Excel百万数据如何快速导入?
前言
今天要讨论一个让无数人抓狂的话题:如何高效导入百万级Excel数据。
去年有家公司找到我,他们的电商系统遇到一个致命问题:每天需要导入20万条商品数据,但一执行就卡死,最长耗时超过3小时。
更魔幻的是,重启服务器后前功尽弃。
经过半天的源码分析,我们发现了下面这些触目惊心的代码...
1 为什么传统导入方案会崩盘?
很多小伙伴在实现Excel导入时,往往直接写出这样的代码:
// 错误示例:逐行读取+逐条插入
public void importExcel(File file) {
List<Product> list = ExcelUtils.readAll(file); // 一次加载到内存
for (Product product : list) {
productMapper.insert(product); // 逐行插入
}
}
这种写法会引发三大致命问题:
1.1 内存熔断:堆区OOM惨案
- 问题:POI的
UserModel(如XSSFWorkbook)一次性加载整个Excel到内存 - 实验:一个50MB的Excel(约20万行)直接耗尽默认的1GB堆内存
- 症状:频繁Full GC ➔ CPU飙升 ➔ 服务无响应
1.2 同步阻塞:用户等到崩溃
- 过程:用户上传文件 → 同步等待所有数据处理完毕 → 返回结果
- 风险:连接超时(HTTP默认30秒断开)→ 任务丢失
1.3 效率黑洞:逐条操作事务
- 实测数据:MySQL单线程逐条插入≈200条/秒 → 处理20万行≈16分钟
- 幕后黑手:每次insert都涉及事务提交、索引维护、日志写入
2 性能优化四板斧
第一招:流式解析
使用POI的SAX模式替代DOM模式:
// 正确写法:分段读取(以HSSF为例)
OPCPackage pkg = OPCPackage.open(file);
XSSFReader reader = new XSSFReader(pkg);
SheetIterator sheets = (SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
try (InputStream stream = sheets.next()) {
Sheet sheet = new XSSFSheet(); // 流式解析
RowHandler rowHandler = new RowHandler();
sheet.onRow(row -> rowHandler.process(row));
sheet.process(stream); // 不加载全量数据
}
}
️ 避坑指南:
- 不同Excel版本需适配(HSSF/XSSF/SXSSF)
- 避免在解析过程中创建大量对象,需复用数据容器
第二招:分页批量插入
基于MyBatis的批量插入+连接池优化:
// 分页批量插入(每1000条提交一次)
public void batchInsert(List<Product> list) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
ProductMapper mapper = sqlSession.getMapper(ProductMapper.class);
int pageSize = 1000;
for (int i = 0; i < list.size(); i += pageSize) {
List<Product> subList = list.subList(i, Math.min(i + pageSize, list.size()));
mapper.batchInsert(subList);
sqlSession.commit();
sqlSession.clearCache(); // 清理缓存
}
}
关键参数调优:
# MyBatis配置
mybatis.executor.batch.size=1000
