彩笔运维勇闯机器学习--cpu与qps的线性关系
前言
书接上文,上一小节简单介绍了一元回归的基本原理、使用方式,作为运维,实践才是最重要的,那本小节就来实践一下我们之前的话题:探索cpu与qps的关系
获取数据
1. cpu数据
由于我的监控数据在阿里云的prometheus上面,并且阿里云也提供了一种查询方式,通过本地搭建的prometheus的remote_read功能,读取远端阿里云的数据
搭建本地的prometheus
准备配置文件
cat ~/workspace/prometheus/docker/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s). # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus" # metrics_path defaults to '/metrics'
# scheme defaults to 'http'. static_configs:
- targets: ["localhost:9090"] remote_read:
- url: "https://cn-beijing.arms.aliyuncs.com:9443/api/v1/prometheus/***/***/***/cn-beijing/api/v1/read"
read_recent: trueremote_read可以参考 阿里云prometheus文档docker启动
docker run --name=prometheus -d \
-v ./prometheus.yml:/etc/prometheus/prometheus.yml \
-p 9090:9090 \
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \
prom/prometheus
搭建好之后通过prometheus接口来获取数据
def get_container_cpu_usage_seconds_total(start_time, end_time, step):
url = "http://localhost:9090/api/v1/query_range"
query = f'sum(rate(container_cpu_usage_seconds_total{{image!="",pod_name=~"^helloworld-[a-z0-9].+-[a-z0-9].+",namespace="default"}}[{step}s]))' params = {
"query": query,
"start": start_time,
"end": end_time,
"step": step
} response = requests.get(url, params=params)
data = response.json()
return data
我们获取了
helloworld这组pod在某个时间段所使用的cpu之和
2. qps数据
由于我的日志是托管在阿里云的sls,这里依然使用阿里云sls接口,直接把数据拉下来
训练模型
由于sls日志与prometheus涉及到一些敏感内容,我这里直接调用方法,就不展示具体代码了,prometheus的代码可以参考上述,sls日志的代码可以直接去阿里云文档里面模拟接口copy
from flow import get_cpu_data, get_query_data
from datetime import datetime
import pandas as pd
start_time = datetime.strptime('2025-03-21 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-03-21 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 60
sls_step = 3600
query = get_query_data(start_time, end_time, sls_step)
cpu = get_cpu_data(start_time, end_time, step)
print('cpu: ', len(cpu), cpu)
print('query: ', len(query), query)
运行看一下

每分钟获取一次数据,cpu与qps的数据分别打印出来,1440个(只显示了前10个,看下数据长什么样子就行了),这里一定要注意数量对齐
开始训练
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from flow import get_cpu_data, get_query_data
from datetime import datetime
import pandas as pd
start_time = datetime.strptime('2025-03-23 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-03-25 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 60
sls_step = 3600
query = get_query_data(start_time, end_time, sls_step)
cpu = get_cpu_data(start_time, end_time, step)
print('cpu 数据个数为{} ,前10数据为{}'.format(len(cpu), cpu[:10]))
print('query 数据个数为{} ,前10数据为{}'.format(len(query), query[:10]))
# 准备数据
data = {
'cpu': cpu,
'query': query
}
df = pd.DataFrame(data)
X = df[['query']]
y = df['cpu']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=88)
# 创建模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse}, R²: {r2}")
脚本!启动

训练是训练出来的,但是模型好烂啊!
