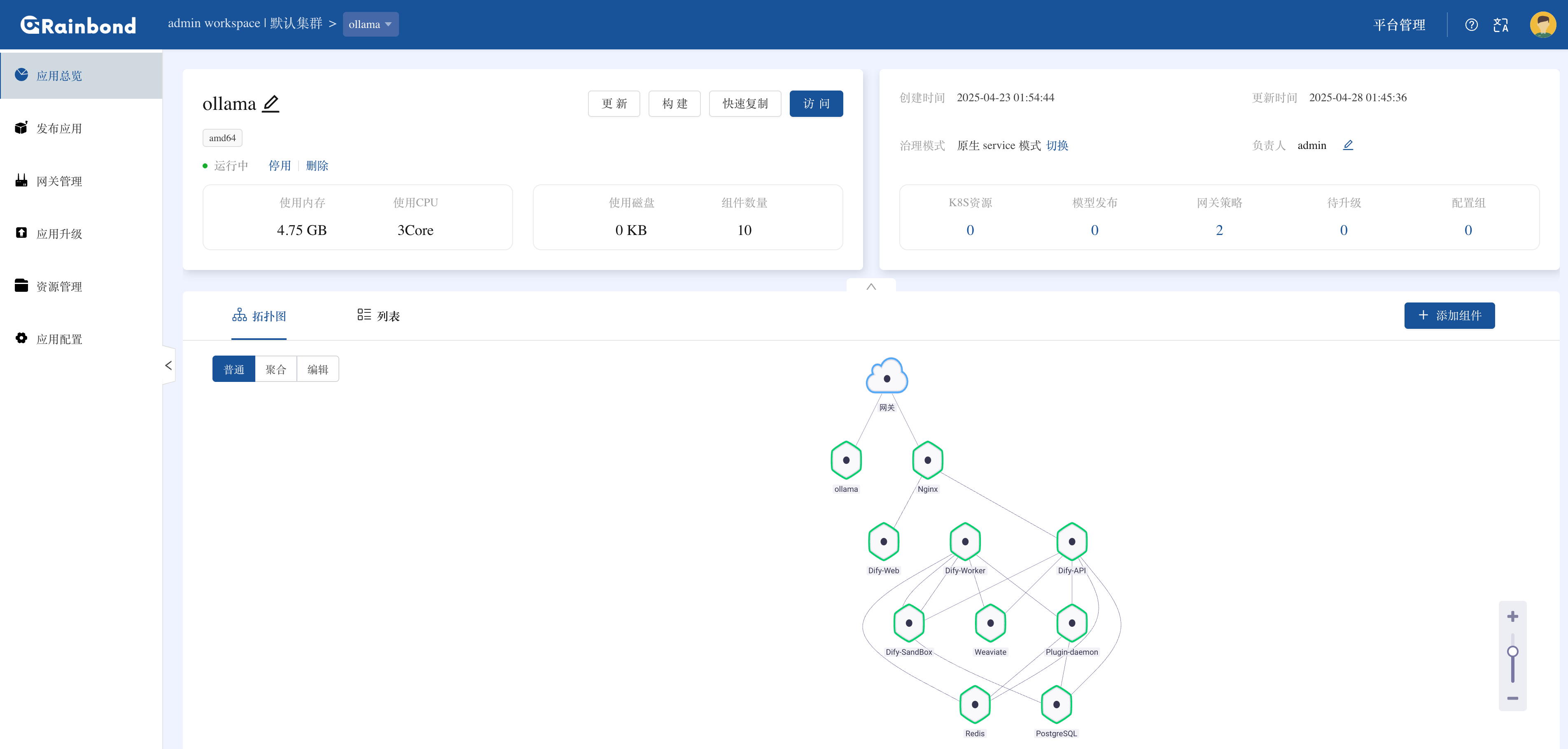
点击访问按钮即可通过平台生成的域名访问 Dify 可视化界面,注册即可开始 AI 应用开发之旅。
配置 Dify 使用本地大模型
关于如何在本地部署 DeepSeek R1 大模型可以参考我写的上一篇文章 K8S 部署 Deepseek 要 3 天?别逗了!Ollama+GPU Operator 1 小时搞定,同时在哔哩哔哩也有视频。
添加 Embedding 模型
Embedding 模型就像一个语义转换器:把我们写的文字、上传的文档这些人类能看懂的内容,变成机器能计算的数字指纹(向量)。比如怎么备份文件和文件备份步骤,这两句话意思差不多,经过模型处理后,生成的向量也很接近,这样机器就能知道它们是同一个意思,而不是只看字是不是一样。
