使用ob_tools包收集分析oceanbase数据库oracle租户缓慢sql语句
概述
1、手册目的:
本手册旨在提供一种系统化的方法论,以便发现和分析慢SQL语句。通过使用ob_tools包,收集和分析在交付期间,应用程序在不同场景下进行压测时所产生的慢SQL语句,从而实现性能调优和优化建议。
2、文档内容:
本手册包含以下几个主要部分:
1. ob_tools包内存储过程和函数介绍:
详细介绍ob_tools包中的各个存储过程和函数的功能、使用方法以及参数说明,为读者提供清晰的理解和应用基础。
2. ob_tools包内存储过程和函数的不同场景使用案例:
针对不同的应用场景,提供具体的使用案例,展示如何利用这些存储过程和函数来收集和分析数据,以满足特定的性能需求。
3. 数据分析报表SQL介绍及使用案例
提供用于数据分析的SQL语句示例,说明如何使用报表分析SQL,并结合具体案例展示其应用效果,以帮助交付同学更好地理解性能瓶颈及优化方向。
3、需求背景:
较多客户反馈v$ob_sql_audit和gv$ob_sql_audit视图查询缓慢,且数据无法持久化,导致在复查问题或诊断性能故障时,除了OCP能够找到相关记录外,其他地方很难获取具体记录。
因此,针对这一问题,借着某银行项目期间,特别编写了相关持久化v$ob_sql_audit+分析数据的方法,以分析某核心系统ISV V8微服务(TCC架构)核心系统在不同场景下的联机交易压测需求。
通过系统化的数据收集和分析手段,本手册旨在帮助用户更有效地识别和解决性能问题。
1、先决条件
在使用 ob_tools 包之前,首先需要创建相应的数据库用户,并赋予该用户连接数据库、创建、修改、删除对象的权限。此外,还需要使用sys用户执行以下命令,以确保用户能够执行相关操作。
CREATE USER YZJ IDENYIFIED BY 123456;
GRANT DBA TO YZJ;
GRANT EXECUTE ON dbms_metadata TO YZJ;
创建好用户以后,还需要先需要确保相关数据库对象已被正确创建。
为此,我们提供了一个名为 manage_objects 的存储过程,用于初始化必要的数据库对象。
2、manage_objects 初始化存储过程
一、manage_objects.proc 代码
create or replace PROCEDURE manage_objects(p_action IN VARCHAR2) IS
-- 定义时间变量
v_start_time TIMESTAMP;
v_end_time TIMESTAMP;
v_elapsed_time INTERVAL DAY(2) TO SECOND(6);
-- 用于处理参数错误的异常
ex_invalid_action EXCEPTION;
PRAGMA EXCEPTION_INIT(ex_invalid_action, -20001);
-- 用于检查传入参数是否合法
PROCEDURE check_action(p_action IN VARCHAR2) IS
BEGIN
IF UPPER(p_action) NOT IN ('INIT', 'UPDATE', 'DELETE') THEN
RAISE ex_invalid_action;
END IF;
END check_action;
-- 打印操作信息
PROCEDURE log_info(p_message IN VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(p_message);
END log_info;
-- 记录操作时间
PROCEDURE log_time(p_start_time IN TIMESTAMP, p_end_time IN TIMESTAMP) IS
BEGIN
v_elapsed_time := p_end_time - p_start_time;
log_info('开始时间: ' || TO_CHAR(p_start_time, 'YYYY-MM-DD HH24:MI:SS.FF'));
log_info('结束时间: ' || TO_CHAR(p_end_time, 'YYYY-MM-DD HH24:MI:SS.FF'));
log_info('耗时: ' || TO_CHAR(v_elapsed_time));
END log_time;
BEGIN
/*
声明
过程名称: manage_objects
函数作用: 该存储过程用于根据传入参数来执行初始化(INIT)、更新(UPDATE)、删除(DELETE)数据库对象的操作。
创建日期: 2024-09-23
作者: (YZJ、须佐)
版本: v1.0
需求说明:
该存储过程实现了对数据库表、索引和序列的管理操作。根据传入参数控制不同的操作:
- INIT:创建所有相关表、索引、序列。
- UPDATE:更新部分表数据,并重建索引。
- DELETE:删除所有相关表、索引、序列。
每个操作执行的时间(开始、结束时间)及操作耗时会被记录并输出,以方便调试和监控。
创建前提:
在创建此存储过程之前,需要确保具备如下对象管理权限:
- 创建/删除表
- 创建/删除索引
- 创建/删除序列
操作内容:
1. INIT 操作:
- 创建以下表结构:XZ_SQL_AUDIT, XZ_CDC_LOG, XZ_SQL_AUDIT_CDC。
- 创建序列:SEQ_XZ_SQL_AUDIT_CDC_CID。
- 创建索引:IDX_XZSQLAUDIT_INDEX2, IDX_XZ_INDEXES_INDEX1, IDX_XZ_OBJECTS_INDEX1。
- 每个表、序列和索引的创建过程都会记录详细的执行时间。
2. UPDATE 操作:
- TRUNCATE 表 `XZ_INDEXES` 和 `XZ_OBJECTS`,并重新导入数据。
- 重新导入 DBA_INDEXES 和 DBA_OBJECTS 中的数据,并重建索引。
- 操作期间将记录执行时间和操作结果。
3. DELETE 操作:
- 删除所有创建的表、索引和序列。
- 删除过程中将记录执行的操作和时间。
调用方法:
根据所需的操作,传入不同的参数:
```
BEGIN
manage_objects('INIT'); -- 创建对象
END;
/
BEGIN
manage_objects('UPDATE'); -- 更新数据
END;
/
BEGIN
manage_objects('DELETE'); -- 删除对象
END;
/
```
注意事项:
- 参数必须为 'INIT', 'UPDATE' 或 'DELETE',如果传入其他参数,存储过程将抛出异常并停止执行。
- 执行过程中会有大量的日志信息输出,确保开启 `DBMS_OUTPUT.PUT_LINE`。
*/
-- 检查参数是否合法
check_action(UPPER(p_action));
IF UPPER(p_action) = 'INIT' THEN
-- 初始化对象创建
log_info('================ INIT - 创建表、索引、序列 ================');
-- 创建表 XZ_SQL_AUDIT
log_info('开始创建表: XZ_SQL_AUDIT');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE '
CREATE TABLE XZ_SQL_AUDIT (
C_ID NUMBER(38),C_RQ_TIME TIMESTAMP(6),C_BATCH_ID NUMBER(38),C_NAME VARCHAR2(100),C_FLAG CHAR(2),SVR_IP VARCHAR2(46),SVR_PORT NUMBER(38),
REQUEST_ID NUMBER(38),SQL_EXEC_ID NUMBER(38),TRACE_ID VARCHAR2(128),SID NUMBER(38),CLIENT_IP VARCHAR2(46),CLIENT_PORT NUMBER(38),TENANT_ID NUMBER(38),
EFFECTIVE_TENANT_ID NUMBER(38),TENANT_NAME VARCHAR2(64),USER_ID NUMBER(38),USER_NAME VARCHAR2(64),USER_GROUP NUMBER(38),USER_CLIENT_IP VARCHAR2(46),
DB_ID NUMBER(38),DB_NAME VARCHAR2(128),SQL_ID VARCHAR2(32),QUERY_SQL VARCHAR2(4000),PLAN_ID NUMBER(38),AFFECTED_ROWS NUMBER(38),RETURN_ROWS NUMBER(38),
PARTITION_CNT NUMBER(38),RET_CODE NUMBER(38),QC_ID NUMBER(38),DFO_ID NUMBER(38),SQC_ID NUMBER(38),WORKER_ID NUMBER(38),EVENT VARCHAR2(64),P1TEXT VARCHAR2(64),
P1 NUMBER(38),P2TEXT VARCHAR2(64),P2 NUMBER(38),P3TEXT VARCHAR2(64),P3 NUMBER(38),WAIT_CLASS_ID NUMBER(38),WAIT_CLASS# NUMBER(38),WAIT_CLASS VARCHAR2(64),
STATE VARCHAR2(19),WAIT_TIME_MICRO NUMBER(38),TOTAL_WAIT_TIME_MICRO NUMBER(38),TOTAL_WAITS NUMBER(38),RPC_COUNT NUMBER(38),PLAN_TYPE NUMBER(38),
IS_INNER_SQL NUMBER(38),IS_EXECUTOR_RPC NUMBER(38),IS_HIT_PLAN NUMBER(38),REQUEST_TIME NUMBER(38),ELAPSED_TIME NUMBER(38),NET_TIME NUMBER(38),NET_WAIT_TIME NUMBER(38),
QUEUE_TIME NUMBER(38),DECODE_TIME NUMBER(38),GET_PLAN_TIME NUMBER(38),EXECUTE_TIME NUMBER(38),APPLICATION_WAIT_TIME NUMBER(38),CONCURRENCY_WAIT_TIME NUMBER(38),
USER_IO_WAIT_TIME NUMBER(38),SCHEDULE_TIME NUMBER(38),ROW_CACHE_HIT NUMBER(38),BLOOM_FILTER_CACHE_HIT NUMBER(38),BLOCK_CACHE_HIT NUMBER(38),DISK_READS NUMBER(38),
RETRY_CNT NUMBER(38),TABLE_SCAN NUMBER(38),CONSISTENCY_LEVEL NUMBER(38),MEMSTORE_READ_ROW_COUNT NUMBER(38),SSSTORE_READ_ROW_COUNT NUMBER(38),DATA_BLOCK_READ_CNT NUMBER(38),
DATA_BLOCK_CACHE_HIT NUMBER(38),INDEX_BLOCK_READ_CNT NUMBER(38),INDEX_BLOCK_CACHE_HIT NUMBER(38),BLOCKSCAN_BLOCK_CNT NUMBER(38),BLOCKSCAN_ROW_CNT NUMBER(38),
PUSHDOWN_STORAGE_FILTER_ROW_CNT NUMBER(38),REQUEST_MEMORY_USED NUMBER(38),EXPECTED_WORKER_COUNT NUMBER(38),USED_WORKER_COUNT NUMBER(38),SCHED_INFO VARCHAR2(16384),
PS_CLIENT_STMT_ID NUMBER(38),PS_INNER_STMT_ID NUMBER(38),TX_ID NUMBER(38),SNAPSHOT_VERSION NUMBER(38),REQUEST_TYPE NUMBER(38),IS_BATCHED_MULTI_STMT NUMBER(38),
OB_TRACE_INFO VARCHAR2(4096),PLAN_HASH NUMBER(38),PARAMS_VALUE CLOB,RULE_NAME VARCHAR2(256),TX_INTERNAL_ROUTING NUMBER,TX_STATE_VERSION NUMBER(38),FLT_TRACE_ID VARCHAR2(1024),
NETWORK_WAIT_TIME NUMBER(38),PRIMARY KEY (C_ID, C_BATCH_ID)
) partition by range(C_BATCH_ID) subpartition by hash(C_ID)
(partition P1 values less than (200) (subpartition subp0,subpartition subp1,subpartition subp2,subpartition subp3,subpartition subp4,subpartition subp5,subpartition subp6,subpartition subp7,subpartition subp8,subpartition subp9),
partition P2 values less than (400) (subpartition subp10,subpartition subp11,subpartition subp12,subpartition subp13,subpartition subp14,subpartition subp15,subpartition subp16,subpartition subp17,subpartition subp18,subpartition subp19),
partition P3 values less than (600) (subpartition subp20,subpartition subp21,subpartition subp22,subpartition subp23,subpartition subp24,subpartition subp25,subpartition subp26,subpartition subp27,subpartition subp28,subpartition subp29),
partition P4 values less than (800) (subpartition subp30,subpartition subp31,subpartition subp32,subpartition subp33,subpartition subp34,subpartition subp35,subpartition subp36,subpartition subp37,subpartition subp38,subpartition subp39),
partition P5 values less than (1000) (subpartition subp40,subpartition subp41,subpartition subp42,subpartition subp43,subpartition subp44,subpartition subp45,subpartition subp46,subpartition subp47,subpartition subp48,subpartition subp49),
partition P_MAX VALUES LESS THAN (MAXVALUE) (subpartition subp50,subpartition subp51,subpartition subp52,subpartition subp53,subpartition subp54,subpartition subp55,subpartition subp56,subpartition subp57,subpartition subp58,subpartition subp59))
';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建索引 IDX_XZSQLAUDIT_INDEX2
log_info('开始创建索引: IDX_XZSQLAUDIT_INDEX2');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE INDEX IDX_XZSQLAUDIT_INDEX2 on XZ_SQL_AUDIT (C_BATCH_ID, C_NAME, USER_NAME, SQL_ID, RETRY_CNT, RPC_COUNT,QUERY_SQL, NET_TIME, NET_WAIT_TIME, QUEUE_TIME, DECODE_TIME, GET_PLAN_TIME, EXECUTE_TIME, ELAPSED_TIME) LOCAL';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建序列 SEQ_XZ_SQL_AUDIT_CDC_CID
log_info('开始创建序列: SEQ_XZ_SQL_AUDIT_CDC_CID');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE SEQUENCE SEQ_XZ_SQL_AUDIT_CDC_CID MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 CACHE 10000 NOORDER NOCYCLE';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建日志表 XZ_CDC_LOG
log_info('开始创建表: XZ_CDC_LOG');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE TABLE XZ_CDC_LOG (C_BATCH_ID NUMBER, C_START_TIME TIMESTAMP(6), C_END_TIME TIMESTAMP(6), C_START_SCN NUMBER, C_END_SCN NUMBER, C_EXECUTE_TIME INTERVAL DAY(2) TO SECOND(6), PRIMARY KEY (C_BATCH_ID))';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建分析表 XZ_SQL_AUDIT_CDC
log_info('开始创建表: XZ_SQL_AUDIT_CDC');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE '
CREATE TABLE XZ_SQL_AUDIT_CDC (
C_ID NUMBER(38) DEFAULT SEQ_XZ_SQL_AUDIT_CDC_CID.NEXTVAL,C_BATCH_ID NUMBER(38),SVR_IP VARCHAR2(46),SVR_PORT NUMBER(38),REQUEST_ID NUMBER(38),SQL_EXEC_ID NUMBER(38),
TRACE_ID VARCHAR2(128),SID NUMBER(38),CLIENT_IP VARCHAR2(46),CLIENT_PORT NUMBER(38),TENANT_ID NUMBER(38),EFFECTIVE_TENANT_ID NUMBER(38),TENANT_NAME VARCHAR2(64),
