python批量下载网易云音乐文件到本地
现在听歌大多数只支持在线听,下载要钱,没网络就白搭了。好吧,用技术手段解决免费、下载、批量等一些列问题
整个脚本的逻辑和流程是,把歌曲地址都存在一个txt中,然后循环每次取一条链接,分析链接对应歌曲的id和歌曲名,然后下载该歌曲,同时已歌曲名命名下载后的文件
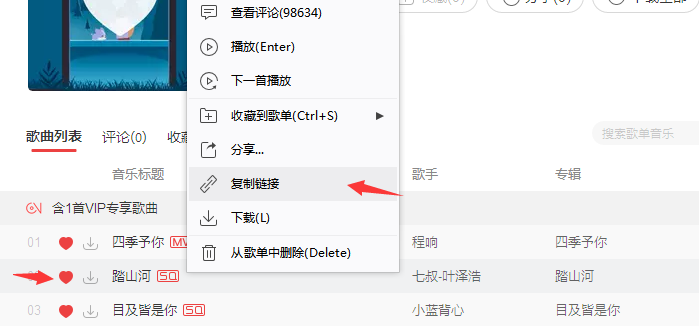
网易云音乐客户端复制音乐地址,比如上面那首《踏山河》:https://music.163.com/song?id=1804320463&userid=502092978
歌曲地址内有可以看到id=1804320463,需要把这串数字分离出来,后面下载会用到,用正则分离出来
url=“https://music.163.com/song?id=1804320463&userid=502092978“”
song_id=re.findall('id=(.+?)&userid',url)[0]
然后根据地址获取歌曲名称,这里使用的是xpath爬虫抓取数据
song_url=“https://music.163.com/song?id=1804320463&userid=502092978“”
response = requests.get(song_url,headers)
wb_data = response.text # 将页面转换成文档树
html = etree.HTML(wb_data)
music_name = html.xpath('//em[@class = "f-ff2"]/text()')[0]
再就是下载歌曲,下载歌曲需要用到网易云的专属下载接口,http://music.163.com/song/media/outer/url?id=,id=后面即填入上面步骤分离出来的歌曲id
response = requests.get("http://music.163.com/song/media/outer/url?id="+song_id+".mp3")
content = response.content
with open(music_name+'.mp3', mode="wb") as f:
f.write(content)
print("下载"+" "+music_name+" "+"完成")
然后在脚本目录下创建一个txt文件,把歌曲地址复制到文本内(每行一条地址)
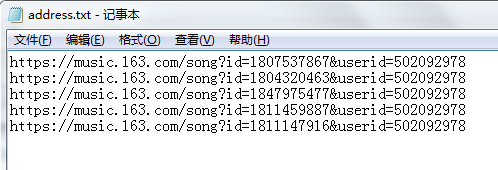
为了方便观察每一步获取的数据,再每一步操作后面加入把数据打印出来,执行脚本
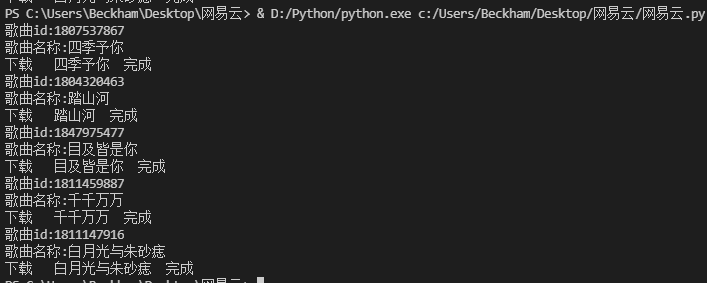
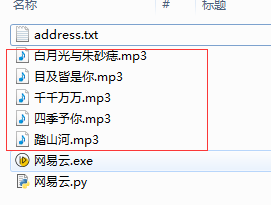
以上即是本案例的主要步骤和对应的脚本,至于读取txt文件等,就参考后面附上的所有脚本内容
同时,已经把脚本打包成exe文件,没有安装python的电脑环境也可以执行(加微信xiaobeishuwu发文件)
特别强调,不要下的太过分,仅仅是技术交流,商业牟利自负责任
附全部脚本
import requests #倒入requests库
from lxml import etree #倒入lxml 库(没有这个库,pip install lxml安装)
import re headers = {
'authority': 'music.163.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'nested-navigate',
'referer': 'https://music.163.com/',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '_iuqxldmzr_=32; _ntes_nuid=01c796eee1899b3e988043381c5fe3ed; WM_TID=bClwjpRRyMhFBRRUVVZ8eNGfcwSRUP4D; vjuids=91172de86.167ba393a03.0.751a7745c4db9; vjlast=1545017572.1572947033.22; mail_psc_fingerprint=73ad847ab9b5c4a03a9db849350e6c87; _ntes_nnid=01c796eee1899b3e988043381c5fe3ed,1606698119460; NMTID=00OIwuy7su1M7DopUdapOO9k7XQi98AAAF2Fqu0fA; _ga=GA1.2.1259495320.1607509476; P_INFO=zoulong1989@yeah.net|1607662298|0|mailyeah|00&99|hun&1606470131&mailyeah#hun&430100