Flink CDC 实时同步 MySQL


- Flink CDC 实时同步 MySQL
- Flink CDC 实时同步 Oracle
准备工作
MySQL 数据库(version:
5.7.25),注意,MySQL 数据库版本必须大于 5.6,否则不支持。开启 MySQL 的 log-bin:
[mysqld]
# Binary Logging.
log-bin=mysql-bin
server-id=1
Flink (version :
1.18.1)添加以下 jar 包到
flink/lib:flink-sql-connector-mysql-cdc.jar负责 sourceflink-connector-jdbc.jar负责 sinkmysql-connector-java.jarsink 端所需的 jdbc 驱动

准备待同步源端表
源端表:
cdc_test_source.player_sourceCREATE TABLE `player_source` (
`id` int(11),
`name` varchar(255),
PRIMARY KEY (`id`)
);
准备目标端表
在目标端创建和源端同构的表:
cdc_test_target.player_targetCREATE TABLE `player_target` (
`id` int(11),
`name` varchar(255),
PRIMARY KEY (`id`)
);
SQL-Client 实现数据同步
使用 Flink 的 sql-client 实现数据同步
启动 Flink
./bin/start-cluster.sh
启动 sql-client
sudo ./bin/sql-client.sh

数据同步任务创建
创建源端表对应的逻辑表,参照 MySQL 字段类型和 FlinkSQL 字段类型的映射关系
CREATE TABLE source_dest (
`id` INT ,
`name` STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'username',
'password' = 'password',
'database-name' = 'cdc_test_source',
'table-name' = 'player_source'
);
创建目标端表对应的逻辑表
CREATE TABLE sink_dest (
`id` INT,
`name` STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://127.0.0.1:3306/cdc_test_target',
'username' = 'username',
'password' = 'password',
'table-name' = 'player_target',
'sink.parallelism' = '1'
);
建立源端逻辑表和目标端逻辑表的连接
INSERT INTO
sink_dest (id, name)
SELECT
id,
name
FROM
source_dest;
任务创建成功:
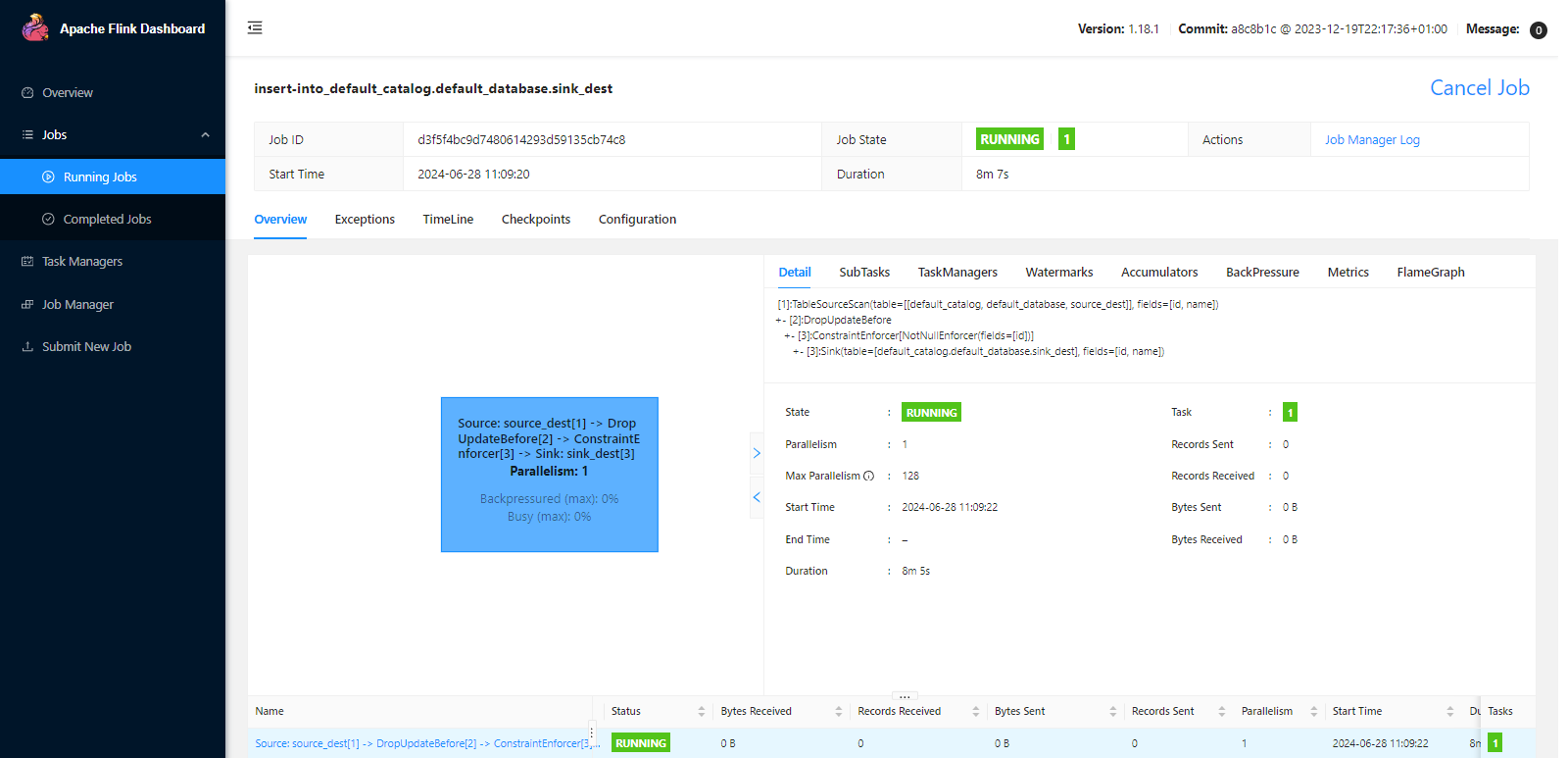
Flink Web 查看提交的任务:
源端表中进行更新、删除操作,查看目标端表是否自动完成同步
TableAPI 实现数据同步
引入 maven 依赖:
<properties>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.15.4</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.4.0</version>
</dependency>
<dependencies>
程序实现:
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.StatementSet;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkSQL {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 9091);
// configuration.setString("execution.checkpointing.interval", "3min");
StreamExecutionEnvironment env = StreamExecutionEnvironment
.createLocalEnvironmentWithWebUI(configuration);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String createSourceTableSQL = "CREATE TABLE source_dest (" +