USER_ID NUMBER(38),USER_NAME VARCHAR2(64),USER_GROUP NUMBER(38),USER_CLIENT_IP VARCHAR2(46),DB_ID NUMBER(38),DB_NAME VARCHAR2(128),SQL_ID VARCHAR2(32),QUERY_SQL VARCHAR2(4000),
PLAN_ID NUMBER(38),AFFECTED_ROWS NUMBER(38),RETURN_ROWS NUMBER(38),PARTITION_CNT NUMBER(38),RET_CODE NUMBER(38),QC_ID NUMBER(38),DFO_ID NUMBER(38),SQC_ID NUMBER(38),
WORKER_ID NUMBER(38),EVENT VARCHAR2(64),P1TEXT VARCHAR2(64),P1 NUMBER(38),P2TEXT VARCHAR2(64),P2 NUMBER(38),P3TEXT VARCHAR2(64),P3 NUMBER(38),WAIT_CLASS_ID NUMBER(38),
WAIT_CLASS# NUMBER(38),WAIT_CLASS VARCHAR2(64),STATE VARCHAR2(19),WAIT_TIME_MICRO NUMBER(38),TOTAL_WAIT_TIME_MICRO NUMBER(38),TOTAL_WAITS NUMBER(38),RPC_COUNT NUMBER(38),
PLAN_TYPE NUMBER(38),IS_INNER_SQL NUMBER(38),IS_EXECUTOR_RPC NUMBER(38),IS_HIT_PLAN NUMBER(38),REQUEST_TIME NUMBER(38),ELAPSED_TIME NUMBER(38),NET_TIME NUMBER(38),
NET_WAIT_TIME NUMBER(38),QUEUE_TIME NUMBER(38),DECODE_TIME NUMBER(38),GET_PLAN_TIME NUMBER(38),EXECUTE_TIME NUMBER(38),APPLICATION_WAIT_TIME NUMBER(38),
CONCURRENCY_WAIT_TIME NUMBER(38),USER_IO_WAIT_TIME NUMBER(38),SCHEDULE_TIME NUMBER(38),ROW_CACHE_HIT NUMBER(38),BLOOM_FILTER_CACHE_HIT NUMBER(38),BLOCK_CACHE_HIT NUMBER(38),
DISK_READS NUMBER(38),RETRY_CNT NUMBER(38),TABLE_SCAN NUMBER(38),CONSISTENCY_LEVEL NUMBER(38),MEMSTORE_READ_ROW_COUNT NUMBER(38),SSSTORE_READ_ROW_COUNT NUMBER(38),
DATA_BLOCK_READ_CNT NUMBER(38),DATA_BLOCK_CACHE_HIT NUMBER(38),INDEX_BLOCK_READ_CNT NUMBER(38),INDEX_BLOCK_CACHE_HIT NUMBER(38),BLOCKSCAN_BLOCK_CNT NUMBER(38),BLOCKSCAN_ROW_CNT NUMBER(38),
PUSHDOWN_STORAGE_FILTER_ROW_CNT NUMBER(38),REQUEST_MEMORY_USED NUMBER(38),EXPECTED_WORKER_COUNT NUMBER(38),USED_WORKER_COUNT NUMBER(38),SCHED_INFO VARCHAR2(16384),
PS_CLIENT_STMT_ID NUMBER(38),PS_INNER_STMT_ID NUMBER(38),TX_ID NUMBER(38),SNAPSHOT_VERSION NUMBER(38),REQUEST_TYPE NUMBER(38),IS_BATCHED_MULTI_STMT NUMBER(38),
OB_TRACE_INFO VARCHAR2(4096),PLAN_HASH NUMBER(38),PARAMS_VALUE CLOB,RULE_NAME VARCHAR2(256),TX_INTERNAL_ROUTING NUMBER,TX_STATE_VERSION NUMBER(38),FLT_TRACE_ID VARCHAR2(1024),
NETWORK_WAIT_TIME NUMBER(38),PRIMARY KEY (C_ID, REQUEST_TIME)) partition by hash(REQUEST_TIME)
(partition P0,partition P1,partition P2,partition P3,partition P4,partition P5,partition P6,partition P7,partition P8,partition P9,partition P10,partition P11,partition P12,
partition P13,partition P14,partition P15,partition P16,partition P17,partition P18,partition P19,partition P20,partition P21,partition P22,partition P23,partition P24,partition P25,
partition P26,partition P27,partition P28,partition P29,partition P30,partition P31,partition P32,partition P33,partition P34,partition P35,partition P36,partition P37,partition P38,partition P39)
';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建索引 IDX_XZSQLAUDITCDC_INDEX2
log_info('开始创建索引: IDX_XZSQLAUDITCDC_INDEX2');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE INDEX IDX_XZSQLAUDITCDC_INDEX2 on XZ_SQL_AUDIT_CDC (C_BATCH_ID, DB_NAME,USER_NAME, SQL_ID, RETRY_CNT, RPC_COUNT,QUERY_SQL, NET_TIME, NET_WAIT_TIME, QUEUE_TIME, DECODE_TIME, GET_PLAN_TIME, EXECUTE_TIME, ELAPSED_TIME) LOCAL';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建辅助表 XZ_INDEXES
log_info('开始创建表: XZ_INDEXES');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE TABLE XZ_INDEXES AS
SELECT /*+PARALLEL(30)*/
upper(a.table_owner) table_owner,
upper(a.table_name) table_name,
count(distinct case when a.partitioned = ''YES'' then a.index_name else null end) local_index_cnt,
count(distinct case when a.partitioned = ''NO'' then a.index_name else null end ) global_index_cnt,
count(distinct case when b.constraint_type = ''P'' then b.constraint_name else null end) pk_cnt
FROM dba_indexes a inner join dba_constraints b on a.table_owner = b.owner and a.table_name = b.table_name
group by a.table_owner, a.table_name';
v_end_time := SYSTIMESTAMP;
commit;
log_time(v_start_time, v_end_time);
-- 创建索引 IDX_XZINDEX_INDEX1
log_info('开始创建索引: IDX_XZINDEX_INDEX1');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE INDEX IDX_XZINDEX_INDEX1 on XZ_INDEXES (TABLE_OWNER,TABLE_NAME)';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建辅助表 XZ_OBJECTS
log_info('开始创建表: XZ_OBJECTS');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE TABLE XZ_OBJECTS AS SELECT * FROM DBA_OBJECTS';
commit;
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- 创建索引 IDX_XZOBJECTS_INDEX1
log_info('开始创建索引: IDX_XZOBJECTS_INDEX1');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'CREATE INDEX IDX_XZOBJECTS_INDEX1 on XZ_OBJECTS (OWNER,OBJECT_NAME,OBJECT_TYPE)';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
ELSIF UPPER(p_action) = 'UPDATE' THEN
-- 更新操作
log_info('================ UPDATE - 更新表 XZ_INDEXES 和 XZ_OBJECTS ================');
-- TRUNCATE TABLE XZ_INDEXES 并重新导入数据
log_info('开始清空表: XZ_INDEXES');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'TRUNCATE TABLE XZ_INDEXES';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('重新导入数据到 XZ_INDEXES');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'INSERT /*+PARALLEL(30)*/ INTO XZ_INDEXES
SELECT upper(a.table_owner), upper(a.table_name),
count(distinct case when a.partitioned = ''YES'' then a.index_name else null end) local_index_cnt,
count(distinct case when a.partitioned = ''NO'' then a.index_name else null end) global_index_cnt,
count(distinct case when b.constraint_type = ''P'' then b.constraint_name else null end) pk_cnt
FROM dba_indexes a INNER JOIN dba_constraints b ON a.table_owner = b.owner AND a.table_name = b.table_name
GROUP BY a.table_owner, a.table_name';
commit;
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
-- TRUNCATE TABLE XZ_OBJECTS 并重新导入数据
log_info('开始清空表: XZ_OBJECTS');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'TRUNCATE TABLE XZ_OBJECTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('重新导入数据到 XZ_OBJECTS');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'INSERT INTO XZ_OBJECTS SELECT * FROM DBA_OBJECTS';
commit;
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
ELSIF UPPER(p_action) = 'DELETE' THEN
-- 删除所有对象
log_info('================ DELETE - 删除所有表、索引和序列 ================');
-- 删除索引、序列、表
log_info('开始删除表: XZ_SQL_AUDIT');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP TABLE XZ_SQL_AUDIT CASCADE CONSTRAINTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('开始删除序列: SEQ_XZ_SQL_AUDIT_CDC_CID');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP SEQUENCE SEQ_XZ_SQL_AUDIT_CDC_CID';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('开始删除表: XZ_CDC_LOG');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP TABLE XZ_CDC_LOG CASCADE CONSTRAINTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('开始删除表: XZ_SQL_AUDIT_CDC');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP TABLE XZ_SQL_AUDIT_CDC CASCADE CONSTRAINTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('开始删除表: XZ_INDEXES');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP TABLE XZ_INDEXES CASCADE CONSTRAINTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
log_info('开始删除表: XZ_OBJECTS');
v_start_time := SYSTIMESTAMP;
EXECUTE IMMEDIATE 'DROP TABLE XZ_OBJECTS CASCADE CONSTRAINTS';
v_end_time := SYSTIMESTAMP;
log_time(v_start_time, v_end_time);
END IF;
EXCEPTION
WHEN ex_invalid_action THEN
DBMS_OUTPUT.PUT_LINE('传入的参数不正确!参数应为 INIT, UPDATE 或 DELETE');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('发生异常: ' || SQLERRM);
END manage_objects;
**manage_objects** 存储过程的主要功能是根据传入的参数创建、更新或删除数据库对象。
该过程可以执行三种操作:
- INIT:创建所有所需的表、索引和序列。
- UPDATE:更新部分表数据并重建索引。
- DELETE:删除所有相关的表、索引和序列。
二、manage_objects 使用方法
在调用 manage_objects 存储过程之前,请确保具备足够的权限(如创建/删除表、索引、序列等)。
BEGIN
manage_objects( p_action => 'INIT'); -- 创建对象
END;
/
BEGIN
manage_objects( p_action => 'UPDATE'); -- 更新数据
END;
/
BEGIN
manage_objects( p_action => 'DELETE'); -- 删除对象
END;
/
obclient [YZJ]> set serveroutput on;
obclient [YZJ]> BEGIN
-> manage_objects('DELETE'); -- 删除对象
-> END;
-> /
Query OK, 1 row affected (1.359 sec)
================ DELETE - 删除所有表、索引和序列 ================
开始删除表: XZ_SQL_AUDIT
开始时间: 2024-09-28 11:22:39.684759
结束时间: 2024-09-28 11:22:39.864360
耗时: +00 00:00:00.179601
开始删除序列: SEQ_XZ_SQL_AUDIT_CDC_CID
开始时间: 2024-09-28 11:22:39.865110
结束时间: 2024-09-28 11:22:39.903495
耗时: +00 00:00:00.038385
开始删除表: XZ_CDC_LOG
开始时间: 2024-09-28 11:22:39.904163
结束时间: 2024-09-28 11:22:39.957957
耗时: +00 00:00:00.053794
开始删除表: XZ_SQL_AUDIT_CDC
开始时间: 2024-09-28 11:22:39.958671
结束时间: 2024-09-28 11:22:40.101779
耗时: +00 00:00:00.143108
开始删除表: XZ_INDEXES
开始时间: 2024-09-28 11:22:40.102526
结束时间: 2024-09-28 11:22:40.163580
耗时: +00 00:00:00.061054
开始删除表: XZ_OBJECTS
开始时间: 2024-09-28 11:22:40.164344
结束时间: 2024-09-28 11:22:40.236159
耗时: +00 00:00:00.071815
obclient [YZJ]>
obclient [YZJ]>
obclient [YZJ]> BEGIN
-> manage_objects('INIT'); -- 创建对象
-> END;
-> /
Query OK, 1 row affected (3.797 sec)
