Java开发AI项目,太爽了!LangChain4j保姆级教程
大家好,我是程序员鱼皮。现在 AI 应用开发可以说是程序员必备的技能了,求职时能够大幅增加竞争力。之前我用 Spring AI 带大家做过一个 开源的 AI 超级智能体项目,这次我来带大家快速掌握另一个主流的 Java AI 应用开发框架 LangChain4j。
这个教程也是我精心设计,拒绝枯燥的理论,而是用一个编程小助手项目带大家在实战中依次学习 LangChain 几乎所有主流的用法和特性。看完这个教程,你不仅学会了 LangChain,还直接多了一段项目经历,岂不美哉?
文章近一万字,有点长,建议收藏,观看视频版体验更佳~
需求分析
我们要实现一个 AI 编程小助手,可以帮助用户答疑解惑,并且给出编程学习的指导建议,比如:
编程学习路线
项目学习建议
程序员求职指南
程序员常见面试题

要实现这个需求,我们首先要能够调用 AI 完成 基础对话,而且要支持实现 多轮对话记忆。此外,如果想进一步增强 AI 的能力,需要让它能够 使用工具 来联网搜索内容;还可以让 AI 基于我们自己的 知识库回答,给用户提供我们在编程领域沉淀的资源和经验。

如果要从 0 开始实现上述功能,还是很麻烦的,因此我们要使用 AI 开发框架来提高效率。
什么是 LangChain4j?
目前主流的 Java AI 开发框架有 Spring AI 和 LangChain4j,它们都提供了很多 开箱即用的 API 来帮你调用大模型、实现 AI 开发常用的功能,比如我们今天要学的:
对话记忆
结构化输出
RAG 知识库
工具调用
MCP
SSE 流式输出
就我个人体验下来,这两个框架的很多概念和用法都是类似的,也都提供了很多插件扩展,都支持和 Spring Boot 项目集成。虽然有一些编码上的区别,但孰好孰坏,使用感受也是因人而异的。
实际开发中应该如何选择呢?
我想先带你用 LangChain4j 开发完一个项目,最后再揭晓答案,因为那个时候你自己也会有一些想法。
AI 应用开发
新建项目
打开 IDEA 开发工具,新建一个 Spring Boot 项目,Java 版本选择 21(因为 LangChain4j 最低支持 17 版本):
选择依赖,使用 3.5.x 版本的 Spring Boot,引入 Spring MVC 和 Lombok 注解库:

新建项目后,先修改配置文件后缀为 yml,便于后面填写配置。
这里我会建议大家创建一个 application-local.yml 配置文件,将开发时用到的敏感配置写到这里,并且添加到 .gitignore 中,防止不小心开源出来。
AI 对话 - ChatModel
ChatModel 是最基础的概念,负责和 AI 大模型交互。
首先需要引入至少一个 AI 大模型依赖,这里选择国内的阿里云大模型,提供了和 Spring Boot 项目的整合依赖包,比较方便:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
需要到 阿里云百炼平台 获取大模型调用 key,注意不要泄露!
回到项目,在配置文件中添加大模型配置,指定模型名称和 API Key:
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <You API Key here>
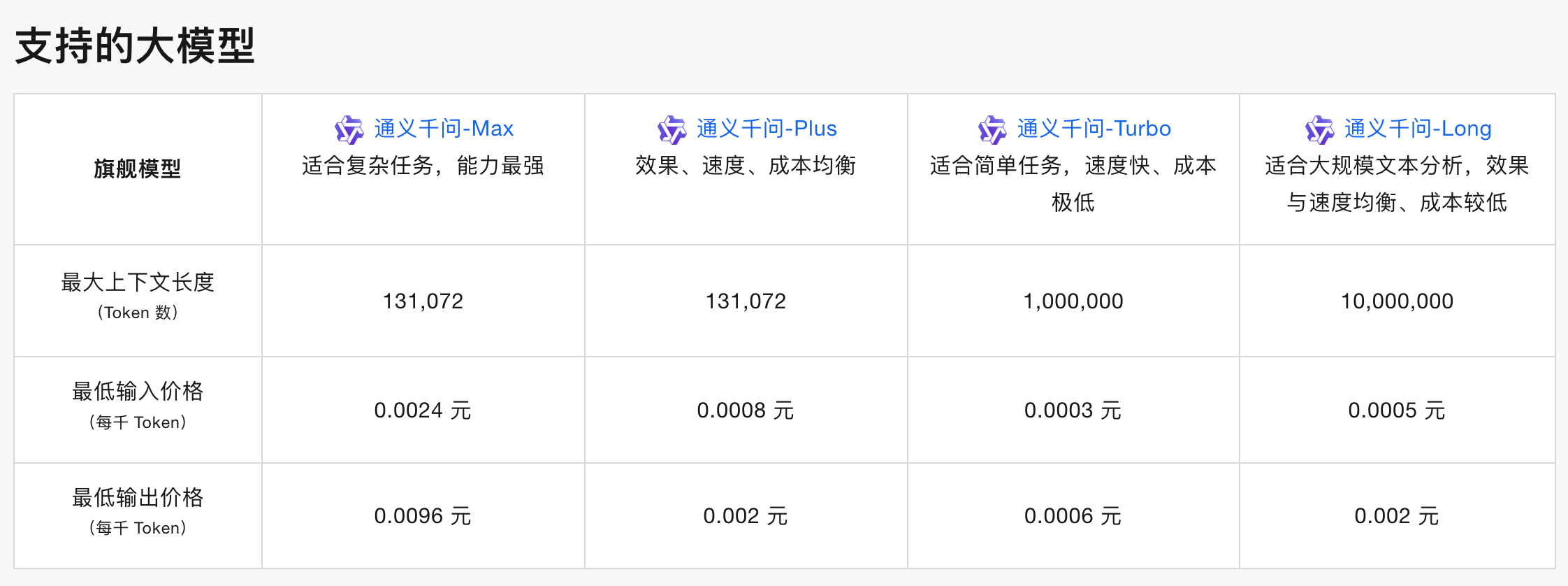
可以 按需选择模型名称,追求效果可以用 qwen-max,否则可以选择效果、速度、成本均衡的 qwen-plus。
除了编写配置让 Spring Boot 自动构建 ChatModel 外,也可以通过构造器自己创建 ChatModel 对象。这种方式更灵活,在 LangChain4j 中我们会经常用到这种方式来构造对象。
ChatModel qwenModel = QwenChatModel.builder()
.apiKey("You API key here")
.modelName("qwen-max")
.enableSearch(true)
.temperature(0.7)
.maxTokens(4096)
.stops(List.of("Hello"))
.build();
有了 ChatModel 后,创建一个 AiCodeHelper 类,引入自动注入的 qwenChatModel,编写简单的对话代码,并利用 Lombok 注解打印输出结果日志:
@Service
@Slf4j
public class AiCodeHelper {
@Resource
private ChatModel qwenChatModel;
public String chat(String message) {
UserMessage userMessage = UserMessage.from(message);
ChatResponse chatResponse = qwenChatModel.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
}
编写单元测试,向 AI 打个招呼吧:
@SpringBootTest
class AiCodeHelperTest {
@Resource
private AiCodeHelper aiCodeHelper;
@Test
void chat() {
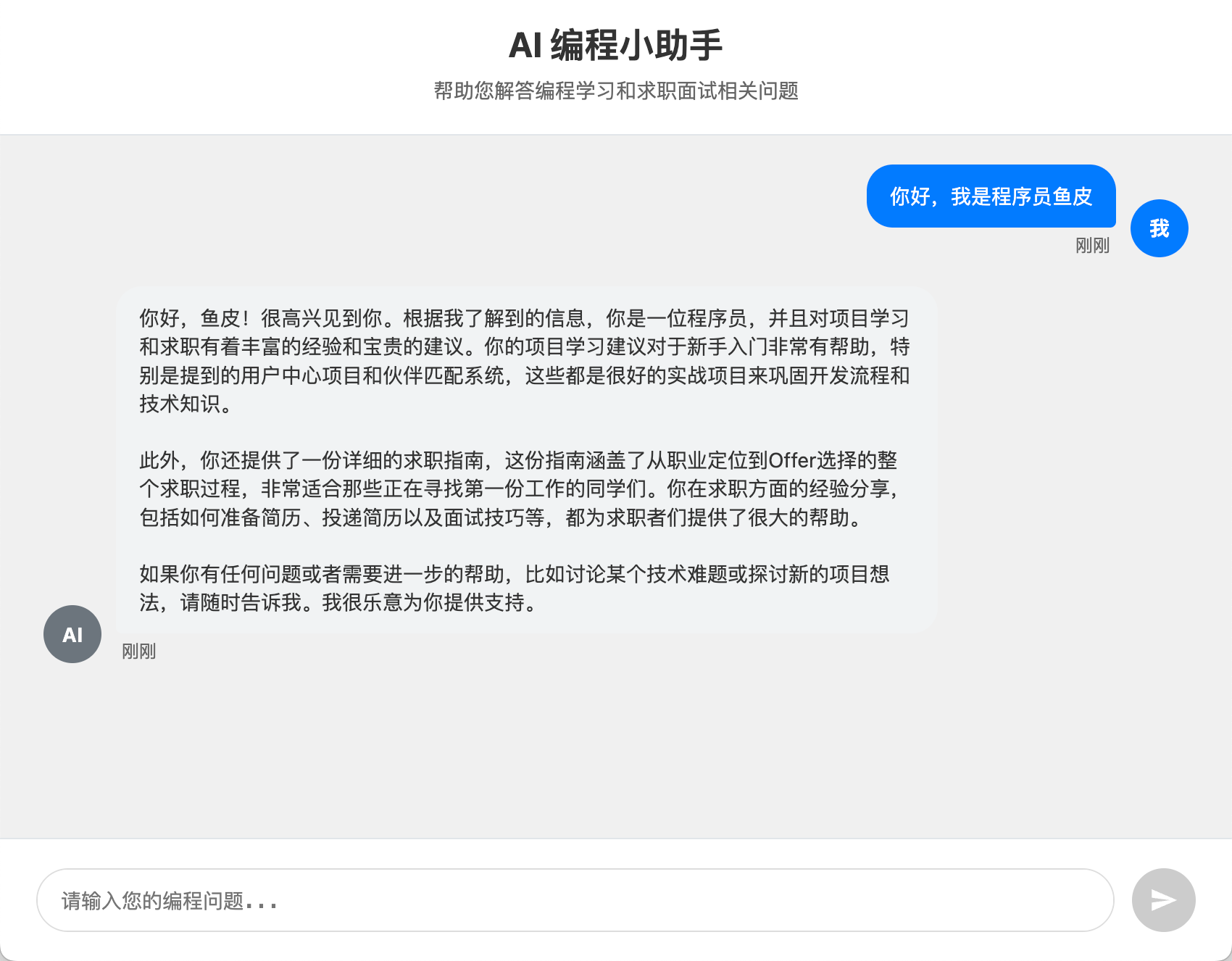
aiCodeHelper.chat("你好,我是程序员鱼皮");
}
}
以 Debug 模式运行单元测试,成功运行并查看输出:

如果遇到找不到符号的 lombok 报错:
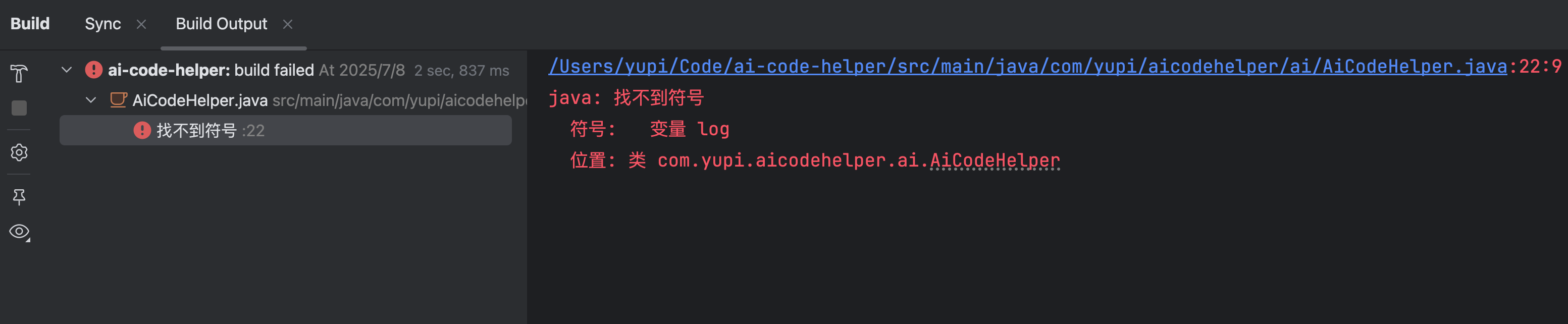 可以修改 IDEA 的注解处理器配置,改为使用项目中的 lombok:
可以修改 IDEA 的注解处理器配置,改为使用项目中的 lombok:
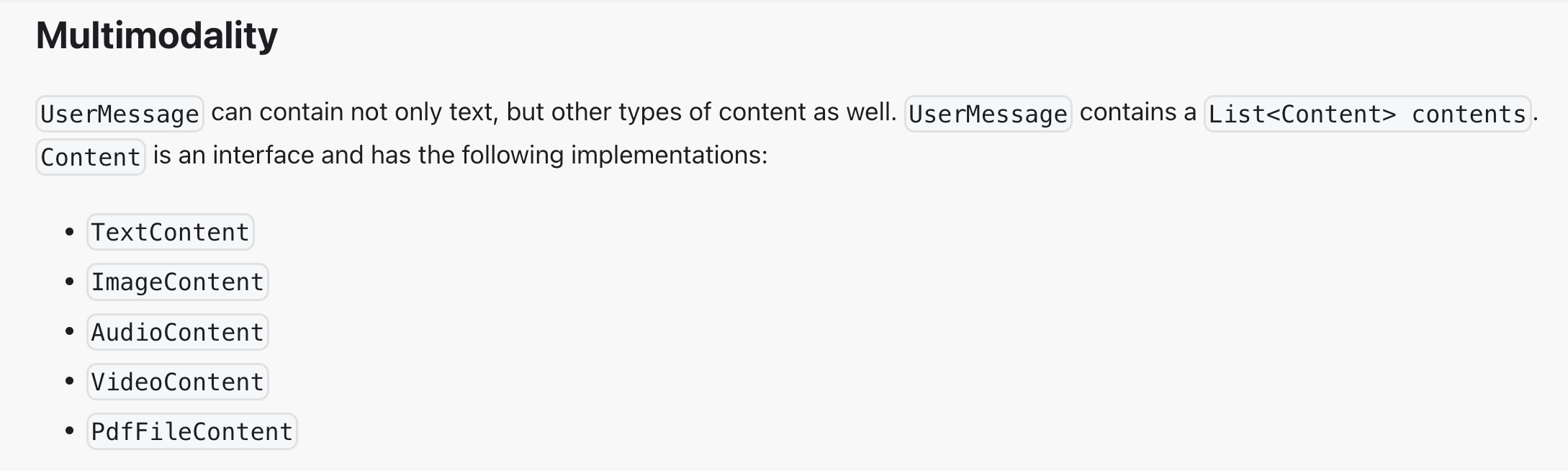
多模态 - Multimodality
多模态是指能够同时处理、理解和生成多种不同类型数据的能力,比如文本、图像、音频、视频、PDF 等等。