"`id` INT," +
"`name` STRING," +
"PRIMARY KEY (`id`) NOT ENFORCED" +
") WITH (" +
"'connector' = 'mysql-cdc'," +
"'hostname' = '127.0.0.1'," +
"'username' = 'username'," +
"'password' = 'password'," +
"'database-name' = 'cdc_test_source'," +
"'table-name' = 'player_source'," +
"'scan.startup.mode' = 'latest-offset'" +
");";
tableEnv.executeSql(createSourceTableSQL);
String createSinkTableSQL = "CREATE TABLE sink_dest (" +
"`id` INT," +
"`name` STRING," +
"PRIMARY KEY (`id`) NOT ENFORCED" +
") WITH (" +
"'connector' = 'jdbc'," +
"'url' = 'jdbc:mysql://127.0.0.1:3306/cdc_test_target'," +
"'username' = 'username'," +
"'password' = 'password'," +
"'table-name' = 'player_target'" +
");";
tableEnv.executeSql(createSinkTableSQL);
String insertSQL = "INSERT INTO sink_dest SELECT * FROM source_dest;";
StatementSet statementSet = tableEnv.createStatementSet();
statementSet.addInsertSql(insertSQL);
statementSet.execute();
}
}
我们在 Configuration 中设置了 rest.port = 9091, 程序启动成功后,可以在浏览器打开 localhost:9091 看到提交运行的任务。
scan.startup.mode 可取值为:
initial:当没有指定 `scan.startup.mode` 时,默认取值为 `initial`,官网对 initial 的 [说明原文](https://nightlies.apache.org/flink/flink-cdc-docs-master/zh/docs/connectors/cdc-connectors/mysql-cdc/#startup-reading-position) 是 `Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.`
earliest-offset:可访问的最早的 binlog 偏移量。
latest-offset:从 binlog 的末尾位置开始读取,这意味着只接收 connector 启动之后的变更事件流。
specific-offset:跳过快照阶段,从特定偏移量开始读取 binlog 事件。该偏移量可以使用二进制日志文件名和位置指定。
timestamp:从一个指定的时间戳位置开始读取 binlog,时间的设定很方便,但是根据 timestamp 定位到具体的 offset 需要经过一点儿时间。
遇到的问题
执行 FlinkSQL 报错
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException:
Could not find any factory for identifier 'mysql-cdc' that
implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
Available factory identifiers are:
blackhole
datagen
filesystem
jdbc
oracle-cdc
print
python-input-format
错误原因
不识别源端定义的 mysql-cdc ,缺少 `flink-sql-connector-mysql-cdc.jar。
解决方案
添加 flink-connector-jdbc.jar 和 flink-sql-connector-mysql-cdc.jar 重启后解决。
MySQL 开启 bin-log 报错
[ERROR] You have enabled the binary log, but you haven’t provided the mandatory server-id.