================ INIT - 创建表、索引、序列 ================
开始创建表: XZ_SQL_AUDIT
开始时间: 2024-09-28 11:21:35.216756
结束时间: 2024-09-28 11:21:35.465584
耗时: +00 00:00:00.248828
开始创建索引: IDX_XZSQLAUDIT_INDEX2
开始时间: 2024-09-28 11:21:35.466338
结束时间: 2024-09-28 11:21:37.852109
耗时: +00 00:00:02.385771
开始创建序列: SEQ_XZ_SQL_AUDIT_CDC_CID
开始时间: 2024-09-28 11:21:37.852915
结束时间: 2024-09-28 11:21:37.893742
耗时: +00 00:00:00.040827
开始创建表: XZ_CDC_LOG
开始时间: 2024-09-28 11:21:37.894449
结束时间: 2024-09-28 11:21:37.977595
耗时: +00 00:00:00.083146
开始创建表: XZ_SQL_AUDIT_CDC
开始时间: 2024-09-28 11:21:37.978392
结束时间: 2024-09-28 11:21:38.178886
耗时: +00 00:00:00.200494
开始创建索引: IDX_XZSQLAUDITCDC_INDEX2
开始时间: 2024-09-28 11:21:38.179642
结束时间: 2024-09-28 11:21:39.721940
耗时: +00 00:00:01.542298
开始创建表: XZ_INDEXES
开始时间: 2024-09-28 11:21:39.722672
结束时间: 2024-09-28 11:21:40.373707
耗时: +00 00:00:00.651035
开始创建索引: IDX_XZINDEX_INDEX1
开始时间: 2024-09-28 11:21:40.374425
结束时间: 2024-09-28 11:21:40.653932
耗时: +00 00:00:00.279507
开始创建表: XZ_OBJECTS
开始时间: 2024-09-28 11:21:40.654757
结束时间: 2024-09-28 11:21:41.069441
耗时: +00 00:00:00.414684
开始创建索引: IDX_XZOBJECTS_INDEX1
开始时间: 2024-09-28 11:21:41.070205
结束时间: 2024-09-28 11:21:41.349171
耗时: +00 00:00:00.278966
obclient [YZJ]>
obclient [YZJ]>
obclient [YZJ]> BEGIN
-> manage_objects('UPDATE'); -- 更新数据
-> END;
-> /
Query OK, 1 row affected (0.741 sec)
================ UPDATE - 更新表 XZ_INDEXES 和 XZ_OBJECTS ================
开始清空表: XZ_INDEXES
开始时间: 2024-09-28 11:24:55.138446
结束时间: 2024-09-28 11:24:55.211236
耗时: +00 00:00:00.072790
重新导入数据到 XZ_INDEXES
开始时间: 2024-09-28 11:24:55.211981
结束时间: 2024-09-28 11:24:55.586314
耗时: +00 00:00:00.374333
开始清空表: XZ_OBJECTS
开始时间: 2024-09-28 11:24:55.587017
结束时间: 2024-09-28 11:24:55.656094
耗时: +00 00:00:00.069077
重新导入数据到 XZ_OBJECTS
开始时间: 2024-09-28 11:24:55.656805
结束时间: 2024-09-28 11:24:55.937035
耗时: +00 00:00:00.280230
当调用 manage_objects 时,根据传入的参数,存储过程会执行相应的操作:
- INIT 操作:创建以下对象:
- 表
XZ_SQL_AUDIT - 表
XZ_CDC_LOG - 表
XZ_SQL_AUDIT_CDC - 序列
SEQ_XZ_SQL_AUDIT_CDC_CID - 索引
IDX_XZSQLAUDIT_INDEX2和其他辅助表xz_indexes和xz_objects。
- 表
- UPDATE 操作:更新
xz_indexes和xz_objects辅助表的数据,具体作用后续会介绍到。 - DELETE 操作:删除所有创建的表、索引和序列。
三、***注意事项***
运行该存储过程后,确保其成功完成,才能继续编译 **ob_tools** 包。
3、ob_tools 包介绍使用
ob_tools 包目前包含以下过程和函数:
**extract_sqlaudit_proc**:从gv$ob_sql_audit视图提取指定时间段内的 SQL 执行数据,并存储到xz_sql_audit表中,便于后续分析和优化。**real_time_cdc_proc**:实时收集gv$ob_sql_audit中的数据,并固化到xz_sql_audit_cdc表,以便在长时间运行的任务中保持数据的有效性。**get_table_name**:从 SQL 语句中提取一个或多个表名,帮助用户了解涉及的表。**get_table_info**:获取多个表的详细信息,包括分区规则、索引数量和数据行数,便于用户SQL优化期能快速了解到涉及到的表的相关信息。
未来会持续更新,增加更多功能以满足不同需求。
****** 注意 ******
该工具代码是在 ob 4.2.1.7 版本开始编写第一个过程,在 ob 4.2.1.8 版本增加新的过程与函数。如果使用该工具分析sql性能问题,建议在 ob 4.2.1.7 版本后使用。
CREATE OR REPLACE PACKAGE ob_tools IS
-- 联机压测收集数据存储过程
PROCEDURE extract_sqlaudit_proc(P_NAME VARCHAR2, p_FLAG char, P_START_TIME VARCHAR2, p_END_TIME VARCHAR2);
-- 跑批实时拉取数据存储过程
PROCEDURE real_time_cdc_proc(p_END_TIME VARCHAR2 );
-- 通过SQL文本获取表名
FUNCTION get_table_name(p_owner varchar2 ,p_string_sql clob) RETURN VARCHAR2;
-- 通过表名获取表信息
FUNCTION get_table_info(p_tablename_list VARCHAR2) RETURN VARCHAR2;
END ob_tools;
/
CREATE OR REPLACE PACKAGE BODY ob_tools IS
PROCEDURE extract_sqlaudit_proc(P_NAME VARCHAR2, p_FLAG char, P_START_TIME VARCHAR2, p_END_TIME VARCHAR2)
IS
V_NAME VARCHAR2(100):=upper(P_NAME); -- 场景名称
V_FLAG CHAR(2) :=upper(p_FLAG); -- s 为拉取单个事务,m 为拉取多个事务(压测)
V_MAX_BATCH INT;
V_START_TIME VARCHAR2(100):=P_START_TIME; --开始时间
V_END_TIME VARCHAR2(100):=p_END_TIME; --结束时间
V_START_SCN NUMBER;
V_END_SCN NUMBER;
/*
V_NAME:场景名称
V_FLAG:S为拉取单个事务,M为拉取多个事务(压测)
V_MAX_BATCH:记录批次数
*/
V_SQL VARCHAR2(4000);
V_FLAG_EXCEPTION EXCEPTION;
V_END_TIME_SMALL_EXCEPTION EXCEPTION;
BEGIN
/*
声明
过程名称: extract_sqlaudit_proc
功能描述: 该存储过程用于从 `gv$ob_sql_audit` 视图中提取指定时间段内的数据,并将其存储到 `xz_sql_audit` 表中,以便后续分析。
创建日期: 2024-08-15
作者: (YZJ、须佐)
版本: v1.2
需求背景:
本存储过程是为满足 XX 银行某核心系统ISV V8 微服务(TCC 架构)核心系统在不同场景下的联机交易压测需求而编写。
通过收集压测期间的数据,可以分析出缓慢 SQL,并提供优化建议。
分析手段需要手动编写分析 SQL。
创建前提:
必须预先创建 `xz_sql_audit` 分析表,以确保 `extract_sqlaudit_proc` 过程能够成功编译。
调用方法:
建议使用 obclient 命令行工具,并开启服务输出选项:
```
set serveroutput on;
```
调用示例:
```
BEGIN
extract_sqlaudit_proc(
P_NAME => 'IB1261一借一贷 单笔交易',
-- 描述收集数据的具体场景和用途。
-- 若为并发压测数据,可写为:'IB1261 200并发压测 5分钟'
p_FLAG => 'S',
-- 指定压测类型:单交易为 'S',并发为 'M'
P_START_TIME => '2024-09-03 18:06:00',
-- 指定压测的开始时间
p_END_TIME => '2024-09-03 18:06:20'
-- 指定压测的结束时间
);
END;
/
```
*/
IF TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6') > TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6') THEN
RAISE V_END_TIME_SMALL_EXCEPTION;
END IF;
IF V_FLAG != 'S' AND V_FLAG != 'M' THEN
RAISE V_FLAG_EXCEPTION;
END IF;
-- 找到最大批次数加1
SELECT NVL(MAX(C_BATCH_ID),0) +1 INTO V_MAX_BATCH FROM XZ_SQL_AUDIT;
-- 将传进来的值转换成字符串时间戳格式。
V_START_TIME := TO_CHAR(TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6'),'YYYY-MM-DD HH24:MI:SS:FF6');
V_END_TIME := TO_CHAR(TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6'),'YYYY-MM-DD HH24:MI:SS:FF6');
V_START_SCN := timestamp_to_scn(TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6')) / 1000 ; -- 将开始时间转成开始scn
V_END_SCN := timestamp_to_scn(TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6')) / 1000 ; -- 将结束时间转成结束scn
V_SQL:='
insert /*+ ENABLE_PARALLEL_DML PARALLEL(16)*/ into XZ_SQL_AUDIT
select (:1 * 10000000000)+i , scn_to_timestamp(x.request_time * 1000),:2,:3,:4,
x.SVR_IP,x.SVR_PORT,x.REQUEST_ID,x.SQL_EXEC_ID,x.TRACE_ID,x.SID,x.CLIENT_IP,x.CLIENT_PORT,
x.TENANT_ID,x.EFFECTIVE_TENANT_ID,x.TENANT_NAME,x.USER_ID,x.USER_NAME,x.USER_GROUP,x.USER_CLIENT_IP,
x.DB_ID,x.DB_NAME,x.SQL_ID,to_char(substr(x.QUERY_SQL,1,3995)),x.PLAN_ID,x.AFFECTED_ROWS,x.RETURN_ROWS,x.PARTITION_CNT,
x.RET_CODE,x.QC_ID,x.DFO_ID,x.SQC_ID,x.WORKER_ID,x.EVENT,x.P1TEXT,x.P1,x.P2TEXT,x.P2,x.P3TEXT,x.P3,
x.WAIT_CLASS_ID,x.WAIT_CLASS#,x.WAIT_CLASS,x.STATE,x.WAIT_TIME_MICRO,x.TOTAL_WAIT_TIME_MICRO,x.TOTAL_WAITS,
x.RPC_COUNT,x.PLAN_TYPE,x.IS_INNER_SQL,x.IS_EXECUTOR_RPC,x.IS_HIT_PLAN,x.REQUEST_TIME,x.ELAPSED_TIME,
x.NET_TIME,x.NET_WAIT_TIME,x.QUEUE_TIME,x.DECODE_TIME,x.GET_PLAN_TIME,x.EXECUTE_TIME,x.APPLICATION_WAIT_TIME,
x.CONCURRENCY_WAIT_TIME,x.USER_IO_WAIT_TIME,x.SCHEDULE_TIME,x.ROW_CACHE_HIT,x.BLOOM_FILTER_CACHE_HIT,
x.BLOCK_CACHE_HIT,x.DISK_READS,x.RETRY_CNT,x.TABLE_SCAN,x.CONSISTENCY_LEVEL,x.MEMSTORE_READ_ROW_COUNT,
x.SSSTORE_READ_ROW_COUNT,x.DATA_BLOCK_READ_CNT,x.DATA_BLOCK_CACHE_HIT,x.INDEX_BLOCK_READ_CNT,
x.INDEX_BLOCK_CACHE_HIT,x.BLOCKSCAN_BLOCK_CNT,x.BLOCKSCAN_ROW_CNT,x.PUSHDOWN_STORAGE_FILTER_ROW_CNT,
x.REQUEST_MEMORY_USED,x.EXPECTED_WORKER_COUNT,x.USED_WORKER_COUNT,x.SCHED_INFO,x.PS_CLIENT_STMT_ID,
x.PS_INNER_STMT_ID,x.TX_ID,x.SNAPSHOT_VERSION,x.REQUEST_TYPE,x.IS_BATCHED_MULTI_STMT,x.OB_TRACE_INFO,
x.PLAN_HASH,x.PARAMS_VALUE,x.RULE_NAME,x.TX_INTERNAL_ROUTING,x.TX_STATE_VERSION,x.FLT_TRACE_ID,x.NETWORK_WAIT_TIME
from(
select /*+ PARALLEL(16) query_timeout(50000000000) */ rownum i, a.* from GV$OB_SQL_AUDIT a where
query_sql not like ''%tsp_datasource_check_config%''
and query_sql not like ''%tsp_instans_heartbeat%''
and query_sql not like ''%tsp_instans_param_version%''
and query_sql not like ''%tsp_service_in%''
and query_sql not like ''%tsp_mutex%''
and query_sql not like ''%tsp_param_sync_task%''
and query_sql not like ''%ob_sql_audit%''
and query_sql not like ''%ALTER%TABLE%''
and query_sql not like ''%extract_sqlaudit_proc%''
and TENANT_NAME <> ''sys''
) x where x.request_time >= :5 and x.request_time <= :6
';
EXECUTE IMMEDIATE V_SQL USING V_MAX_BATCH,V_MAX_BATCH,V_NAME,V_FLAG,V_START_SCN,V_END_SCN;
COMMIT;
DBMS_OUTPUT.PUT_LINE(P_START_TIME || ' ~ ' || p_END_TIME || '时间段可以查询:select * from xz_sql_audit where c_batch_id = ' || V_MAX_BATCH || ' ;');
/*
-- 调试代码
dbms_output.put_line(V_NAME);
dbms_output.put_line(V_MAX_BATCH);
dbms_output.put_line(V_START_TIME);
dbms_output.put_line(V_END_TIME);
dbms_output.put_line(V_SQL);
*/
EXCEPTION
WHEN V_FLAG_EXCEPTION THEN
DBMS_OUTPUT.PUT_LINE('p_FLAG参数传入的值错误,S:为拉取单个事务、M:为拉取多个事务(压测)');
WHEN V_END_TIME_SMALL_EXCEPTION THEN
DBMS_OUTPUT.PUT_LINE('结束时间: ' || V_END_TIME || ' 比' || ' 开始时间: ' || V_START_TIME ||' 小,请检查传入的时间。' );
END;
FUNCTION get_table_name(p_owner varchar2 ,p_string_sql clob)
RETURN VARCHAR2 IS
v_sql CLOB := p_string_sql;
v_table_names VARCHAR2(4000) := '';
v_pos INTEGER := 1;
v_table_name VARCHAR2(200);
v_match_count INTEGER := 0;
v_owner VARCHAR2(200):= upper(p_owner);
BEGIN
/*
声明
函数名称: get_table_name
函数作用: 从 SQL 语句中提取一个或多个表名。
创建日期: 2024-09-22
作者: (YZJ、须佐)
版本: v1.0
功能描述:
本函数用于解析给定的 SQL 语句,并从中提取出一个或多个表名。
主要适用于标准 SQL 语句,包括但不限于 SELECT 语句。
限制条件:
当前版本不支持以下类型的 SQL 语句:
- 使用逗号分隔的表连接,如:
```
SELECT * FROM a a1, b b1 WHERE a1.id = b1.id;
SELECT * FROM a, b WHERE a1.id = b1.id;
```
- 仅支持标准 SQL 语句格式。
创建前提:
无需额外的前提条件,直接调用即可。
调用方法:
示例:
```
select get_table_name(query_sql) from gv$ob_sql_audit;
```
注意事项:
- 请确保输入的 SQL 语句格式正确,否则可能无法正确提取表名。
- 本函数暂时不支持所有 SQL 标准,后续版本将逐步增强功能。