LangChain4j 中使用多模态的方法很简单,用户消息中是可以添加图片、音视频、PDF 等媒体资源的。
我们先编写一个支持传入自定义 UserMessage 的方法:
public String chatWithMessage(UserMessage userMessage) {
ChatResponse chatResponse = qwenChatModel.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
然后编写单元测试,传入一张图片:
@Test
void chatWithMessage() {
UserMessage userMessage = UserMessage.from(
TextContent.from("描述图片"),
ImageContent.from("https://www.codefather.cn/logo.png")
);
aiCodeHelper.chatWithMessage(userMessage);
}
但是效果不理想,qwen-max 模型无法直接查看或分析图片:
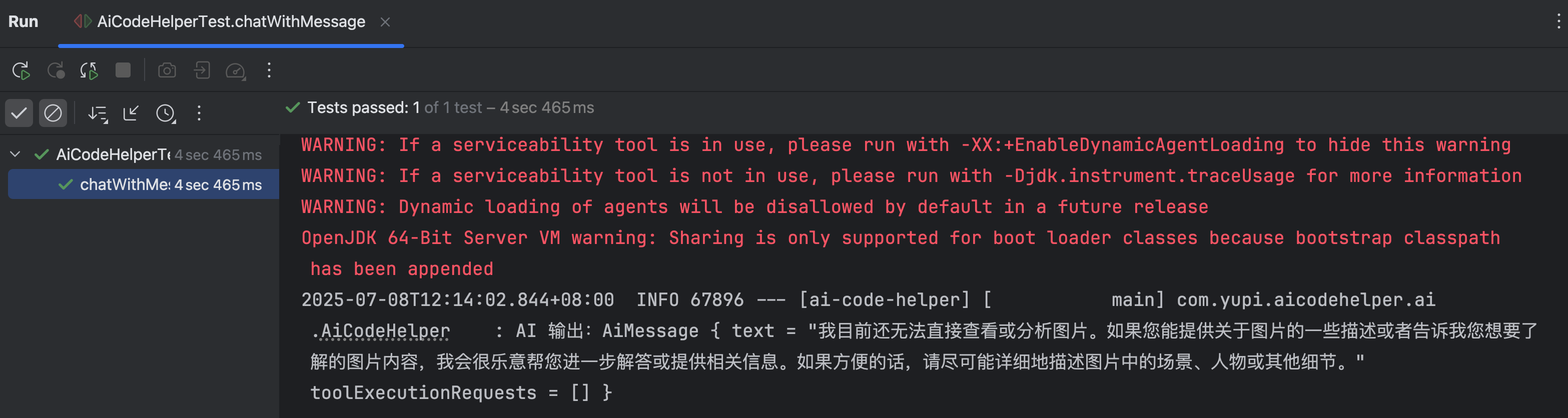
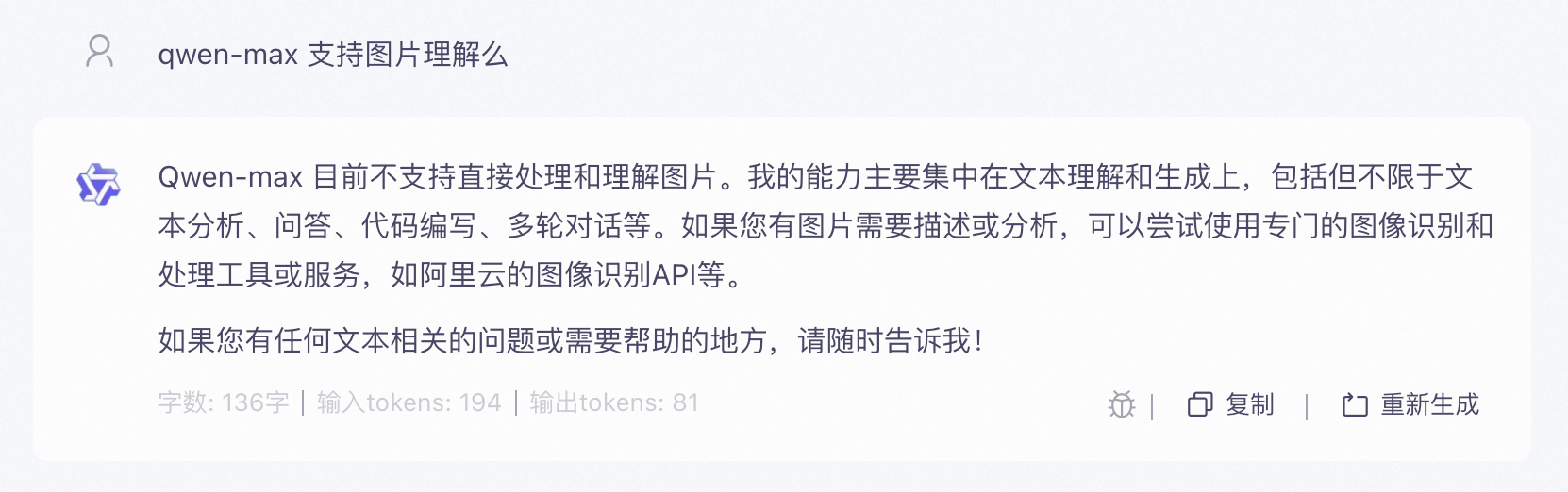
这也是目前多模态开发最关键的问题,虽然编码不难,但需要大模型本身支持多模态。可以在 LangChain 官网看到 大模型能力支持表,不过一切以实际测试为准。
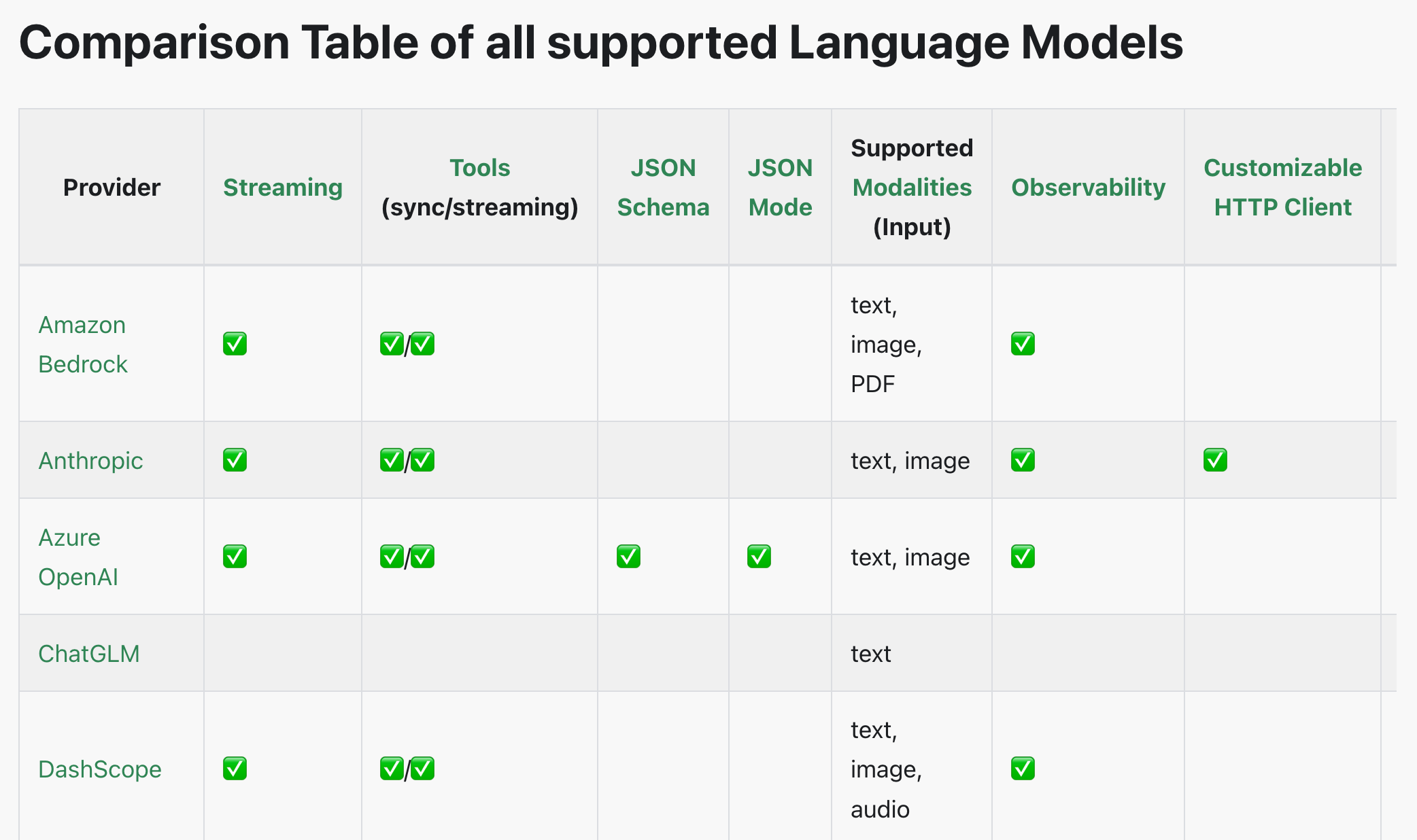
目前框架对多模态的适配度也没有那么好,一不留神就报错了,所以我们先了解这种用法就好了,感兴趣的同学也可以用 OpenAI 等其他模型实现多模态。
系统提示词 - SystemMessage
系统提示词是设置 AI 模型行为规则和角色定位的隐藏指令,用户通常不能直接看到。系统 Prompt 相当于给 AI 设定人格和能力边界,也就是告诉 AI “你是谁?你能做什么?”。
根据我们的需求,编写一段系统提示词:
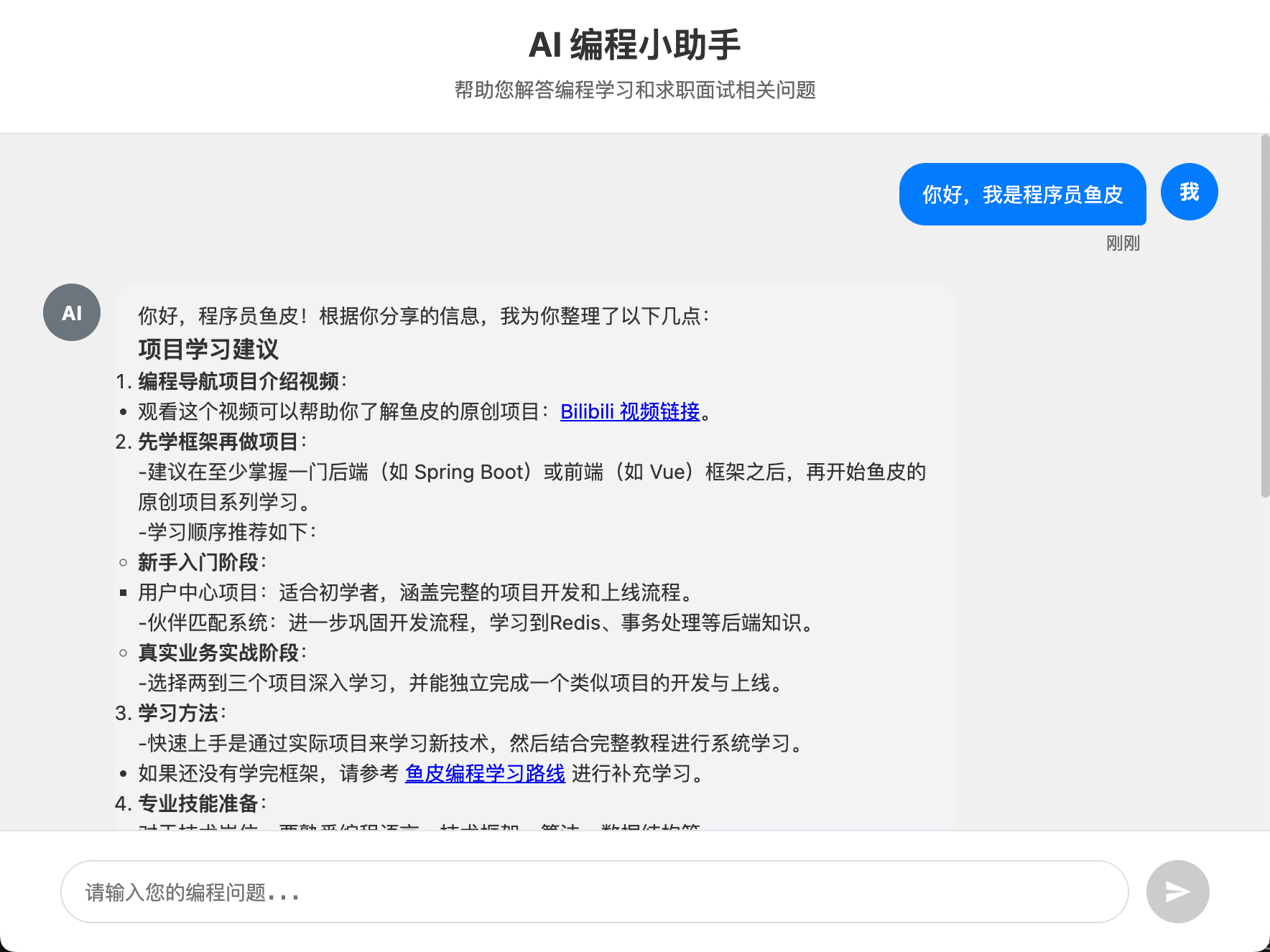
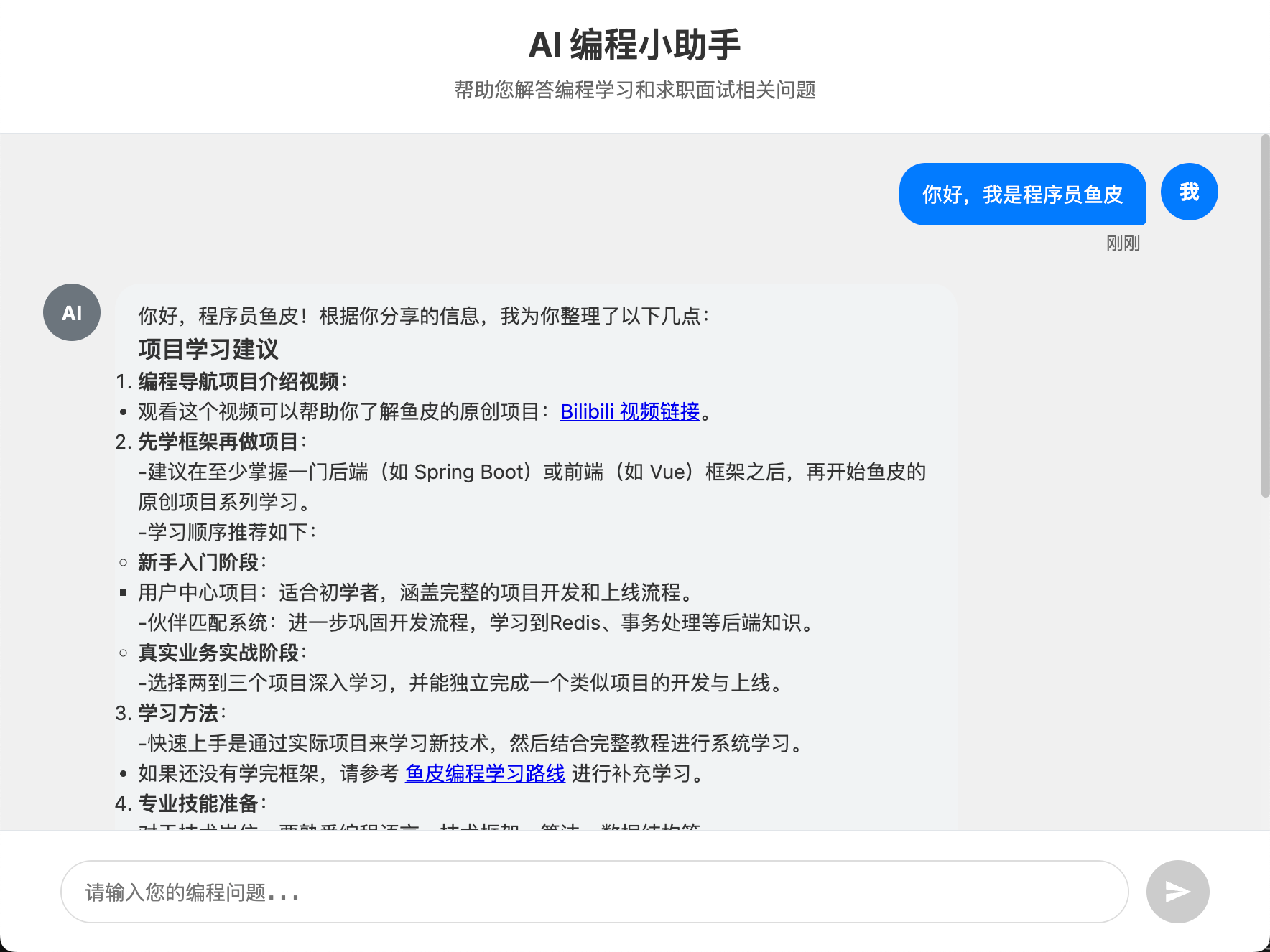
你是编程领域的小助手,帮助用户解答编程学习和求职面试相关的问题,并给出建议。重点关注 4 个方向:
1. 规划清晰的编程学习路线
2. 提供项目学习建议
3. 给出程序员求职全流程指南(比如简历优化、投递技巧)
4. 分享高频面试题和面试技巧
请用简洁易懂的语言回答,助力用户高效学习与求职。
编程导航的同学可以看 AI 超级智能体项目第 3 期,有讲解过提示词优化技巧。