Please refer to the proper server start-up parameters documentation
2016-09-03T03:17:51.815890Z 0 [ERROR] Aborting
报错原因
在设置 bin-log 日志的时候,没有设置 server_id 参数。server-id 参数用于在复制中,为主库和备库提供一个独立的 ID,以区分主库和备库;
开启二进制文件的时候,需要设置这个参数。
解决方案
修改 MySQL 配置文件 my.ini (windows) / my.cnf (linux)
[mysqld]
# Binary Logging.
log-bin=mysql-bin
server-id=1
重启 MySQL 服务。
Flink CDC 实时同步 MySQL的更多相关文章
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- maxwell实时同步mysql中binlog
概述 Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis.RabbitMQ.Redis.Google Cloud ...
- canal-1.1.5实时同步MySQL数据到Elasticsearch
一.环境准备 1.jkd 8+ 2.mysql 5.7+ 3.Elasticsearch 7+ 4.kibana 7+ 5.canal.adapter 1.1.5 二.部署 一.创建数据库CanalD ...
- flink-cdc实时同步mysql数据到elasticsearch
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- 使用maxwell实时同步mysql数据到kafka
一.软件环境: 操作系统:CentOS release 6.5 (Final) java版本: jdk1.8 zookeeper版本: zookeeper-3.4.11 kafka 版本: kafka ...
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
- rsync实时同步mysql数据库
1.主机slave 注:没有包的可以去下载 yum -y install gcc gcc-c++ 上传包 rsync-3.1.3.tar.gz 使用tar命令解压 使用gcc gcc-c++编译 ./ ...
- Mysql 到 Hbase 数据如何实时同步,强大的 Streamsets 告诉你
很多情况大数据集群需要获取业务数据,用于分析.通常有两种方式: 业务直接或间接写入的方式 业务的关系型数据库同步到大数据集群的方式 第一种可以是在业务中编写代码,将觉得需要发送的数据发送到消息队列,最 ...
- Mysql数据实时同步
企业运维的数据库最常见的是 mysql;但是 mysql 有个缺陷:当数据量达到千万条的时候,mysql 的相关操作会变的非常迟缓; 如果这个时候有需求需要实时展示数据;对于 mysql 来说是一种灾 ...
- mysql实时同步到mssql的解决方案
数据库在应用程序中是必不可少的部分,mysql是开源的,所以很多人它,mssql是微软的,用在windows平台上是非常方便的,所以也有很多人用它.现在问题来了,如何将这两个数据库同步,即数据内容保持 ...
随机推荐
- linux 操作系统下安装可视化界面
一.安装背景 1.小白一只,英文不熟.还很菜,面了几个实施,打击的体无完肤!so,人丑多读书吧. 2.安装环境: VMware + centos7 3.本着不懂就问的原则 开始了--- 二.安装前准备 ...
- Devexpress GridControl下拉框实现联动
实现效果 1.先在设计界面绑定数据列 1.点击设计器 2.绑定数据列 2. 绑定GridView的 FocusedRowChanged事件 //定义两个下拉框 _RIcmbtype:不良分类 _RIc ...
- Round #2022/12/03
问题 B: 约数个数 题目描述 有 \(t\) 次询问,每次给你一个数 \(n\) ,求在 \([1,n]\) 内约数个数最多的数的约数个数. 输入 第一行一个正整数 \(t\) . 之后 \(t\) ...
- TreeMap源码详解—彻底搞懂红黑树的平衡操作
介绍 TreeSet和TreeMap在Java里有着相同的实现,前者仅仅是对后者做了一层包装,也就是说TreeSet里面有一个TreeMap(适配器模式). Java TreeMap实现了Sorted ...
- C# – class, filed, property, const, readonly, get, set, init, required 使用基础
前言 心血来潮,这篇讲点基础的东西. Field 比起 Property,Field 很不起眼,你若问 JavaScript,它甚至都没有 Field. 但在 C#,class 里头真正装 value ...
- Python条件语句 if
语法: 示例: if elif else:
- 三,MyBatis-Plus 的各种查询的“超详细说明”,比如(等值查询,范围查询,模糊查询...)
三,MyBatis-Plus 的各种查询的"超详细说明",比如(等值查询,范围查询,模糊查询...) @ 目录 三,MyBatis-Plus 的各种查询的"超详细说明&q ...
- 【VMware VCF】使用 VCF Import Tool 将现有 vSphere 环境导入为 VI 域。
VCF Import Tool 工具使用两种方式来帮助客户将现有的 vSphere 或 vSphere + vSAN 环境转变为 VMware Cloud Foundation 环境,分别是转换(Co ...
- ShardingSphere系列(一)——ShardingSphere-JDBC初体验
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC.Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品 ...
- 多Master节点的k8s集群部署-完整版
多Master节点的k8s集群部署 一.准备工作 1.准备五台主机(三台Master节点,一台Node节点,一台普通用户)如下: 角色 IP 内存 核心 磁盘 Master01 192.168.116 ...