维护记录:
- 2024-09-22: 初始版本发布。
*/
/* 循环逐步匹配正则表达式,提取表名 */
LOOP
v_table_name := REGEXP_SUBSTR(v_sql, '(?i)(FROM|JOIN|INTO|UPDATE|DELETE)\s+("[^"]+"\.)?"?(\w+)"?', v_pos, 1, NULL, 3);
/* 如果找不到更多的表名,退出循环 */
EXIT WHEN v_table_name IS NULL;
/* 累积表名 */
v_table_names := v_table_names || UPPER(v_owner) || '.' || UPPER(v_table_name) || ',';
/* 计算下一个匹配的位置 */
v_pos := INSTR(v_sql, v_table_name, v_pos) + LENGTH(v_table_name);
/* 增加匹配次数 */
v_match_count := v_match_count + 1;
END LOOP;
/* v_match_count 如果大于0 ,表示匹配到表名,则去掉最后一个多余的逗号和空格
v_match_count 如果不大于0,则表示整条SQL没有匹配到表名,返回 '' 字符串。
*/
IF v_match_count > 0 THEN
v_table_names := RTRIM(v_table_names, ',');
RETURN v_table_names;
ELSE
RETURN '';
END IF;
/*
-- 调试代码
dbms_output.put_line(p_string_sql);
dbms_output.put_line(v_table_names);
dbms_output.put_line(v_pos);
dbms_output.put_line(v_match_count);
*/
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('err_message: ' || SQLERRM);
END get_table_name;
FUNCTION get_table_info(p_tablename_list VARCHAR2)
RETURN VARCHAR2 IS
v_tablename_list VARCHAR2(4000) := UPPER(p_tablename_list); -- 输入字符串
v_separator CHAR := ','; -- 分割符
v_part VARCHAR2(100); -- 临时变量存储分割后的部分
v_index NUMBER := 1; -- 当前索引
v_length NUMBER := LENGTH(v_tablename_list); -- 字符串长度
v_tablename VARCHAR2(200);
v_schemaname VARCHAR2(200);
v_partition_rule VARCHAR2(200); -- 表的分区规则
v_object_type VARCHAR2(200); -- 对象类型
v_outinfo CLOB; -- 函数最终return的信息
v_exception_info VARCHAR2(2000); -- 存储异常信息
v_local_index_cnt INT;
v_global_index_cnt INT;
v_pk_cnt INT;
v_row_cnt INT; -- 表或视图的数据行数
BEGIN
/*
声明
函数名称: get_table_info
函数作用: 提取多个表的详细信息(包括分区规则、本地索引数、全局索引数、主键数量以及数据行数)。
创建日期: 2024-09-23
作者: (YZJ、须佐)
版本: v1.2
功能描述:
本函数用于解析传入的表名列表(以逗号分隔),并获取每个表的详细信息,包括:
- 分区规则(如果有)
- 本地索引数量
- 全局索引数量
- 主键数量
- 表或视图数据行数
调用方法:
示例:
```
SELECT get_table_info('schema1.table1, schema2.table2')
FROM dual;
```
返回值:
返回包含表信息的 VARCHAR2 字符串,多个表的信息以换行符分隔。
注意事项:
- 函数基于 DBA 视图 `XZ_OBJECTS` 和 `XZ_INDEXES`,需要确保调用用户具有相应的权限。
- 请确保输入的表名列表格式正确,否则可能无法获取表的相关信息。
维护记录:
- 2024-09-23: 初始版本发布。
- 2024-09-23: 增加统计表或视图数据行数的功能。
*/
-- 表头
v_outinfo := RPAD('表名', 35) || ' | ' || RPAD('分区规则', 45) || ' | ' || RPAD('本地索引数量', 15) || ' | ' || RPAD('全局索引数量', 15) || ' | ' || RPAD('主键PK数量', 10) || ' | ' || RPAD('数据行数', 10) || CHR(10) ;
v_outinfo := v_outinfo || '------------------------------------------------------------------------------------------------------------------------------------------------' || CHR(10);
-- 使用循环遍历每个子字符串
WHILE v_index <= v_length LOOP
-- 每次循环开始,清空异常信息
v_exception_info := NULL;
-- 获取下一个子字符串的位置
v_part := SUBSTR(v_tablename_list, v_index, INSTR(v_tablename_list, v_separator, v_index) - v_index);
-- 如果子字符串为空,则说明已经到达最后一个子字符串
IF v_part IS NULL OR v_part = '' THEN
v_part := SUBSTR(v_tablename_list, v_index);
END IF;
-- 提取用户、表名 ,例子: 用户名.表名
v_schemaname := UPPER(REGEXP_SUBSTR(v_part, '^[^.]+'));
v_tablename := UPPER(REGEXP_SUBSTR(v_part, '[^.]+$'));
-- 首先从 xz_objects 判断下有没有这个对象,不然怕后面会报错、异常
BEGIN
SELECT UPPER(MAX(CASE
WHEN object_type = 'TABLE SUBPARTITION' THEN 'TABLE PARTITION'
ELSE object_type END)
) -- 1、TABLE PARTITION 2、TABLE 3、VIEW
INTO v_object_type FROM xz_objects WHERE owner = v_schemaname AND object_name = v_tablename;
EXCEPTION
WHEN NO_DATA_FOUND THEN
v_exception_info := '在 xz_objects 基表内没有找到该对象信息,请检查是否输入错误!';
WHEN OTHERS THEN
v_exception_info := '未知异常,无法获取对象信息:( ' || SUBSTR(SQLERRM, 1, 60) || ' ... )'; -- 截断错误信息
END;
-- 如果获取到对象信息
IF v_object_type IS NOT NULL THEN
IF v_object_type = 'TABLE PARTITION' OR v_object_type = 'TABLE' THEN
-- 分区表或非分区表处理
IF v_object_type = 'TABLE PARTITION' THEN
-- 分区表处理
SELECT /*+ PARALLEL(8) */
UPPER(TO_CHAR(REGEXP_SUBSTR(DBMS_METADATA.GET_DDL('TABLE', v_tablename, v_schemaname), 'partition\s+by\s+(\w+)\(([^)]+)\)')))
INTO v_partition_rule
FROM dual;
ELSE
-- 非分区表处理
v_partition_rule := '非分区表';
END IF;
-- 获取表的数据行数
BEGIN
EXECUTE IMMEDIATE 'SELECT /*+ PARALLEL(8) */ COUNT(1) FROM ' || v_schemaname || '.' || v_tablename INTO v_row_cnt;
EXCEPTION
WHEN OTHERS THEN
v_row_cnt := -1; -- 如果查询表行数时出现异常,设置为 -1 表示未知
END;
-- 获取表的索引信息
BEGIN
-- 如果表没有索引
SELECT a.local_index_cnt,
a.global_index_cnt,
a.pk_cnt INTO v_local_index_cnt, v_global_index_cnt, v_pk_cnt
FROM xz_indexes a
WHERE a.table_owner = v_schemaname AND a.table_name = v_tablename;
EXCEPTION
WHEN NO_DATA_FOUND THEN
v_local_index_cnt := 0;
v_global_index_cnt := 0;
v_pk_cnt := 0;
END;
-- 拼接输出信息
v_outinfo := v_outinfo || RPAD(v_schemaname || '.' || v_tablename, 35) || ' | ' || RPAD(v_partition_rule, 45)
|| ' | ' || RPAD(v_local_index_cnt, 15)
|| ' | ' || RPAD(v_global_index_cnt, 15)
|| ' | ' || RPAD(v_pk_cnt, 10)
|| ' | ' || RPAD(v_row_cnt, 10) || CHR(10);
ELSIF v_object_type = 'VIEW' THEN
-- 如果是视图,统计行数,本地索引、全局索引和主键设为 0
v_local_index_cnt := 0;
v_global_index_cnt := 0;
v_pk_cnt := 0;
-- 获取视图的行数
BEGIN
EXECUTE IMMEDIATE 'SELECT /*+ PARALLEL(8) */ COUNT(1) FROM ' || v_schemaname || '.' || v_tablename INTO v_row_cnt;
EXCEPTION
WHEN OTHERS THEN
v_row_cnt := -1; -- 如果查询视图行数时出现异常,设置为 -1 表示未知
END;
-- 拼接视图的输出信息
v_outinfo := v_outinfo || RPAD(v_schemaname || '.' || v_tablename, 35) || ' | ' || RPAD('视图', 45)
|| ' | ' || RPAD(v_local_index_cnt, 15)
|| ' | ' || RPAD(v_global_index_cnt, 15)
|| ' | ' || RPAD(v_pk_cnt, 10)
|| ' | ' || RPAD(v_row_cnt, 10) || CHR(10);
ELSE
-- 其他对象,无法获取详细信息
v_local_index_cnt := 0;
v_global_index_cnt := 0;
v_pk_cnt := 0;
-- 拼接无法获取详细信息的输出
v_outinfo := v_outinfo || RPAD(v_schemaname || '.' || v_tablename, 35) || ' | ' || RPAD('未知异常,无法获取对象信息!', 100)
|| ' | ' || RPAD(v_local_index_cnt, 15)
|| ' | ' || RPAD(v_global_index_cnt, 15)
|| ' | ' || RPAD(v_pk_cnt, 10)
|| ' | ' || RPAD('0', 10) || CHR(10); -- 数据行数为 0
END IF;
ELSE
-- 如果没获取到对象信息,默认设置索引和主键为 0
v_local_index_cnt := 0;
v_global_index_cnt := 0;
v_pk_cnt := 0;
-- 拼接异常输出信息
v_outinfo := v_outinfo || RPAD(v_schemaname || '.' || v_tablename, 35) || ' | ' || RPAD(v_exception_info, 100)
|| ' | ' || RPAD(v_local_index_cnt, 15)
|| ' | ' || RPAD(v_global_index_cnt, 15)
|| ' | ' || RPAD(v_pk_cnt, 10)
|| ' | ' || RPAD('0', 10) || CHR(10); -- 数据行数为 0
END IF;
-- 更新索引位置
v_index := v_index + LENGTH(v_part) + 1;
-- 重置变量
v_partition_rule := '';
v_object_type := '';
END LOOP;
-- 增加最后一行的分隔线
v_outinfo := v_outinfo || '------------------------------------------------------------------------------------------------------------------------------------------------' || CHR(10);
RETURN v_outinfo;
END get_table_info;
PROCEDURE real_time_cdc_proc(
p_END_TIME VARCHAR2 -- 结束时间
)
IS
p_stop_date varchar(200):=p_END_TIME; -- 传入的停止时间,这个时间之前都会增量cdc抽取gv$ob_sql_audit数据
v_stop_date TIMESTAMP ; -- 字符串参数转换日期时间戳的变量
v_num int:=1; -- 循环CNT控制变量
v_current_date TIMESTAMP; -- 当前日期
v_start_time TIMESTAMP ; -- cdc 拉取的开始时间、核心变量
v_end_time TIMESTAMP ; -- cdc 拉取的结束时间、核心变量
v_start_scn NUMBER ; -- cdc 拉取的开始scn、核心变量
v_end_scn NUMBER ; -- cdc 拉取的结束scn、核心变量
v_sql_excute_start_time TIMESTAMP ;
v_sql_excute_end_time TIMESTAMP ;
v_interval INTERVAL day to second; -- 每次 insert into xz_sql_audit_cdc 的间隔时间类型
v_interval_char varchar2(2000); -- 每次 insert into xz_sql_audit_cdc 的间隔类型转换成字符串
v_interval_num NUMBER;
v_sql varchar2(4000);
BEGIN
/*
声明
过程名称: real_time_cdc_proc
函数作用: 该存储过程用于实时收集 `gv$ob_sql_audit` 视图中的数据,并将其固化到 `xz_sql_audit_cdc` 表中。
创建日期: 2024-09-10
作者: (YZJ、须佐)
版本: v2.0
需求说明:
本存储过程是为了满足 XX 银行某核心系统ISV V8 微服务(TCC 架构)核心系统在跑批任务期间实时收集请求的跑批 SQL。
由于 `gv$ob_sql_audit` 视图数据超过内存阈值会被定期刷新,且应用跑批时间较长,因此只能实施实时采集 `gv$ob_sql_audit` 表的数据,并将其固化到 `xz_sql_audit_cdc` 表中。
该存储过程主要用于收集 `gv$ob_sql_audit` 视图中的所有数据,以便后续分析缓慢 SQL 并提供优化建议。
分析手段需要手动编写分析 SQL。
创建前提:
在创建此存储过程之前,需要提前创建以下对象:
1. 序列:SEQ_XZ_SQL_AUDIT_CDC_CID
2. 日志记录表:XZ_CDC_LOG
- 用于记录 `xz_sql_audit_cdc` 表目前采集了多少次数据,每次采集的时间。
3. 数据分析表:XZ_SQL_AUDIT_CDC
- 用于固化 `gv$ob_sql_audit` 视图中的所有数据,后续主要分析该表内容。
调用方法:
建议使用 obclient 命令行工具编写 Shell 脚本后台执行:
```
BEGIN
real_time_cdc_proc(p_END_TIME => '2024-12-12 01:00:00');
-- 2024-12-12 01:00:00 为存储过程结束运行的时间
END;
/
```
*/
BEGIN
/* 如果传入的 p_stop_date 无法转换成日期参数,报错抛出异常,下面的代码不用执行 */
v_stop_date := to_timestamp(p_stop_date,'YYYY-MM-DD HH24:MI:SS');
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('p_stop_date 请传入能转换日期类型的参数!' );
RETURN ;
END;
v_current_date := SYSTIMESTAMP;
WHILE v_current_date <= v_stop_date LOOP
IF v_num = 1 THEN
/* 初始化数据,xz_sql_audit_cdc 灌入10行数据 */
v_sql := '
insert into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where rownum <= 10';
/* 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num;
v_sql_excute_end_time := SYSTIMESTAMP;
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
ELSIF v_num = 2 THEN
v_end_time := SYSTIMESTAMP ; -- 结束时间戳,获取当前时间。
v_start_time := v_end_time - interval '70' second; -- 开始时间戳,结束时间往前面减70秒作为每次数据开始时间。
/*
where request_time > v_start_time:(v_end_time - interval '70' second) and request_time < v_end_time:SYSTIMESTAMP
*/
v_start_scn := timestamp_to_scn(v_start_time) / 1000 ; -- 将开始时间转成开始scn