在咱们的知识库里,上传的资料必须先通过这个模型转换成向量,存到专门的数据库里。这样当用户用自然语言提问时,系统不是傻乎乎地匹配关键词,而是真正理解问题的意思,从数据库里精准找到最相关的内容。比如问API 调用报错怎么解决,系统能直接定位到文档里讲错误处理的部分,而不是只返回带API和报错字眼的零散段落,这一步就像给知识库建了一个语义索引,是让 AI 能读懂咱们私有数据的关键。
使用 Ollama 部署本地的 Embedding 模型:
进入 Rainbond 的 Ollama 组件内,进入 Web 终端执行如下命令:
ollama pull bge-m3
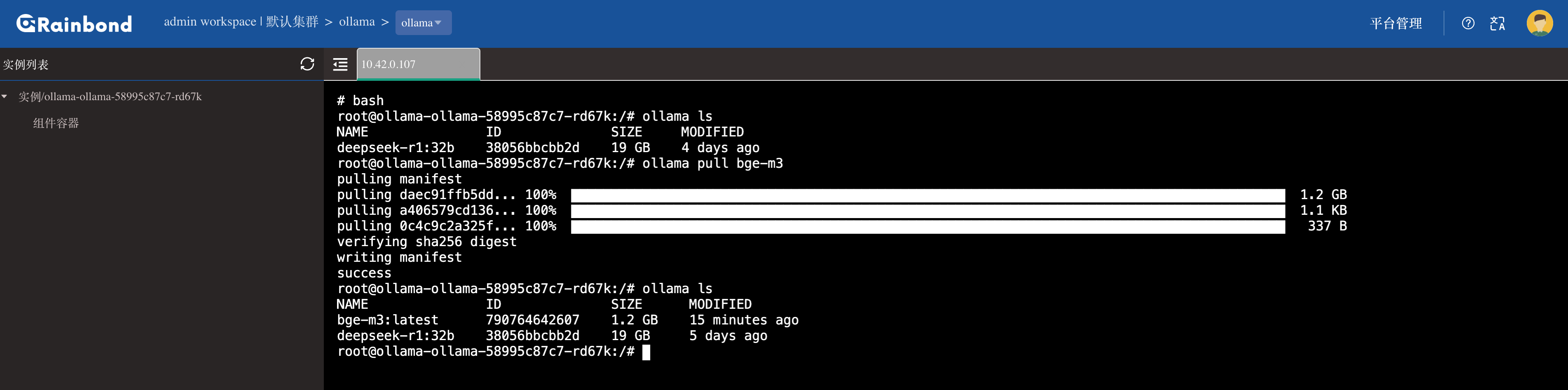
为啥选 BGE-M3?主要因为它是专为中文检索场景定制的选手,背靠中科院团队研发,天生自带中文语义理解 Buff。你也可以直接在 Ollama 里搜索其他 Embedding 模型。
在 Dify 中配置本地 Embedding 模型和 LLM 模型
进入 Dify 页面后,点击右上角头像 -> 设置 -> 模型供应商,安装 Ollama。插件安装可能需要点时间,如未成功请再次安装。
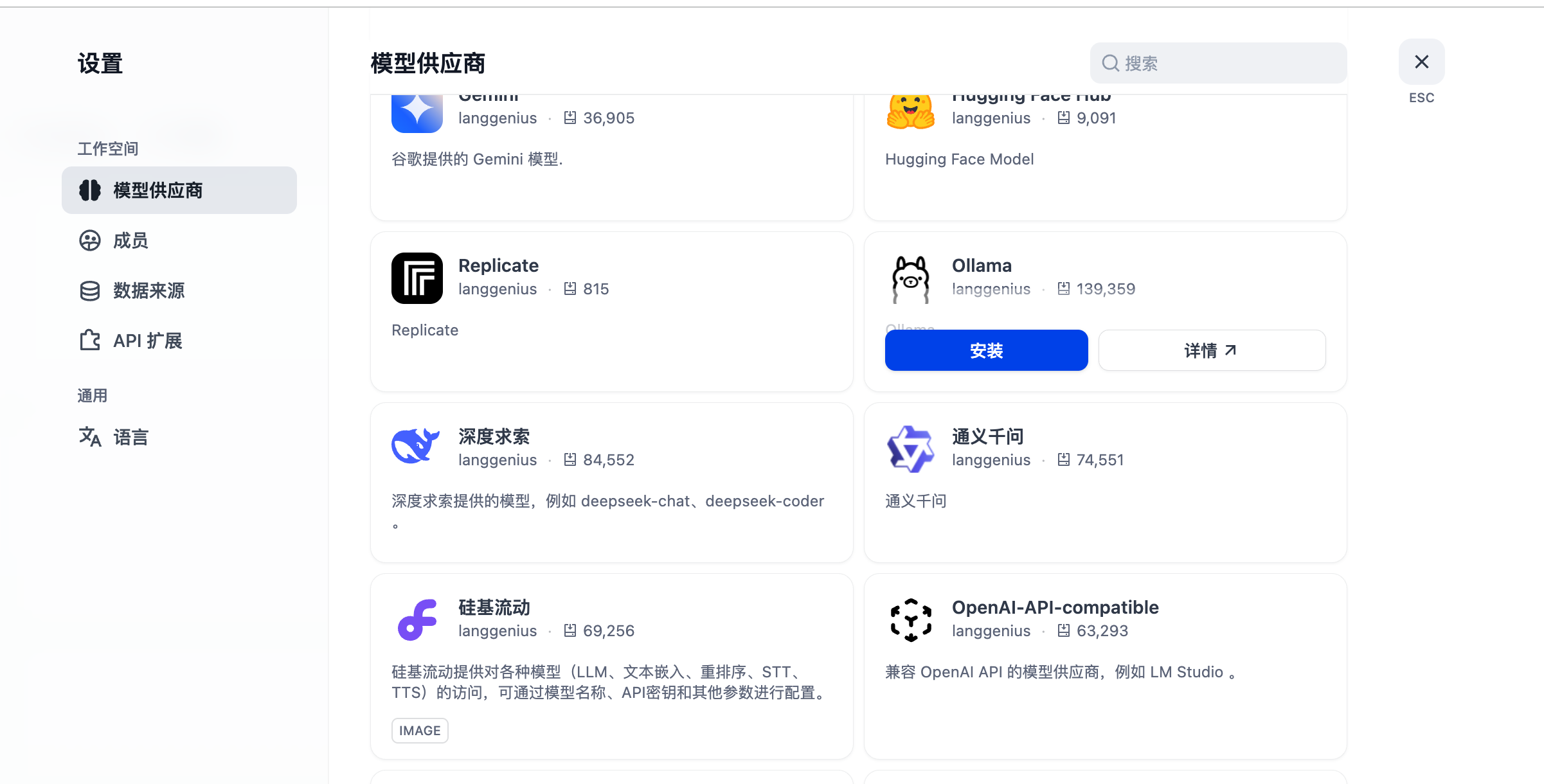
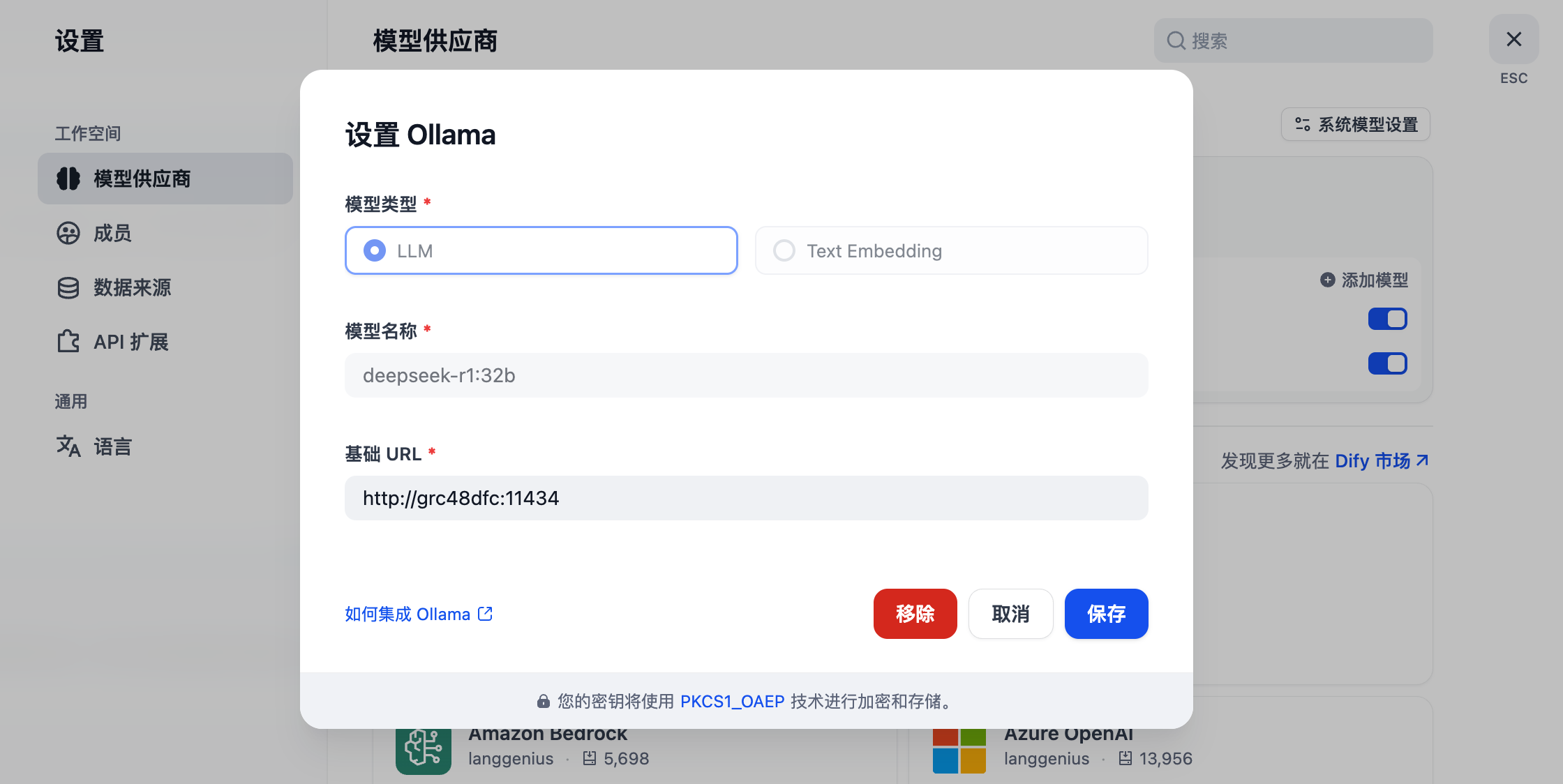