# 连接池(Druid)
spring.datasource.druid.maxActive=50
spring.datasource.druid.initialSize=10
第三招:异步化处理
架构设计:
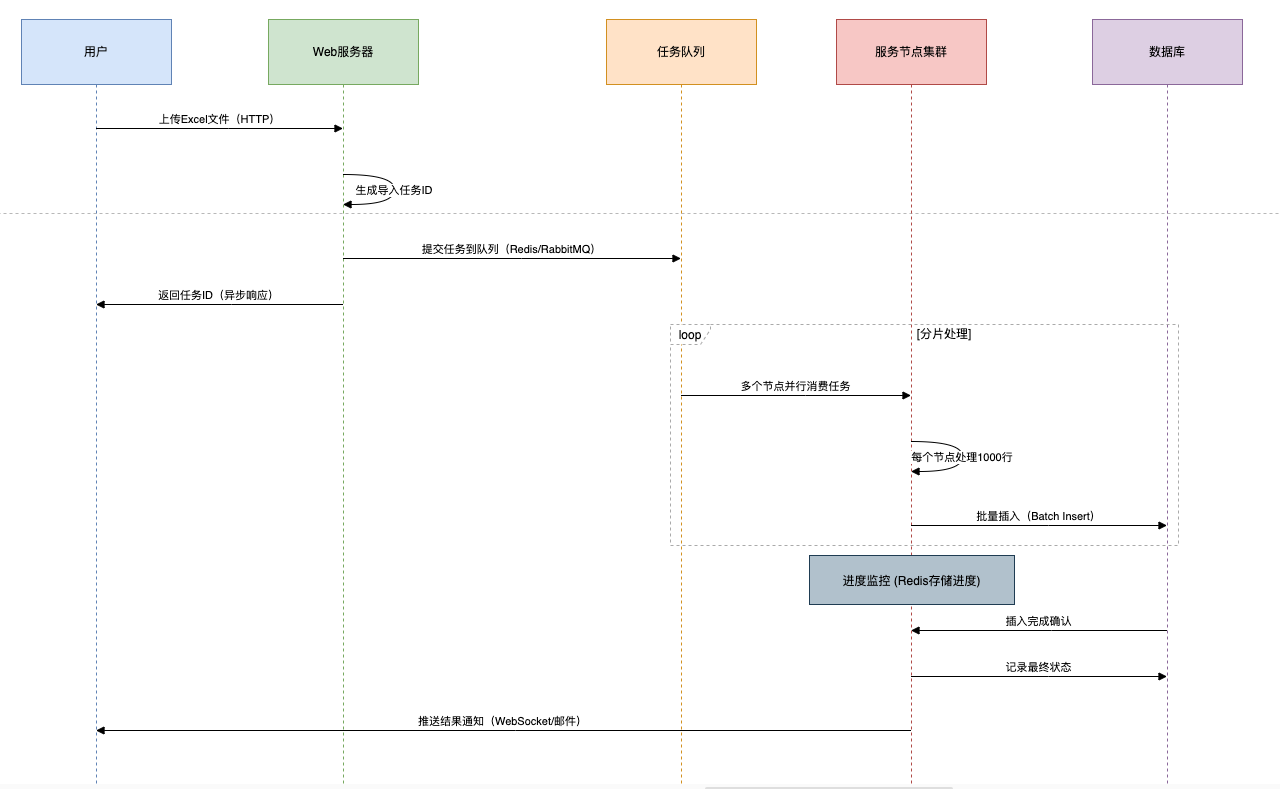
- 前端上传:客户端使用WebUploader等分片上传工具
- 服务端:
- 生成唯一任务ID
- 写入任务队列(Redis Stream/RabbitMQ)
- 异步线程池:
- 多线程消费队列
- 处理进度存储在Redis中
- 结果通知:通过WebSocket或邮件推送完成状态
第四招:并行导入
对于千万级数据,可采用分治策略:
| 阶段 | 操作 | 耗时对比 |
|---|---|---|
| 单线程 | 逐条读取+逐条插入 | 基准值100% |
| 批处理 | 分页读取+批量插入 | 时间降至5% |
| 多线程分片 | 按Sheet分片,并行处理 | 时间降至1% |
| 分布式分片 | 多节点协同处理(如Spring Batch集群) | 时间降至0.5% |
3 代码之外的关键经验
3.1 数据校验必须前置
典型代码缺陷:
// 错误:边插入边校验,可能污染数据库
public void validateAndInsert(Product product) {
if (product.getPrice() < 0) {
throw new Exception("价格不能为负");
}
productMapper.insert(product);
}
正确实践:
- 在流式解析阶段完成基础校验(格式、必填项)
- 入库前做业务校验(数据关联性、唯一性)
3.2 断点续传设计
解决方案:
- 记录每个分片的处理状态
- 失败时根据偏移量(offset)恢复
3.3 日志与监控
配置要点:
// Spring Boot配置Prometheus指标
@Bean
public MeterRegistryCustomizer<PrometheusMeterRegistry> metrics() {
return registry -> registry.config().meterFilter(
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return DistributionStatisticConfig.builder()
.percentiles(0.5, 0.95) // 统计中位数和95分位
.build().merge(config);
}
}
);
}
四、百万级导入性能实测对比
测试环境:
- 服务器:4核8G,MySQL 8.0
- 数据量:100万行x15列(约200MB Excel)
| 方案 | 内存峰值 | 耗时 | 吞吐量 |
|---|---|---|---|
| 传统逐条插入 | 2.5GB | 96分钟 | 173条/秒 |
| 分页读取+批量插入 | 500MB | 7分钟 | 2381条/秒 |
| 多线程分片+异步批量 | 800MB | 86秒 | 11627条/秒 |
| 分布式分片(3节点) | 300MB/节点 | 29秒 | 34482条/秒 |
总结
Excel高性能导入的11条军规:
- 决不允许全量加载数据到内存 → 使用SAX流式解析
- 避免逐行操作数据库 → 批量插入加持
- 永远不要让用户等待 → 异步处理+进度查询
- 横向扩展比纵向优化更有效 → 分片+分布式计算
- 内存管理是生死线 → 对象池+避免临时大对象
- 合理配置连接池参数 → 杜绝瓶颈在数据源
- 前置校验绝不动摇 → 脏数据必须拦截在入口
- 监控务必完善 → 掌握全链路指标
- 设计必须支持容灾 → 断点续传+幂等处理
- 抛弃单机思维 → 拥抱分布式系统设计
- 测试要覆盖极端场景 → 百万数据压测不可少
如果你正在为Excel导入性能苦恼,希望这篇文章能为你的系统打开一扇新的大门。
如果你有其他想了解的技术难题,欢迎在评论区留言!