v_end_scn := timestamp_to_scn(v_end_time) / 1000 ; -- 将结束时间转成结束scn
v_sql := '
insert /*+ APPEND PARALLEL(8) */ into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select /*+ PARALLEL(8) query_timeout(50000000000) */
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where request_time > :2 and request_time < :3' ;
/* 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num,v_start_scn,v_end_scn;
v_sql_excute_end_time := SYSTIMESTAMP;
-- 记录SQL执行的时间
v_interval := (v_sql_excute_end_time - v_sql_excute_start_time);
v_interval_char := to_char(extract(day from v_interval) * 86400 +
extract(hour from v_interval) * 3600 +
extract(minute from v_interval) * 60 +
extract(second from v_interval));
v_interval_num := to_number(v_interval_char);
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
ELSE
/* v_num = 1 第1次初始化装载数据,装载多少没什么关系
v_num = 2 第2次拉取间隔数据,确定好 v_start_time、v_end_time 的时间点。
v_num = 3 第3次以后,继承第2次的时间
start_time = null end_time = null
start_time = t2 - 5 end_time = t2
start_time = t2 end_time = t3
start_time = t3 end_time = t4
*/
v_start_time := v_end_time;
v_end_time := v_end_time + (interval '1' second * v_interval_num);
v_start_scn := timestamp_to_scn(v_start_time) / 1000 ; -- 将开始时间转成开始scn
v_end_scn := timestamp_to_scn(v_end_time) / 1000 ; -- 将结束时间转成结束scn
v_sql := '
insert /*+ APPEND PARALLEL(8) */ into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select /*+ PARALLEL(8) query_timeout(50000000000) */
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where request_time > :2 and request_time < :3' ;
/* 批插数据 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num,v_start_scn,v_end_scn;
v_sql_excute_end_time := SYSTIMESTAMP;
-- 记录SQL执行的时间
v_interval := (v_sql_excute_end_time - v_sql_excute_start_time);
v_interval_char := to_char(extract(day from v_interval) * 86400 +
extract(hour from v_interval) * 3600 +
extract(minute from v_interval) * 60 +
extract(second from v_interval));
v_interval_num := to_number(v_interval_char);
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
END IF ;
v_num := v_num + 1;
v_current_date := SYSTIMESTAMP ;
END LOOP ;
COMMIT ;
-- 调试代码
/* if v_stop_date = to_date('2024-01-01','YYYY-MM-DD') THEN
DBMS_OUTPUT.PUT_LINE('true') ;
else
DBMS_OUTPUT.PUT_LINE('false') ;
END IF;
DBMS_OUTPUT.PUT_LINE('调式代码-p_stop_date:'|| to_char(v_stop_date,'YYYY-MM-DD HH24:MI:SS') );
*/
END;
END ob_tools;
一、extract_sqlaudit_proc 存储过程介绍、使用
1、介绍
extract_sqlaudit_proc 是我编写的第一个存储过程,源于某银行项目期间对某核心系统ISV V8核心应用在压测期间缓慢SQL分析的需求而编写。
其实通过OCP SQL诊断功能捞慢SQL语句也不是不行,当时不选择使用OCP来分析有以下几点原因:
- OCP SQL诊断数据可能存在一定的偏差,例如在某银行遇到情况:OCP会把SQL的RPC次数也算到SQL的执行次数内。就因为这个问题,当时和某核心系统ISV 开发产生一些理解上的偏差。
- OCP SQL诊断数据只能显示聚合后的一些平均信息,如果想分析应用不同场景的单笔交易内包含的什么SQL语句,交易接口SQL的执行顺序,单交易接口缓慢的SQL语句是哪些?这些需求通过OCP是采集不到相应的数据。
- 数据库、应用系统做了调整优化,对于要拿历史数据和现在优化后的数据进行对比分析比较困难。
基于上面痛点,所以后续到了客户现场,花半天时间写好、调试好这个过程就可以拿来使用了。某核心系统ISV 核心系统后续所有交易场景,单笔交易的SQL语句数据,不同交易并发压测的数据,都是通过这个过程来收集持久化。
刚开始这个过程比较Low,性能很差,收集5分钟的压测数据落盘(大概2000w ~ 3000w行数据左右),开100个并发都需要拉10多分钟,不过后续慢慢优化了些逻辑,现在拉大量的数据开16个并行也只需要几分钟而已。
PROCEDURE extract_sqlaudit_proc(P_NAME VARCHAR2, p_FLAG char, P_START_TIME VARCHAR2, p_END_TIME VARCHAR2)
IS
V_NAME VARCHAR2(100):=upper(P_NAME); -- 场景名称
V_FLAG CHAR(2) :=upper(p_FLAG); -- s 为拉取单个事务,m 为拉取多个事务(压测)
V_MAX_BATCH INT;
V_START_TIME VARCHAR2(100):=P_START_TIME; --开始时间
V_END_TIME VARCHAR2(100):=p_END_TIME; --结束时间
V_START_SCN NUMBER;
V_END_SCN NUMBER;
/*
V_NAME:场景名称
V_FLAG:S为拉取单个事务,M为拉取多个事务(压测)
V_MAX_BATCH:记录批次数
*/
V_SQL VARCHAR2(4000);
V_FLAG_EXCEPTION EXCEPTION;
V_END_TIME_SMALL_EXCEPTION EXCEPTION;
BEGIN
/*
声明
过程名称: extract_sqlaudit_proc
功能描述: 该存储过程用于从 `gv$ob_sql_audit` 视图中提取指定时间段内的数据,并将其存储到 `xz_sql_audit` 表中,以便后续分析。
创建日期: 2024-08-15
作者: (YZJ、须佐)
版本: v1.2
需求背景:
本存储过程是为满足 XX 银行某核心系统ISV V8 微服务(TCC 架构)核心系统在不同场景下的联机交易压测需求而编写。
通过收集压测期间的数据,可以分析出缓慢 SQL,并提供优化建议。
分析手段需要手动编写分析 SQL。
创建前提:
必须预先创建 `xz_sql_audit` 分析表,以确保 `extract_sqlaudit_proc` 过程能够成功编译。
调用方法:
建议使用 obclient 命令行工具,并开启服务输出选项:
```
set serveroutput on;
```
调用示例:
```
BEGIN
extract_sqlaudit_proc(
P_NAME => 'IB1261一借一贷 单笔交易',
-- 描述收集数据的具体场景和用途。
-- 若为并发压测数据,可写为:'IB1261 200并发压测 5分钟'
p_FLAG => 'S',
-- 指定压测类型:单交易为 'S',并发为 'M'
P_START_TIME => '2024-09-03 18:06:00',
-- 指定压测的开始时间
p_END_TIME => '2024-09-03 18:06:20'
-- 指定压测的结束时间
);
END;
/
```
*/
IF TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6') > TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6') THEN
RAISE V_END_TIME_SMALL_EXCEPTION;
END IF;
IF V_FLAG != 'S' AND V_FLAG != 'M' THEN
RAISE V_FLAG_EXCEPTION;
END IF;
-- 找到最大批次数加1
SELECT NVL(MAX(C_BATCH_ID),0) +1 INTO V_MAX_BATCH FROM XZ_SQL_AUDIT;
-- 将传进来的值转换成字符串时间戳格式。
V_START_TIME := TO_CHAR(TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6'),'YYYY-MM-DD HH24:MI:SS:FF6');
V_END_TIME := TO_CHAR(TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6'),'YYYY-MM-DD HH24:MI:SS:FF6');
V_START_SCN := timestamp_to_scn(TO_TIMESTAMP(V_START_TIME,'YYYY-MM-DD HH24:MI:SS:FF6')) / 1000 ; -- 将开始时间转成开始scn
V_END_SCN := timestamp_to_scn(TO_TIMESTAMP(V_END_TIME,'YYYY-MM-DD HH24:MI:SS:FF6')) / 1000 ; -- 将结束时间转成结束scn
V_SQL:='
insert /*+ ENABLE_PARALLEL_DML PARALLEL(16)*/ into XZ_SQL_AUDIT
select (:1 * 10000000000)+i , scn_to_timestamp(x.request_time * 1000),:2,:3,:4,
x.SVR_IP,x.SVR_PORT,x.REQUEST_ID,x.SQL_EXEC_ID,x.TRACE_ID,x.SID,x.CLIENT_IP,x.CLIENT_PORT,
x.TENANT_ID,x.EFFECTIVE_TENANT_ID,x.TENANT_NAME,x.USER_ID,x.USER_NAME,x.USER_GROUP,x.USER_CLIENT_IP,
x.DB_ID,x.DB_NAME,x.SQL_ID,x.QUERY_SQL,x.PLAN_ID,x.AFFECTED_ROWS,x.RETURN_ROWS,x.PARTITION_CNT,
x.RET_CODE,x.QC_ID,x.DFO_ID,x.SQC_ID,x.WORKER_ID,x.EVENT,x.P1TEXT,x.P1,x.P2TEXT,x.P2,x.P3TEXT,x.P3,
x.WAIT_CLASS_ID,x.WAIT_CLASS#,x.WAIT_CLASS,x.STATE,x.WAIT_TIME_MICRO,x.TOTAL_WAIT_TIME_MICRO,x.TOTAL_WAITS,
x.RPC_COUNT,x.PLAN_TYPE,x.IS_INNER_SQL,x.IS_EXECUTOR_RPC,x.IS_HIT_PLAN,x.REQUEST_TIME,x.ELAPSED_TIME,
x.NET_TIME,x.NET_WAIT_TIME,x.QUEUE_TIME,x.DECODE_TIME,x.GET_PLAN_TIME,x.EXECUTE_TIME,x.APPLICATION_WAIT_TIME,
x.CONCURRENCY_WAIT_TIME,x.USER_IO_WAIT_TIME,x.SCHEDULE_TIME,x.ROW_CACHE_HIT,x.BLOOM_FILTER_CACHE_HIT,
x.BLOCK_CACHE_HIT,x.DISK_READS,x.RETRY_CNT,x.TABLE_SCAN,x.CONSISTENCY_LEVEL,x.MEMSTORE_READ_ROW_COUNT,
x.SSSTORE_READ_ROW_COUNT,x.DATA_BLOCK_READ_CNT,x.DATA_BLOCK_CACHE_HIT,x.INDEX_BLOCK_READ_CNT,
x.INDEX_BLOCK_CACHE_HIT,x.BLOCKSCAN_BLOCK_CNT,x.BLOCKSCAN_ROW_CNT,x.PUSHDOWN_STORAGE_FILTER_ROW_CNT,
x.REQUEST_MEMORY_USED,x.EXPECTED_WORKER_COUNT,x.USED_WORKER_COUNT,x.SCHED_INFO,x.PS_CLIENT_STMT_ID,
x.PS_INNER_STMT_ID,x.TX_ID,x.SNAPSHOT_VERSION,x.REQUEST_TYPE,x.IS_BATCHED_MULTI_STMT,x.OB_TRACE_INFO,
x.PLAN_HASH,x.PARAMS_VALUE,x.RULE_NAME,x.TX_INTERNAL_ROUTING,x.TX_STATE_VERSION,x.FLT_TRACE_ID,x.NETWORK_WAIT_TIME
from(
select /*+ PARALLEL(16) query_timeout(50000000000) */ rownum i, a.* from GV$OB_SQL_AUDIT a where
query_sql not like ''%tsp_datasource_check_config%''
and query_sql not like ''%tsp_instans_heartbeat%''
and query_sql not like ''%tsp_instans_param_version%''
and query_sql not like ''%tsp_service_in%''
and query_sql not like ''%tsp_mutex%''
and query_sql not like ''%tsp_param_sync_task%''
and query_sql not like ''%ob_sql_audit%''
and query_sql not like ''%ALTER%TABLE%''
and query_sql not like ''%extract_sqlaudit_proc%''
and TENANT_NAME <> ''sys''
) x where x.request_time >= :5 and x.request_time <= :6
';
/*
query_sql not like 都是排除掉不需要的数据的表,例如tsp_开头都是某核心系统ISV 后台任务的表,不参与交易场景,所以提前排除掉。
*/
EXECUTE IMMEDIATE V_SQL USING V_MAX_BATCH,V_MAX_BATCH,V_NAME,V_FLAG,V_START_SCN,V_END_SCN;
COMMIT;
DBMS_OUTPUT.PUT_LINE(P_START_TIME || ' ~ ' || p_END_TIME || '时间段可以查询:select * from xz_sql_audit where c_batch_id = ' || V_MAX_BATCH || ' ;');
/*
-- 调试代码
dbms_output.put_line(V_NAME);
dbms_output.put_line(V_MAX_BATCH);
dbms_output.put_line(V_START_TIME);
dbms_output.put_line(V_END_TIME);
dbms_output.put_line(V_SQL);
*/
EXCEPTION
WHEN V_FLAG_EXCEPTION THEN
DBMS_OUTPUT.PUT_LINE('p_FLAG参数传入的值错误,S:为拉取单个事务、M:为拉取多个事务(压测)');
WHEN V_END_TIME_SMALL_EXCEPTION THEN
DBMS_OUTPUT.PUT_LINE('结束时间: ' || V_END_TIME || ' 比' || ' 开始时间: ' || V_START_TIME ||' 小,请检查传入的时间。' );
END extract_sqlaudit_proc;
2、调用存储过程
应用人员每次执行完并发压测任务/单笔交易任务,会提供任务开始时间与结束时间,此时可以使用存储过程拉取数据。
建议使用黑屏的方式执行存储过程,执行前黑屏打开输出选项:set serverout on;
set serveroutput on;
BEGIN
ob_tools.extract_sqlaudit_proc(
P_NAME => 'IB1261一借一贷 单笔交易',
-- 描述收集数据的具体场景和用途。
-- 若为并发压测数据,可写为:'IB1261 200并发压测 5分钟'
p_FLAG => 'S',
-- 指定压测类型:单交易为 'S',并发为 'M'
P_START_TIME => '2024-09-28 11:58:00',
-- 指定压测的开始时间
p_END_TIME => '2024-09-28 11:59:20'
-- 指定压测的结束时间
);
END;
/
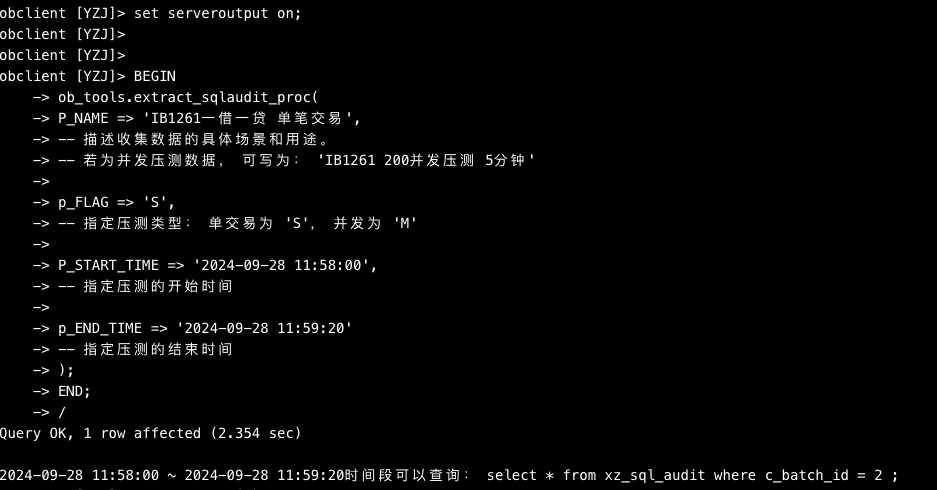
指定 c_batch_id = 2 的就可以把 2024-09-28 11:58:00 ~ 2024-09-28 11:59:20 之间一分钟的数据查出来了。
3、参数说明
P_NAME 参数 : 描述收集数据的具体场景和用途,这个在收集数据之前描述得越清晰越好,单交易、并发压测、或者其他用途最好描述清楚,这个名称是会写入 xz_sql_audit 表的 c_name 字段,后续可以直接使用 c_batch_id 进行查找、统计不同场景、用途的数据出来方便比较。
P_FLAG 参数 :这个参数只有两种状态,S:就是单交易数据,M:就是并发压测数据,其实也是个对数据打标签的字段,相当于辅助 P_NAME 的功能。
P_START_TIME 参数 :执行你要获取数据的开始时间,我一般输入的是压测的开始时间,输入时间的格式:yyyy-mm-dd hh24:mi:ss.ff6。