想要使用系统提示词,最直接的方法是创建一个系统消息,把它和用户消息一起发送给 AI。
修改 chat 方法,代码如下:
private static final String SYSTEM_MESSAGE = """
你是编程领域的小助手,帮助用户解答编程学习和求职面试相关的问题,并给出建议。重点关注 4 个方向:
1. 规划清晰的编程学习路线
2. 提供项目学习建议
3. 给出程序员求职全流程指南(比如简历优化、投递技巧)
4. 分享高频面试题和面试技巧
请用简洁易懂的语言回答,助力用户高效学习与求职。
""";
public String chat(String message) {
SystemMessage systemMessage = SystemMessage.from(SYSTEM_MESSAGE);
UserMessage userMessage = UserMessage.from(message);
ChatResponse chatResponse = qwenChatModel.chat(systemMessage, userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
再次运行单元测试和 AI 对话,显然系统预设生效了:
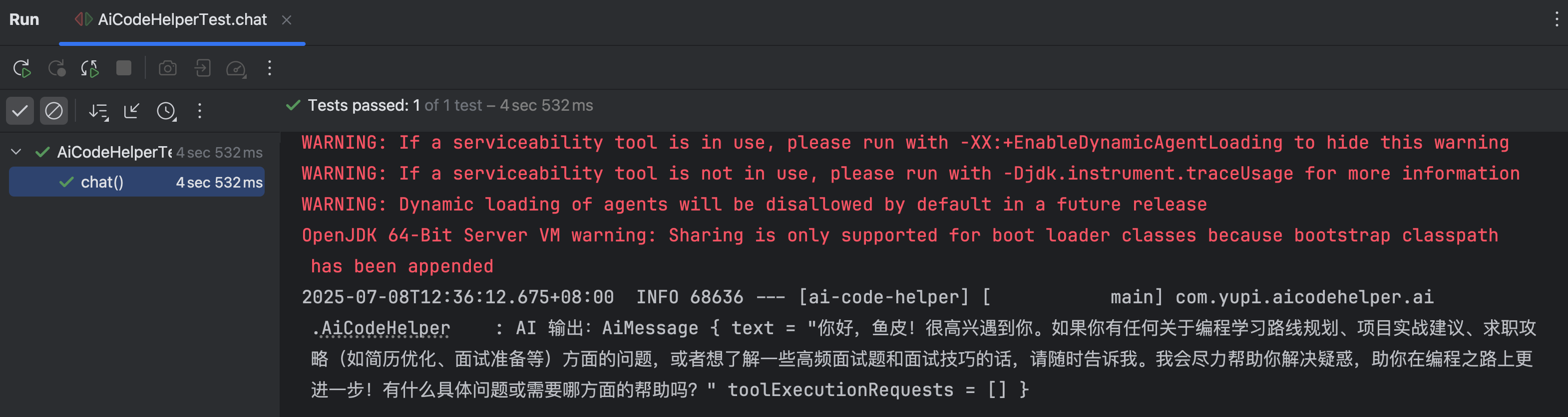
AI 服务 - AI Service
在学习更多特性前,我们要了解 LangChain4j 最重要的开发模式 —— AI Service,提供了很多高层抽象的、用起来更方便的 API,把 AI 应用当做服务来开发。
使用 AI Service
首先引入 langchain4j 依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
然后创建一个编程助手 AI Service 服务,采用声明式开发方法,编写一个对话方法,然后可以直接通过 @SystemMessage 注解定义系统提示词。
public interface AiCodeHelperService {
@SystemMessage("你是一位编程小助手")
String chat(String userMessage);
}
不过由于我们提示词较长,写到注解里很不优雅,所以单独在 resources 目录下新建文件 system-prompt.txt 来存储系统提示词。
@SystemMessage 注解支持从文件中读取系统提示词:
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
}
然后我们需要编写工厂类,用于创建 AI Service:
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
return AiServices.create(AiCodeHelperService.class, qwenChatModel);
}
}
调用 AiServices.create 方法就可以创建出 AI Service 的实现类了,背后的原理是利用 Java 反射机制创建了一个实现接口的代理对象,代理对象负责输入和输出的转换,比如把 String 类型的用户消息参数转为 UserMessage 类型并调用 ChatModel,再将 AI 返回的 AiMessage 类型转换为 String 类型作为返回值。
但我们不用关心这么多,直接写接口和注解来开发就好。你喜欢这种开发方式么?
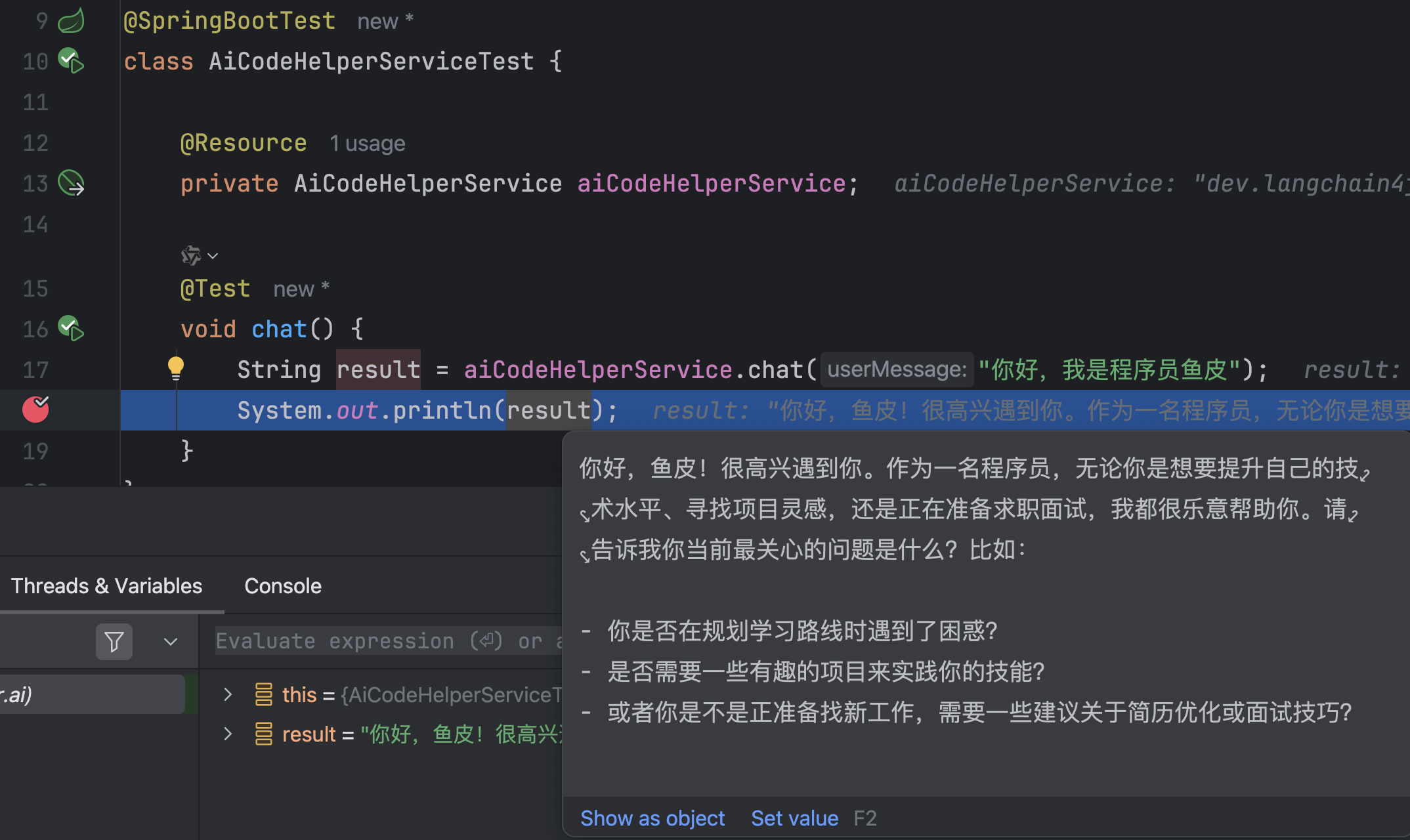
编写单元测试,调用我们开发的 AI Service:
@SpringBootTest
class AiCodeHelperServiceTest {
@Resource
private AiCodeHelperService aiCodeHelperService;
@Test
void chat() {
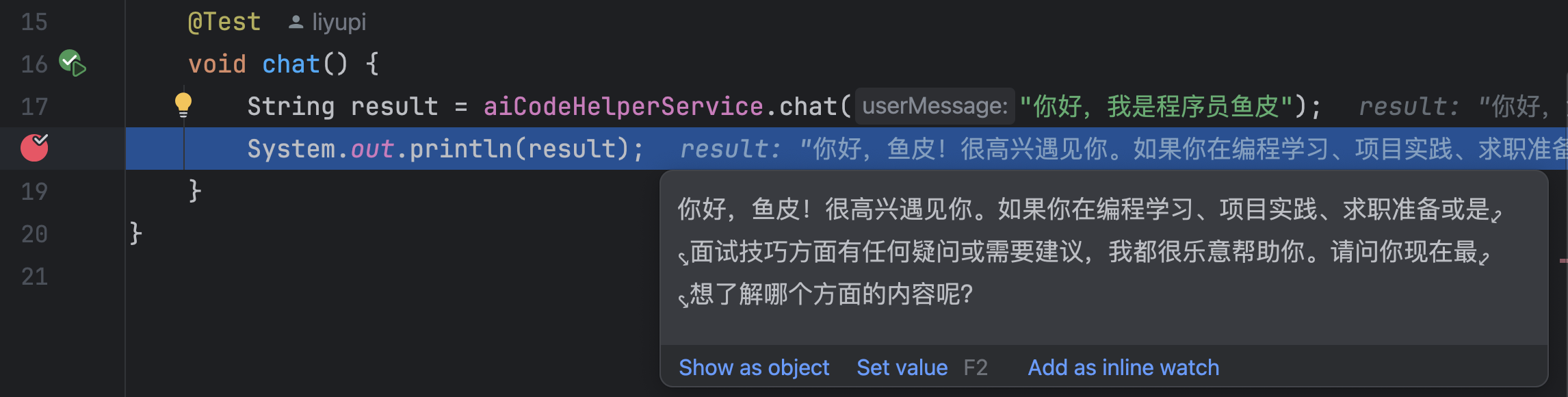
String result = aiCodeHelperService.chat("你好,我是程序员鱼皮");
System.out.println(result);
}
}
Debug 运行,发现生成了 AI Service 的代理类,并且系统提示词生效了。是不是比之前自己拼接系统消息要方便多了?
Spring Boot 项目中使用
如果你觉得手动调用 create 方法来创建 Service 比较麻烦,在 Spring Boot 项目中可以引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
然后给 AI Service 加上 @AiService 注解,就能自动创建出服务实例了:
@AiService
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
}
记得注释掉之前工厂类的 @Configuration 注解,否则会出现 Bean 冲突
再次运行单元测试,也是可以正常对话的:
这种方式虽然更方便了,但是缺少了自主构建的灵活性(可以自由设置很多参数),所以我建议还是采用自主构建。之后的功能特性,我们也会基于这种 AI Service 开发模式来实现。
会话记忆 - ChatMemory
会话记忆是指让 AI 能够记住用户之前的对话内容,并保持上下文连贯性,这是实现 AI 应用的核心特性。
怎么实现对话记忆?最传统的方式是自己维护消息列表,不仅要手动添加消息,消息多了还要考虑淘汰、不同用户的消息还要隔离,想想都头疼!
// 自己实现会话记忆
Map<String, List<Message>> conversationHistory = new HashMap<>();
public String chat(String message, String userId) {
// 获取用户历史记录
List<Message> history = conversationHistory.getOrDefault(userId, new ArrayList<>());
// 添加用户新消息
Message userMessage = new Message("user", message);
history.add(userMessage);
// 构建完整历史上下文
StringBuilder contextBuilder = new StringBuilder();
for (Message msg : history) {
contextBuilder.append(msg.getRole()).append(": ").append(msg.getContent()).append("\n");
}
// 调用 AI API
String response = callAiApi(contextBuilder.toString());
// 保存 AI 回复到历史
Message aiMessage = new Message("assistant", response);
history.add(aiMessage);
conversationHistory.put(userId, history);
return response;
}
使用会话记忆
LangChain4j 为我们提供了开箱即用的 MessageWindowChatMemory 会话记忆,最多保存 N 条消息,多余的会自动淘汰。创建会话记忆后,在构造 AI Service 设置 chatMemory:
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
// 会话记忆
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.build();
return aiCodeHelperService;
}
}
编写单元测试,测试会话记忆是否生效:
@Test
void chatWithMemory() {
String result = aiCodeHelperService.chat("你好,我是程序员鱼皮");
System.out.println(result);
result = aiCodeHelperService.chat("你好,我是谁来着?");
System.out.println(result);
}
Debug 运行单元测试,可以看到会话记忆存储的消息列表:
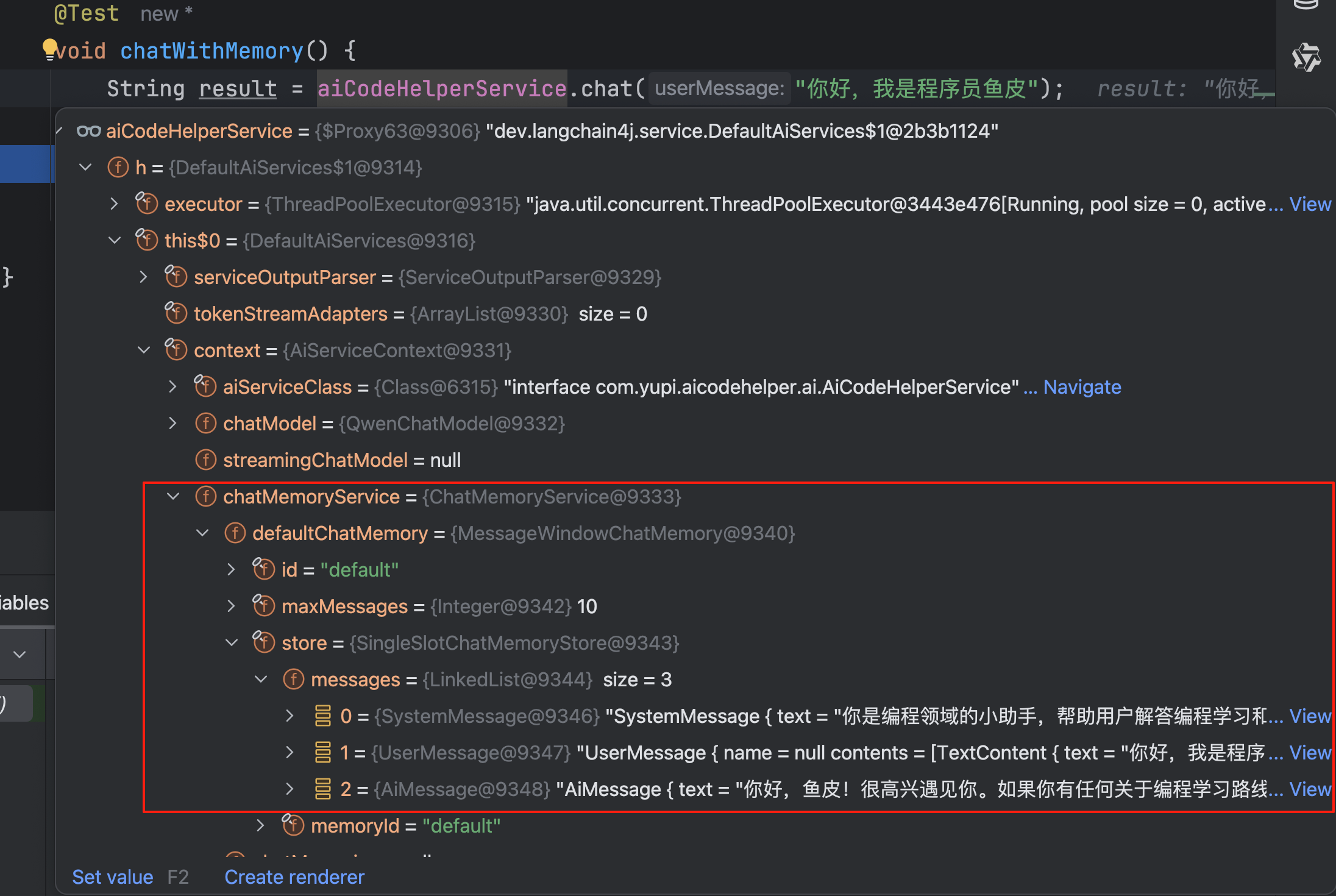
查看输出结果,会话记忆生效:

进阶用法
会话记忆默认是存储在内存的,重启后会丢失,可以通过自定义 ChatMemoryStore 接口的实现类,将消息保存到 MySQL 等其他数据源中。

如果有多个用户,希望每个用户之间的消息隔离,可以通过给对话方法增加 memoryId 参数和注解,在调用对话时传入 memoryId 即可(类似聊天室的房间号):
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
构造 AI Service 时,可以通过 chatMemoryProvider 来指定 每个 memoryId 单独创建会话记忆:
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.build();
结构化输出
结构化输出是指将大模型返回的文本输出转换为结构化的数据格式,比如一段 JSON、一个对象、或者是复杂的对象列表。
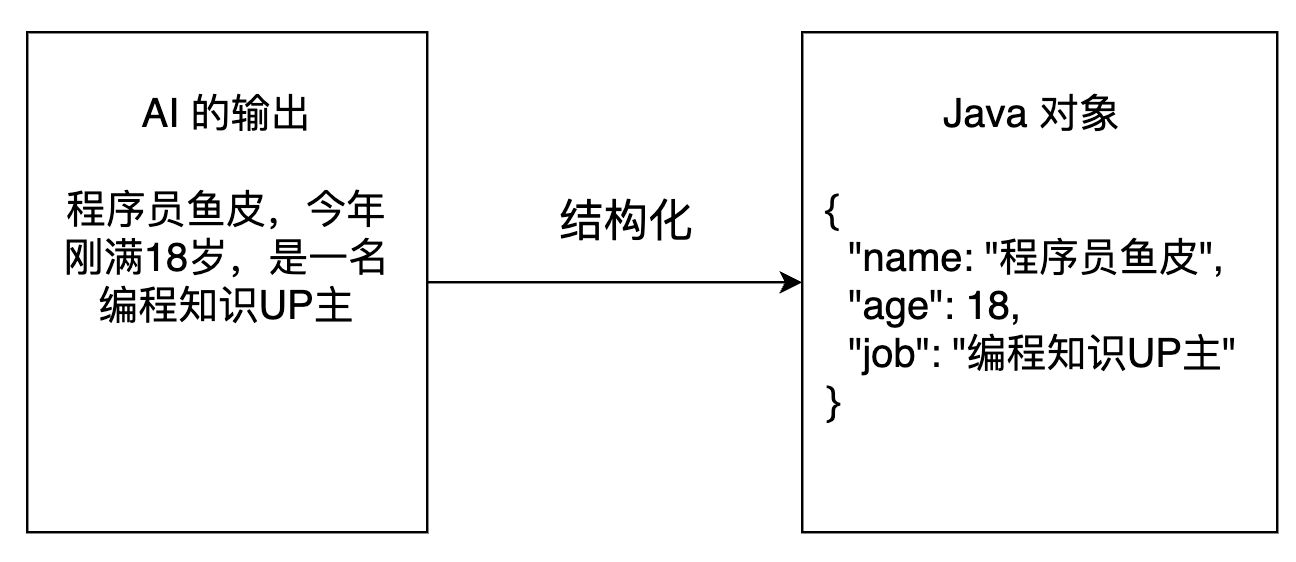
结构化输出有 3 种实现方式:
利用大模型的 JSON schema
利用 Prompt + JSON Mode
利用 Prompt
默认是 Prompt 模式,也就是在原本的用户提示词下 拼接一段内容 来指定大模型强制输出包含特定字段的 JSON 文本。
你是一个专业的信息提取助手。请从给定文本中提取人员信息,
并严格按照以下 JSON 格式返回结果:
{
"name": "人员姓名",
"age": 年龄数字,
"height": 身高(米),
"married": true/false,
"occupation": "职业"
}
重要规则:
1. 只返回 JSON 格式,不要添加任何解释
2. 如果信息不明确,使用 null
3. age 必须是数字,不是字符串
4. married 必须是布尔值
感兴趣的同学可以 阅读这篇文章 了解更多,不过我们开发时无需关心这些,只要修改对话方法的返回值,框架就会自动帮我们实现结构化输出,非常爽!
比如我们增加一个 让 AI 生成学习报告 的方法,AI 需要输出学习报告对象,包含名称和建议列表:
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
// 学习报告
record Report(String name, List<String> suggestionList){}
编写单元测试:
@Test
void chatForReport() {
String userMessage = "你好,我是程序员鱼皮,学编程两年半,请帮我制定学习报告";
AiCodeHelperService.Report report = aiCodeHelperService.chatForReport(userMessage);
System.out.println(report);
}
运行单元测试,效果很不错:
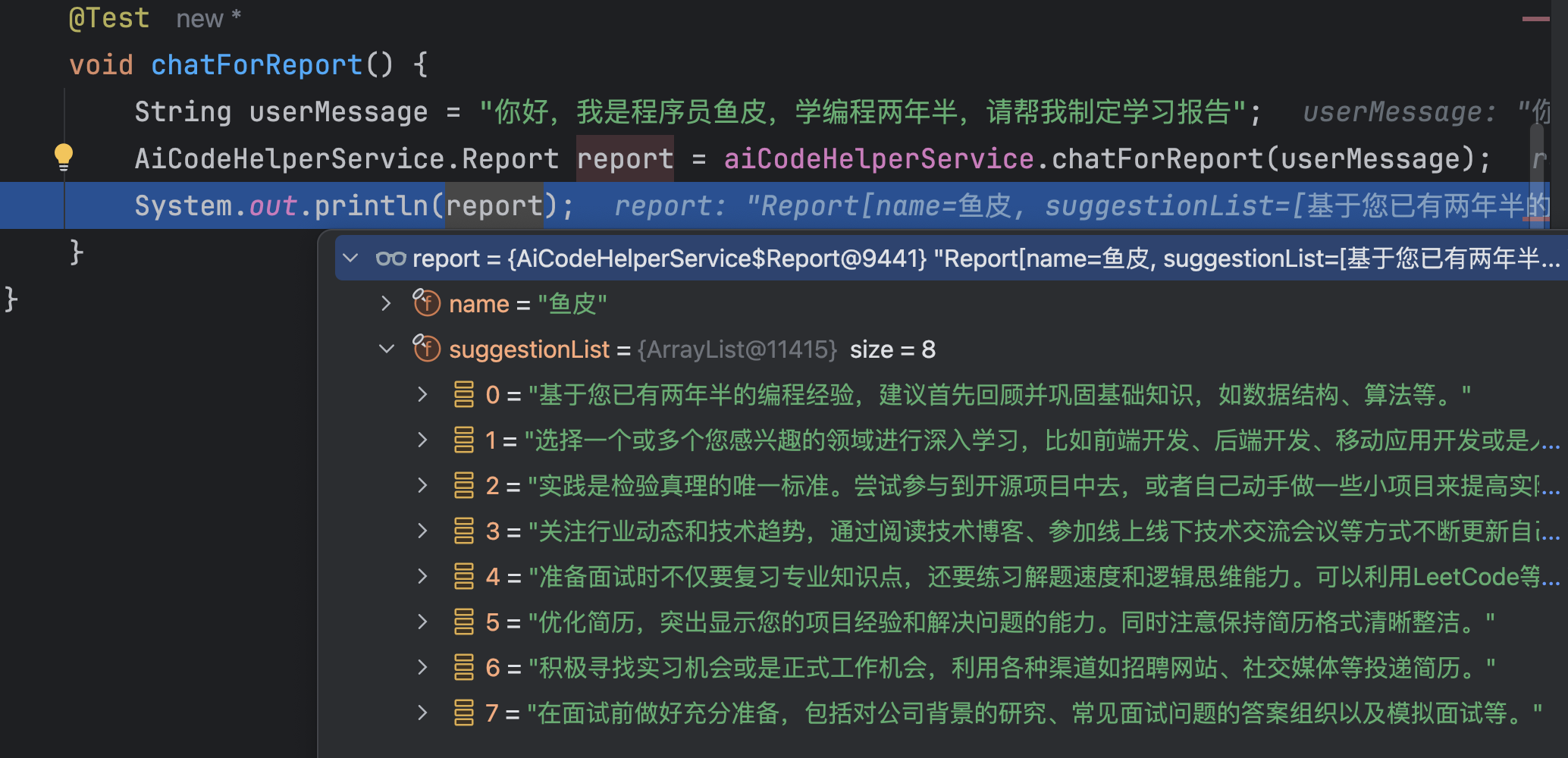
如果你发现 AI 有时无法生成准确的 JSON,那么可以采用 JSON Schema 模式,直接在请求中约束 LLM 的输出格式。这是目前最可靠、精确度最高的结构化输出实现。
ResponseFormat responseFormat = ResponseFormat.builder()
.type(JSON)
.jsonSchema(JsonSchema.builder()
.name("Person")
.rootElement(JsonObjectSchema.builder()
.addStringProperty("name")
.addIntegerProperty("age")
.addNumberProperty("height")
.addBooleanProperty("married")
.required("name", "age", "height", "married")
.build())
.build())
.build();
ChatRequest chatRequest = ChatRequest.builder()
.responseFormat(responseFormat)
.messages(userMessage)
.build();
检索增强生成 - RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 AI 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
简单来说,RAG 就像给 AI 配了一个 “小抄本”,让 AI 回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。很多企业也基于 RAG 搭建了自己的智能客服,可以用自己积累的领域知识回复用户。
RAG 的完整工作流程如下:
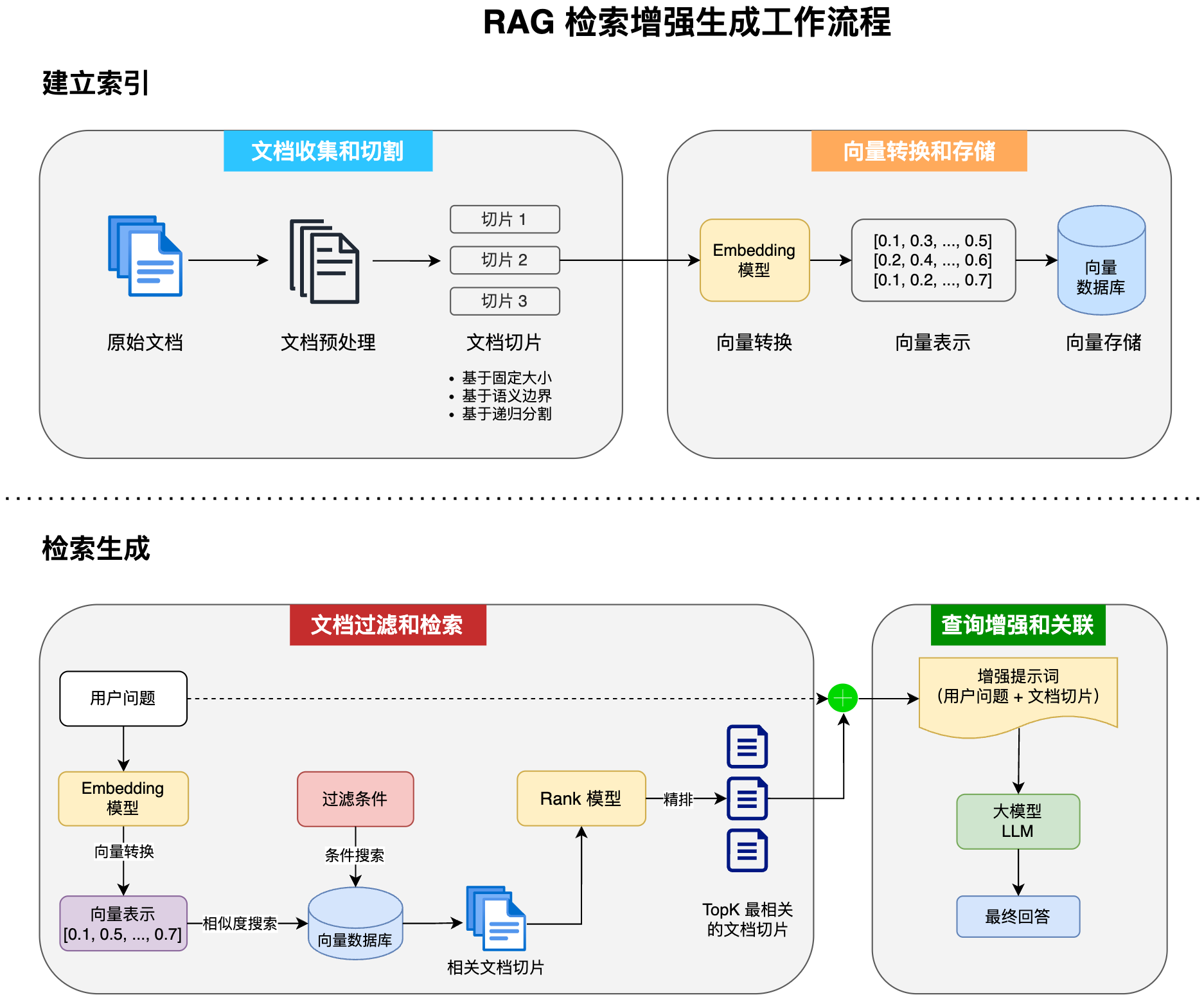
让我们来实操一下,首先我准备了 4 个文档,放在了 resources/docs 目录下:

LangChain 提供了 3 种 RAG 的实现方式,我把它称为:极简版、标准版、进阶版。
极简版 RAG
极简版适合快速查看效果,首先需要引入额外的依赖,里面包含了内置的离线 Embedding 模型,开箱即用:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.1.0-beta7</version>
</dependency>
示例代码如下,使用内置的文档加载器读取文档,然后利用内置的 Embedding 模型将文档转换成向量,并存储在内置的 Embedding 内存存储中,最后给 AI Service 绑定默认的内容检索器。
// RAG
// 1. 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
// 2. 使用内置的 EmbeddingModel 转换文本为向量,然后存储到自动注入的内存 embeddingStore 中
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
// RAG:从内存 embeddingStore 中检索匹配的文本片段
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
可以看到,极简版的特点是 “一切皆默认”,实际开发中,为了更好的效果,建议采用标准版或进阶版。
标准版 RAG
下面来试试标准版 RAG 实现,为了更好地效果,我们需要:
加载 Markdown 文档并按需切割
Markdown 文档补充文件名信息
自定义 Embedding 模型
自定义内容检索器
在 Spring Boot 配置文件中添加 Embedding 模型配置,使用阿里云提供的 text-embedding-v4 模型:
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <You API Key here>
embedding-model:
model-name: text-embedding-v4
api-key: <You API Key here>
新建 rag.RagConfig,编写 RAG 相关的代码,执行 RAG 的初始流程并返回了一个定制的内容检索器 Bean:
/**
* 加载 RAG
*/
@Configuration
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddingModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Bean
public ContentRetriever contentRetriever() {
// ------ RAG ------
// 1. 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
// 2. 文档切割:将每个文档按每段进行分割,最大 1000 字符,每次重叠最多 200 个字符
DocumentByParagraphSplitter paragraphSplitter = new DocumentByParagraphSplitter(1000, 200);
// 3. 自定义文档加载器
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(paragraphSplitter)
// 为了提高搜索质量,为每个 TextSegment 添加文档名称
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
// 使用指定的向量模型
.embeddingModel(qwenEmbeddingModel)
.embeddingStore(embeddingStore)
.build();
// 加载文档
ingestor.ingest(documents);
// 4. 自定义内容查询器
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) // 最多 5 个检索结果
.minScore(0.75) // 过滤掉分数小于 0.75 的结果
.build();
return contentRetriever;
}
}
然后在构建 AI Service 时绑定内容检索器:
@Resource
private ContentRetriever contentRetriever;
@Bean
public AiCodeHelperService aiCodeHelperService() {
// 会话记忆
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.build();
return aiCodeHelperService;
}
编写单元测试:
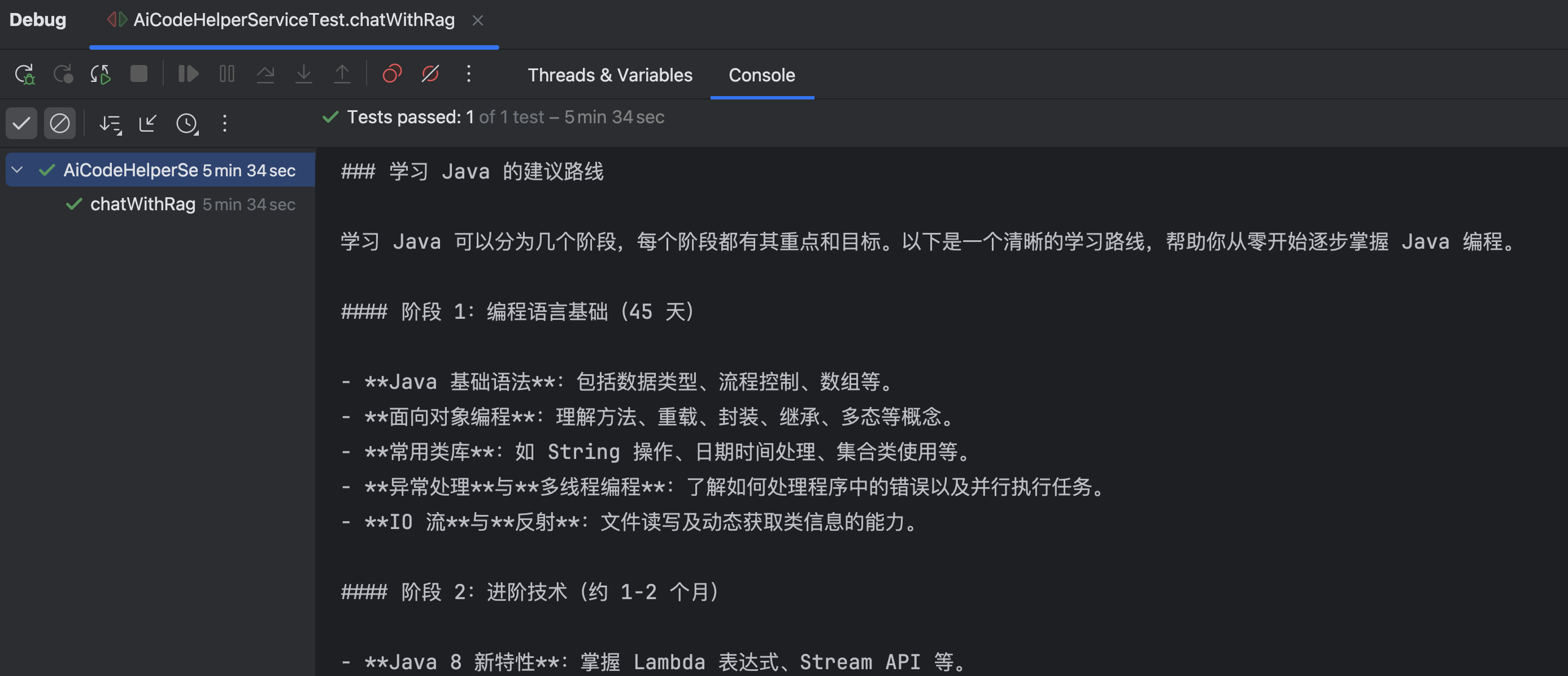
@Test
void chatWithRag() {
Result<String> result = aiCodeHelperService.chatWithRag("怎么学习 Java?有哪些常见面试题?");
System.out.println(result.content());
System.out.println(result.sources());
}
Debug 运行,能够看到分割的文档片段,部分文档片段有内容重叠:

可以在对话记忆中看到实际发送的、增强后的 Prompt:

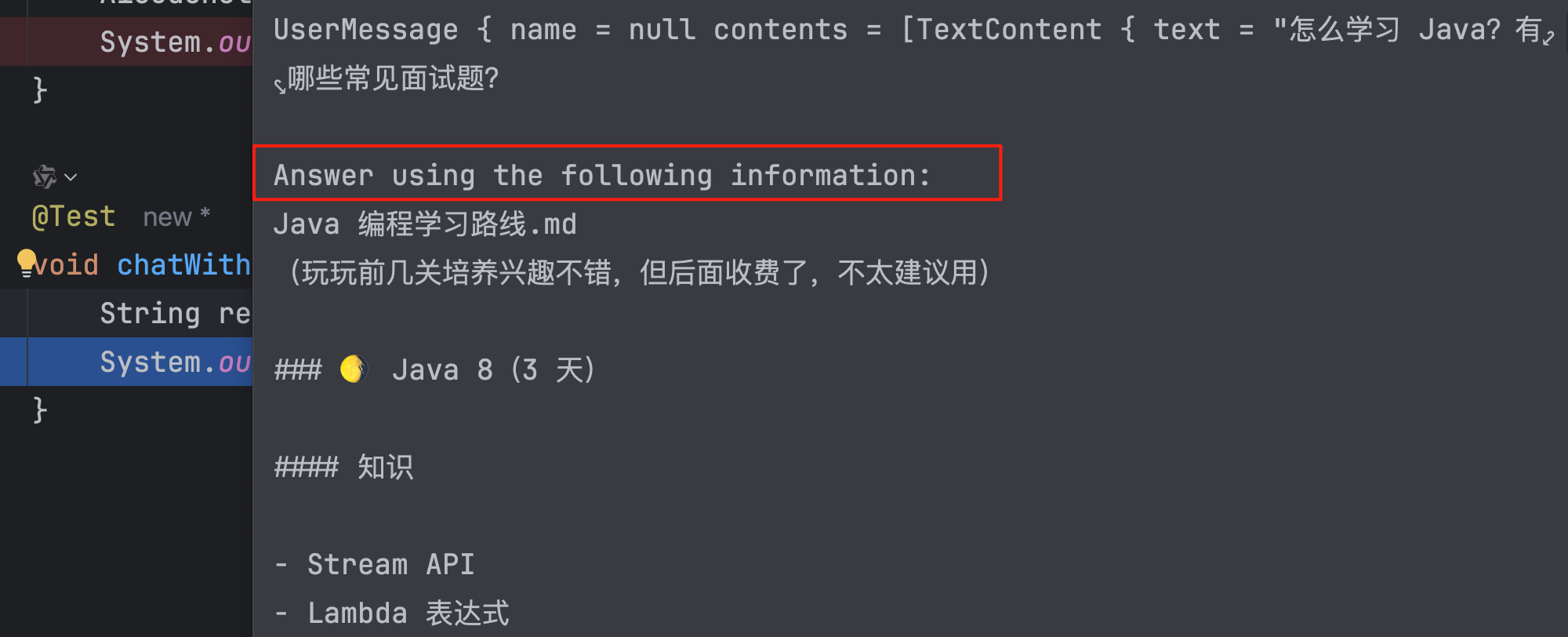
回答效果也是符合预期的:
获取引用源文档
如果能够给 AI 的回答下面展示回答来源,更容易增加内容的可信度:
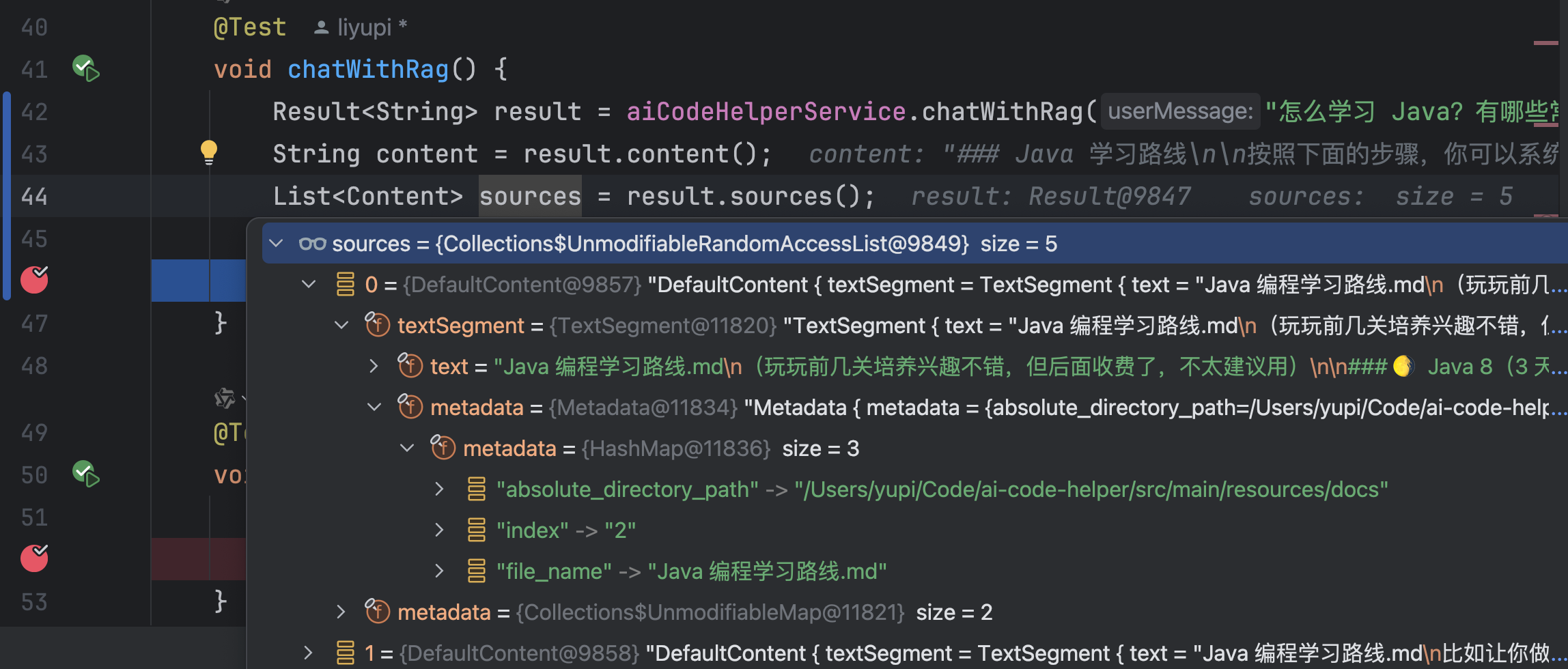
在 LangChain4j 中,实现这个功能很简单。在 AI Service 中新增方法,在原本的返回类型外封装一层 Result 类,就可以获得封装后的结果,从中能够获取到 RAG 引用的源文档、以及 Token 的消耗情况等等。
@SystemMessage(fromResource = "system-prompt.txt")
Result<String> chatWithRag(String userMessage);
修改单元测试,输出更多信息:
@Test
void chatWithRag() {
Result<String> result = aiCodeHelperService.chatWithRag("怎么学习 Java?有哪些常见面试题?");
String content = result.content();
List<Content> sources = result.sources();
System.out.println(content);
System.out.println(sources);
}
执行效果如图,获取到了引用的源文档信息:
进阶版 RAG
这就是一套标准的 RAG 实现了,大多数时候,使用标准版就够了。进阶版会更加灵活,额外支持查询转换器、查询路由、内容聚合器、内容注入器等特性,将整个 RAG 的流程流水线化(RAG pipeline)。

定义好 RAG 流程后,最后通过 RetrievalAugmentor 提供给 AI Service:
AiServices.builder(xxx.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();
此外,之前我们使用的是内存向量存储,每次启动都要重新加载文档、调用嵌入模型,比较耗时,所以实际开发中建议使用独立的存储,官方支持很多第三方存储,但是个人比较推荐 PG Vector,在原有关系库的基础上安装插件来支持向量存储,而且支持的特性很多。

工具调用 - Tools
工具调用(Tool Calling)可以理解为让 AI 大模型 借用外部工具 来完成它自己做不到的事情。
跟人类一样,如果只凭手脚完成不了工作,那么就可以利用工具箱来完成。
工具可以是任何东西,比如网页搜索、对外部 API 的调用、访问外部数据、或执行特定的代码等。
比如用户提问 “帮我查询上海最新的天气”,AI 本身并没有这些知识,它就可以调用 “查询天气工具”,来完成任务。
需要注意的是,工具调用的本质 并不是 AI 服务器自己调用这些工具、也不是把工具的代码发送给 AI 服务器让它执行,它只能提出要求,表示 “我需要执行 XX 工具完成任务”。而真正执行工具的是我们自己的应用程序,执行后再把结果告诉 AI,让它继续工作。
我们需要的网络搜索能力,就可以通过工具调用来实现。这里我们细化下需求:让 AI 能够通过我的 面试鸭刷题网站 来搜索面试题。
实现方案很简单,因为面试鸭网站的搜索页面 支持通过 URL 参数传入不同的搜索关键词,我们只需要利用 Jsoup 库 抓取面试鸭搜索页面的题目列表就可以了。
好家伙,我爬我自己?不过大家不要尝试,很容易被封号。