- 我们获取的数据为3天的,3.23 -- 3.25
- MSE高达0.04,我们之前说过,MSE有平方的计算,那实际误差是0.2,基本是20%--30%的水平了
- R²才0.48,该模型只能解释48%的数据
我训练了个寂寞啊,这模型太烂,必须要修正一下
修正模型
修正模型从检查数据开始,看下数据是否有异常。画图是最直观的检查方式,那就找一个开源的库来画图,用matplotlib来完成,安装也非常简单,pip3 install matplotlib
先拿一天的数据来看看,3.23
import matplotlib.pyplot as plt
from datetime import datetime
from flow import get_cpu_data
step = 60
sls_step = 3600
l = [
{
'name': '3-23',
'start_time': datetime.strptime('2025-03-23 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp(),
'end_time': datetime.strptime('2025-03-23 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
},
]
# 画多条线
for piece in l:
cpu = get_cpu_data(piece['start_time'], piece['end_time'], step)
plt.plot(cpu, marker='o', linestyle='-', label=piece['name'])
# 图例
plt.legend()
# 显示
plt.show()
脚本!启动
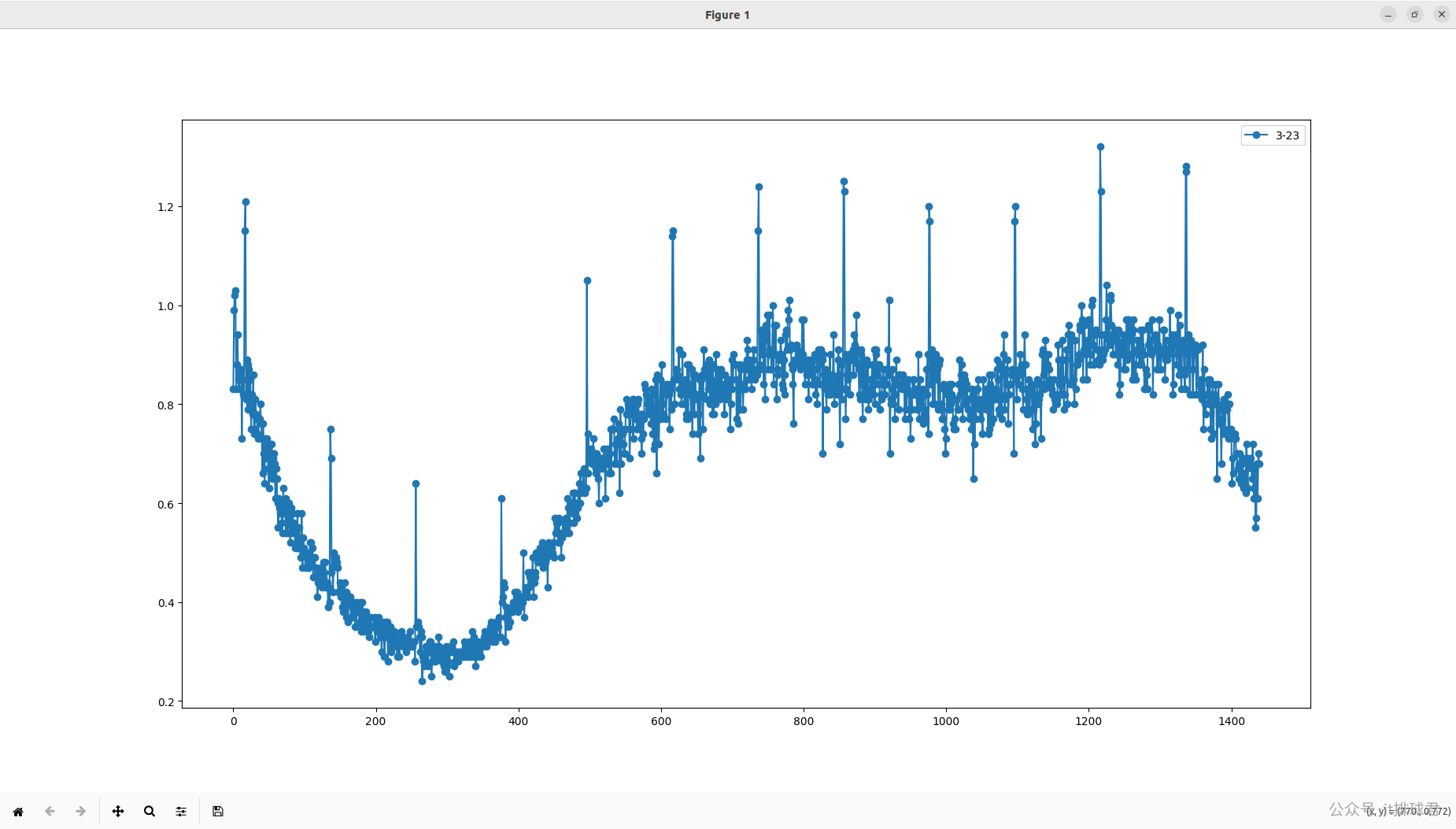
看起来数据很多,并且杂乱,并且cpu数据有个特性,会有激凸的特点,这对于数据收敛是不利的,所以,尝试把间隔时间调长一点,5分钟
step = 600
脚本!启动
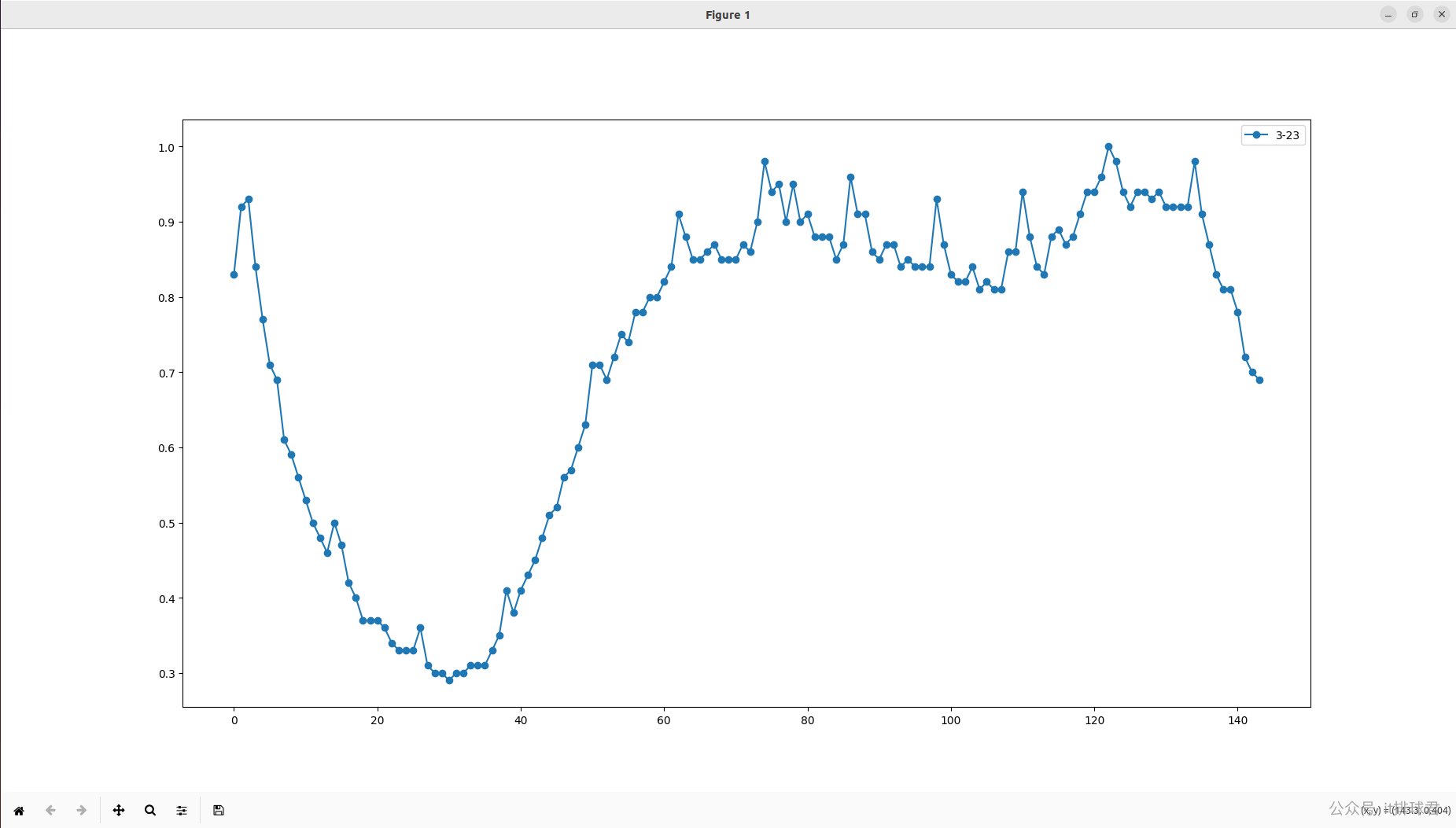
看起来数据少了很多,并且离群激凸点没有了,尝试带入到训练脚本去试一试
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from flow import get_cpu_data, get_query_data
from datetime import datetime
import pandas as pd
start_time = datetime.strptime('2025-03-23 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-03-25 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 600
sls_step = 3600*6
query = get_query_data(start_time, end_time, sls_step)
cpu = get_cpu_data(start_time, end_time, step)
print('cpu 数据个数为{} ,前10数据为{}'.format(len(cpu), cpu[:10]))
print('query 数据个数为{} ,前10数据为{}'.format(len(query), query[:10]))
# 准备数据
data = {
'cpu': cpu,
'query': query
}
df = pd.DataFrame(data)
X = df[['query']]
y = df['cpu']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=88)
# 创建模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse}, R²: {r2}")
脚本!启动

哇哦,模型提升了
- MSE来到了0.004,误差为0.063左右,大约在5%--10%之间
- R²来到了0.89,解释了将近90%的数据,模型性能极大提升
为了再次提升性能,提高模型的泛化能力,需要继续内卷,卷起来!