P_END_TIME 参数 :执行你要获取数据的结束时间,我一般输入的是压测的结束时间,输入时间的格式:yyyy-mm-dd hh24:mi:ss.ff6。
4、注意
如果所需的数据时间范围超出了 gv$ob_sql_audit 的保留窗口,则无法获取相应数据。因此,建议在应用压测结束后,尽快使用extract_sqlaudit_proc存储过程拉取数据并固化到 xz_sql_audit 表中,以避免 gv$ob_sql_audit 中的压测数据被淘汰。
在某银行项目期间,通常针对单个交易场景的压测是 200 并发,持续 5 分钟左右。为了避免 gv$ob_sql_audit 超出数据承载容量,建议控制压测时间,避免时间过长导致数据溢出或丢失。
5、分析缓慢SQL数据
5.1、分析并发压测期间缓慢的SQL
SELECT /*+ PARALLEL(8) */
xzzz.c_name,
xzzz.c_start_time,
xzzz.c_end_time,
xzzz.user_name ,
xzzz.db_name ,
xzzz.SQL_ID ,
xzzz.sql语句,
nvl(ob_tools.get_table_info(ob_tools.get_table_name(xzzz.db_name,xzzz.sql语句)),'none') 表信息,
xzzz.sql执行次数,
xzzz.计划次数,
xzzz.sql_cpu_时间占比,
xzzz.平均执行时间_毫秒,
xzzz.平均总执行时间_毫秒,
xzzz.最大总执行时间_毫秒,
xzzz.平均重试次数,
xzzz.平均RPC次数,
xzzz.平均RPC接收到时间_毫秒,
xzzz.平均请求接收时间_毫秒,
xzzz.平均队列时间_毫秒,
xzzz.平均出队列解析时间_毫秒,
xzzz.平均获取计划时间_毫秒
from (
SELECT
xzz.c_name as c_name,
xzz.c_start_time as c_start_time,
xzz.c_end_time as c_end_time,
upper(xzz.user_name) as user_name ,
upper(xzz.db_name) as db_name ,
xzz.sql_id as SQL_ID ,
count(1) as sql执行次数,
max(xzz.c_query_sql) as sql语句,
max(xzz.c_plan_cnt) as 计划次数,
round((sum(xzz.execute_time) / xzz.cpu_sum) * 100, 2) as sql_cpu_时间占比,
round(avg(xzz.execute_time) ,2)/1000 as 平均执行时间_毫秒,
round(avg(xzz.elapsed_time) ,2)/1000 as 平均总执行时间_毫秒,
round(max(xzz.ELAPSED_TIME) ,2)/1000 as 最大总执行时间_毫秒,
round(avg(xzz.retry_cnt) ,2) as 平均重试次数,
round(avg(xzz.rpc_count) ,2) as 平均RPC次数,
round(avg(xzz.net_time) ,2)/1000 as 平均RPC接收到时间_毫秒,
round(avg(xzz.net_wait_time) ,2)/1000 as 平均请求接收时间_毫秒,
round(avg(xzz.queue_time) ,2)/1000 as 平均队列时间_毫秒,
round(avg(xzz.decode_time) ,2)/1000 as 平均出队列解析时间_毫秒,
round(avg(xzz.get_plan_time) ,2)/1000 as 平均获取计划时间_毫秒
from (
SELECT xz.*,
LISTAGG(distinct UPPER(xz.c_plan_type) || ':' || xz.c_plan_type_cnt , ',')
WITHIN GROUP(ORDER BY xz.c_plan_type)
over(partition by xz.c_batch_id,xz.user_name,xz.db_name,xz.sql_id) c_plan_cnt
from (
SELECT
min(to_char(x.c_rq_time,'YYYY-MM-DD HH24:MI:SS.FF6')) over(partition by x.c_batch_id) c_start_time,
max(to_char(x.c_rq_time,'YYYY-MM-DD HH24:MI:SS.FF6')) over(partition by x.c_batch_id) c_end_time,
count(x.c_plan_type) over(partition by x.c_batch_id,x.user_name,x.db_name,x.sql_id,x.c_plan_type) c_plan_type_cnt ,
x.*
from (
SELECT
b.*,
to_char(substr(b.query_sql, 1, 4000)) c_query_sql,
(case
when b.PLAN_TYPE = 0 then 'inner'
when b.PLAN_TYPE = 1 then 'local'
when b.PLAN_TYPE = 2 then 'remote'
when b.PLAN_TYPE = 3 then 'distributed'
else null end) c_plan_type,
sum(b.execute_time) over(partition by b.c_name) cpu_sum
FROM xz_sql_audit b
where b.user_name not in ('YZJ')
and b.db_name not in ('YZJ')
and b.c_batch_id = 2 -- 选择需要分析的数据集
) x
)xz
) xzz
GROUP BY
xzz.c_name,
xzz.c_start_time,
xzz.c_end_time,
xzz.db_name,
xzz.user_name,
xzz.sql_id,
xzz.cpu_sum
) xzzz
where xzzz.sql_cpu_时间占比 > 0.5
ORDER BY 1 ASC, 11 DESC;


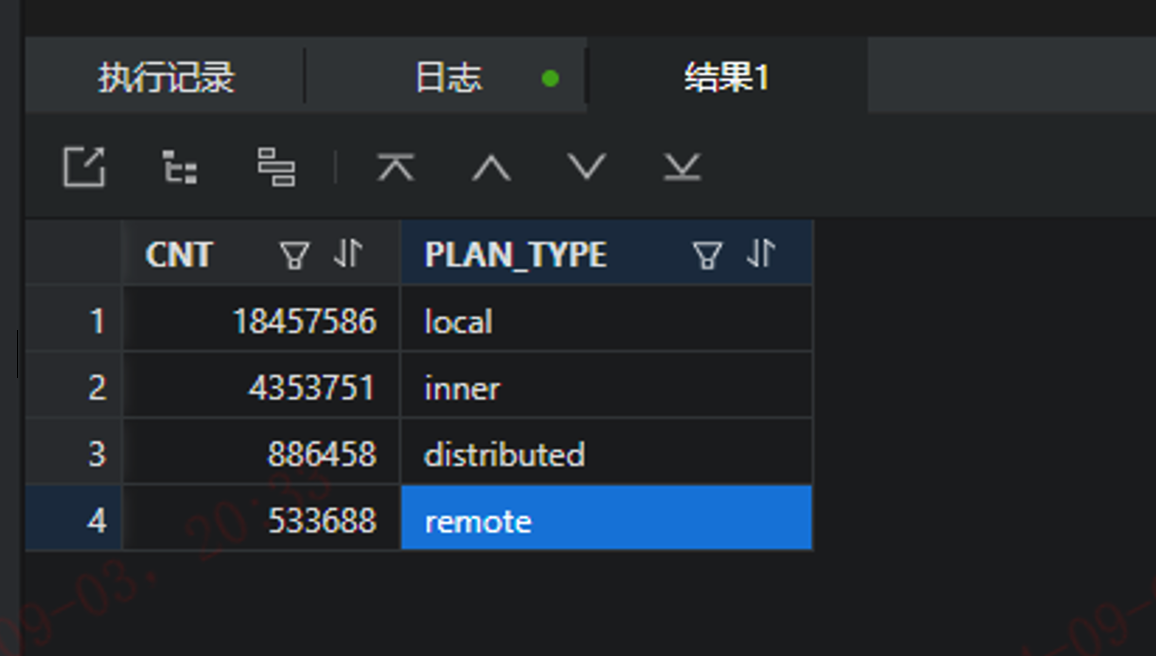
5.2、分析不同场景单笔/并发交易SQL计划类型数量
with x as (select sql_id,plan_type from xz_sql_audit where c_batch_id = 16 ) /*只需要改这个 c_batch_id */
select count(sql_id) cnt,
(case
when a.PLAN_TYPE = 0 then 'inner'
when a.PLAN_TYPE = 1 then 'local'
when a.PLAN_TYPE = 2 then 'remote'
when a.PLAN_TYPE = 3 then 'distributed'
else null
end ) PLAN_TYPE
from x a group by plan_type
order by 1 desc;
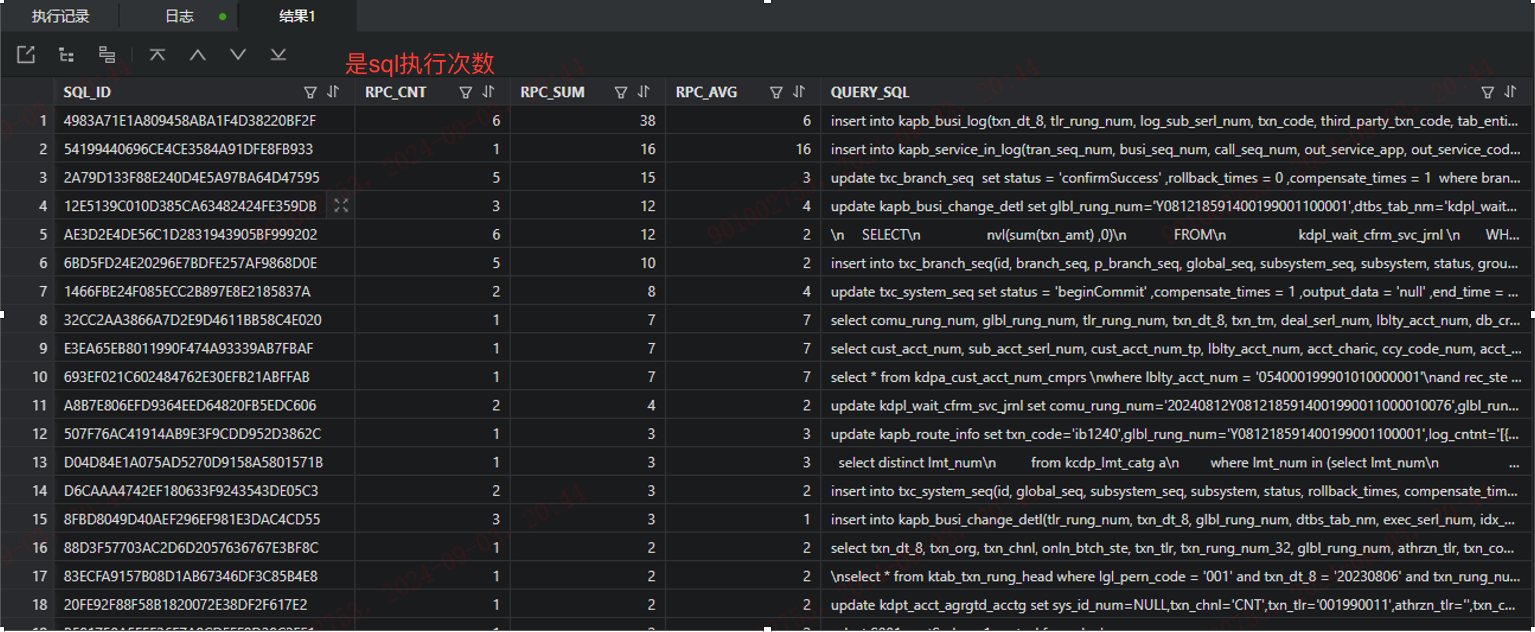
5.3、分析RPC 大于0的单笔/并发SQL
with x AS
(SELECT /*+ PARALLEL(32) */ * FROM xz_sql_audit WHERE c_batch_id = 2)
SELECT a.sql_id,
a.sql_excute_cnt,
a.rpc_sum,
a.rpc_avg,
(SELECT to_char(substr(b.query_sql,1,3000)) FROM x b WHERE a.sql_id = b.sql_id AND rownum <=1) query_sql
FROM
(SELECT a.sql_id,
count(1) sql_excute_cnt,
sum(a.RPC_COUNT) rpc_sum,
round(avg(a.RPC_COUNT)) rpc_avg
FROM x a
WHERE not(query_sql LIKE '%COMMIT%'
OR query_sql LIKE '%ROLLBACK%')
GROUP BY a.sql_id
HAVING sum(a.RPC_COUNT) > 0
) a
ORDER BY 3 desc;
5.4、分析单笔交易SQL执行顺序(只能分析单笔交易)
with x as (select /*+ PARALLEL(32) */ * from xz_sql_audit where c_batch_id = 2)
SELECT
a.start_time 业务交易开始时间,
a.end_time 业务交易结束时间,
a.c_name 交易场景,
a.c_rq_time_char 服务层SQL请求时间,
a.svr_ip 服务端IP,
a.user_name 用户名,
a.sid 会话号,
a.tx_id 事务ID,
a.tx_id_rn 事务内顺序,
a.query_sql 服务层请求SQL,
a.net_time RPC接收到时间,
a.net_wait_time 请求接收时间,
a.QUEUE_TIME 队列时间,
a.DECODE_TIME 出队列解析时间,
a.get_plan_time 获取计划时间,
a.execute_time 执行时间,
a.RETRY_CNT 重试次数,
a.RPC_COUNT RPC次数,
a.ELAPSED_TIME SERVER总执行时间,
a.TABLE_SCAN 是否全表扫描,
a.PLAN_TYPE 计划类型,
a.IS_HIT_PLAN 是否命中缓存
FROM (
SELECT
TO_CHAR(b.start_time,'YYYY-MM-DD HH24:MI:SS.FF6') start_time,
TO_CHAR(b.end_time,'YYYY-MM-DD HH24:MI:SS.FF6') end_time,
a.c_name,
TO_CHAR(a.c_rq_time,'YYYY-MM-DD HH24:MI:SS.FF6') c_rq_time_char,
a.svr_ip svr_ip,
a.user_name user_name,
a.tx_id tx_id,
a.sid sid,
row_number() over(partition by a.tx_id order by c_rq_time asc) tx_id_rn ,
to_char(substr(a.query_sql,1,3000)) query_sql,
a.net_time,
a.net_wait_time,
a.QUEUE_TIME,
a.DECODE_TIME,
a.get_plan_time,
a.execute_time,
a.RETRY_CNT,
a.RPC_COUNT,
a.ELAPSED_TIME,
a.TABLE_SCAN,
a.IS_HIT_PLAN,
(case
when a.PLAN_TYPE = 0 then 'inner'
when a.PLAN_TYPE = 1 then 'local'
when a.PLAN_TYPE = 2 then 'remote'
when a.PLAN_TYPE = 3 then 'distributed'
else null
end ) PLAN_TYPE,
a.c_rq_time
FROM x a inner join (
SELECT min(c_rq_time) start_time,
max(c_rq_time) end_time,
to_char(min(c_rq_time),'YYYY-MM-DD HH24:MI:SS.FF6') start_time_char,
to_char(max(c_rq_time),'YYYY-MM-DD HH24:MI:SS.FF6') end_time_char,
min(to_char(substr(query_sql,1,3000))) min_sql,
max(to_char(substr(query_sql,1,3000))) max_sql,
C_BATCH_ID
from x where (QUERY_SQL like '%insert%in_log%' or QUERY_SQL like '%update%in_log%') -- 某核心系统ISV 核心系统所有场景接口开始和结束都有 insert into service_in_log 和 update service_in_log 表的操作,截取这中间的时间段
GROUP BY C_BATCH_ID
) b on a.c_batch_id = b.c_batch_id and a.c_rq_time between b.start_time
and b.end_time and a.user_name <> 'YZJ' ) A
order by 服务层SQL请求时间 asc , 事务ID asc , 事务内顺序 asc;
二、real_time_cdc_proc 存储过程介绍、使用
1、介绍
real_time_cdc_proc过程相当于是 extract_sqlaudit_proc 的进阶版,将每次人工收集固化数据的操作自动化。源于某银行项目期间对某核心系统ISV V8核心应用在跑批期间持续收集缓慢SQL分析的需求而编写。
因为跑批期间持续时间长,gv$ob_sql_audit 视图内数据可能很快被淘汰掉,所以需要一种持续收集数据的方法,real_time_cdc_proc过程做的就是定期将 gv$ob_sql_audit数据固化到 XZ_SQL_AUDIT_CDC 表内。
PROCEDURE real_time_cdc_proc( p_END_TIME VARCHAR2) -- 结束时间
IS
p_stop_date varchar(200):=p_END_TIME; -- 传入的停止时间,这个时间之前都会增量cdc抽取gv$ob_sql_audit数据
v_stop_date TIMESTAMP ; -- 字符串参数转换日期时间戳的变量
v_num int:=1; -- 循环CNT控制变量
v_current_date TIMESTAMP; -- 当前日期
v_start_time TIMESTAMP ; -- cdc 拉取的开始时间、核心变量
v_end_time TIMESTAMP ; -- cdc 拉取的结束时间、核心变量
v_start_scn NUMBER ; -- cdc 拉取的开始scn、核心变量
v_end_scn NUMBER ; -- cdc 拉取的结束scn、核心变量
v_sql_excute_start_time TIMESTAMP ;
v_sql_excute_end_time TIMESTAMP ;
v_interval INTERVAL day to second; -- 每次 insert into xz_sql_audit_cdc 的间隔时间类型
v_interval_char varchar2(2000); -- 每次 insert into xz_sql_audit_cdc 的间隔类型转换成字符串
v_interval_num NUMBER;
v_sql varchar2(4000);
BEGIN
/*
声明
过程名称: real_time_cdc_proc
函数作用: 该存储过程用于实时收集 `gv$ob_sql_audit` 视图中的数据,并将其固化到 `xz_sql_audit_cdc` 表中。
创建日期: 2024-09-10
作者: (YZJ、须佐)
版本: v2.0
需求说明:
本存储过程是为了满足 XX 银行某核心系统ISV V8 微服务(TCC 架构)核心系统在跑批任务期间实时收集请求的跑批 SQL。
由于 `gv$ob_sql_audit` 视图数据超过内存阈值会被定期刷新,且应用跑批时间较长,因此只能实施实时采集 `gv$ob_sql_audit` 表的数据,并将其固化到 `xz_sql_audit_cdc` 表中。
该存储过程主要用于收集 `gv$ob_sql_audit` 视图中的所有数据,以便后续分析缓慢 SQL 并提供优化建议。
分析手段需要手动编写分析 SQL。
创建前提:
在创建此存储过程之前,需要提前创建以下对象:
1. 序列:SEQ_XZ_SQL_AUDIT_CDC_CID
2. 日志记录表:XZ_CDC_LOG
- 用于记录 `xz_sql_audit_cdc` 表目前采集了多少次数据,每次采集的时间。
3. 数据分析表:XZ_SQL_AUDIT_CDC
- 用于固化 `gv$ob_sql_audit` 视图中的所有数据,后续主要分析该表内容。
调用方法:
建议使用 obclient 命令行工具编写 Shell 脚本后台执行:
```
BEGIN
real_time_cdc_proc(p_END_TIME => '2024-12-12 01:00:00');
-- 2024-12-12 01:00:00 为存储过程结束运行的时间
END;
/
```
*/
BEGIN
/* 如果传入的 p_stop_date 无法转换成日期参数,报错抛出异常,下面的代码不用执行 */
v_stop_date := to_timestamp(p_stop_date,'YYYY-MM-DD HH24:MI:SS');
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('p_stop_date 请传入能转换日期类型的参数!' );
RETURN ;
END;
v_current_date := SYSTIMESTAMP;
WHILE v_current_date <= v_stop_date LOOP
IF v_num = 1 THEN
/* 初始化数据,xz_sql_audit_cdc 灌入10行数据 */
v_sql := '
insert into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where rownum <= 10';
/* 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num;
v_sql_excute_end_time := SYSTIMESTAMP;
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
ELSIF v_num = 2 THEN
v_end_time := SYSTIMESTAMP ; -- 结束时间戳,获取当前时间。
v_start_time := v_end_time - interval '70' second; -- 开始时间戳,结束时间往前面减70秒作为每次数据开始时间。
/*
where request_time > v_start_time:(v_end_time - interval '70' second) and request_time < v_end_time:SYSTIMESTAMP
*/
v_start_scn := timestamp_to_scn(v_start_time) / 1000 ; -- 将开始时间转成开始scn
v_end_scn := timestamp_to_scn(v_end_time) / 1000 ; -- 将结束时间转成结束scn
v_sql := '
insert /*+ APPEND PARALLEL(8) */ into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select /*+ PARALLEL(8) query_timeout(50000000000) */
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where request_time > :2 and request_time < :3' ;