分别对接本地的 LLM 和 Text Embedding 模型相关信息。我这里填写的是 Ollama 内网地址,因为我的 Dify 和 Ollama 部署在一个 Rainbond 集群内,就可以通过内网访问;内网地址可在 Ollama 组件内 -> 端口查看到对内服务的访问地址,如下:
踩坑:保存后模型没有添加,我又添加了好几次,最后我等了10分钟左右插件才加载好,前面重复添加的几个都出来了-。-
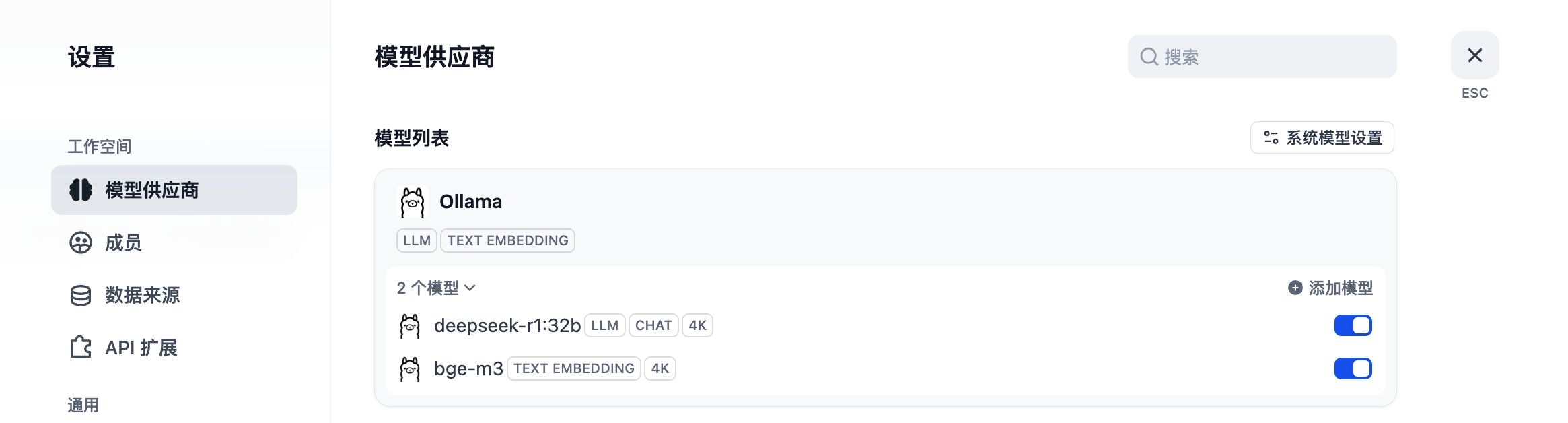
配置系统默认模型。
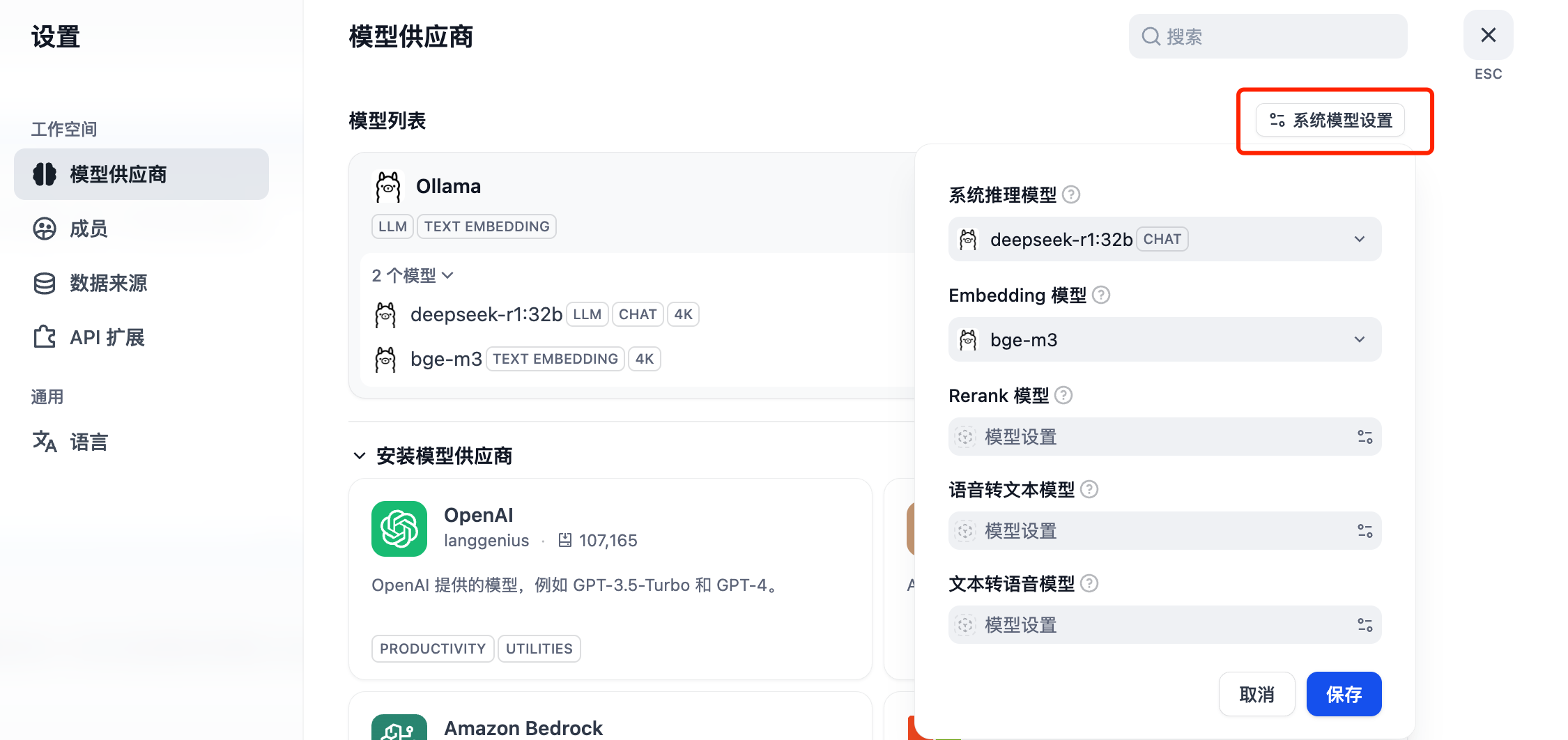
创建知识库
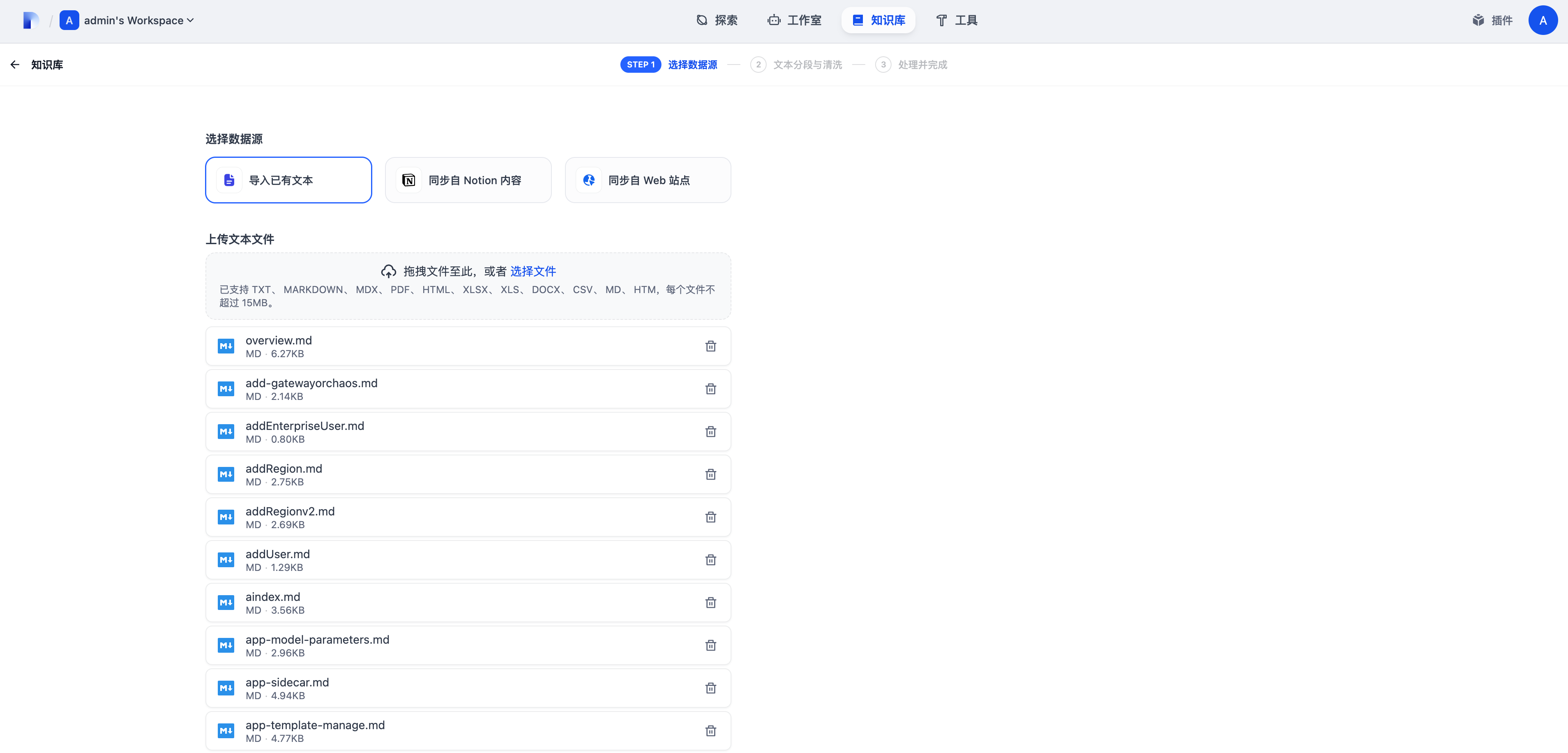
点击上方的知识库按钮,创建一个新的知识库,上传本地的文档并下一步。
