Tortoise-ORM级联查询与预加载性能优化
title: Tortoise-ORM级联查询与预加载性能优化
date: 2025/04/26 12:25:42
updated: 2025/04/26 12:25:42
author: cmdragon
excerpt:
Tortoise-ORM通过异步方式实现级联查询与预加载机制,显著提升API性能。模型关联关系基础中,定义一对多关系如作者与文章。级联查询通过select_related方法实现,预加载通过prefetch_related优化N+1查询问题。实战中,构建高效查询接口,如获取作者详情及最近发布的文章。高级技巧包括嵌套关联预加载、条件预加载和自定义预加载方法。常见报错处理如RelationNotFoundError、QueryTimeoutError和ValidationError。最佳实践建议包括测试环境查询分析、添加Redis缓存层、添加数据库索引和分页限制返回数据量。
categories:
- 后端开发
- FastAPI
tags:
- Tortoise-ORM
- 级联查询
- 预加载
- 性能优化
- FastAPI
- 数据库关联
- N+1查询问题

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
{kind=link}
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
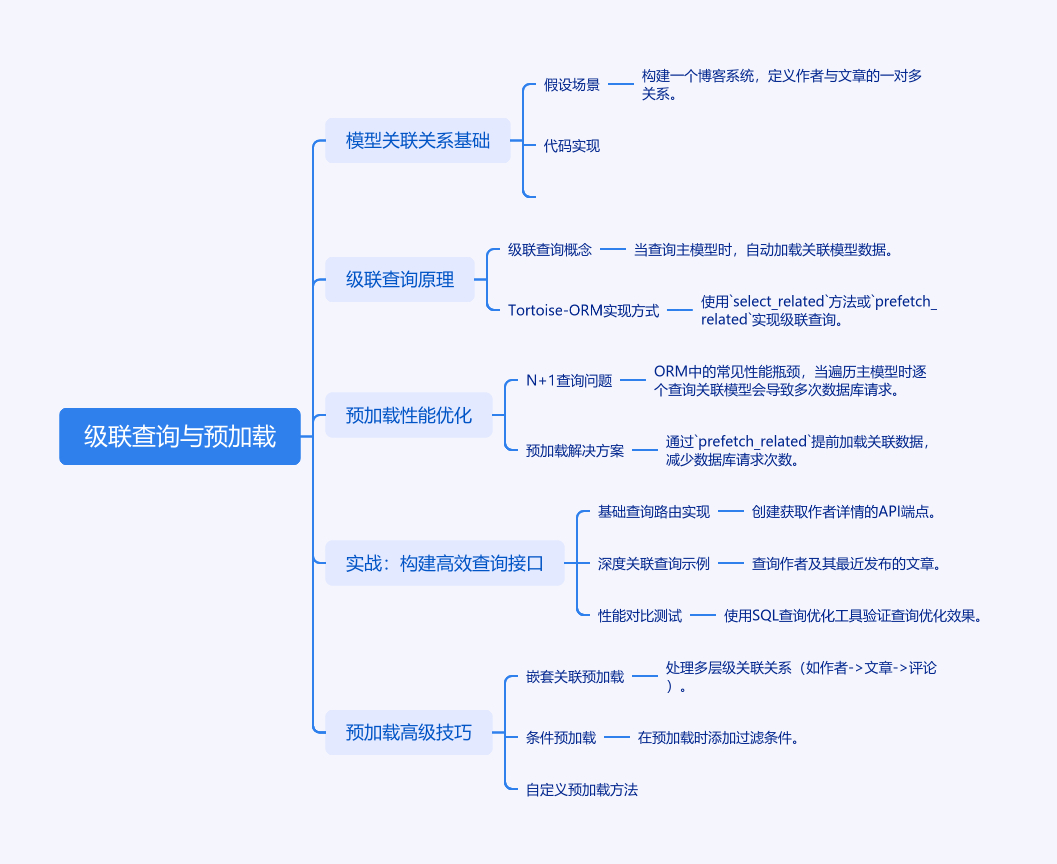
一、级联查询与预加载核心概念
在开发Web应用时,处理数据库表之间的关联关系是常见需求。Tortoise-ORM通过异步方式实现级联查询与预加载机制,能够显著提升API性能。
1.1 模型关联关系基础
假设我们构建一个博客系统,定义作者(Author)与文章(Article)的一对多关系:
from tortoise.models import Model
from tortoise import fields
class Author(Model):
id = fields.IntField(pk=True)
name = fields.CharField(max_length=50)
# 定义反向关系查询名称
articles: fields.ReverseRelation["Article"]
class Article(Model):
id = fields.IntField(pk=True)
title = fields.CharField(max_length=255)
content = fields.TextField()
# 外键关联到Author模型
author: fields.ForeignKeyRelation[Author] = fields.ForeignKeyField(
"models.Author", related_name="articles"
)
1.2 级联查询原理
当查询主模型时自动加载关联模型数据,例如获取作者时联带查询其所有文章。Tortoise-ORM通过select_related方法实现:
# 获取作者及其所有文章(单次查询)
author = await Author.filter(name="张三").prefetch_related("articles")
1.3 预加载性能优化
N+1查询问题是ORM常见性能瓶颈。当遍历作者列表时逐个查询文章会导致多次数据库请求。通过prefetch_related提前加载关联数据:
# 批量获取作者列表及其关联文章(2次查询)
authors = await Author.all().prefetch_related("articles")
for author in authors:
print(f"{author.name}的文章:{len(await author.articles)}篇")
二、实战:构建高效查询接口
2.1 基础查询路由实现
创建获取作者详情的API端点:
from fastapi import APIRouter