/* 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num,v_start_scn,v_end_scn;
v_sql_excute_end_time := SYSTIMESTAMP;
-- 记录SQL执行的时间
v_interval := (v_sql_excute_end_time - v_sql_excute_start_time);
v_interval_char := to_char(extract(day from v_interval) * 86400 +
extract(hour from v_interval) * 3600 +
extract(minute from v_interval) * 60 +
extract(second from v_interval));
v_interval_num := to_number(v_interval_char);
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
ELSE
/* v_num = 1 第1次初始化装载数据,装载多少没什么关系
v_num = 2 第2次拉取间隔数据,确定好 v_start_time、v_end_time 的时间点。
v_num = 3 第3次以后,继承第2次的时间
start_time = null end_time = null
start_time = t2 - 5 end_time = t2
start_time = t2 end_time = t3
start_time = t3 end_time = t4
*/
v_start_time := v_end_time;
v_end_time := v_end_time + (interval '1' second * v_interval_num);
v_start_scn := timestamp_to_scn(v_start_time) / 1000 ; -- 将开始时间转成开始scn
v_end_scn := timestamp_to_scn(v_end_time) / 1000 ; -- 将结束时间转成结束scn
v_sql := '
insert /*+ APPEND PARALLEL(8) */ into xz_sql_audit_cdc(
C_BATCH_ID,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,QUERY_SQL,PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME)
select /*+ PARALLEL(8) query_timeout(50000000000) */
:1,SVR_IP,SVR_PORT,REQUEST_ID,SQL_EXEC_ID,TRACE_ID,SID,CLIENT_IP,CLIENT_PORT,TENANT_ID,EFFECTIVE_TENANT_ID,
TENANT_NAME,USER_ID,USER_NAME,USER_GROUP,USER_CLIENT_IP,DB_ID,DB_NAME,SQL_ID,to_char(substr(QUERY_SQL,1,3995)),PLAN_ID,AFFECTED_ROWS,
RETURN_ROWS,PARTITION_CNT,RET_CODE,QC_ID,DFO_ID,SQC_ID,WORKER_ID,EVENT,P1TEXT,P1,P2TEXT,P2,P3TEXT,P3,WAIT_CLASS_ID,
WAIT_CLASS#,WAIT_CLASS,STATE,WAIT_TIME_MICRO,TOTAL_WAIT_TIME_MICRO,TOTAL_WAITS,RPC_COUNT,PLAN_TYPE,IS_INNER_SQL,
IS_EXECUTOR_RPC,IS_HIT_PLAN,REQUEST_TIME,ELAPSED_TIME,NET_TIME,NET_WAIT_TIME,QUEUE_TIME,DECODE_TIME,GET_PLAN_TIME,
EXECUTE_TIME,APPLICATION_WAIT_TIME,CONCURRENCY_WAIT_TIME,USER_IO_WAIT_TIME,SCHEDULE_TIME,ROW_CACHE_HIT,
BLOOM_FILTER_CACHE_HIT,BLOCK_CACHE_HIT,DISK_READS,RETRY_CNT,TABLE_SCAN,CONSISTENCY_LEVEL,MEMSTORE_READ_ROW_COUNT,
SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT,BLOCKSCAN_BLOCK_CNT,
BLOCKSCAN_ROW_CNT,PUSHDOWN_STORAGE_FILTER_ROW_CNT,REQUEST_MEMORY_USED,EXPECTED_WORKER_COUNT,USED_WORKER_COUNT,SCHED_INFO,
PS_CLIENT_STMT_ID,PS_INNER_STMT_ID,TX_ID,SNAPSHOT_VERSION,REQUEST_TYPE,IS_BATCHED_MULTI_STMT,OB_TRACE_INFO,PLAN_HASH,
PARAMS_VALUE,RULE_NAME,TX_INTERNAL_ROUTING,TX_STATE_VERSION,FLT_TRACE_ID,NETWORK_WAIT_TIME
from gv$ob_sql_audit where request_time > :2 and request_time < :3' ;
/* 批插数据 执行SQL */
v_sql_excute_start_time := SYSTIMESTAMP ;
EXECUTE IMMEDIATE V_SQL USING v_num,v_start_scn,v_end_scn;
v_sql_excute_end_time := SYSTIMESTAMP;
-- 记录SQL执行的时间
v_interval := (v_sql_excute_end_time - v_sql_excute_start_time);
v_interval_char := to_char(extract(day from v_interval) * 86400 +
extract(hour from v_interval) * 3600 +
extract(minute from v_interval) * 60 +
extract(second from v_interval));
v_interval_num := to_number(v_interval_char);
INSERT INTO xz_cdc_log values(v_num,v_start_time,v_end_time,v_start_scn,v_end_scn,(v_sql_excute_end_time-v_sql_excute_start_time));
/* 初始化数据的提交,只提交一次 */
COMMIT ;
END IF ;
v_num := v_num + 1;
v_current_date := SYSTIMESTAMP ;
END LOOP ;
COMMIT ;
-- 调试代码
/* if v_stop_date = to_date('2024-01-01','YYYY-MM-DD') THEN
DBMS_OUTPUT.PUT_LINE('true') ;
else
DBMS_OUTPUT.PUT_LINE('false') ;
END IF;
DBMS_OUTPUT.PUT_LINE('调式代码-p_stop_date:'|| to_char(v_stop_date,'YYYY-MM-DD HH24:MI:SS') );
*/
END;
2、调用存储过程
建议使用 obclient 命令行工具编写 Shell 脚本后台执行
BEGIN
real_time_cdc_proc(p_end_time => '2024-12-12 01:00:00'); -- 2024-12-12 01:00:00 为存储过程结束运行的时间
END;
/
nohup obclient -h11.161.204.57 -P2883 -uYZJ@oracle_pub#availabilitytest -p"xxxxx" -e "source real_time_cdc_proc.sql" &
3、参数说明
p_end_time 参数 :时间格式yyyy-mm-dd hh24:mi:ss。 传入一个截止时间,例如:2024-12-01 01:00:00 ,到了这个时间点,real_time_cdc_proc 存储过程会自动停止运行。
4、注意
real_time_cdc_proc 被停止后(无论是自动停止,还是被手动 kill 掉后台会话),如果直接重新启动 real_time_cdc_proc 会报错,无法继续运行。
需要做以下操作:
- 如果之前的数据还需要:
* 备份 xz_sql_audit_cdc 和 xz_cdc_log 这两张表,建议对这两张表重命名。
* 命名完成后执行 manage_objects 存储过程。
* 然后可以继续执行过程。
alter table xz_sql_audit_cdc rename to xz_sql_audit_cdc_1;
alter table xz_cdc_log rename to xz_cdc_log_1;
BEGIN
manage_objects( p_action => 'delete'); -- 删除所有对象
END;
/
BEGIN
manage_objects( p_action => 'init'); -- 创建对象
END;
/
BEGIN
real_time_cdc_proc(p_end_time => '2024-12-12 01:00:00'); -- 2024-12-12 01:00:00 为存储过程结束运行的时间
END;
/
nohup obclient -h11.161.204.57 -P2883 -uYZJ@oracle_pub#availabilitytest -p"xxxxx" -e "source real_time_cdc_proc.sql" &
- 如果之前的数据不需要:
* 直接执行manage_objects 存储过程,然后可以继续执行过程。
BEGIN
manage_objects( p_action => 'delete'); -- 删除所有对象
END;
/
BEGIN
manage_objects( p_action => 'init'); -- 创建对象
END;
/
BEGIN
real_time_cdc_proc(p_end_time => '2024-12-12 01:00:00'); -- 2024-12-12 01:00:00 为存储过程结束运行的时间
END;
/
nohup obclient -h11.161.204.57 -P2883 -uYZJ@oracle_pub#availabilitytest -p"xxxxx" -e "source real_time_cdc_proc.sql" &
5、监控real_time_cdc_proc数据同步的进度
可以观察 xz_cdc_log 表,知道目前数据同步到哪个时间点。
execute_time 是指本次拉数据花了多次时间。
c_end_time - c_start_time 永远等于上一次拉数据的 execute_time。
通过这种逻辑能保证 real_time_cdc_proc存储过程拉取 gv$ob_sql_audit 的数据不会有遗漏。
select
c_batch_id,
to_char(c_start_time,'yyyy-mm-dd hh24:mi:ss.ff6') c_start_time,
to_char(c_end_time,'yyyy-mm-dd hh24:mi:ss.ff6') c_end_time,
c_end_time - c_start_time c_last_time,
c_execute_time execute_time
from XZ_CDC_LOG order by 1 desc;
6、分析缓慢SQL数据
SELECT /*+ PARALLEL(64) */
xzzz.c_name,
xzzz.c_start_time,
xzzz.c_end_time,
xzzz.user_name ,
xzzz.db_name ,
xzzz.SQL_ID ,
xzzz.sql语句,
nvl(ob_tools.get_table_info(ob_tools.get_table_name(xzzz.db_name,xzzz.sql语句)),'none') 表信息,
xzzz.sql执行次数,
xzzz.计划次数,
xzzz.sql_cpu_时间占比,
xzzz.平均执行时间,
xzzz.平均总执行时间,
xzzz.最大总执行时间,
xzzz.平均重试次数,
xzzz.平均RPC次数,
xzzz.平均RPC接收到时间,
xzzz.平均请求接收时间,
xzzz.平均队列时间,
xzzz.平均出队列解析时间,
xzzz.平均获取计划时间
from (
SELECT
xzz.c_name as c_name,
xzz.c_start_time as c_start_time,
xzz.c_end_time as c_end_time,
upper(xzz.user_name) as user_name ,
upper(xzz.db_name) as db_name ,
xzz.sql_id as SQL_ID ,
count(1) as sql执行次数,
max(xzz.c_query_sql) as sql语句,
max(xzz.c_plan_cnt) as 计划次数,
round((sum(xzz.execute_time) / xzz.cpu_sum) * 100, 2) as sql_cpu_时间占比,
round(avg(xzz.execute_time) ,2)/1000 as 平均执行时间,
round(avg(xzz.elapsed_time) ,2)/1000 as 平均总执行时间,
round(max(xzz.ELAPSED_TIME) ,2)/1000 as 最大总执行时间,
round(avg(xzz.retry_cnt) ,2) as 平均重试次数,
round(avg(xzz.rpc_count) ,2) as 平均RPC次数,
round(avg(xzz.net_time) ,2)/1000 as 平均RPC接收到时间,
round(avg(xzz.net_wait_time) ,2)/1000 as 平均请求接收时间,
round(avg(xzz.queue_time) ,2)/1000 as 平均队列时间,
round(avg(xzz.decode_time) ,2)/1000 as 平均出队列解析时间,
round(avg(xzz.get_plan_time) ,2)/1000 as 平均获取计划时间
from (
SELECT xz.*,
LISTAGG(distinct UPPER(xz.c_plan_type) || ':' || xz.c_plan_type_cnt , ',')
WITHIN GROUP(ORDER BY xz.c_plan_type)
over(partition by xz.c_name,xz.user_name,xz.db_name,xz.sql_id) c_plan_cnt
from (
SELECT
x.*,
count(x.c_plan_type) over(partition by x.c_name,x.user_name,x.db_name,x.sql_id,x.c_plan_type) c_plan_type_cnt
from (
SELECT
a.*,
b.*,
--nvl(get_table_info(get_table_name(b.db_name,b.query_sql)),'none') c_table_name,
to_char(substr(b.query_sql, 1, 4000)) c_query_sql,
(case
when b.PLAN_TYPE = 0 then 'inner'
when b.PLAN_TYPE = 1 then 'local'
when b.PLAN_TYPE = 2 then 'remote'
when b.PLAN_TYPE = 3 then 'distributed'
else null end) c_plan_type,
sum(b.execute_time) over(partition by a.c_name) cpu_sum
FROM (
/* 建议了解清楚跑批每个步骤的流程,每个流程的名称、每个流程的开始和结束时间,
使用UNION ALL 合并到一起成为一个跑批的任务流水表,任务流越细,越能分析出性能瓶颈
*/
select '步骤1:换日前数据清理' c_name,
(timestamp_to_scn(to_timestamp('2024-09-13 21:25:40:669','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_start_scn,
(timestamp_to_scn(to_timestamp('2024-09-13 21:25:48:181','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_end_scn,
to_char(to_timestamp('2024-09-13 21:25:40:669','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_start_time,
to_char(to_timestamp('2024-09-13 21:25:48:181','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_end_time
from dual
union all
select '步骤2:换日前' c_name,
(timestamp_to_scn(to_timestamp('2024-09-13 21:27:01:281','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_start_scn,
(timestamp_to_scn(to_timestamp('2024-09-13 21:34:31:893','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_end_scn,
to_char(to_timestamp('2024-09-13 21:27:01:281','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_start_time,
to_char(to_timestamp('2024-09-13 21:34:31:893','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_end_time
from dual
union all
select '步骤3: 换日' c_name,
(timestamp_to_scn(to_timestamp('2024-09-13 21:35:40:493','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_start_scn,
(timestamp_to_scn(to_timestamp('2024-09-13 21:36:20:912','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_end_scn,