再次分析数据,由于有3天的数据,尝试将3天的数据对比作图,看看有什么收获
import matplotlib.pyplot as plt
from datetime import datetime
from flow import get_cpu_data
step = 600
l = [
{
'name': '3-23',
'start_time': datetime.strptime('2025-03-23 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp(),
'end_time': datetime.strptime('2025-03-23 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
},
{
'name': '3-24',
'start_time': datetime.strptime('2025-03-24 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp(),
'end_time': datetime.strptime('2025-03-24 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
},
{
'name': '3-25',
'start_time': datetime.strptime('2025-03-25 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp(),
'end_time': datetime.strptime('2025-03-25 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
}
]
# 画多条线
for piece in l:
cpu = get_cpu_data(piece['start_time'], piece['end_time'], step)
plt.plot(cpu, marker='o', linestyle='-', label=piece['name'])
# 图例
plt.legend()
# 显示
plt.show()
脚本!启动
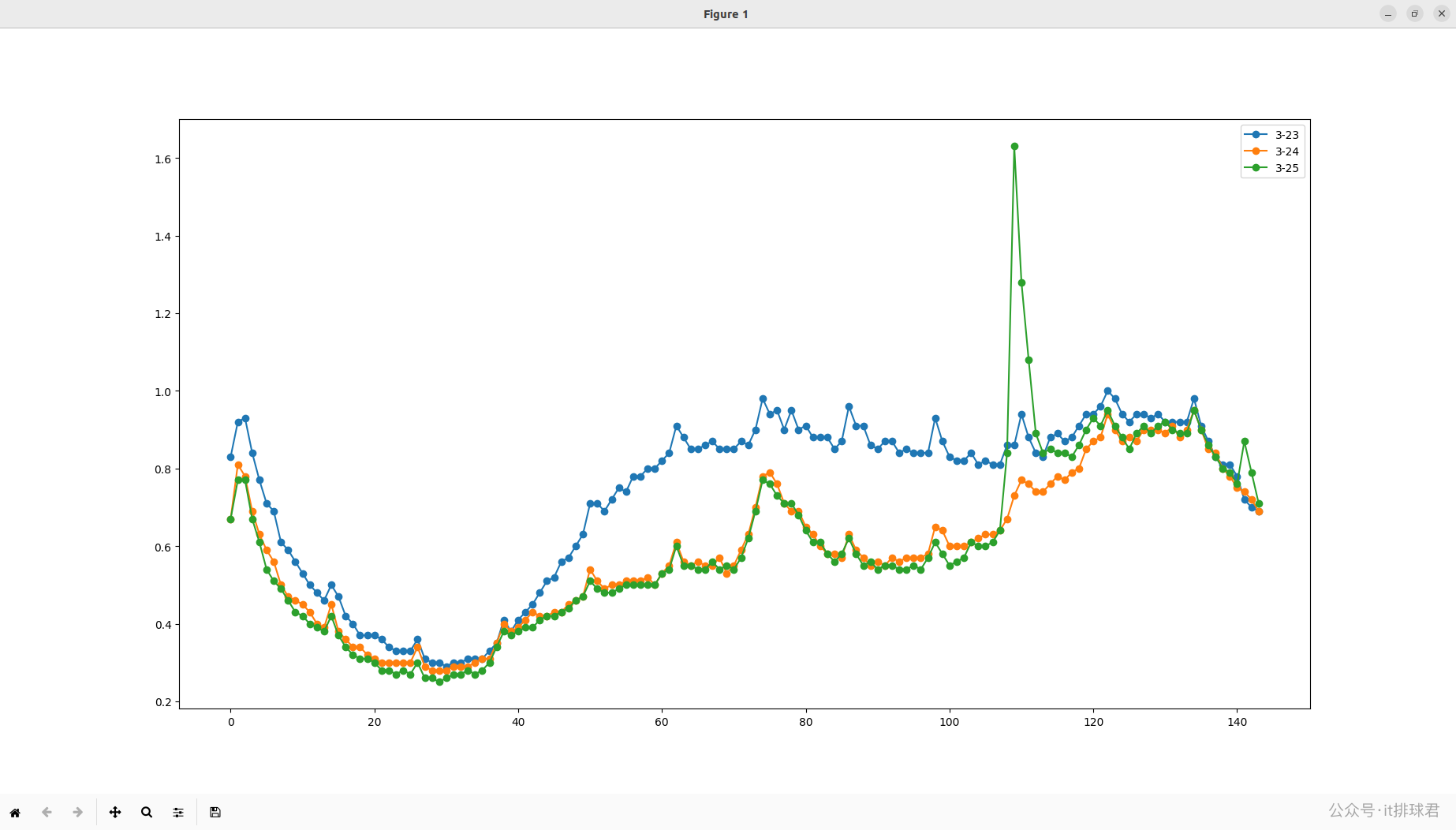
找到你了!25号的数据,你是怎么回事,怎么突然间高潮了。我去找业务的同事询问,原来那一天系统发红包,大量用户在那个时刻都去领红包去了,造成了cpu异常
哦~原来如此,那一天属于异常数据,有两种方法,第一种就是用异常检测算法将异常点全部踢掉,由于我还不会异常检测算法(比如什么均方差、箱型图、孤立森林之类的);所以我使用了第二种方法,放弃3.25的数据, =_=!
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from flow import get_cpu_data, get_query_data
from datetime import datetime
import pandas as pd
start_time = datetime.strptime('2025-03-23 00:00:00', '%Y-%m-%d %H:%M:%S').timestamp()