这里是对文档进行分段与清洗,这里都默认就可以了,具体可以参考 Dify 知识库文档。
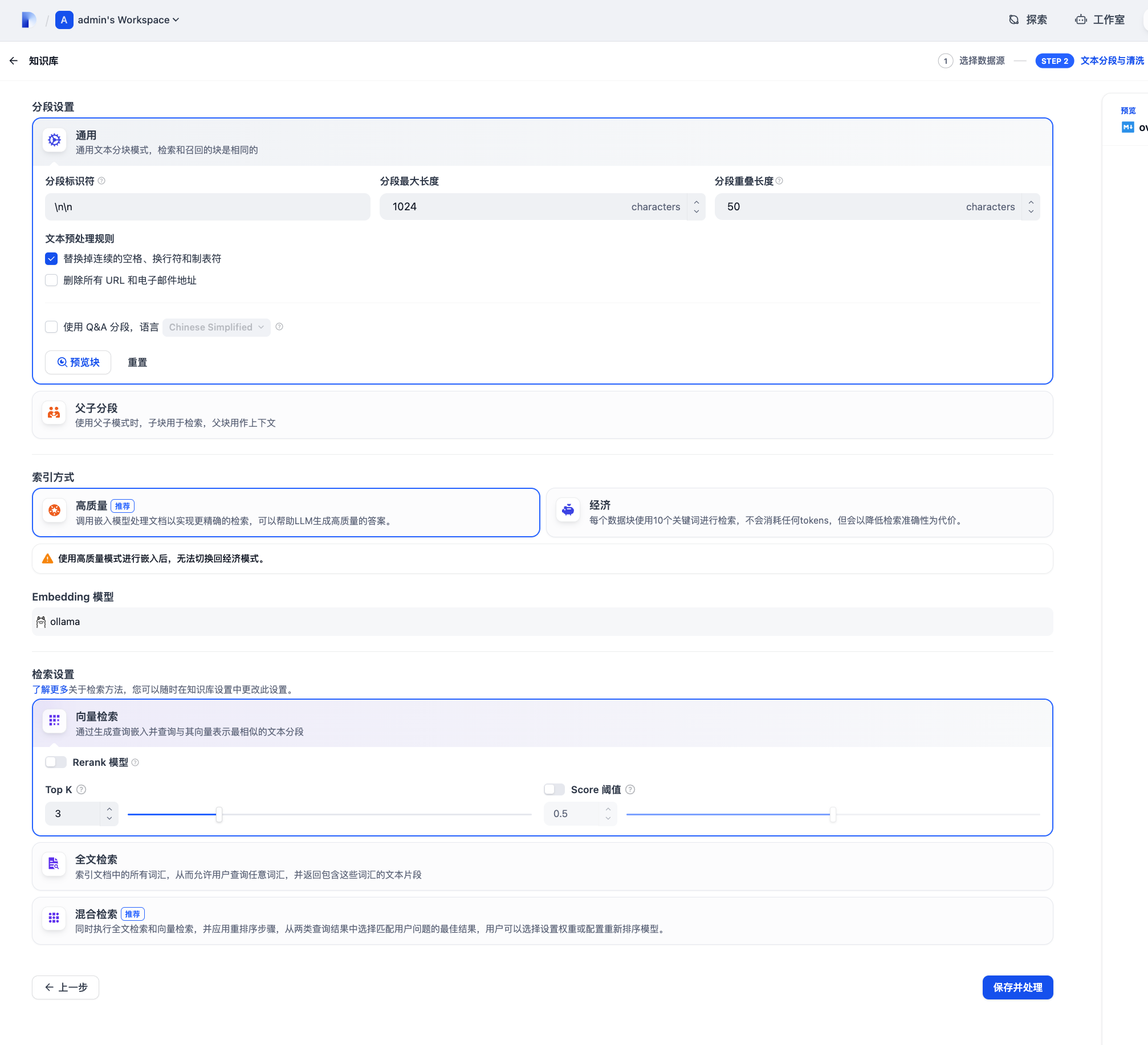
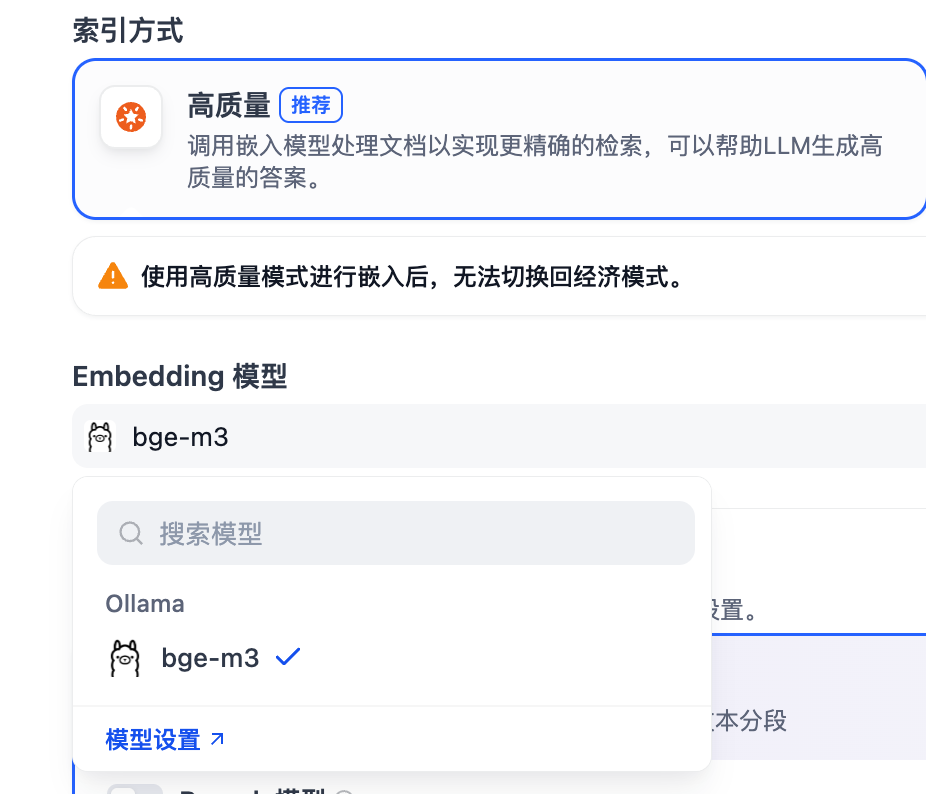
模型记得选择我们上面配置的 bpe-m3 Embedding 模型。
等待所有文档的状态变为可用即可进行下一步。
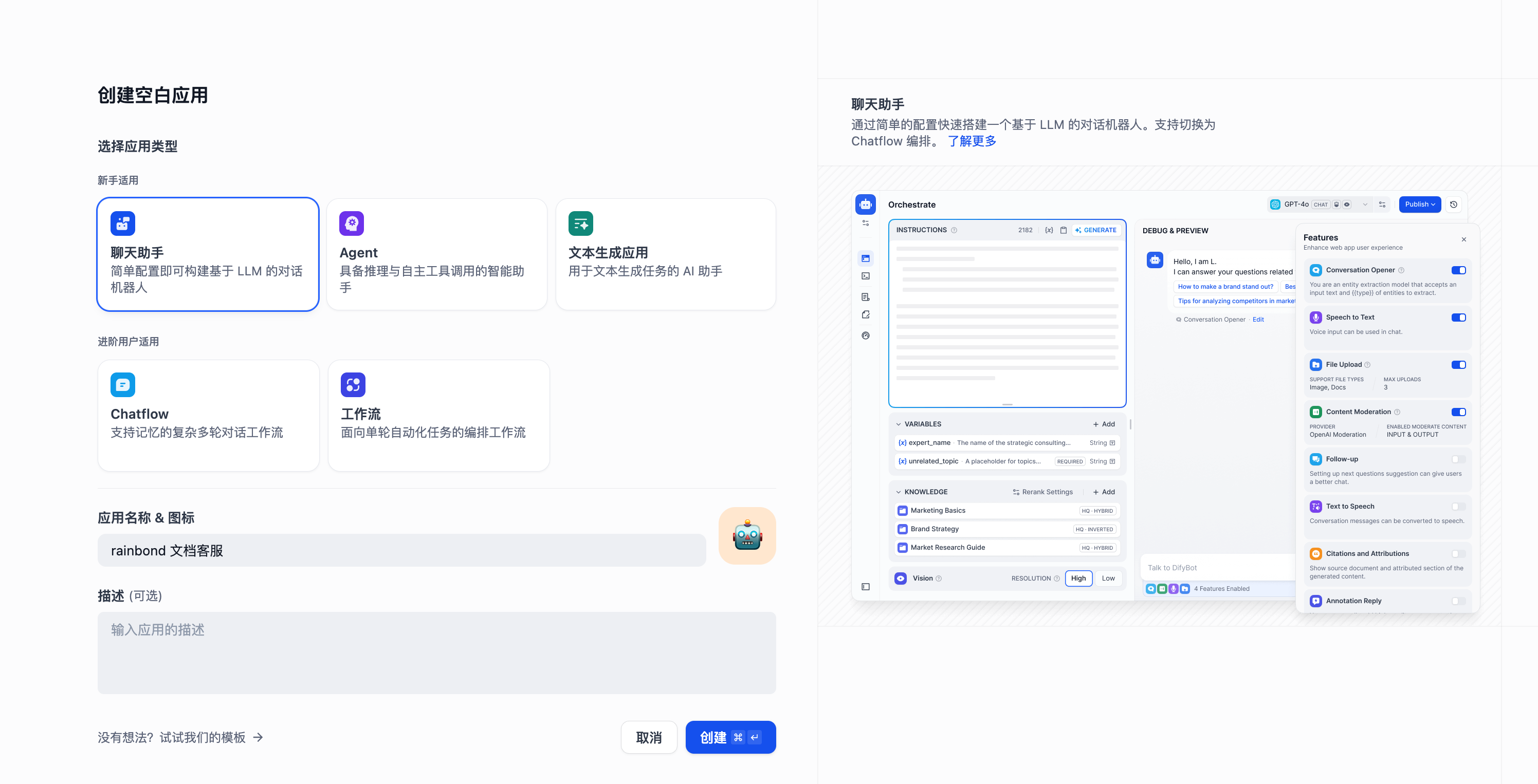
创建聊天助手
首先我们创建一个聊天助手应用。
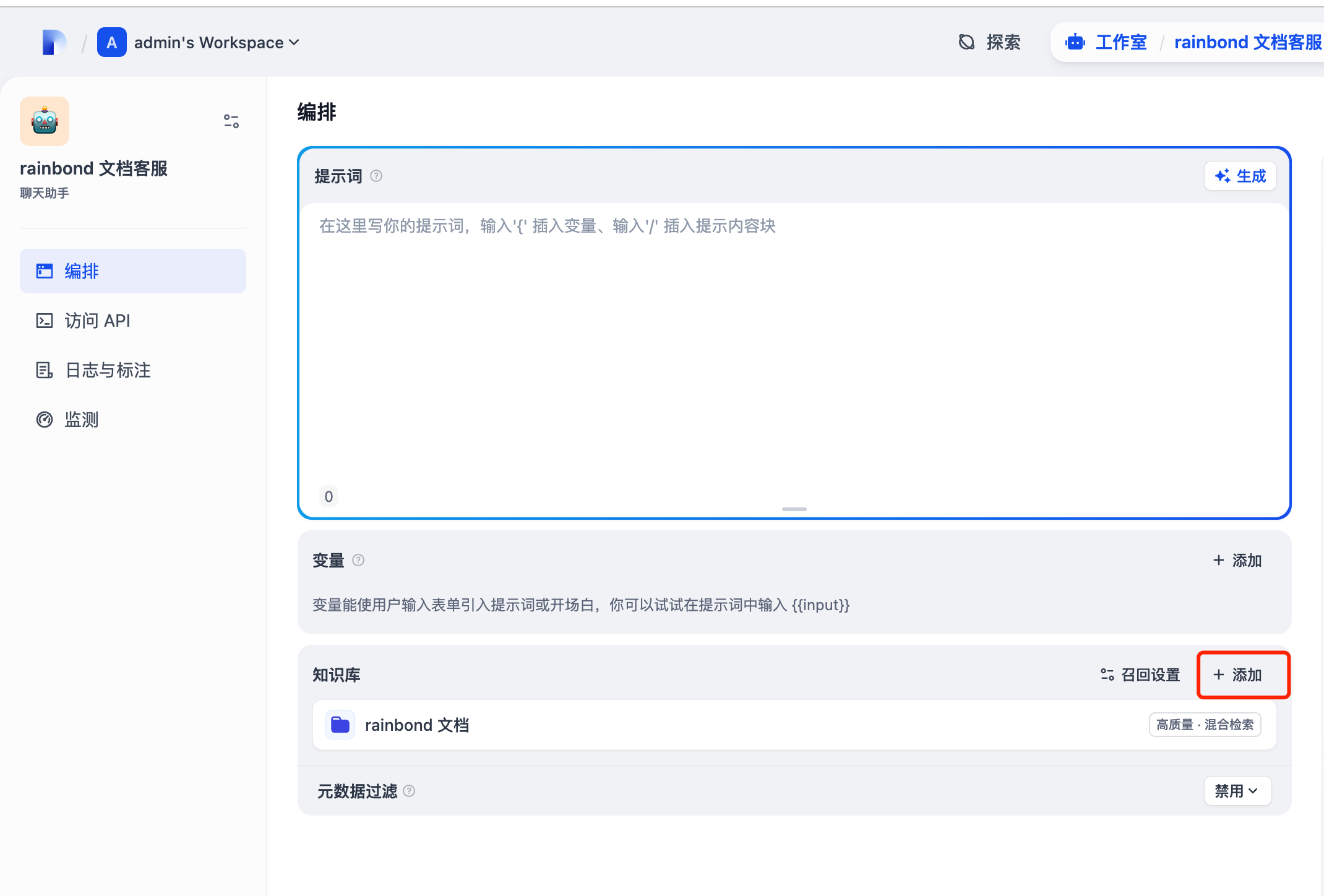
添加我们上面创建的知识库