from pydantic import BaseModel
router = APIRouter()
class AuthorOut(BaseModel):
id: int
name: str
articles: list[dict] = []
class Config:
orm_mode = True
@router.get("/authors/{author_id}", response_model=AuthorOut)
async def get_author(author_id: int):
author = await Author.get(id=author_id).prefetch_related("articles")
return await AuthorOut.from_tortoise_orm(author)
2.2 深度关联查询示例
查询作者及其最近发布的3篇文章:
class ArticlePreview(BaseModel):
title: str
created_at: datetime
class AuthorDetail(AuthorOut):
latest_articles: list[ArticlePreview] = []
@router.get("/authors/{author_id}/detail", response_model=AuthorDetail)
async def get_author_detail(author_id: int):
author = await Author.get(id=author_id)
articles = await author.articles.all().order_by("-created_at").limit(3)
return AuthorDetail(
**await AuthorOut.from_tortoise_orm(author),
latest_articles=articles
)
2.3 性能对比测试
使用EXPLAIN ANALYZE验证查询优化效果:
-- 未优化查询
EXPLAIN
ANALYZE
SELECT *
FROM author
WHERE id = 1;
EXPLAIN
ANALYZE
SELECT *
FROM article
WHERE author_id = 1;
-- 优化后查询
EXPLAIN
ANALYZE
SELECT *
FROM author
LEFT JOIN article ON author.id = article.author_id
WHERE author.id = 1;
三、预加载高级技巧
3.1 嵌套关联预加载
处理多层级关联关系(作者->文章->评论):
# 三层级预加载示例
authors = await Author.all().prefetch_related(
"articles__comments" # 双下划线表示嵌套关系
)
3.2 条件预加载
预加载时添加过滤条件:
# 只预加载2023年发布的文章
authors = await Author.all().prefetch_related(
articles=Article.filter(created_at__year=2023)
)
3.3 自定义预加载方法
创建复杂查询的复用方法:
class Author(Model):
@classmethod
async def get_with_popular_articles(cls):
return await cls.all().prefetch_related(
articles=Article.filter(views__gt=1000)
)
四、课后Quiz
当需要加载作者及其所有文章的标签时,正确的预加载方式是:
A)prefetch_related("articles")
B)prefetch_related("articles__tags")
C)select_related("articles.tags")以下哪种场景最适合使用select_related?