end_time = datetime.strptime('2025-03-24 23:59:59', '%Y-%m-%d %H:%M:%S').timestamp()
step = 600
sls_step = 3600*6
query = get_query_data(start_time, end_time, sls_step)
cpu = get_cpu_data(start_time, end_time, step)
print('cpu 数据个数为{} ,前10数据为{}'.format(len(cpu), cpu[:10]))
print('query 数据个数为{} ,前10数据为{}'.format(len(query), query[:10]))
# 准备数据
data = {
'cpu': cpu,
'query': query
}
df = pd.DataFrame(data)
X = df[['query']]
y = df['cpu']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=88)
# 创建模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse}, R²: {r2}")

真是一场酣畅淋漓的战斗
- MSE来到了0.001,误差是0.03,大约在5%以内
- R²来到了0.976,差不多98%的数据都能够被解释了
这个模型已经很优秀了,来预测一把
# 预测
predicted_query = [10000, 50000]
new_data = pd.DataFrame({
"query": [x*300 for x in predicted_query]
})
predicted_qps = model.predict(new_data)
print("预测的 qps:", predicted_query)
print("预测的 cpu:", predicted_qps)
这里要注意,query是5分钟内访问的总和,所以如果qps是1w,需要qps*300,才是5分钟的query
脚本!启动

装杯时刻
- 老板:我们的系统能够承受什么样的压力?
- 牛马:我们系统日常qps在5w左右,峰值qps在20w左右,消耗的cpu分别为42和172,按照我们4c8g的云服务器,分别需要11台和44台,现在我们使用的服务器为100台,可以缩减服务器成本大约50%
- 老板:牛批,节约下来的钱请你吃一顿麻辣烫
- 牛马:谢谢老板栽培
联系我
- 联系我,做深入的交流

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教...
彩笔运维勇闯机器学习--cpu与qps的线性关系的更多相关文章
- 运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了
线上服务CPU飙升 前言 功能开发完成仅仅是项目周期中的第一步,一个完美的项目是在运行期体现的 今天我们就来看看笔者之前遇到的一个问题CPU飙升的问题. 代码层面从功能上看没有任何问题但是投入使用后却 ...