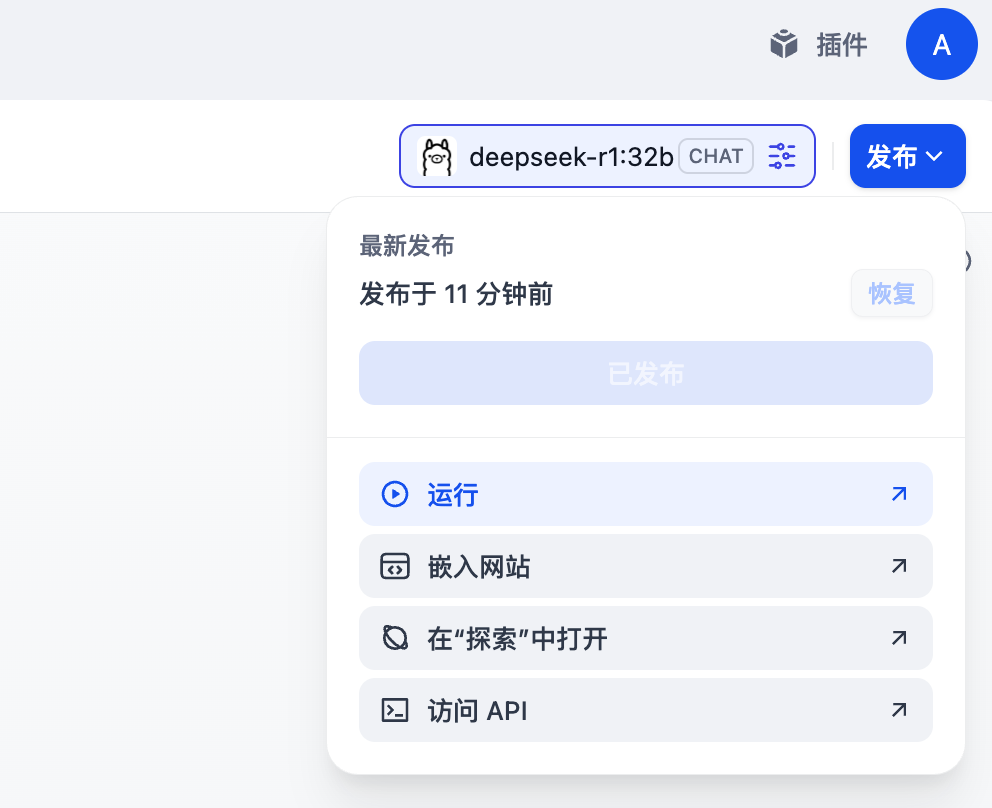
点击右上角的发布,再点击运行。
测试对话

可以说效果还是比较不错的。如果感觉回答的效果还不满意,可以参考文档对召回参数进行调整。
最后
到这儿,一个能读懂企业私有文档、数据完全本地化可控的 AI 知识库就搭好了!从部署 Dify 到配置 Embedding 模型,再到上传文档、创建聊天助手,每一步都是围绕让技术落地为实际需求设计的;既解决了传统文档检索的低效问题,又用本地化部署守住了数据安全的底线。把复杂的架构变成人人能用的工具,让代码和文档真正服务于业务。
如果你在搭建过程中遇到资源调整、模型适配等细节问题,别忘了回到文中看看踩坑提示;如果想进一步优化问答效果,Dify 的召回参数配置、Rainbond 的资源调度策略都有很大探索空间。现在,你可以试着让这个专属的 AI 助手回答文档问题,也可以把它分享给团队小伙伴,让知识真正流动起来。
后续我还会分享更多本地化 AI 应用的实操经验,如果你对某个环节想深入了解,或者有新的需求场景,欢迎在评论区留言。咱们下期折腾再见~
Dify+DeepSeek实战教程!企业级 AI 文档库本地化部署,数据安全与智能检索我都要的更多相关文章
- MWeb for Mac使用教程-如何在文档库中快速搜索
使用MWeb for Mac专业的 Markdown 编辑写作软件,可以让你随时记录自己的想法,灵感,创意,为您的工作节省宝贵的时间.本篇文章带来的是MWeb for Mac如何在文档库中快速搜索使用 ...