A) 获取用户基本信息
B) 获取用户及其个人资料(一对一关系)
C) 获取博客及其所有评论(一对多关系)
答案与解析:
- B正确,双下划线语法用于跨模型预加载。C语法错误,select_related不能用于一对多关系
- B正确,select_related优化一对一关系查询。一对多用prefetch_related更合适
五、常见报错处理
报错1:RelationNotFoundError
原因:模型未正确定义关联字段
解决方案:
- 检查
related_name拼写是否正确 - 确认关联模型已正确导入
报错2:QueryTimeoutError
原因:复杂预加载导致查询过慢
解决方案:
- 添加数据库索引
- 拆分查询为多个步骤
- 使用
only()限制返回字段
报错3:ValidationError
原因:Pydantic模型字段不匹配
解决方案:
- 检查response_model字段类型
- 使用
orm_mode = True配置 - 验证数据库字段类型是否匹配
六、最佳实践建议
- 始终在测试环境进行
EXPLAIN查询分析 - 对频繁访问的接口添加Redis缓存层
- 为常用查询字段添加数据库索引
- 使用分页限制返回数据量
- 定期进行慢查询日志分析
安装环境要求:
pip install fastapi uvicorn tortoise-orm pydantic
配置Tortoise-ORM示例:
from tortoise import Tortoise
async def init_db():
await Tortoise.init(
db_url='sqlite://db.sqlite3',
modules={'models': ['path.to.models']}
)
await Tortoise.generate_schemas()
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:Tortoise-ORM级联查询与预加载性能优化 | cmdragon's Blog
往期文章归档:
- 使用Tortoise-ORM和FastAPI构建评论系统 | cmdragon's Blog
- 分层架构在博客评论功能中的应用与实现 | cmdragon's Blog
- 深入解析事务基础与原子操作原理 | cmdragon's Blog
- 掌握Tortoise-ORM高级异步查询技巧 | cmdragon's Blog
- FastAPI与Tortoise-ORM实现关系型数据库关联 | cmdragon's Blog
- Tortoise-ORM与FastAPI集成:异步模型定义与实践 | cmdragon's Blog
- 异步编程与Tortoise-ORM框架 | cmdragon's Blog
- FastAPI数据库集成与事务管理 | cmdragon's Blog
- FastAPI与SQLAlchemy数据库集成 | cmdragon's Blog
- FastAPI与SQLAlchemy数据库集成与CRUD操作 | cmdragon's Blog
- FastAPI与SQLAlchemy同步数据库集成 | cmdragon's Blog
- SQLAlchemy 核心概念与同步引擎配置详解 | cmdragon's Blog
- FastAPI依赖注入性能优化策略 | cmdragon's Blog
- FastAPI安全认证中的依赖组合 | cmdragon's Blog
- FastAPI依赖注入系统及调试技巧 | cmdragon's Blog
- FastAPI依赖覆盖与测试环境模拟 | cmdragon's Blog
- FastAPI中的依赖注入与数据库事务管理 | cmdragon's Blog
- FastAPI依赖注入实践:工厂模式与实例复用的优化策略 | cmdragon's Blog
- FastAPI依赖注入:链式调用与多级参数传递 | cmdragon's Blog
- FastAPI依赖注入:从基础概念到应用 | cmdragon's Blog
- FastAPI中实现动态条件必填字段的实践 | cmdragon's Blog
- FastAPI中Pydantic异步分布式唯一性校验 | cmdragon's Blog
- 掌握FastAPI与Pydantic的跨字段验证技巧 | cmdragon's Blog
- FastAPI中的Pydantic密码验证机制与实现 | cmdragon's Blog
- 深入掌握FastAPI与OpenAPI规范的高级适配技巧 | cmdragon's Blog
- Pydantic字段元数据指南:从基础到企业级文档增强 | cmdragon's Blog
- Pydantic Schema生成指南:自定义JSON Schema | cmdragon's Blog
- Pydantic递归模型深度校验36计:从无限嵌套到亿级数据的优化法则 | cmdragon's Blog
- Pydantic异步校验器深:构建高并发验证系统 | cmdragon's Blog
- Pydantic根校验器:构建跨字段验证系统 | cmdragon's Blog
- Pydantic配置继承抽象基类模式 | cmdragon's Blog
- Pydantic多态模型:用鉴别器构建类型安全的API接口 | cmdragon's Blog
- FastAPI性能优化指南:参数解析与惰性加载 | cmdragon's Blog
- FastAPI依赖注入:参数共享与逻辑复用 | cmdragon's Blog
Tortoise-ORM级联查询与预加载性能优化的更多相关文章
- H5 缓存机制浅析 移动端 Web 加载性能优化
腾讯Bugly特约作者:贺辉超 1 H5 缓存机制介绍 H5,即 HTML5,是新一代的 HTML 标准,加入很多新的特性.离线存储(也可称为缓存机制)是其中一个非常重要的特性.H5 引入的离线存储, ...
- CSS加载性能优化
将首屏页面要用到的CSS文件,放在页面头部加载,其他模块的CSS可以使用异步加载:loadCSS 和 Preload. 关于preload,推进2篇文章给大家看下: 1.通过rel="pre ...
- React 16 加载性能优化指南
关于 React 应用加载的优化,其实网上类似的文章已经有太多太多了,随便一搜就是一堆,已经成为了一个老生常谈的问题. 但随着 React 16 和 Webpack 4.0 的发布,很多过去的优化手段 ...