先引入 Jsoup 库:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.20.1</version>
</dependency>
然后在 tools 包下编写工具,通过 @Tool 注解就能声明工具了,注意 要认真编写工具和工具参数的描述,这直接决定了 AI 能否正确地调用工具。
@Slf4j
public class InterviewQuestionTool {
/**
* 从面试鸭网站获取关键词相关的面试题列表
*
* @param keyword 搜索关键词(如"redis"、"java多线程")
* @return 面试题列表,若失败则返回错误信息
*/
@Tool(name = "interviewQuestionSearch", value = """
Retrieves relevant interview questions from mianshiya.com based on a keyword.
Use this tool when the user asks for interview questions about specific technologies,
programming concepts, or job-related topics. The input should be a clear search term.
"""
)
public String searchInterviewQuestions(@P(value = "the keyword to search") String keyword) {
List<String> questions = new ArrayList<>();
// 构建搜索URL(编码关键词以支持中文)
String encodedKeyword = URLEncoder.encode(keyword, StandardCharsets.UTF_8);
String url = "https://www.mianshiya.com/search/all?searchText=" + encodedKeyword;
// 发送请求并解析页面
Document doc;
try {
doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.timeout(5000)
.get();
} catch (IOException e) {
log.error("get web error", e);
return e.getMessage();
}
// 提取面试题
Elements questionElements = doc.select(".ant-table-cell > a");
questionElements.forEach(el -> questions.add(el.text().trim()));
return String.join("\n", questions);
}
}
给 AI Service 绑定工具:
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.build();
编写单元测试,验证工具的效果:
@Test
void chatWithTools() {
String result = aiCodeHelperService.chat("有哪些常见的计算机网络面试题?");
System.out.println(result);
}
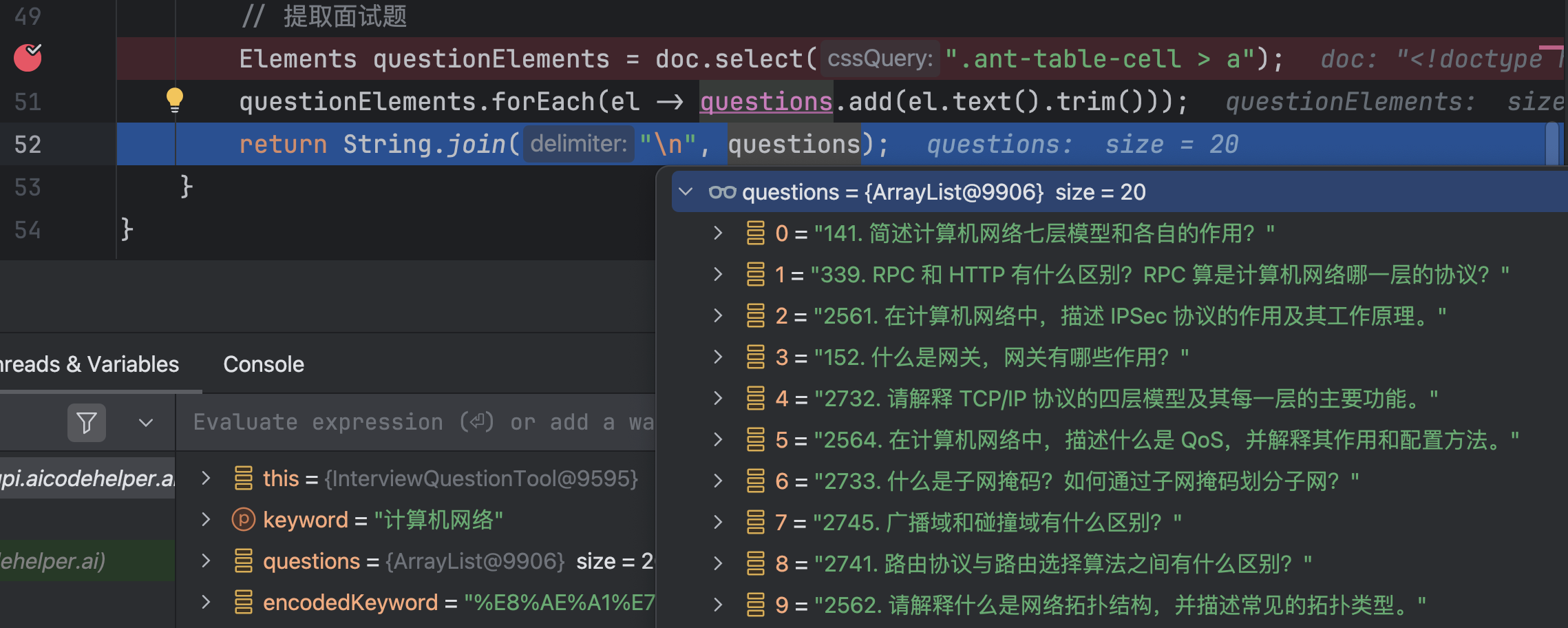
Debug 运行,发现 AI 调用了工具:

工具检索到了题目列表:
可以通过 Debug 看到 AI Service 加载了工具:
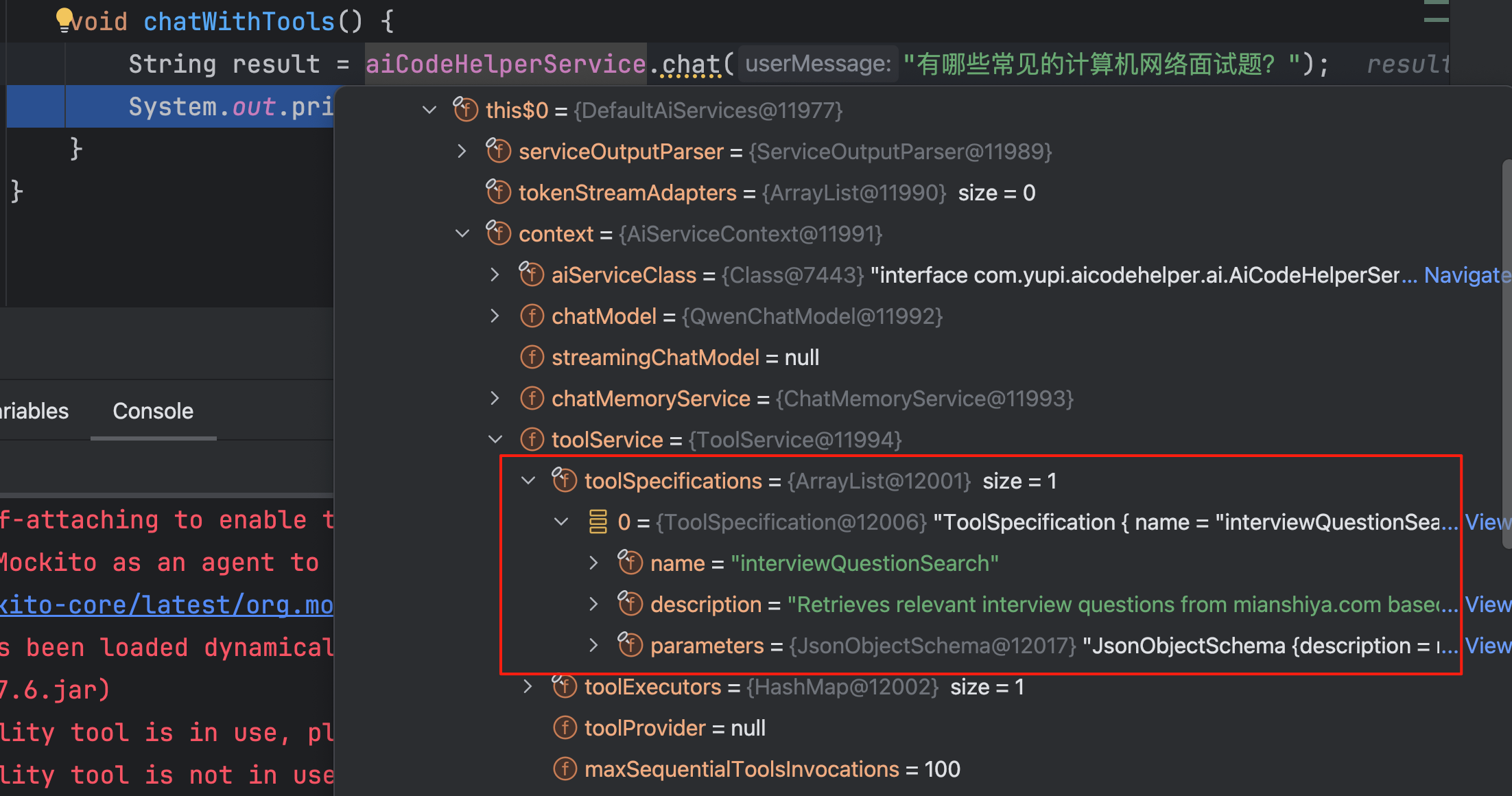
可以通过会话记忆查看工具的调用过程:
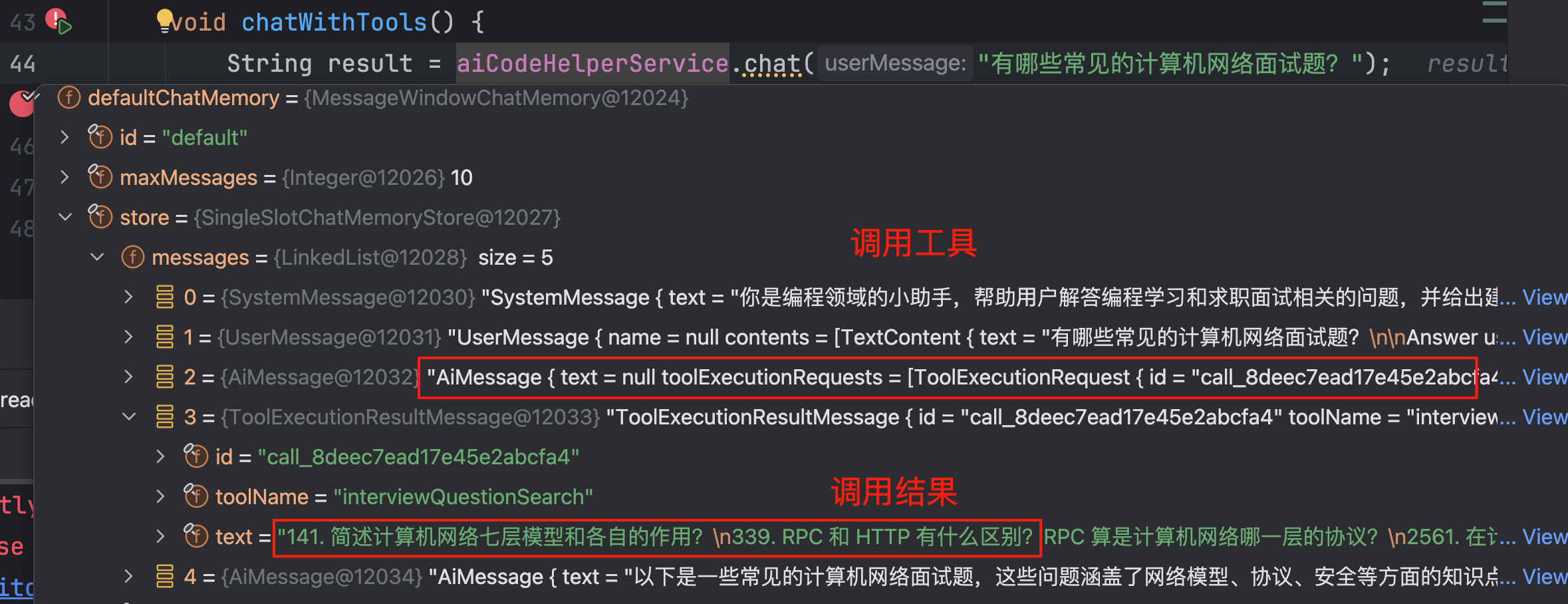
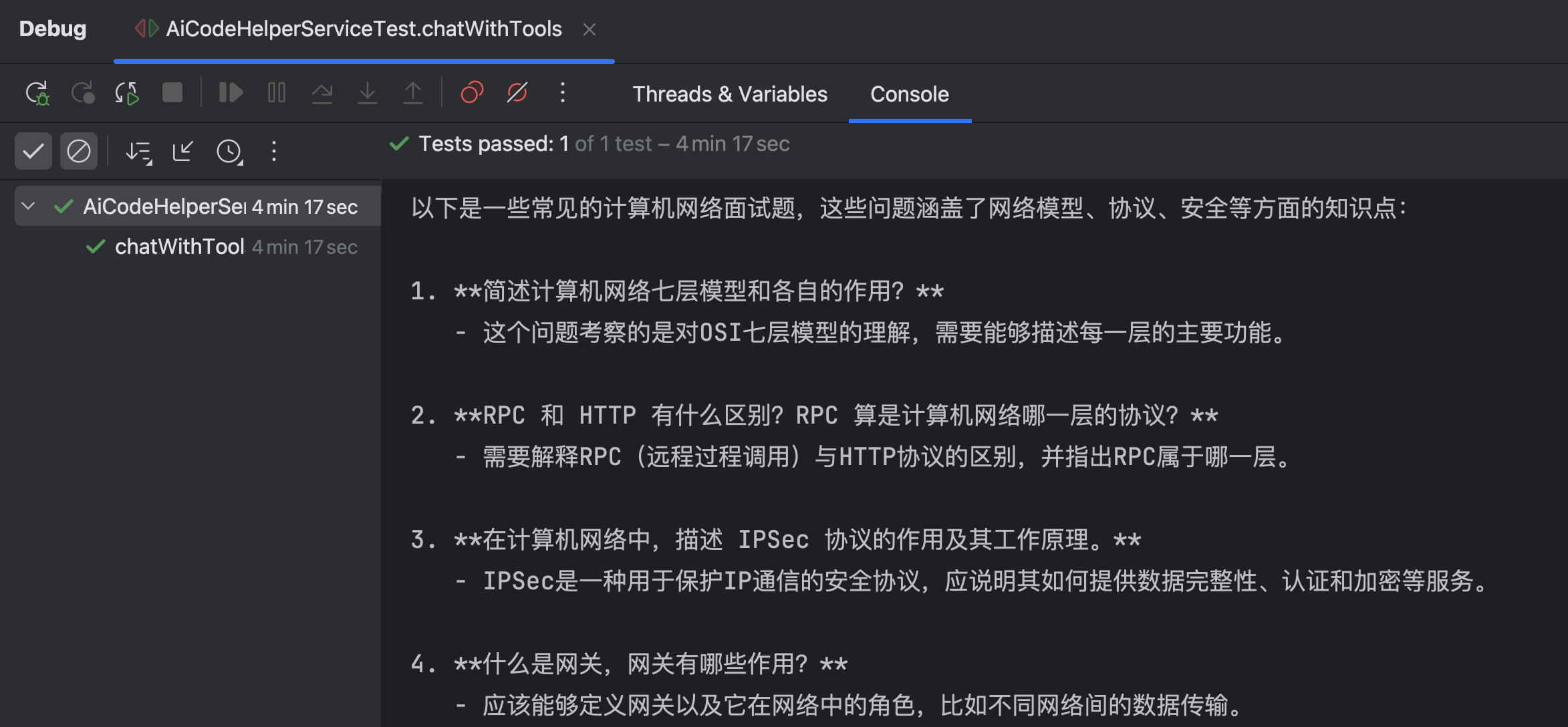
输出结果符合预期:
前面只演示了最简单的工具定义方法 —— 声明式,LangChain4j 也提供了编程式的工具定义方法,不过我相信你不会想这么做的(除非是动态创建工具)。