#10#0#0|&0|mailyeah|zoulong1989@yeah.net; ntes_kaola_ad=1; __guid=94650624.2334178747771955700.1621191366476.4607; WEVNSM=1.0.0; vinfo_n_f_l_n3=3d881b79189ff41c.1.12.1547520183001.1614838367331.1621988944652; WNMCID=ejsics.1623379617606.01.0; WM_NI=mdEEc6iEFx0kqT58oiR1ru7%2FkLYUA1PyRK6%2BTHLghGMimil%2BS5tVG%2FwgVucIvSbr8YLaHYx37EAxuzxT1dsFJEhDfawZAmKXmaade%2FrrEDFjQu3pQNMcaiAKD5mlJQ26TGI%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb2ea6a8a889cd1cc49ed9a8fb6d85b879b8f84f862baaaa5acd669b49f99b9eb2af0fea7c3b92aafbc8ba6e23eab9b8a99b361b38cfbd9ee6392efbe96b625a99497b6c43b94a79eacb52198988488eb4d8fb7a38aef2191ebbcb7c625b5b99a96e243b68dae93bb5390bf88bafb39f59b8f99f872bc8cff85f24e8a9ba8a5e56bb5868f8eca54afbfaf85e825b2ae8ba5c56293abfd91d4468fbdaf8ac44188eba38dc95bf2ea9ca8cc37e2a3; playerid=78983598; JSESSIONID-WYYY=%2FRnux48Q%2FpfVFCwSG6v2vRBRWVgCV%2B6Sq6AI4NdRfU527Dz%2FaA74w3xExYMzsWMrMCOh4w6fvc%5CM3inN2WkZQ3gtAUt%5CHwj4rtxKYCdj6OaYHu%2FxAthJgtmzw%2BaHzKUSz36Vo45aOsuf1Hq2NTx0N5qs7p%5CPc%2B6KB6ZvkhG5HvzS62pi%3A1629883157132; monitor_count=7',
} soure = open('address.txt', 'r')
value = soure.readlines()
soure.close() def download_music(value,headers):
#读取歌曲地址
for url in value:
url=url[:-1]#去掉换行符,然后url后面会带个空格,访问不了链接 #解析地址,获取歌曲名称和id
song_id=re.findall('id=(.+?)&userid',url)[0]
print("歌曲id:"+song_id)
song_url = "https://music.163.com/song?id="+song_id
response = requests.get(song_url,headers=headers)
wb_data = response.text # 将页面转换成文档树
html = etree.HTML(wb_data)
music_name = html.xpath('//em[@class = "f-ff2"]/text()')[0]
print("歌曲名称:"+music_name)
#将歌曲名称和id传入,下载歌曲
response = requests.get("http://music.163.com/song/media/outer/url?id="+song_id+".mp3",headers=hearders)
content = response.content
with open(music_name+'.mp3', mode="wb") as f:
f.write(content)
print("下载"+" "+music_name+" "+"完成")
download_music(value,headers)
python批量下载网易云音乐文件到本地的更多相关文章
- 如何下载网易云音乐APP里的MV和短视频?
本人:网易云音乐死粉,朋友圈大多都用的是云音乐,因为推荐功能牛逼 然后:发现云音乐APP里越来越多吸引我的短视频,经常看到好的就想保存到相册,然后微信发给朋友 但是:不知道怎么下载网易云音乐的短视频, ...
- 使用python3下载网易云音乐歌单歌曲,附源代码
""" 用selenium+PhantomJS配合,不需要进行逆向工程 python 3下的selenium不能默认安装,需要指定版本2.48.0 "" ...