- SPA 首屏加载性能优化之 vue-cli3 拆包配置
前言 现在已经是vue-cli3.x webpack4.x 的时代了,但是网上很多拆包配置还是一些比较低版本的. 本文主要是分享自己的拆包踩坑经验. 主要是用了webpack4 的 splitC ...
- ListView加载性能优化---ViewHolder---分页
ListView是Android中一个重要的组件,可以使用它加列表数据,用户可以自己定义列表数据,同时ListView的数据加载要借助Adapter,一般情况下要在Adapter类中重写getCoun ...
- [转]listview加载性能优化ViewHolder
当listview有大量的数据需要加载的时候,会占据大量内存,影响性能,这时候就需要按需填充并重新使用view来减少对象的创建. ListView加载数据都是在public View getView( ...
- android之 listview加载性能优化ViewHolder
在android开发中Listview是一个很重要的组件,它以列表的形式根据数据的长自适应展示具体内容,用户可以自由的定义listview每一列的布局,但当listview有大量的数据需要加载的时候, ...
- listview加载性能优化ViewHolder
在android开发中Listview是一个很重要的组件,它以列表的形式根据数据的长自适应展示具体内容,用户可以自由的定义listview每一列的布局, 但当listview有大量的数据需要加载的时候 ...
- 【JavaScript】页面加载性能优化
核心在于:减少加载时间 1.减少请求次数 2.缩减文件大小 3.异步加载---------------------->比如document.write 4.延迟加载.动态加载---------- ...
- listview加载性能优化
在android开发中Listview是一个很重要的组件,它以列表的形式根据数据的长自适应展示具体内容,用户可以自由的定义listview每一列的布局,但当listview有大量的数据需要加载的时候, ...
随机推荐
- 浅谈OpenStack(一)
本文分享自天翼云开发者社区<浅谈OpenStack(一)>,作者:EmmaDu OpenStack刚诞生的时候比较单纯,只有计算(NASA开源)和存储(Rackspace开源)两个功能组件 ...
- 让存储绿“翼”盎然,天翼云HBlock入选工信部目录!
近日,中国电信天翼云的自研产品HBlock凭借"存储资源盘活技术"成功入选<国家工业和信息化领域节能降碳技术装备推荐目录(2024年版)>(以下简称<目录> ...
- 俄罗斯方块-shell脚本写的,学习学习
#!/bin/bash APP_NAME="${0##*[\\/]}" APP_VERSION="1.0" #颜色定义 iSumColor=7 #颜色总数 cR ...
- SQL Server 2022新功能:将数据库备份到S3兼容的对象存储
SQL Server 2022新功能:将数据库备份到S3兼容的对象存储 本文介绍将S3兼容的对象存储用作数据库备份目标所需的概念.要求和组件. 数据库备份和恢复功能在概念上类似于使用SQL Serve ...
- 只需简单5步,Ansible脚本自动搭建AlwaysOn集群(已测试通过,可实际运行)
只需简单5步,Ansible脚本自动搭建AlwaysOn集群(已测试通过,可实际运行) 之前已经介绍过这套脚本,请看下面↓ 一分钟搞定!CentOS 7.9上用Ansible自动化部署SQL Serv ...
- 史陶比尔Stabli机器人维修小细节
在工业自动化领域,史陶比尔机器人以其卓越的性能和可靠性而著称.然而,即使是尖端的设备,也难免会遇到Stabli机械手故障和问题.对于机器人维护和修理,每一个小细节都显得至关重要. 一.观察 首先,我们 ...
- Java8 stream sorted排序时包括null
开发过程中对象集合根据某个属性排序是常常遇到的情况,但有时排序会遇到对应属性值为null的情况,会报空指针异常. 查找stream.sorted源码看到有Comparator.nullsFirst和C ...
- CentOS安装nginx服务器及配置反向代理
以下是在CentOS上安装nginx服务器并配置反向代理的步骤: 更新系统软件包: sudo yum update 安装nginx: sudo yum install nginx 启动nginx服务: ...
- docker - [10] 容器数据卷
将应用和环境打包成一个镜像,然后发布启动就成为一个容器了. 一.什么是容器数据卷 容器数据卷(Container Data Volumes)是Docker管理的一种特殊类型的存储区域,它为容器提供 ...
- Java01 - Scanner对象
简介 之前我们学的基本语法中并没有实现程序和人的交互,但是Java给我们提供了这样一个工具类,我们可以获取用户的输入.java.util.Scanner是Java5的新特征,我们可以通过Scanner ...