除了联网搜索外,还有一些经典的工具,比如文件读写、PDF 生成、调用终端、输出图表等等。这些工具我们可以自己开发,也可以通过 MCP 直接使用别人开发好的工具。
模型上下文协议 - MCP
MCP(Model Context Protocol,模型上下文协议)是一种开放标准,目的是增强 AI 与外部系统的交互能力。MCP 为 AI 提供了与外部工具、资源和服务交互的标准化方式,让 AI 能够访问最新数据、执行复杂操作,并与现有系统集成。
可以将 MCP 想象成 AI 应用的 USB 接口。就像 USB 为设备连接各种外设和配件提供了标准化方式一样,MCP 为 AI 模型连接不同的数据源和工具提供了标准化的方法。
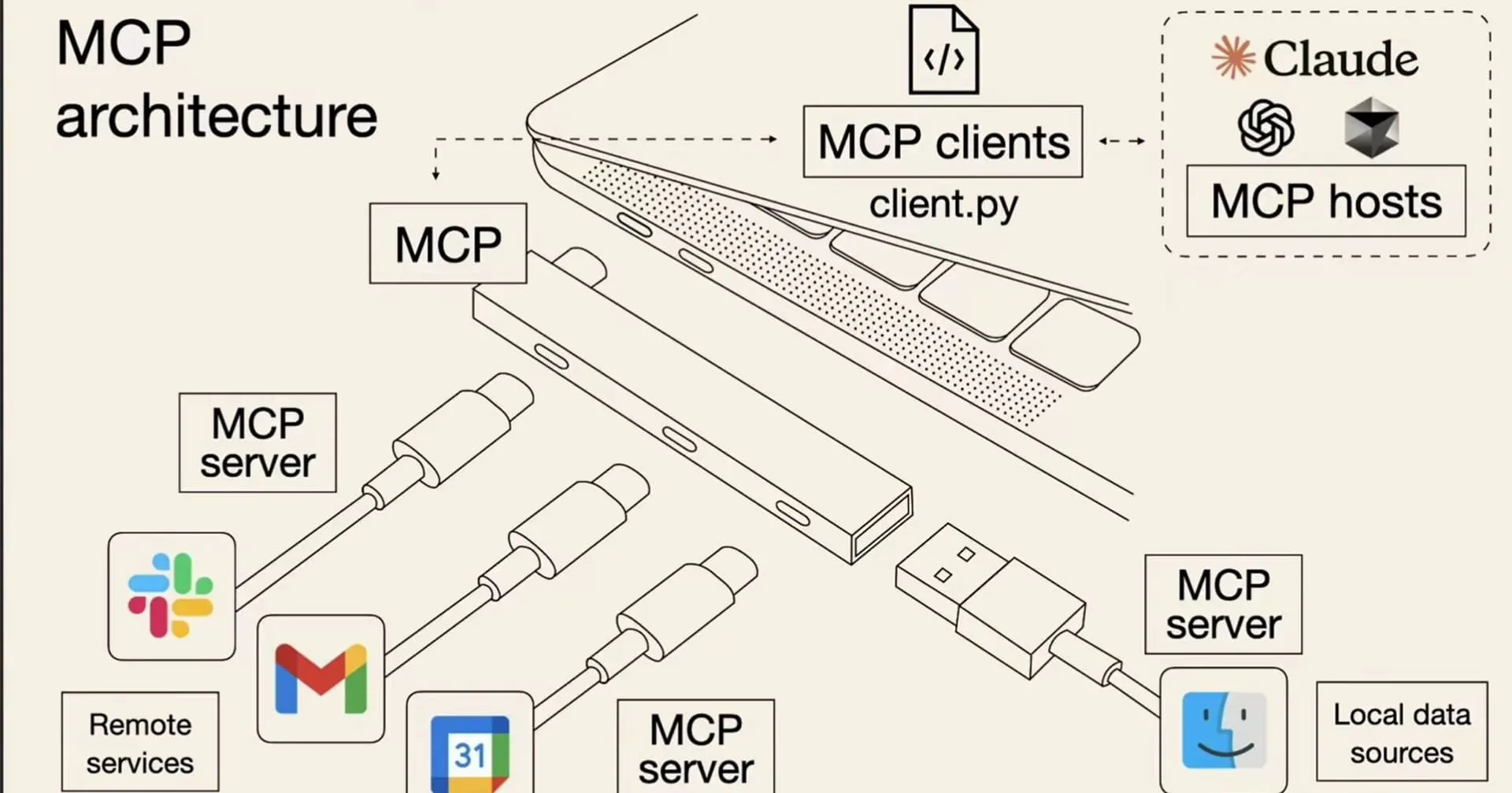
简单来说,通过 MCP 协议,AI 应用可以轻松接入别人提供的服务来实现更多功能,比如查询地理位置、操作数据库、部署网站、甚至是支付等等。
刚刚我们通过工具调用实现了面试题的搜索,下面我们利用 MCP 实现 全网搜索内容,这也是一个典型的 MCP 应用场景了。
首先从 MCP 服务市场搜索 Web Search 服务,推荐 下面这个,因为它提供了 SSE 在线调用服务,不用我们自己在本地安装启动,很方便。
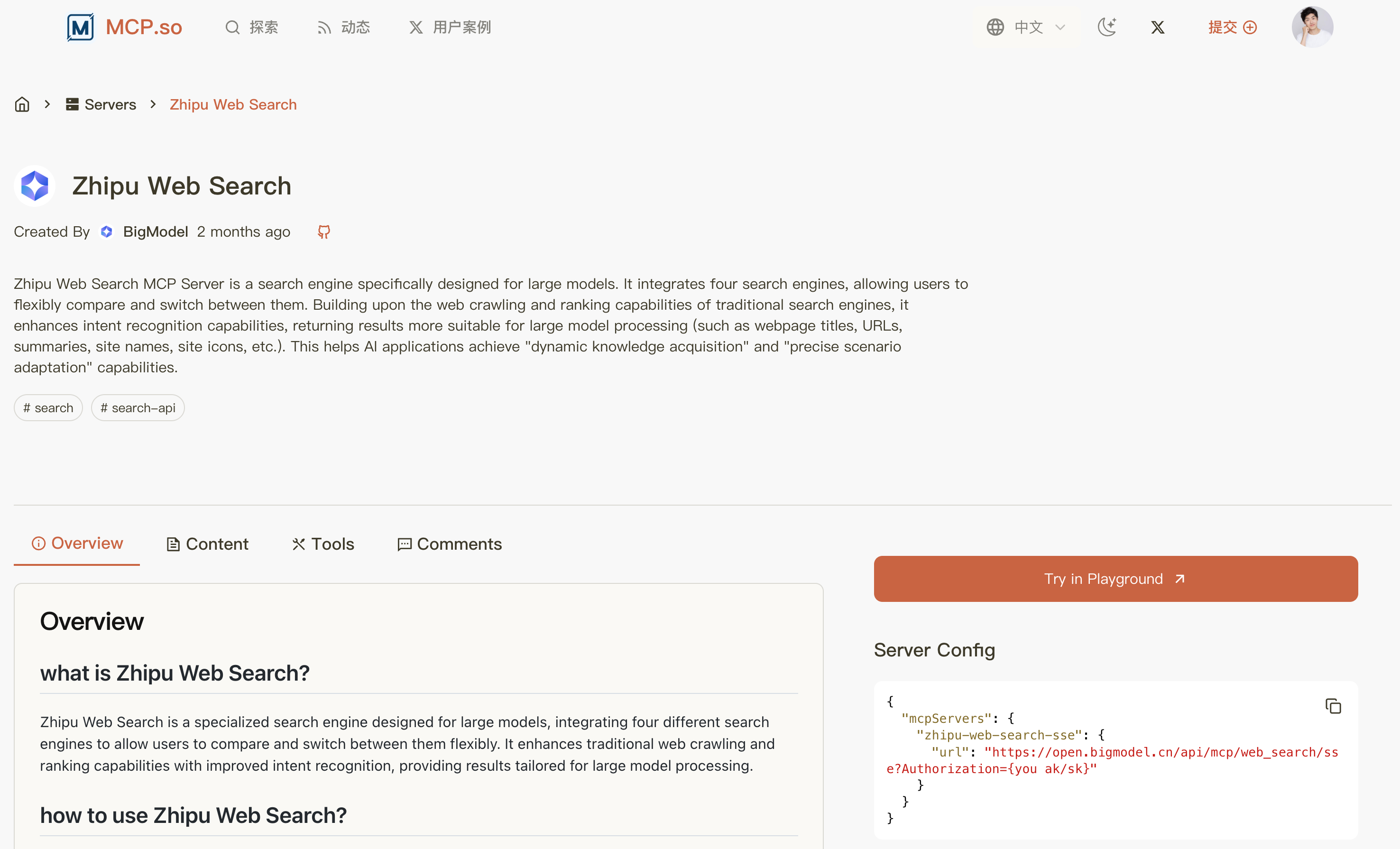
但也要注意,用别人的服务可能是需要 API Key 的,一般是按量付费。
需要先去 平台官方获取 API Key,等会儿会用到:

然后我们要在程序中使用这个 MCP 服务。比较坑的是,感觉 LangChain 对 MCP 的支持没有那么好,官方文档甚至都没有提到要引入的 MCP 依赖包。我还是从开源仓库中找到的依赖:
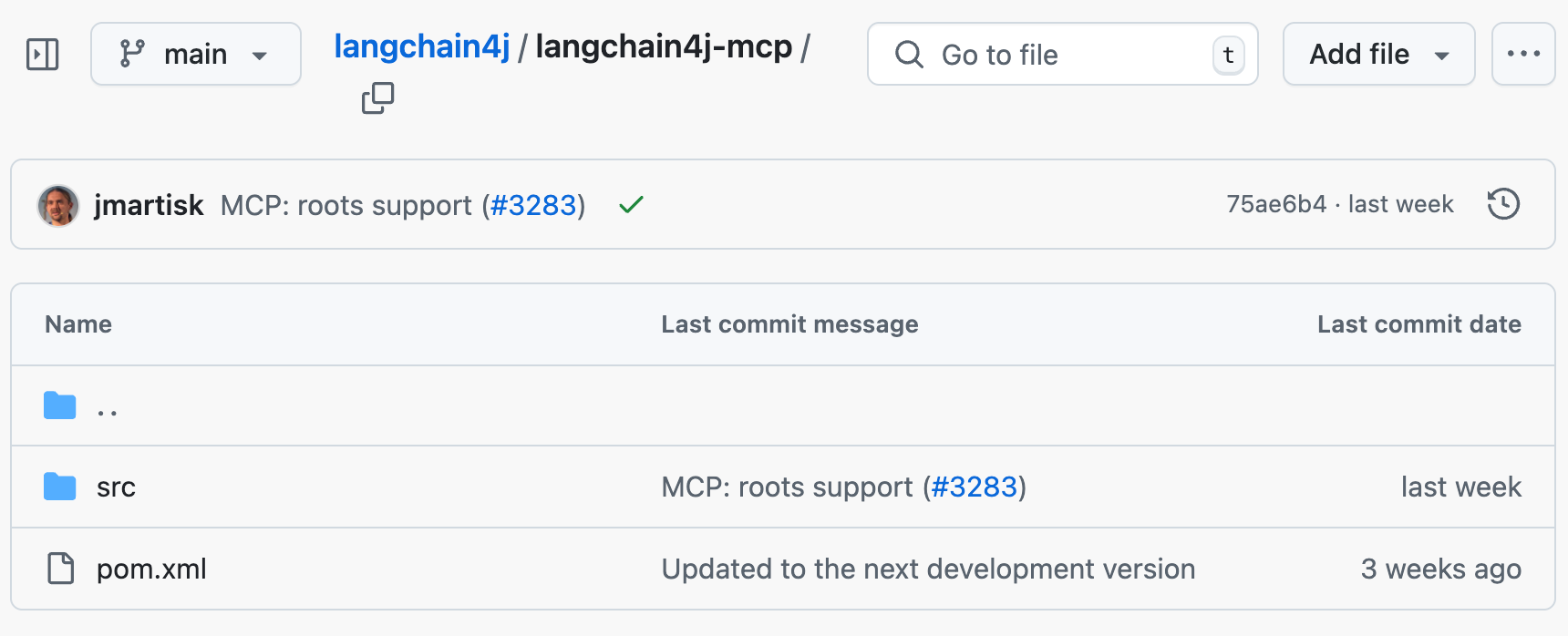
引入依赖:
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-mcp -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
<version>1.1.0-beta7</version>
</dependency>
在配置文件中新增 API Key 的配置:
bigmodel:
api-key: <Your Api Key>
新建 mcp.McpConfig,按照官方的开发方式,初始化和 MCP 服务的通讯,并创建 McpToolProvider 的 Bean:
@Configuration
public class McpConfig {
@Value("${bigmodel.api-key}")
private String apiKey;
@Bean
public McpToolProvider mcpToolProvider() {
// 和 MCP 服务通讯
McpTransport transport = new HttpMcpTransport.Builder()
.sseUrl("https://open.bigmodel.cn/api/mcp/web_search/sse?Authorization=" + apiKey)
.logRequests(true) // 开启日志,查看更多信息
.logResponses(true)
.build();
// 创建 MCP 客户端
McpClient mcpClient = new DefaultMcpClient.Builder()
.key("yupiMcpClient")
.transport(transport)
.build();
// 从 MCP 客户端获取工具
McpToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(mcpClient)
.build();
return toolProvider;
}
}
注意,上面我们是通过 SSE 的方式调用 MCP。如果你是通过 npx 或 uvx 本地启动 MCP 服务,需要先安装对应的工具,并且利用下面的配置建立通讯:
McpTransport transport = new StdioMcpTransport.Builder()
.command(List.of("/usr/bin/npm", "exec", "@modelcontextprotocol/server-everything@0.6.2"))
.logEvents(true) // only if you want to see the traffic in the log
.build();
在 AI Service 中应用 MCP 工具:
@Resource
private McpToolProvider mcpToolProvider;
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.toolProvider(mcpToolProvider) // MCP 工具调用
.build();
编写单元测试:
@Test
void chatWithMcp() {
String result = aiCodeHelperService.chat("什么是程序员鱼皮的编程导航?");
System.out.println(result);
}
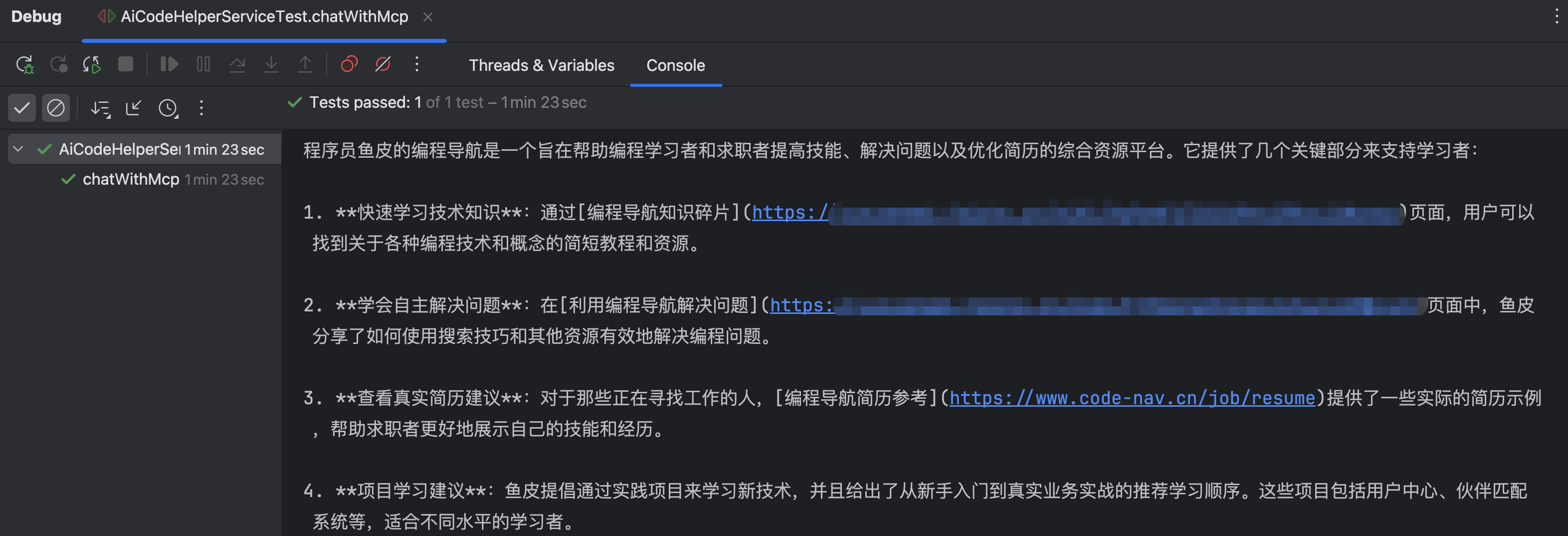
执行单元测试,通过日志查看到了搜索过程:

MCP 服务生效,从网上检索到了内容作为答案:
目前,文档中并没有提到利用 LangChain4j 开发 MCP 的方法,不过目前也不建议用 Java 开发 MCP。
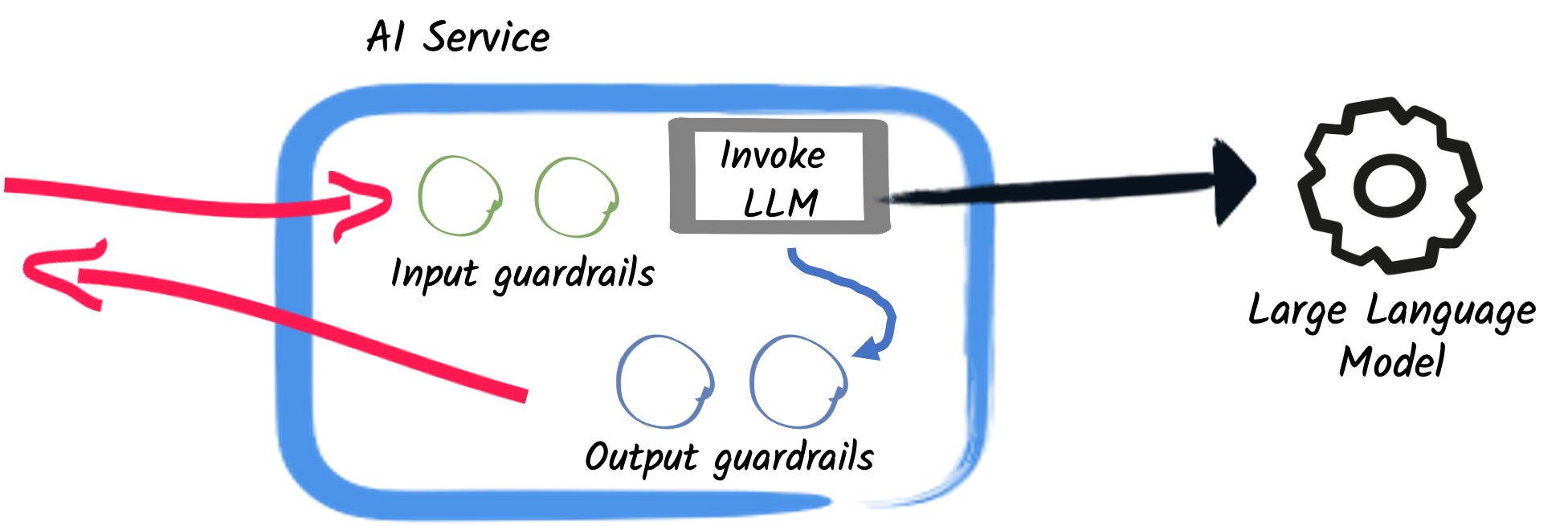
护轨 - Guardrail
其实我感觉护轨这个名字起的不太好,其实我们把它理解为拦截器就好了。分为输入护轨(input guardrails)和输出护轨(output guardrails),可以在请求 AI 前和接收到 AI 的响应后执行一些额外操作,比如调用 AI 前鉴权、调用 AI 后记录日志。
让我们小试一把,在调用 AI 前进行敏感词检测,如果用户提示词包含敏感词,则直接拒绝。
新建 guardrail.SafeInputGuardrail,实现 InputGuardrail 接口:
/**
* 安全检测输入护轨
*/
public class SafeInputGuardrail implements InputGuardrail {
private static final Set<String> sensitiveWords = Set.of("kill", "evil");
/**
* 检测用户输入是否安全
*/
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
// 获取用户输入并转换为小写以确保大小写不敏感
String inputText = userMessage.singleText().toLowerCase();
// 使用正则表达式分割输入文本为单词
String[] words = inputText.split("\\W+");
// 遍历所有单词,检查是否存在敏感词
for (String word : words) {
if (sensitiveWords.contains(word)) {
return fatal("Sensitive word detected: " + word);
}
}
return success();
}
}
LangChain4j 提供了几种快速返回的方法,简单来说,想继续调用 AI 就返回 success、否则就返回 fatal。
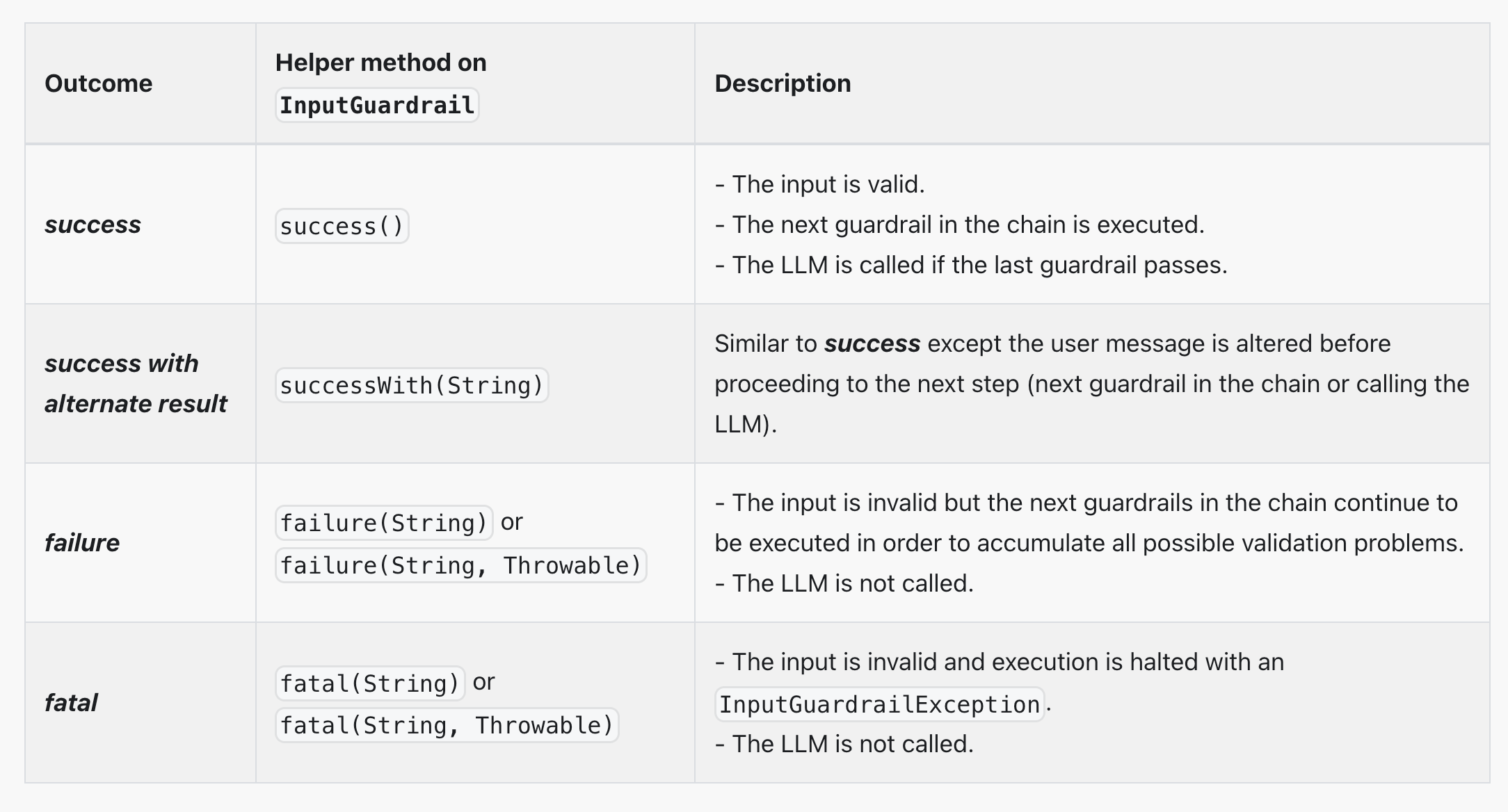
修改 AI Service,使用输入护轨:
@InputGuardrails({SafeInputGuardrail.class})
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
// 学习报告
record Report(String name, List<String> suggestionList) {
}
}
编写单元测试,写一个包含敏感词的提示词:
@Test
void chatWithGuardrail() {
String result = aiCodeHelperService.chat("kill the game");
System.out.println(result);
}
运行并查看效果,会触发输入检测,直接抛出异常:
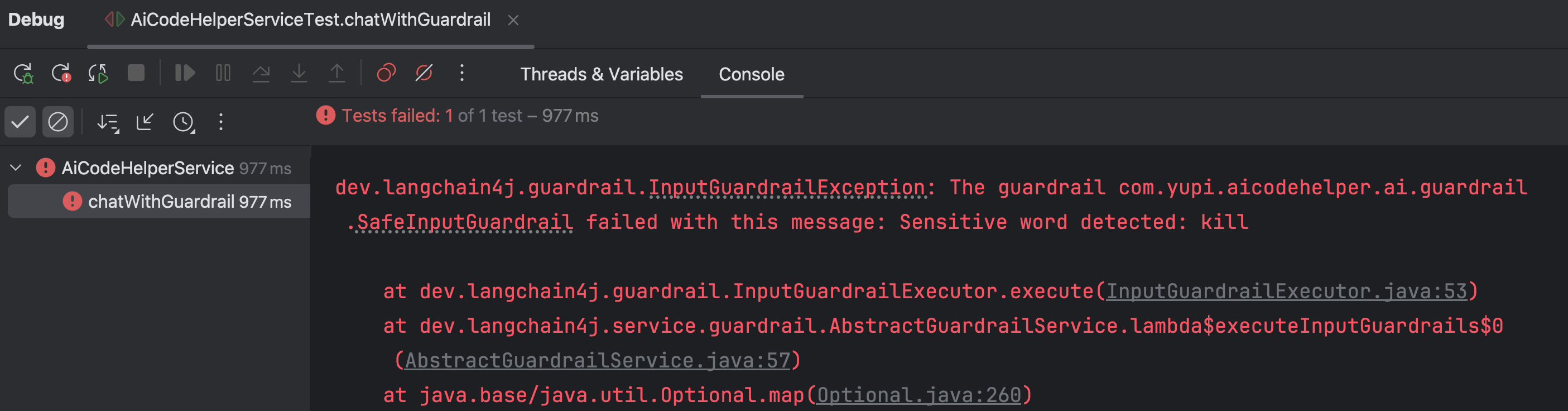
如果不包含敏感词,则会顺利通过。