to_char(to_timestamp('2024-09-13 21:35:40:493','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_start_time,
to_char(to_timestamp('2024-09-13 21:36:20:912','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_end_time
from dual
union all
select '步骤4:换日后' c_name,
(timestamp_to_scn(to_timestamp('2024-09-13 21:51:30:641','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_start_scn,
(timestamp_to_scn(to_timestamp('2024-09-13 22:15:49:056','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_end_scn,
to_char(to_timestamp('2024-09-13 21:51:30:641','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_start_time,
to_char(to_timestamp('2024-09-13 22:15:49:056','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_end_time
from dual
union all
select '步骤5:换日后数据清理' c_name,
(timestamp_to_scn(to_timestamp('2024-09-13 22:17:00:520','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_start_scn,
(timestamp_to_scn(to_timestamp('2024-09-13 23:12:54:548','yyyy-mm-dd hh24:mi:ss:ff6')) / 1000) c_end_scn,
to_char(to_timestamp('2024-09-13 22:17:00:520','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_start_time,
to_char(to_timestamp('2024-09-13 23:12:54:548','yyyy-mm-dd hh24:mi:ss:ff6'),'YYYY-MM-DD HH24:MI:SS.FF6') c_end_time
from dual
) a inner join xz_sql_audit_cdc b
on b.request_time between a.c_start_scn and a.c_end_scn
where b.user_name not in ('YZJ')
and b.db_name not in ('YZJ')
) x
)xz
) xzz
GROUP BY
xzz.c_name,
xzz.c_start_time,
xzz.c_end_time,
xzz.db_name,
xzz.user_name,
xzz.sql_id,
xzz.cpu_sum
) xzzz
where xzzz.sql_cpu_时间占比 > 0.5
ORDER BY 1 ASC, 11 DESC;
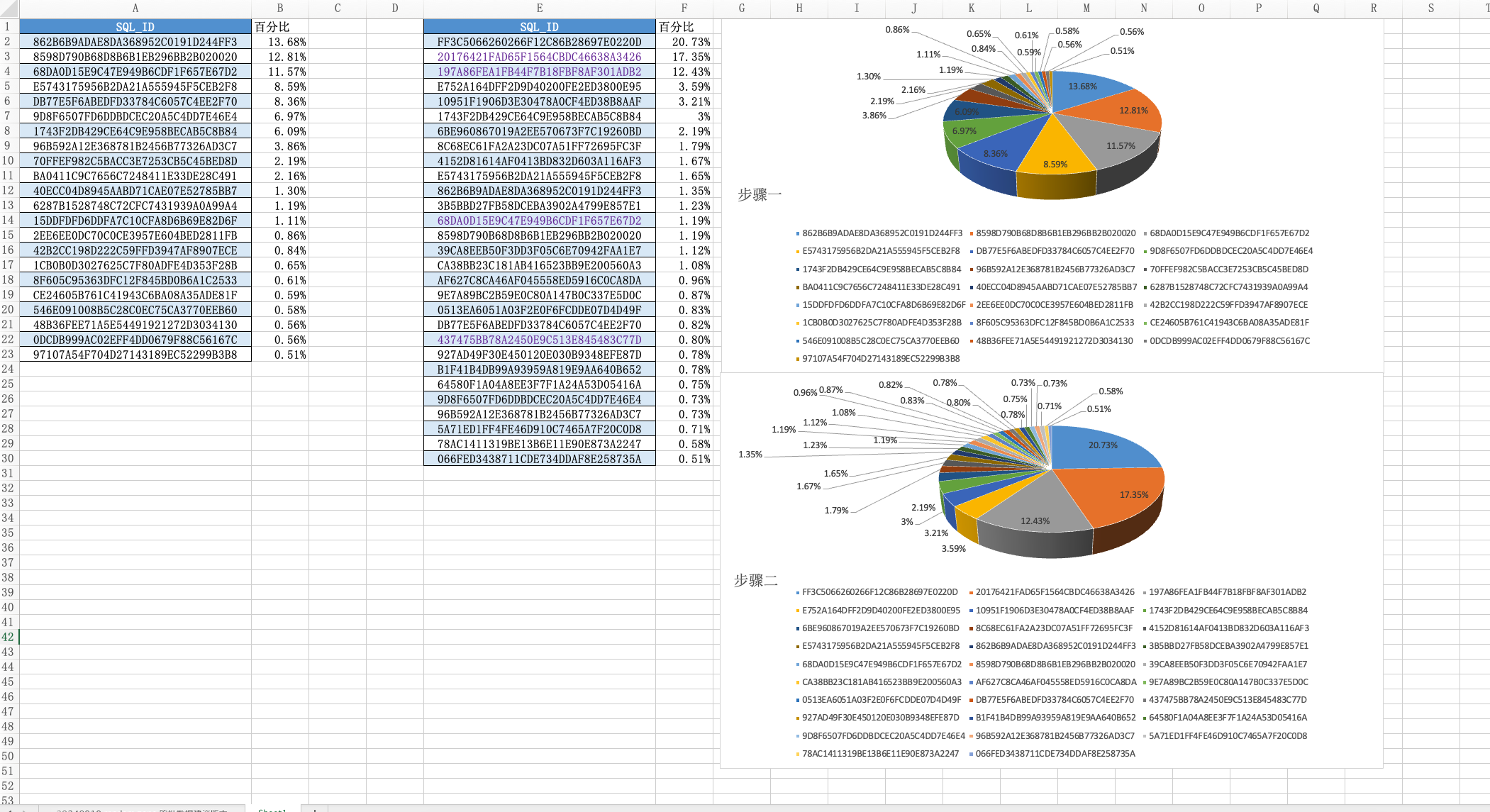
目前还在不断积累不同维度的分析 SQL 语句。ODC 我感觉有个很大的优点,是能够导出 Excel 报表。
通过编写相应的 SQL 分析语句,ODC 可以生成不同维度和时间点的数据报表,并以图形化的方式展现,使得数据分析更为直观和美观。
三、get_table_name、get_table_info 函数介绍、使用
1、介绍
在最初分析 Excel 表格中的 SQL 语句并提出优化建议时,仅获取 SQL 语句和数据库名称的信息,而表名及相关信息需要通过 SQL 语句逐一查找并使用 SHOW CREATE TABLE 等命令,这显得非常繁琐。因此,我写了以下两个函数:
**get_table_name**:此函数从输入的 SQL 语句中提取一个或多个表名。它利用正则表达式匹配关键字(如 FROM 和 JOIN)来识别表名,并与所有者名拼接,最终返回以逗号分隔的表名列表。该函数适用于标准 SQL 语句,便于快速获取相关表信息。**get_table_info**:此函数接收由get_table_name提取的表名列表,获取每个表的详细信息,包括分区规则、本地和全局索引数量、主键数量及数据行数。通过访问数据库视图,该函数提取信息并格式化为易读输出,方便后续分析和优化。
这两个函数可以协同工作,使我能够高效地从 SQL 语句中获取表名和表信息,提高了我的工作效率。
2、调用函数
select ob_tools.get_table_info(ob_tools.get_table_name(a.db_name,a.query_sql)) from gv$ob_sql_audit;
表名 | 分区规则 | 本地索引数量 | 全局索引数量 | 主键PK数量 | 数据行数
------------------------------------------------------------------------------------------------------------------------------------------------
ENS_CBANK.MB_GL_HIST_TOTAL | 非分区表 | 0 | 1 | 1 | 0
ENS_CBANK.MB_GL_HIST | 非分区表 | 0 | 3 | 1 | 0
ENS_CBANK.MB_PROD_TYPE | 非分区表 | 0 | 1 | 1 | 658
ENS_CBANK.MB_GL_HIST | 非分区表 | 0 | 3 | 1 | 0
ENS_CBANK.BAT_MB_BUSINESS_INFO | 非分区表 | 0 | 0 | 0 | 7
ENS_CBANK.MB_GL_HIST | 非分区表 | 0 | 3 | 1 | 0
ENS_CBANK.MB_FEE_AMORTIZE_AGR | 非分区表 | 0 | 1 | 1 | 16364
------------------------------------------------------------------------------------------------------------------------------------------------
表名 | 分区规则 | 本地索引数量 | 全局索引数量 | 主键PK数量 | 数据行数
------------------------------------------------------------------------------------------------------------------------------------------------
ENS_CBANK.MB_ACCT | PARTITION BY HASH("BRANCH") | 0 | 18 | 0 | 17289678
ENS_CBANK.MB_ACCT_SETTLE | PARTITION BY HASH("INTERNAL_KEY") | 1 | 4 | 1 | 12758205
------------------------------------------------------------------------------------------------------------------------------------------------
3、参数说明
**get_table_name**** 函数:****p_owner**** (VARCHAR2)**: 表的所有者(schema)名称,用于构建完整的表名。通常是大写字母。**p_string_sql**** (CLOB、VARCHAR2)**: 输入的 SQL 语句,函数将从中提取表名。
select ob_tools.get_table_name('ENS_CBANK','
SELECT c.settle_acct_internal_key
FROM (SELECT distinct a.settle_acct_internal_key
FROM MB_ACCT_SETTLE a
where (A.SETTLE_ACCT_CLASS = ''AUT'' or
(A.SETTLE_ACCT_CLASS = ''SSI'' and a.settle_weight > 0))
and a.settle_acct_internal_key BETWEEN ''27417440'' and ''27475285''
and nvl(a.priority, ''1'') = ''1''
and exists (select 1
from mb_acct b
WHERE a.INTERNAL_KEY = b.INTERNAL_KEY
and b.source_module = ''CL''
and b.auto_settle = ''Y''
and b.lead_acct_flag = ''N''
and B.acct_status != ''C'')) c,
mb_acct d
WHERE c.settle_acct_internal_key = d.INTERNAL_KEY
AND d.ACCT_STATUS != ''C''
' ) tb_name from dual;
返回:ENS_CBANK.MB_ACCT_SETTLE,ENS_CBANK.MB_ACCT
**get_table_info**** 函数:****p_tablename_list**** (VARCHAR2)**: 以逗号分隔的表名列表,包含所有者和表名的组合(如schema1.table1, schema2.table2)。该参数用于获取每个表的详细信息。
4、注意
使用这两个函数时,需要注意以下几点:
- SQL 语句格式:确保输入的 SQL 语句符合标准格式,特别是包含表名的部分。
get_table_name函数不支持逗号分隔的表连接和非标准 SQL 语句,例如:select * from a,b where a.id = b.id(不支持)。 - 输入参数有效性:确保
get_table_info函数传入的参数是正确的,强烈建议配合get_table_name函数一起使用,避免在调用因格式问题导致查询失败。 - 性能影响:注意在大数据量的环境中,函数执行可能会影响性能,处理大批量数据的时候不建议带上这两个函数,最好是等所有数据聚合完成后,在查询的最外层(返回数据少的情况下),使用这两个函数。
-- 假如返回 99998 行数据,不建议这样使用
select ob_tools.get_table_info(ob_tools.get_table_name(a.db_name,a.query_sql)) tb_info from xz_sql_audit_cdc a where a.request_time > 1 and a.request_time < 99999;
-- 建议聚合返回少量数据以后,最外层使用函数
select
ob_tools.get_table_info(ob_tools.get_table_name(x.db_name,x.qsql))
from (
select
a.db_name,
a.sql_id,
max(a.query_sql) qsql
from xz_sql_audit_cdc a
where a.request_time > 1 and a.request_time < 99999
group by a.db_name,a.sql_id
) x
- 数据正确性:
get_table_info函数返回的数据,本地索引数量、全局索引数量、主键PK数量这几个值都是通过XZ_INDEXES视图查询出来,将系统视图数据同步到辅助表提供给函数能提高性能。如果期间有做过一些业务的改造,例如对表加了主键,增加了本地或者全局索引的操作,继续使用get_table_info查询出来表的信息会跟原来的数据一样。因为get_table_info函数查询的XZ_INDEXES辅助表的数据并没有更新,此时我们只需要更新下XZ_INDEXES表数据即可, 使用manage_objects过程更新完成后,get_table_info函数能查出正确的表信息。
BEGIN
manage_objects( p_action => 'UPDATE'); -- 更新数据
END;
/
================ UPDATE - 更新表 XZ_INDEXES 和 XZ_OBJECTS ================
开始清空表: XZ_INDEXES
开始时间: 2024-09-28 22:52:20.528044
结束时间: 2024-09-28 22:52:20.605177
耗时: +00 00:00:00.077133
重新导入数据到 XZ_INDEXES
开始时间: 2024-09-28 22:52:20.605831
结束时间: 2024-09-28 22:52:21.161543
耗时: +00 00:00:00.555712
开始清空表: XZ_OBJECTS
开始时间: 2024-09-28 22:52:21.162242
结束时间: 2024-09-28 22:52:21.231126
耗时: +00 00:00:00.068884
重新导入数据到 XZ_OBJECTS
开始时间: 2024-09-28 22:52:21.231995
结束时间: 2024-09-28 22:52:21.519196
耗时: +00 00:00:00.287201
使用ob_tools包收集分析oceanbase数据库oracle租户缓慢sql语句的更多相关文章
- Oracle数据库中,在SQL语句中连接字符串的方法是哪个?(选择1项)
Oracle数据库中,在SQL语句中连接字符串的方法是哪个?(选择1项) A.cat B.concat C.join D.+ 解答:B
- Oracle数据库查看表空间sql语句
转: Oracle数据库查看表空间sql语句 2018-09-03 15:49:51 兰海泽 阅读数 6212 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出 ...
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- 如何找出MySQL数据库中的低效SQL语句
面对业务的迅猛发展,DBA的一项重要工作就是及时发现数据库中的低效SQL语句,有的可以立刻着手解决(比如缺少合适的索引),有的需要尽快反馈给开发人员进行修改. MySQL数据库有几个配置选项可以帮助我 ...
- DBA 需要知道N种对数据库性能的监控SQL语句
--DBA 需要知道N种对数据库性能的监控SQL语句 -- IO问题的SQL内部分析 下面的DMV查询可以来检查当前所有的等待累积值. Select wait_type, waiting_tasks_ ...
- oracle中查看sql语句的执行计划
1.在pl/sql中打开cmd命令容器 2.在cmd命令窗口中输入:explain plan for select * from t; 3.查看sql语句的执行计划:select * from tab ...
- 说说oracle分页的sql语句
说说oracle分页的sql语句,分排序和不排序两种. 当结果集不需要进行排序时,每页显示条数为:rowPerPage,当前页数为:currentPage. 1. 相对来说,这种查询速度会快一些,因为 ...
- 创建数据库和表的SQL语句【转】
创建数据库和表的SQL语句 转至http://www.cnblogs.com/philanthr/archive/2011/08/09/2132398.html 创建数据库的SQL语句: 1 crea ...
- Python3:sqlalchemy对sybase数据库操作,非sql语句
Python3:sqlalchemy对sybase数据库操作,非sql语句 # python3 # author lizm # datetime 2018-02-01 10:00:00 # -*- c ...
- Python3:sqlalchemy对mysql数据库操作,非sql语句
Python3:sqlalchemy对mysql数据库操作,非sql语句 # python3 # author lizm # datetime 2018-02-01 10:00:00 # -*- co ...
随机推荐
- Python向IP地址发送字符串
在Python中,向IP地址发送字符串通常意味着你需要通过某种协议来实现通信.最常见的协议包括TCP和UDP.这里,我将分别给出使用TCP和UDP协议向指定IP地址发送字符串的示例代码. 1.TCP. ...
- stm32学习之调试篇踩坑记录
如何下载fml文件 找不到64k的fml文件 could not stop cortex-m device:无法连接,我当时是在程序中的一些初始化函数中,有几条语句禁用了(JTAG+SW) 接线顺序, ...
- 无分号js风格注意的三个问题
建议如果一行代码是以 ( [ ` 开头的,则最好都在其前面补上一个分号. // 1.( function say() { console.log('hello world') } // ...
- 构建 OpenWrt
OpenWrt 是一款路由器操作系统.如果你想要给自己的路由器安装 OpenWrt 的话,一般来说使用别人已经构建好的 OpenWrt 固件就够用了.当然如果你闲得没事干,那么也可以自己构建固件. P ...
- SSH 登陆 Windows 时踩过的坑
有一次处于某些原因我在 Mac 上使用 SSH 远程登陆了 Windows,然后在 Windows 上使用 SSH 登陆 localhost,惊讶地发现登不进去!SSH 提示公钥验证失败.可是我的 W ...
- Blazor开发框架Known-V2.0.10
Known今天迎来了2.0的第11个版本,同时网站网址和板块也进行了一次升级改造,虽不完美,但一直在努力改变,之前一直在完善框架功能,忽略了文档的重要性,所以这次更新了文档和API.交流互动板块也在进 ...
- Angular Material 18+ 高级教程 – CDK Table
前言 CDK Table 是 Angular Material 对 <table> 的抽象 (无 styles) 封装. 无 styles 的 table 有什么好封装的呢? CDK Ta ...
- CSS – Logical Properties
前言 续上一篇介绍了各种语言的阅读方向. 这一篇来讲一下 Logical Properties. 它与 left to right, right to left, horizontal, vertic ...
- 分布式执行引擎Ray-部署
1. Ray集群 Ray 有多种部署模式,包括单机,k8s,VM等. 在单机下,可以直接用ray.init来快速启动ray的运行环境,但是如果要在多节点上执行,则必须先部署Ray Cluster. 一 ...
- Kubernetes基础(kube-apiserver?kube-controller-manager?kube-scheduler?kubelet?kube-proxy?kubectl?)(十一)
一.kube-apiserver API Server 提供了资源对象的唯一操作入口,其它所有组件都必须通过它提供的 API 来操作资源数据.只有 API Server 会与 etcd 进行通信,其它 ...