- elk实战分析nginx日志文档
elk实战分析nginx日志文档 架构: kibana <--- es-cluster <--- logstash <--- filebeat 环境准备:192.168.3.1 no ...
- Java-Runoob-高级教程:Java 文档注释
ylbtech-Java-Runoob-高级教程:Java 文档注释 1.返回顶部 1. Java 文档注释 Java 支持三种注释方式.前两种分别是 // 和 /* */,第三种被称作说明注释,它以 ...
- MongoDB入门教程一[文档与集合]
MongoDB 是面向集合存储的文档型数据库,其涉及到的基本概念与关系型数据库相比有所不同.举个例子,在关系型数据库中,我们记录一个订单的信息,通常是这样设计表结构的: 设计一个订单基本信息表和一个订 ...
- sharepoint中的Power Shell命令创建、删除文档库列表
ListTemplateType 枚举: 自定义列表-GenericList.文档库-DocumentLibrary.图片库-PictureLibrary.公告-Announcements.联系人-C ...
- SharePoint文档库文件夹特殊字符转义
当我们在SharePoint网站文档库中新建文件夹时包含了~ " # % & * : < > ? / \ { | }字符时(一共15个), 或者以.开头或者结束,或者包含 ...
- 在Outlook中查看预览SharePoint文档库的文档
本文概况 阅读时间: 约2分钟 适用版本:SharePoint Server 2010及以上 面向用户:普通用户,管理员 难度指数:★★☆☆☆ 在日常工作中,总有一些常用的文档需要经常打开查看,其实我 ...
- 360安全卫士造成Sharepoint文档库”使用资源管理器打开“异常
备注:企业用户还是少用360为妙 有客户反馈:部门里的XP SP2环境客户机全部异常,使用资源管理器打开Sharepoint文档库,看到的界面样式很老土,跟本地文件夹不一样 ...
- 基于Picture Library创建的图片文档库中的上传多个文件功能(upload multiple files)报错怎么解决?
复现过程 首先,我创建了一个基于Picture Library的图片文档库,名字是 Pic Lib 创建完毕后,我点击它的Upload 下拉菜单,点击Upload Picture按钮 在弹出的对话框中 ...
- SharePoint 2013 文档库中PPT转换PDF
通过使用 PowerPoint Automation Services,可以从 PowerPoint 二进制文件格式 (.ppt) 和 PowerPoint Open XML 文件格式 (.pptx) ...
随机推荐
- DataV过滤器
人才库: return data.filter(function (item) { return item.职级 === ''; }) 区县分析: //一级指标 const t = Object. ...
- ABB机器人3HNE00313-1示教器黑屏故障维修
随着工业自动化的快速发展,ABB机器人示教器在生产线上的应用越来越广泛.然而,在使用过程中,示教器偶尔也会出现故障,其中比较常见的一种是ABB工业机械手示教器黑屏故障. 一.ABB工业机器人示教盒黑屏 ...
- KUKA库卡机器人维修
KUKA库卡机器人作为生产线上的核心设备,一旦出现KUKA机械手故障,将直接影响整个生产线的运行效率.及时的库卡机器人维修工作不仅能够迅速恢复机器人的工作状态,减少生产停滞时间,还能通过预防性维护降低 ...
- Jenkins - [02] 安装部署
题记部分 一.Jenkins是什么 Jenkins,原名Hudson,2011年改为现在的名字,它是一个开源的实现持续集成的软件工具. 官网:https://www.jenkins.io/ 官网: ...
- dx12学习之旅-
记录一下,第一篇博客2024年7月26日下午. 计划在毕业后从事游戏开发的工作,现在在学习龙书dx12,平时会写一些对龙书内容上的一些理解.在读完全书之后,会考虑进行一次龙书相关的总结,不过这应该要很 ...
- JS用 URL 构造函数来解析 URL
const url = new URL('http://username:password@hostname:9090/path?arg=value#anchor'); console.log(url ...
- windows mysql8安装zip
MySQL 是一种广泛使用的关系数据库管理系统,MySQL 8 是其最新的主要版本,结合了出色的性能和丰富的功能. 一.准备工作 1. 下载MySQL 8 zip包 首先,你需要获取MySQL 8的压 ...
- 基于 .NET Blazor 开源、低代码、易扩展的插件开发框架
前言 今天大姚给大家分享一个基于 .NET Blazor 开源的轻量级.跨平台.低代码.易扩展的插件开发框架:Known. 项目介绍 Known 是一个基于 Blazor 的轻量级.跨平台.低代码.易 ...
- JMeter 通过 BeanShell 脚本处理入参和回参
入参:可以通过该方式动态生成入参参数,如时间参数,随机参数等. 操作:右键 HTTP Request - Add - Pre Processor - BeanShell PreProcessor im ...
- composer init
$ composer init Do not run Composer as root/super user! See https://getcomposer.org/root for details ...