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
Excel百万数据如何快速导入?的更多相关文章
- 图解JanusGraph系列 - 关于JanusGraph图数据批量快速导入的方案和想法(bulk load data)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- .net实现与excel的数据交互、导入导出
应该说,一套成熟的基于web的管理系统,与用户做好的excel表格进行数据交互是一个不可或缺的功能,毕竟,一切以方便客(jin)户(qian)为宗旨. 本人之前从事PHP的开发工作,熟悉PHP的都应该 ...
- Excel大数据量分段导入到Oracle
客户需要将一个具有2W多条数据的Excel表格中的数据导入到Oracle数据库的A表中,开始采用的是利用Oledb直接将数据读入到DataTable中,然后通过拼接InserInto语句来插入到数据库 ...
- java中使用POI+excel 实现数据的批量导入和导出
java web中使用POI实现excel文件的导入和导出 文件导出 //导入excle表 public String exportXls() throws IOException{ //1.查询所有 ...
- Excel表格数据导入MySQL数据库
有时候项目需要将存在表格中的批量数据导入数据库,最近自己正好碰到了,总结一下: 1.将excel表格另存为.csv格式文件,excel本身的.xlsx格式导入时可能会报错,为了避免不必要的格式错误,直 ...
- Mysql百万数据量级数据快速导入Redis
前言 随着系统的运行,数据量变得越来越大,单纯的将数据存储在mysql中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能 ...
- Py2neo:一种快速导入百万数据到Neo4j的方式
Py2neo:一种快速导入百万数据到Neo4j的方式 Py2neo是一个可以和Neo4j图数据库进行交互的python包.虽然py2neo操作简单方便,但是当节点和关系达几十上百万时,直接创建和导入节 ...
- [DJANGO] excel十几万行数据快速导入数据库研究
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- excel十几万行数据快速导入数据库研究(转,下面那个方法看看还是可以的)
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- SQL SERVER 与ACCESS、EXCEL的数据导入导出转换
* 说明:复制表(只复制结构,源表名:a 新表名:b) select * into b from a where 1<>1 * 说明:拷贝表(拷贝数据,源表名:a 目标表名:b) ...
随机推荐
- 前端面试100-copy
1.一些开放性题目 1.自我介绍:除了基本个人信息以外,面试官更想听的是你与众不同的地方和你的优势. 2.项目介绍 3.如何看待前端开发? 4.平时是如何学习前端开发的? 5.未来三到五年的规划是怎样 ...
- 第十二章 ArrayList&LinkedList源码解析
一.对于ArrayList需要掌握的七点内容 ArrayList的创建:即构造器 往ArrayList中添加对象:即add(E)方法 获取ArrayList中的单个对象:即get(int index) ...
- Calendar日历类(抽象类)的使用
4. java.util.Calendar( 日历)类 类 Calendar是一个抽象基类,主用用于完成日期字段之间相互操作的功能. 获取Calendar实例的方法 使用Calendar.get ...
- Delphi中IdHttp组件异常非200获取返回JSON数据
参考原文:https://www.atozed.com/forums/thread-771.html?highlight=400+Bad+Request 另外还有一篇文章说明也可参考 http://w ...
- JMeter非GUI模式执行,jtl文件请求与响应数据为空?这里有答案!
JMeter非GUI模式执行,jtl文件请求与响应数据为空?这里有答案! 问题描述 在使用JMeter进行性能测试时,很多用户会选择非GUI(图形用户界面)模式来执行测试,因为这样可以减少客户端的负担 ...
- C#下.NET配置文件的使用(1)
原文链接:https://blog.csdn.net/dbzhang800/article/details/7212420 System.Configuration 命名空间中的东西是为读写应用程序的 ...
- day:3软件测试分类
一.按开发阶段划分 (1)单元测试 (2)集成测试 (3)系统测试 (4)验收测试 二.按查看代码分类 (1)黑盒测试 定义:是一种功能测试,测试中把测试的软件当成一个盒子,不关心盒子内部结构是什么, ...
- [JOISC 2023 Day3] Tourism 题解
大家好,我喜欢珂朵莉树,所以我用珂朵莉树 \(AC\) 了本题. 实际上,我们比较容易发现,这题实际上就是求 \([l,r]\) 中的所有点作为关键点时,虚树所压缩的所有点(实际上就是显现出来的点+在 ...
- Arduino语法--数据类型
Arduino与C语言类似,有多种数据类型.数据类型在数据结构中的定义是一个值的集合,以及定义在这个值集上的一组操作,各种数据类型需要在特定的地方使用.一般来说,变量的数据类型决定了如何将代表这些值的 ...
- 小米10至尊纪念版—官方稳定版一键 TWRE刷入+面具ROOT
1.解锁BL http://www.miui.com/unlock/index.html 2.备份+关机(虽然不会清理数据,但是小心为上) 3.音量下+开机进入fastboot模式 4.解压压缩包,运 ...