- python3爬虫:下载网易云音乐排行榜
#!/usr/bin/python3# -*- encoding:utf-8 -*- # 网易云音乐批量下载 import requestsimport urllib # 榜单歌曲批量下载# r = ...
- 下载网易云音乐的MV
网易云音乐有很多经典视频, 但是苦于没有下载按钮...今天就记录下如何保存MV到本地, 又get一项新技能!!! 一. 安装360极速浏览器(非安利) 二. 打开网易云音乐客户端, 点击"等 ...
- python3爬虫-下载网易云音乐,评论
# -*- coding: utf-8 -*- ''' 16位随机字符的字符串 参数一 获取歌曲下载地址 "{"ids":"[1361348080]" ...
- Python下载网易云收藏
提前声明 仅作为个人学习使用,任何版权问题作者概不负责 本文的语言不会且不可能很严谨 博客园的编辑器有点BUG把我搞晕头了,所以本文可能有点鬼畜 前情 不知道各位有几个是对国内大厂的软件设计很满意的? ...
- python爬虫实例--网易云音乐排行榜爬虫
网易云音乐,以前是有个api 链接的json下载的,现在没了, 只有音乐id,title , 只能看播放请求了, 但是播放请求都是加密的值,好坑... 进过各种努力, 终于找到了个大神写的博客,3.6 ...
- python爬取网易云音乐评论及相关信息
python爬取网易云音乐评论及相关信息 urllib requests 正则表达式 爬取网易云音乐评论及相关信息 urllib了解 参考链接: https://www.liaoxuefeng.com ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
随机推荐
- try-catch-finally的使用
/* * 一.异常的处理:抓抛模型 * * 过程一:"抛":程序在正常执行的过程中,一旦出现异常,就会在异常代码处生成一个对应异常类的对象. * 并将此对象抛出. * 一旦抛出对象 ...
- Linux/Centos文件授权用户文件夹权限介绍
一.Linux文件权限介绍 在Linux中,一切皆为文件(目录也是文件),每个文件对用户具有可读(read).可写(write).可执行(excute)权限.目录的执行操作表示是否有权限进入该目录并操 ...
- USACO24DEC Cake Game S 题解 [ 黄 ] [ 前缀和 ] [ adhoc ]
Cake Game:小清新前缀和题,但是我场上想了半天优先队列贪心假完了 /ll/ll/ll. 观察 本题有三个重要的结论,我们依次进行观察. 不难发现,第二个牛一定会拿 \(\frac{n}{2}- ...
- 盘点10个.NetCore实用的开源框架项目
连续分享.Net开源项目快3个月了,今天我们一起梳理下10个,比较受到大家欢迎的.NetCore开源框架项目. 更多开源项目,可以查看我创建的,.Net开源项目榜单! 一个专注收集.Net开源项目的榜 ...
- 收集 Spring Boot 相关的学习资料
收集 Spring Boot 相关的学习资料,Spring Cloud点这里 重点推荐:Spring Boot 中文索引 推荐博客 纯洁的微笑-Spring Boot系列文章 林祥纤-从零开始学Spr ...
- autMan奥特曼机器人-自建autMan插件市场
一.自建市场配置 配置参数 二.上架设置 设置哪些插件上架,哪些不上架 三.检测是否成功 怎样检查是否成功了?订阅一下自己,然后看应用市场上是否显示 四.用户怎样购买插件 用户想买自建市场作者的插件, ...
- MySQL - [02] 常用SQL
题记部分 一.连接MySQL服务器 1.常规连接方式 # 连接本地mysql服务器 mysql -u 用户名 -p # 连接到指定mysql服务器,回车执行该命令之后需要输入密码 mysql -h 主 ...
- SpringBoot - [02] 第一个SpringBoot程序
jdk maven3.6.3 springboot最新版 idea 如果使用官网 Spring Initializr ,则需要jdk17.21.22,并且是Springboot3.x 可以在idea创 ...
- C#如何使用HttpClient对大文件进行断点上传和下载
什么是Http的断点上传和下载 断点上传:在向服务商上传大文件的时候,将一个大的文件拆分成多个小的文件,每个文件通过单独的Http请求上传给服务器. 断点下载:在向服务器请求下载一个大的资源文件的时候 ...
- [第四章]ABAQUS CM插件中文手册
ABAQUS Composite Modeler User Manual(zh-CN) Dassault Systèmes, 2018 注: 源文档的交叉引用链接,本文无效 有些语句英文表达更易理解, ...