- sql server 运维时CPU,内存,操作系统等信息查询(用sql语句)
我们只要用到数据库,一般会遇到数据库运维方面的事情,需要我们寻找原因,有很多是关乎处理器(CPU).内存(Memory).磁盘(Disk)以及操作系统的,这时我们就需要查询他们的一些设置和内容,下面讲 ...
- 运维笔记--postgresql占用CPU问题定位
运维笔记--postgresql占用CPU问题定位 场景描述: 业务系统访问变慢,登陆服务器查看系统负载并不高,然后查看占用CPU较高的进程,发现是连接数据库的几个进程占用系统资源较多. 处理方式: ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- (转)运维角度浅谈MySQL数据库优化
转自:http://lizhenliang.blog.51cto.com/7876557/1657465 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架 ...
- zookeeper运维 --【】转】
from:http://blog.csdn.net/hengyunabc/article/details/19006911 zookeeper运维 尽管zookeeper在编程上有很多的阱陷,AP ...
- 运维角度浅谈MySQL数据库优化(转)
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分 ...
- 从运维角度浅谈 MySQL 数据库优化
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分 ...
- [转载] 运维角度浅谈:MySQL数据库优化
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 作者:zhenliang8,本文转自51CTO博客,http://lizhenliang. ...
- 运维架构服务监控Open-Falcon
一. 介绍 监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题.监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择.当公司刚 ...
随机推荐
- 用curl测网速统计访问耗时
在<从基础到高级,带你结合案例深入学习curl命令>中,介绍了curl的使用方法,这里介绍一个用于统计响应耗时的最佳实践,助力老铁们合理设置网络超时时间. 下面介绍一个用于统计访问 ...
- 现代 Python 包管理器 `uv`
用 uv + Python 开发命令行工具 当使用 uv 写正规一点的 CLI 应用的时候,还是应该使用 uv init --package [package name] 因为写一个命令行程序总是要安 ...
- windows下操作kubernetes集群
一.下载二进制文件 下载windows下kubectl的客户端,这里根据我们集群的版本进行客户端版本的选择: #下载地址如下 https://storage.googleapis.com/kubern ...
- 爆肝整理!0 基础 AI 编程必拿的 3 大神器:源码一键跑 + 推广秘籍 + 私教答疑
2025年预期的 AI 应用爆发并没有到来,但是编程领域却是个特例.AI 编程工具正在引领大模型落地的浪潮,展现出明显的产品市场契合度(Product Market Fit,PMF). 那么在全面智能 ...
- 安装Docker Desktop时出现报错,WSL2 升级更新失败(退出代码: 1603,错误代码: Wsl/CallMsi/Install/ERROR_INSTALL_FAILURE)解决办法
安装Docker Desktop时出现报错,WSL2 升级更新失败 一.问题 首先遇到的问题是安装docker desktop后,启动引擎时报错 wsl update failed: update ...
- Java并发利器:CountDownLatch深度解析与实战应用
Java并发利器:CountDownLatch深度解析与实战应用 多线程编程中,让主线程等待所有子任务完成是个常见需求.CountDownLatch就像一个倒计时器,当所有任务完成后,主线程才继续执行 ...
- Unity Shader入门精要个人学习笔记
Unity Shader入门精要 渲染流水线 数学基础 1.点和矢量 类型 定义 表达 含义 性质 点(point) 点 (point) 是n 维空间(游戏中主要使用二维和三维空间)中的一个位置,它没 ...
- 2025国内五大MES系统排名探秘:从核心架构到选型指南,解锁智造升级最优解
在智能制造浪潮席卷全球的今天,MES系统(制造执行系统)作为连接企业管理层与车间生产层的"神经中枢",其重要性日益凸显.它能有效打通信息孤岛,实现生产全流程透明化.可控化与智能化, ...
- C#开发的Panel滚动分页控件(滑动版) - 开源研究系列文章
前些时候发布了一个Panel控件分页滚动控件的源码( https://www.cnblogs.com/lzhdim/p/18866367 ),不过那个的页面切换的时候是直接切换控件的高度或水平度的,体 ...
- Layui 更新Table 表格内容的值
$.ajax({ //请求方式 type: "POST", //请求地址 url: "/", //数据,json字符串 data: { }, //请求成功 su ...