当然,除了输入护轨,也可以编写输出护轨,对 AI 的响应结果进行检测。
日志和可观测性
之前我们都是通过 Debug 查看运行信息,不仅不便于调试,而且生产环境肯定不能这么做。
官方提供了 日志 和 可观测性,来帮我们更好地调试程序、发现问题。
日志
开启日志的方法很简单,直接构造模型时指定开启、或者直接编写 Spring Boot 配置,支持打印 AI 请求和响应日志。
OpenAiChatModel.builder()
...
.logRequests(true)
.logResponses(true)
.build();
langchain4j.open-ai.chat-model.log-requests = true
langchain4j.open-ai.chat-model.log-responses = true
logging.level.dev.langchain4j = DEBUG
但并不是所有的 ChatModel 都支持,比如我测试下来 QwenChatModel 就不支持。这时只能把希望交给可观测性了。
可观测性
可以通过自定义 Listener 获取 ChatModel 的调用信息,比较灵活。
新建 listener.ChatModelListenerConfig,输出请求、响应、错误信息:
@Configuration
@Slf4j
public class ChatModelListenerConfig {
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
@Override
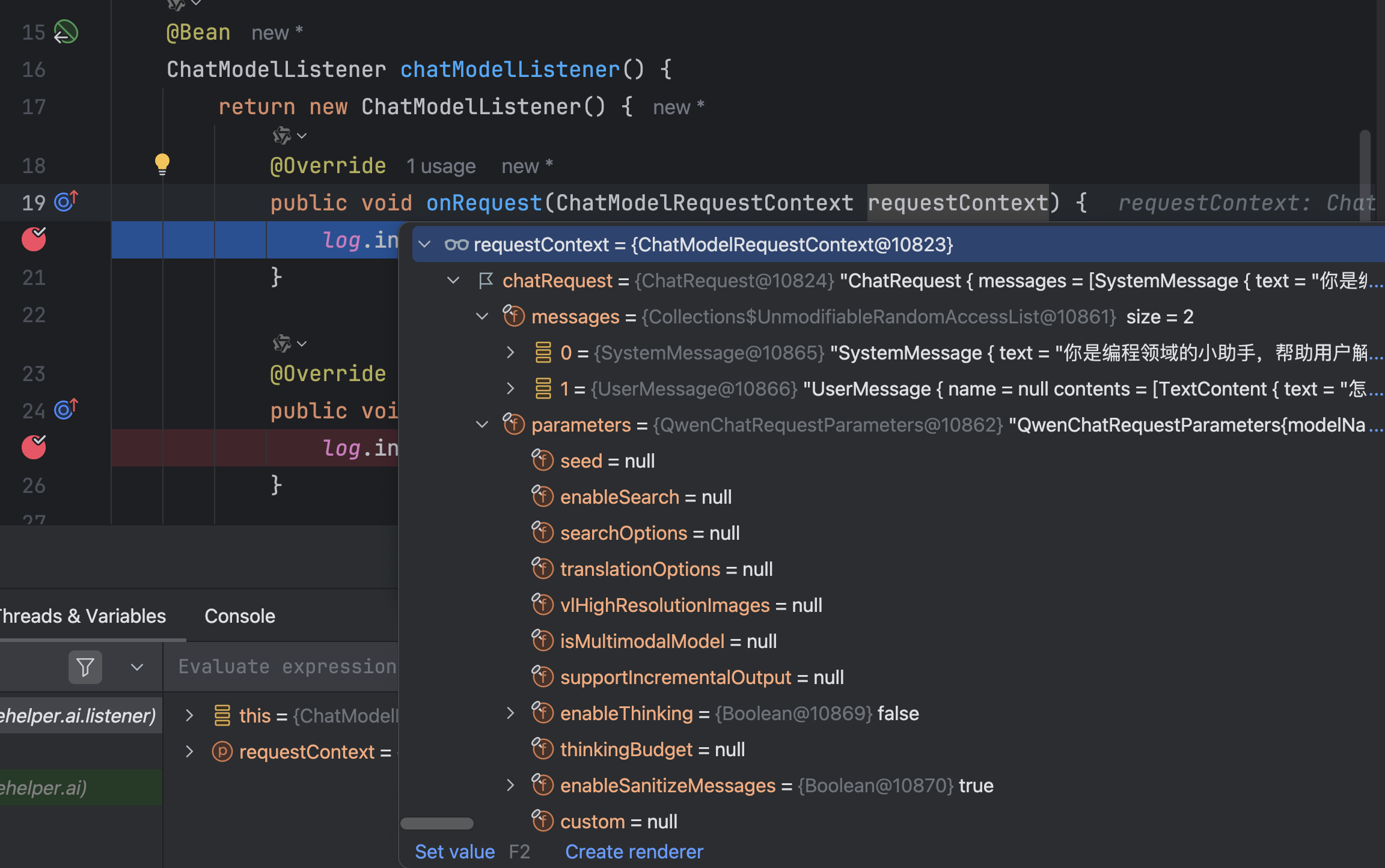
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest(): {}", requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse(): {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError(): {}", errorContext.error().getMessage());
}
};
}
}
但是只定义 Listener 好像对 QwenChatModel 不起作用,所以我们需要手动构造自定义的 QwenChatModel。
新建 model.QwenChatModelConfig,构造 ChatModel 对象并绑定 Listener:
@Configuration
@ConfigurationProperties(prefix = "langchain4j.community.dashscope.chat-model")
@Data
public class QwenChatModelConfig {
private String modelName;
private String apiKey;
@Resource
private ChatModelListener chatModelListener;
@Bean
public ChatModel myQwenChatModel() {
return QwenChatModel.builder()
.apiKey(apiKey)
.modelName(modelName)
.listeners(List.of(chatModelListener))
.build();
}
}
然后,可以将原本引用 ChatModel 的名称改为 myQwenChatModel,防止和 Spring Boot 自动注入的 ChatModel 冲突。
再次调用 AI,就能看到很多信息了:
AI 服务化
至此,AI 的能力基本开发完成,但是目前只支持本地运行,需要编写一个接口提供给前端调用,让 AI 能够成为一个服务。
我们平时开发的大多数接口都是同步接口,也就是等后端处理完再返回。但是对于 AI 应用,特别是响应时间较长的对话类应用,可能会让用户失去耐心等待,因此推荐使用 SSE(Server-Sent Events)技术实现实时流式输出,类似打字机效果,大幅提升用户体验。
SSE 流式接口开发
LangChain 提供了 2 种方式来支持流式响应(注意,流式响应不支持结构化输出)。
一种方法是 TokenStream,先让 AI 对话方法返回 TokenStream,然后创建 AI Service 时指定流式对话模型 StreamingChatModel:
interface Assistant {
TokenStream chat(String message);
}
StreamingChatModel model = OpenAiStreamingChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.create(Assistant.class, model);
TokenStream tokenStream = assistant.chat("Tell me a joke");
tokenStream.onPartialResponse((String partialResponse) -> System.out.println(partialResponse))
.onRetrieved((List<Content> contents) -> System.out.println(contents))
.onToolExecuted((ToolExecution toolExecution) -> System.out.println(toolExecution))
.onCompleteResponse((ChatResponse response) -> System.out.println(response))
.onError((Throwable error) -> error.printStackTrace())
.start();
我个人会更喜欢另一种方法,使用 Flux 代替 TokenStream,熟悉响应式编程的同学应该对 Flux 不陌生吧?让 AI 对话方法返回 Flux 响应式对象即可。示例代码:
interface Assistant {
Flux<String> chat(String message);
}
让我们试一下,首先需要引入响应式包依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
然后给 AI Service 增加流式对话方法,这里顺便支持下多用户的会话记忆:
// 流式对话
Flux<String> chatStream(@MemoryId int memoryId, @UserMessage String userMessage);
由于要用到流式模型,需要增加流式模型配置:
langchain4j:
community:
dashscope:
streaming-chat-model:
model-name: qwen-max
api-key: <Your Api Key>
构造 AI Service 时指定流式对话模型(自动注入即可),并且补充会话记忆提供者:
@Resource
private StreamingChatModel qwenStreamingChatModel;
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(myQwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemory(chatMemory)
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.withMaxMessages(10)) // 每个会话独立存储
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.toolProvider(mcpToolProvider) // MCP 工具调用
.build();
最后,编写 Controller 接口。为了方便测试,这里使用 Get 请求:
@RestController
@RequestMapping("/ai")
public class AiController {
@Resource
private AiCodeHelperService aiCodeHelperService;
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chatStream(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
增加服务器配置,指定后端端口和接口路径前缀:
server:
port: 8081
servlet:
context-path: /api
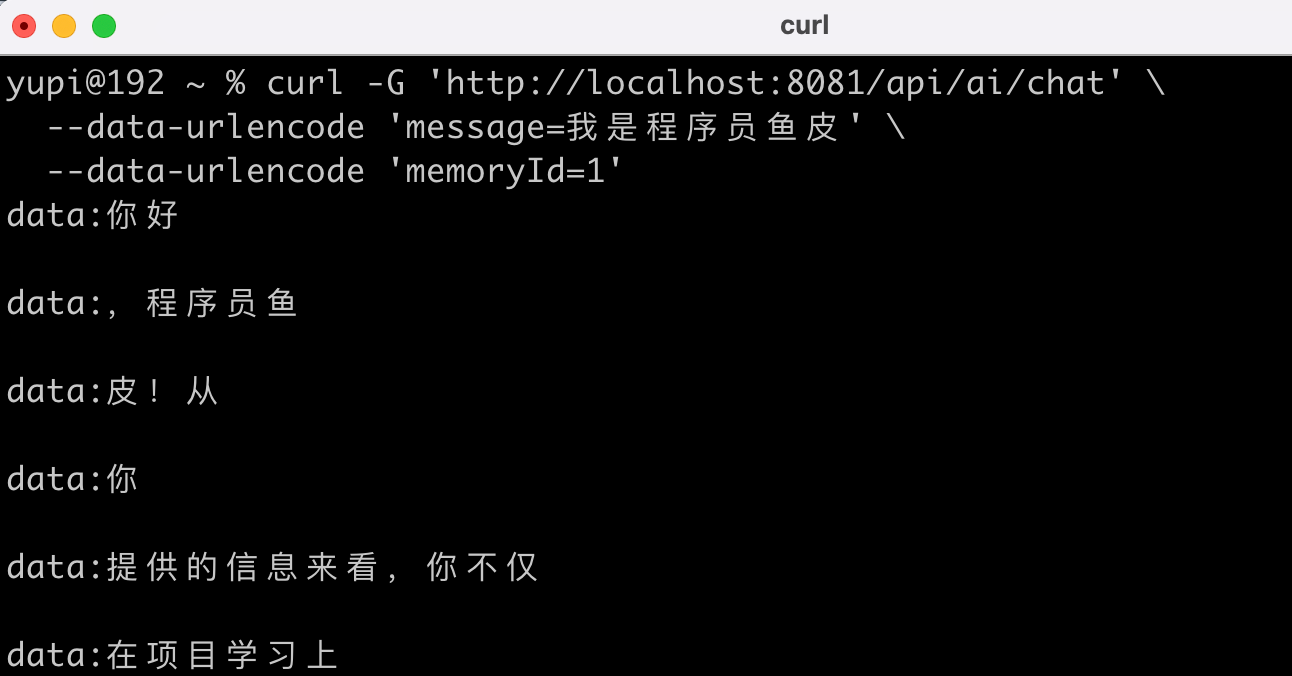
启动服务器,用 CURL 工具测试调用:
curl -G 'http://localhost:8081/api/ai/chat' \
--data-urlencode 'message=我是程序员鱼皮' \
--data-urlencode 'memoryId=1'
可以看到流式的输出结果:
后端支持跨域
为了让前端项目能够顺利调用后端接口,我们需要在后端配置跨域支持。在 config 包下创建跨域配置类,代码如下:
/**
* 全局跨域配置
*/
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 覆盖所有请求
registry.addMapping("/**")
// 允许发送 Cookie
.allowCredentials(true)
// 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突)
.allowedOriginPatterns("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("*");
}
}
注意,如果 .allowedOrigins("*") 与 .allowCredentials(true) 同时配置会导致冲突,因为出于安全考虑,跨域请求不能同时允许所有域名访问和发送认证信息(比如 Cookie)。
AI 生成前端
由于这个项目不需要很复杂的页面,我们可以利用 AI 来快速生成前端代码,极大提高开发效率。这里鱼皮使用 主流 AI 开发工具 Cursor,挑战不写一行代码,生成符合要求的前端项目。
提示词
首先准备一段详细的 Prompt,一般要包括需求、技术选型、后端接口信息,还可以提供一些原型图、后端代码等。
你是一位专业的前端开发,请帮我根据下列信息来生成对应的前端项目代码。
## 需求
应用为《AI 编程小助手》,帮助用户解答编程学习和求职面试相关的问题,并给出建议。
只有一个页面,就是主页:页面风格为聊天室,上方是聊天记录(用户信息在右边,AI 信息在左边),下方是输入框,进入页面后自动生成一个聊天室 id,用于区分不同的会话。通过 SSE 的方式调用 chat 接口,实时显示对话内容。
## 技术选型
1. Vue3 项目
2. Axios 请求库
## 后端接口信息
接口地址前缀:http://localhost:8081/api
## SpringBoot 后端接口代码
@RestController
@RequestMapping("/ai")
public class AiController {
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chatStream(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
注意,如果使用的是 Windows 系统,最好在 prompt 中补充“你应该使用 Windows 支持的命令来完成任务”。
开发
在项目根目录下创建新的前端项目文件夹 ai-code-helper-frontend,使用 Cursor 工具打开该目录,输入 Prompt 执行。注意要选择 Agent 模式、Thinking 深度思考模型(推荐 Claude):
除了源代码外,鱼皮这里连项目介绍文档 README.md 都生成了,确实很爽!
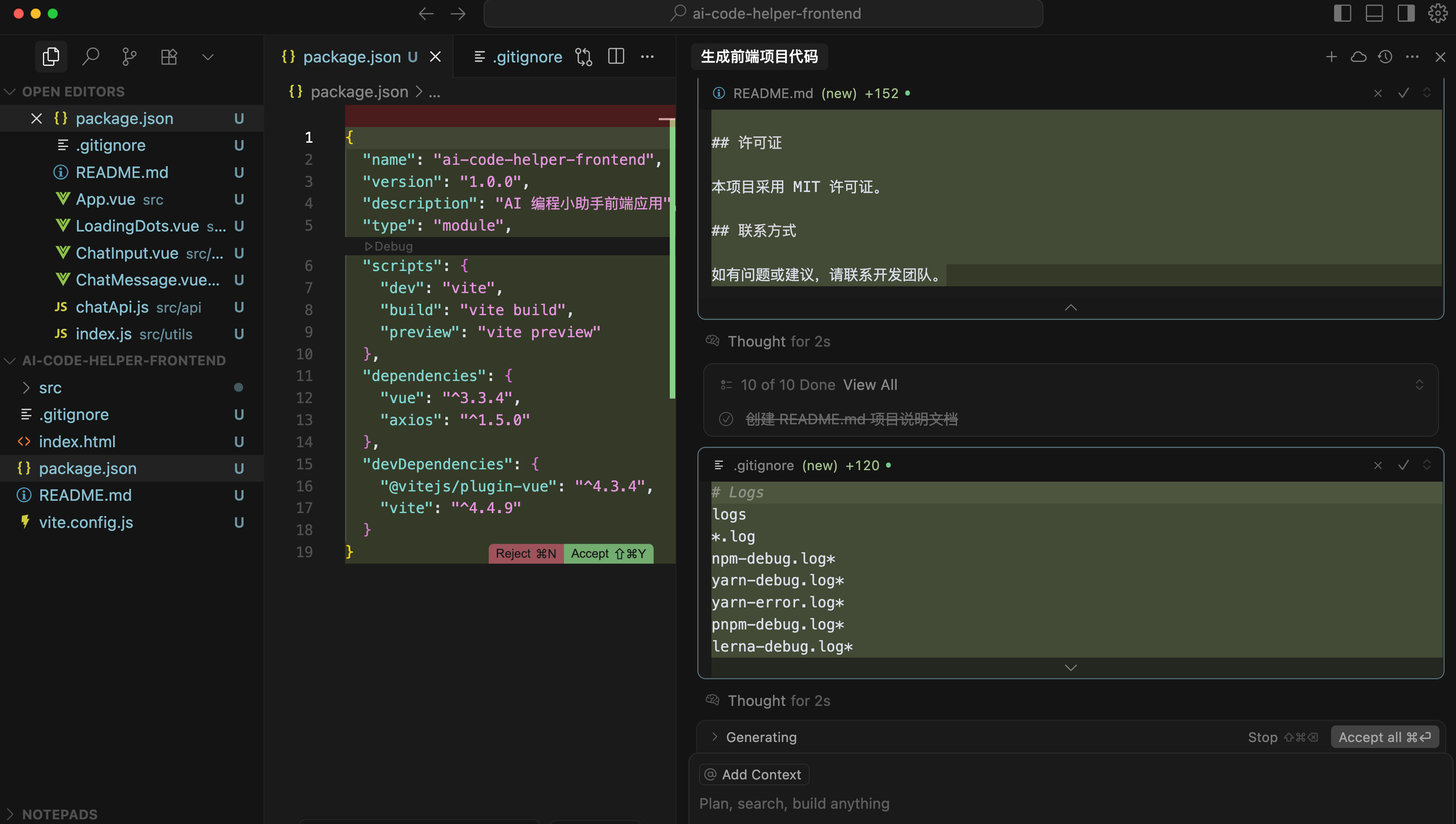
生成完代码后,打开终端执行 npm run dev 命令,或者打开 package.json 文件并利用 Debug 按钮启动项目:

查看效果
运行前端项目后,首先验证功能是否正常,再验证样式。如果发现功能不可用(比如发送消息后没有回复),可以按 F12 打开浏览器控制台查看前端错误信息、或者看后端项目控制台的错误信息,具体报错信息具体分析。这块就会涉及到一些前端相关的知识了,不懂前端的同学尽量多问 AI,让它帮忙修复 Bug 就好。如果实在搞不定,也别瞎折腾了!用鱼皮的代码就好。
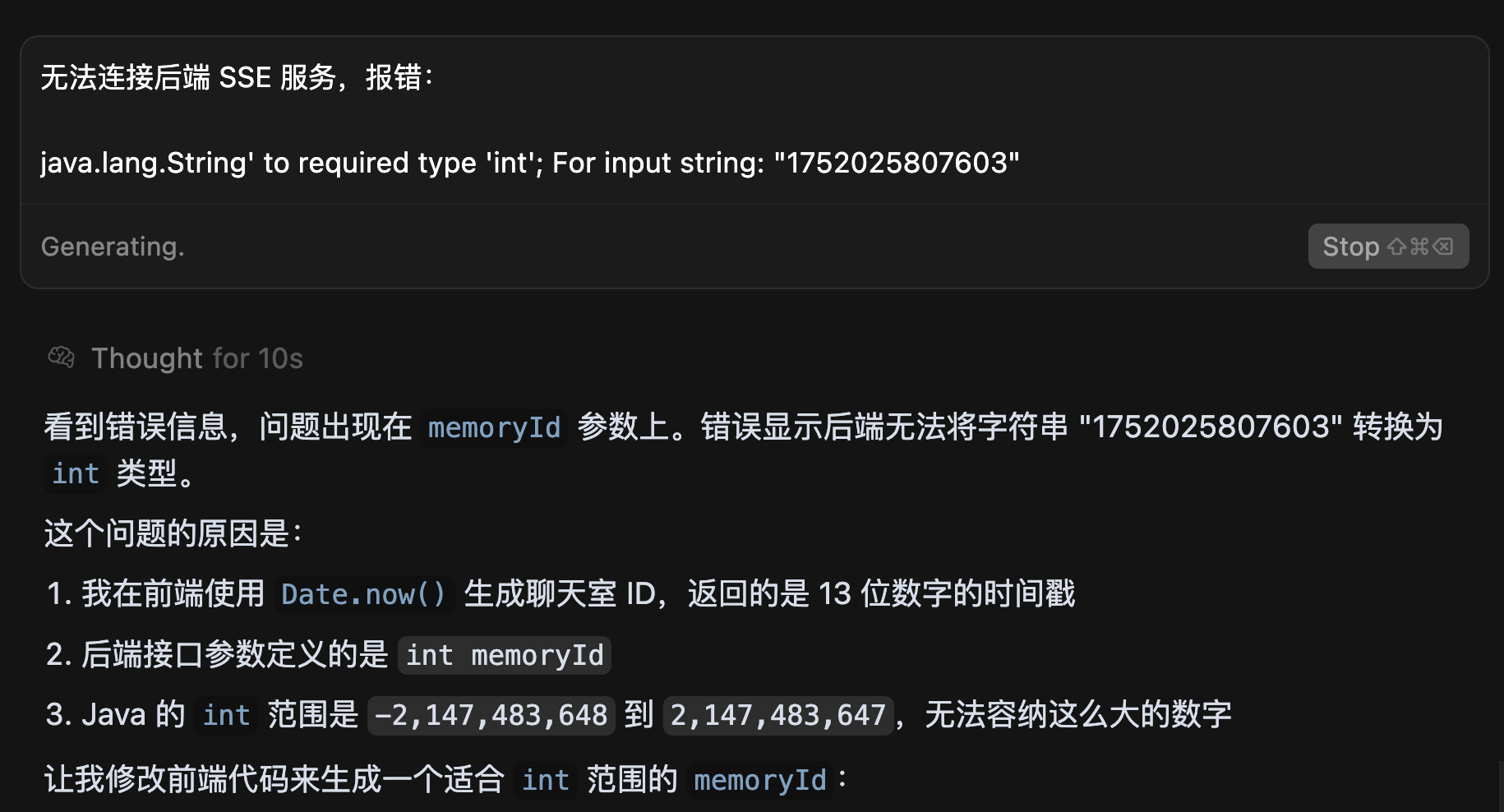
比如我遇到了连接后端 SSE 服务报错的问题,直接复制报错信息给 AI 解决:
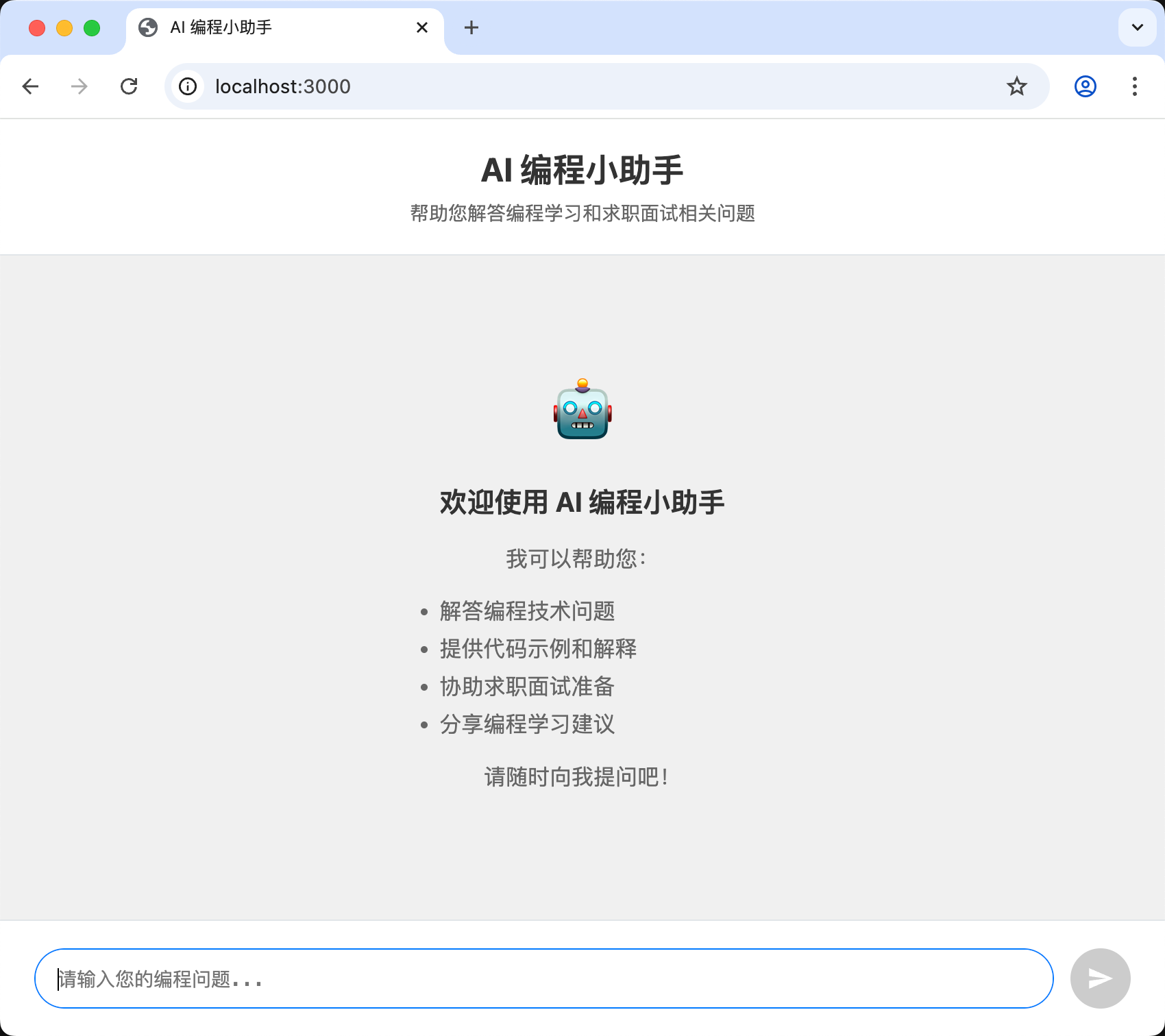
成功运行,查看效果:
确保功能和样式没问题后,记得先提交代码(防止后续被 AI 生成的代码污染),然后你可以按需增加更多功能,比如用 Markdown 展示 AI 的回复消息。
总结
OK,以上就是 LangChain4j 实战项目教程,怎么样,大家学会了还是学废了?
回到开头的那个问题:实际开发中应该如何选择 AI 开发框架呢?
就拿 Spring AI 和 LangChain4j 来说,不知道大家更喜欢哪个框架?我其实会更喜欢 Spring AI 的开发模式,而且 Spring AI 目前支持的能力更多,还有国内 Spring AI Alibaba 的巨头加持,生态更好,遇到问题更容易解决;LangChain4j 的优势在于可以独立于 Spring 项目使用,更自由灵活一些。
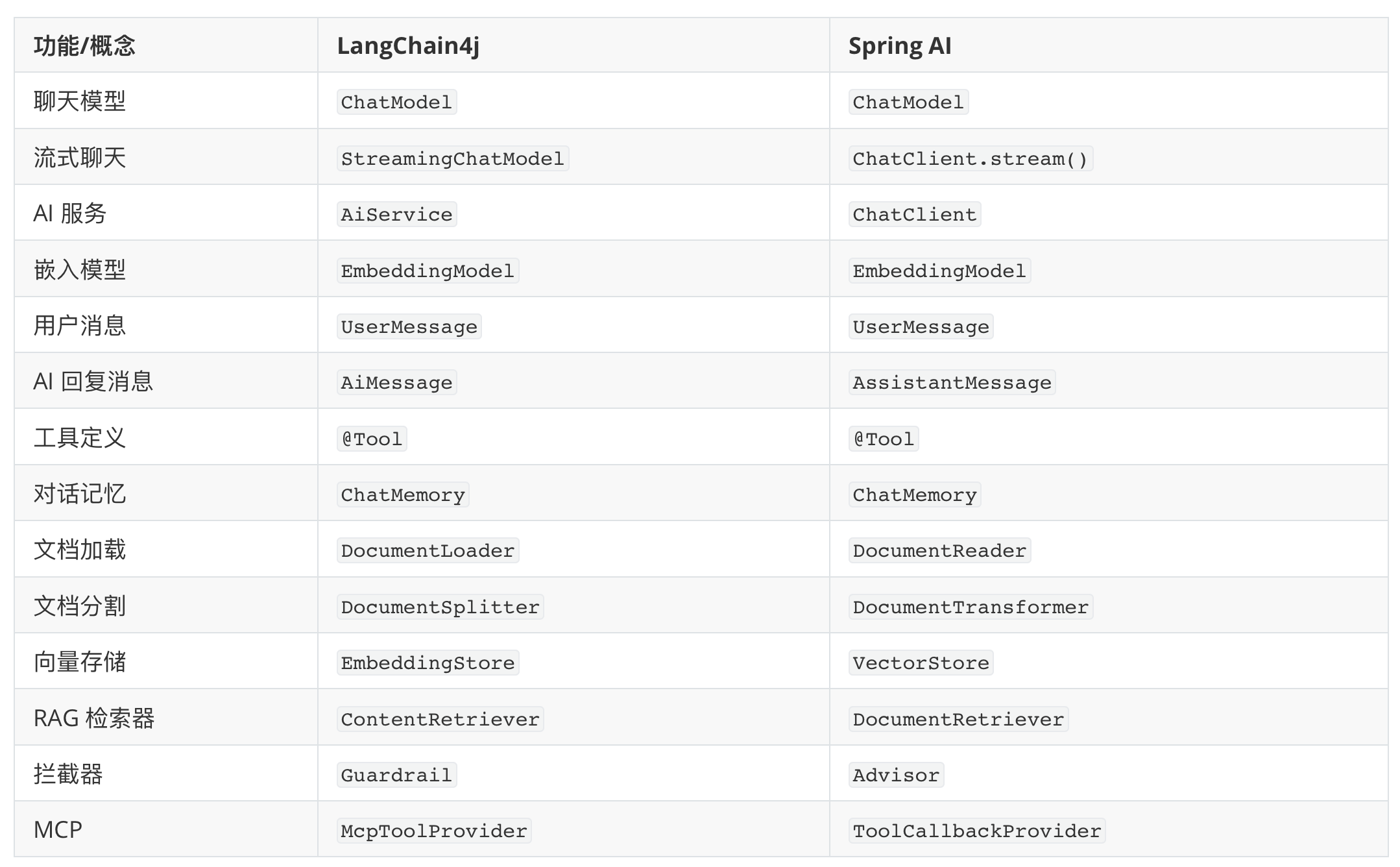
不过这类框架大家重点学习一个就好了,很多概念和用法是相通的:
最后友情提示,今天的这个小项目只是为我即将在 编程导航 带大家做的 AI 新项目打个基础,期待的话多多为我点赞吧~
更多编程学习资源
Java开发AI项目,太爽了!LangChain4j保姆级教程的更多相关文章
- Eclipse for C/C++ 开发环境部署保姆级教程
Eclipse for C/C++ 开发环境部署保姆级教程 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大 ...
- 【良心保姆级教程】java手把手教你用swing写一个学生的增删改查模块
很多刚入门的同学,不清楚如何用java.swing去开发出一个系统? 不清楚如何使用java代码去操作数据库进行增删改查一些列操作,不清楚java代码和数据库(mysql.sqlserver)之间怎么 ...
- java开发struts2项目遇到FilterDispatcher过时
由于工作需要,再次需要写一些简单的Java代码了,曾经的Java编程历历在目,但是却再也找不到以前的感觉了.于是便怀着对儿时Java的记忆,再次踏上Java Web Project. 在此特别鸣谢:h ...
- Java开发之项目分包
在我们开始准备写一个大点规模的项目时,我们不能随便地从main函数就开始往下写,要有清晰的逻辑思路和各个层面上的数据的传递和交互. 同时在我们写项目时也应该分出不同的包来做不同的事情,比如view包就 ...
- Java开发速度神器Lombok,Eclipse端安装使用教程
一.Lombok简介 Lombok是一个代码生成器,可以通过简单的注解形式来帮助我们简化消除一些必须有但显得很臃肿的Java代码的工具,通过使用对应的注解,可以在编译源码的时候生成对应的方法. 使用 ...
- 保姆级教程,如何发现 GitHub 上的优质项目?
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我的系列文章. ...
- 微软 New Bing AI 申请与使用保姆级教程(免魔法)
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问. 大家好,我是小彭. 最近的 AI 技术实在火爆,从 OpenAI 的 ChatGPT,到微软的 New Bi ...
- eclipse开发scrapy爬虫工程,附爬虫临门级教程
写在前面 自学爬虫入门之后感觉应该将自己的学习过程整理一下,也为了留个纪念吧. scrapy环境的配置还请自行百度,其实也不难(仅针对windows系统,centos配置了两天,直到现在都没整明白) ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- renren-fast-vue人人开源前端项目搭建保姆级教程
1.从gitee上clone项目 git clone https://gitee.com/renrenio/renren-fast-vue.git 2.准备好python环境 需要有Python2以上 ...
随机推荐
- Python科学计算系列9—逻辑代数
1.基本定理的验证 代码如下: from sympy import * A, B, C = symbols('A B C') # 重叠律 # A·A=A A+A=A print(to_cnf(A | ...
- 从零开始:基于CUDA 12.6的YOLOv5模型训练实战(RTX 2050显卡全流程)
基于cuda12.6训练yolov5模型 前面完成了使用CPU调用yolov5s模型进行识别车辆,现在想训练自己的模型进行目标识别,使用CPU效率太低,尝试使用GPU加速的Pytorch,再重新整理了 ...
- 参考案例之“对象调用方法时,如何在方法中使用对象,例如(root.display()的display方法中使用root)”
一.对象调用方法时,如何在方法中使用对象,例如(root.display()的display方法中使用root) 1.测试方法 @Test public void suanfa24() { TreeN ...
- 鸿蒙Next复杂列表性能优化:让滑动体验如丝般顺滑
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- C# HttpListener 和 HttpServer区别
HttpListener 和 HttpServer 都是 C# 中用于创建 HTTP 服务器的类库,它们的作用都是监听 HTTP 请求,并向客户端发送 HTTP 响应.它们的主要区别在于实现方式和使用 ...
- Django中的Ajax表单提交与文件上传
Django中Ajax表单提交 Ajax是以一种与服务器交换数据的技术,可以在不重载整个页面的情况下更新网页的一部分.它也可以运用在Django项目的表单中,与普通的views函数不一样的是:表单所在 ...
- 新纪元:"老"新人
博客园注册很久了,但从未发布过内容.终于开通博客,记录自己,也支持博客园! 另外,这次苹果秋季发布会真的好无聊!︎
- 从传统搜索到智能问答:自研 RAG 系统的技术实践与工程落地
一.引言 在数字化转型浪潮下,企业知识服务体系正经历着深刻变革.如何让用户高效获取所需信息,成为提升产品竞争力和用户满意度的关键.葡萄城作为企业级开发工具与解决方案提供商,长期致力于知识服务体系的建设 ...
- System.currentTimeMillis()高并发性能优化
摘要:System.currentTimeMillis()性能问题的研究.测试与优化. 性能优化使用的测试环境: jdk版本jdk8 操作系统: macOS 版本:13.2.1 芯片: App ...
- 解决Mac IntellIJ Idea 卡顿问题,修改内存大小
我们在工作中,经常会遇到因为IntellIJ Idea内存不足而卡顿的问题,可以通过两种方法调整idea的内存大小.我的IDEA版本是2021.2. 第一种调整内存的方法是 Change Me ...