用python做时间序列预测四:*稳/非*稳时间序列
上篇文章简单提到了应该用*稳时间序列做预测,本文将介绍具体概念和原因。
Stationary Series *稳序列
*稳序列有三个基本标准:
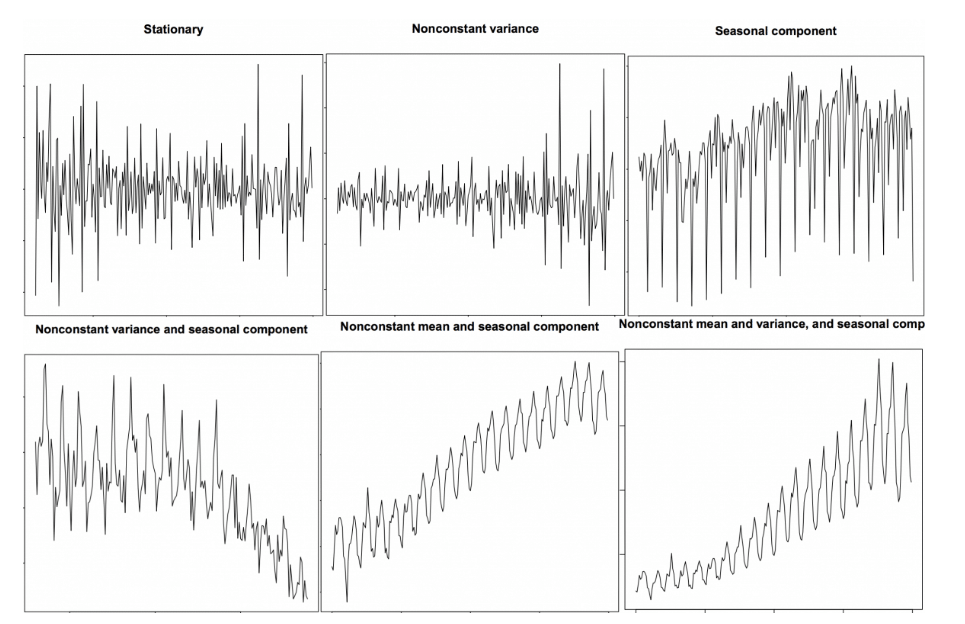
1、序列的均值(mean)不应该是时间的函数(意思是不应该随时间变化),而应该是一个常数。下面的左图满足这个条件,而右图的均值受时间的变化影响。
2、序列的方差(variance)不应该是时间的函数。这种特性称为homoscedasticity(同方差性)。下图描绘了*稳序列和非*稳序列,注意右图分布的不同变化范围。
3、t时间段的序列和前一个时间段的序列的协方差(协方差,衡量的是两个变量在一段时间内同向变化的程度)应该只和时间间隔有关,而与时间t无关,在时间序列中,因为是同一个变量在不同时间段的值序列,所以这里的协方差称为自协方差。右图随着时间的增加,有一段变得越来越紧密了。所以右图的序列的协方差不是常数。
带有趋势和季节性成分的时间序列都是非*稳的,下图给出了更多的区分*稳性的例子:
为什么要关注序列的*稳性?
大多数的统计预测方法都是以*稳时间序列为假设前提来设计的。
比如,对于时间序列自回归预测来说,我们的假设是变量的历史和现状呈现出的基本特性,在未来阶段的一个长时期里会维持不变,而这里的基本特性一般就是用上面提到的均值、方差、自协方差来表示。
更具体的说,自回归预测模型本质是'利用序列的滞后阶数(lags)作为自变量'的线性回归模型,比如lags=2表示使用变量的t-1和t-2时刻的值作为自变量来预测t时刻的值。那么通过在历史序列上训练模型后,得到的这个线性回归模型的各自变量的系数就代表了各滞后时刻的值与下一时刻值的相关性,如果时间序列接**稳,这些相关性在未来一段时间内都不会有大的变化,那么预测未来就成为了可能。
所以,相对非*稳序列的预测,*稳序列的预测更简单和可靠。
非*稳序列如何做预测?
对于非*稳时间序列的预测,我们需要先将其转换为*稳时间序列,方法包括:
- 差分(一阶或n阶)
- 取log
- 开根号
- 时间序列分解
- 综合使用上面的方法
一般来说,做个一阶差分,就可以得到接**稳的时间序列了,如果方差随时间变化较大,那么先取log再做一阶差分就可以了。
什么是差分?
比如有一个序列:[1,5,2,12,20]
一阶差分,得到:[5-1, 2-5, 12-2, 20-12] = [4, -3, 10, 8]
二阶差分(即在一阶差分之后,再做一次差分),得到:[-3-4, -10-3, 8-10] = [-7, -13, -2]
如何测试序列的*稳性?
对于判断时间序列是否*稳,可以通过肉眼观测时间序列图,就类似上面提到的*稳性的3个基本标准,或者
将时间序列分成多个连续的部分,计算各部分的均值、方差和自相关性(或协方差),如果结果相差很大,那么序列就不*稳。但是这些方法都不能量化*稳性,也就是用一个数值来表示出时间序列的*稳性。为此,我们可以使用‘Unit Root Tests’即单位根检验,该方法的思想是如果时间序列有单位根,则就是非*稳的。
以下是常用的两个基于单位根检验思想的实现:
- Augmented Dickey Fuller test (ADF Test)
零假设为序列有单位根,是非*稳的,P-Value如果小于显著级别(0.05),则可以拒绝零假设。- Kwiatkowski-Phillips-Schmidt-Shin – KPSS test (trend stationary)
与ADF正好相反,零假设为序列是*稳的。另外,在python中,可以通过指定regression='ct'参数来让kps把“确定性趋势(deterministic trend)”的序列认为是*稳的。所谓确定性趋势的序列就是斜率始终保持不变的序列,比如下面这样的:
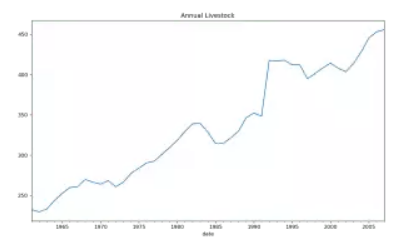
下面是对应的python代码:
from statsmodels.tsa.stattools import adfuller, kpss
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv', parse_dates=['date'])
# ADF Test
result = adfuller(df.value.values, autolag='AIC')
print(f'ADF Statistic: {result[0]}')
print(f'p-value: {result[1]}')
for key, value in result[4].items():
print('Critial Values:')
print(f' {key}, {value}')
# KPSS Test
result = kpss(df.value.values, regression='c')
print('\nKPSS Statistic: %f' % result[0])
print('p-value: %f' % result[1])
for key, value in result[3].items():
print('Critial Values:')
print(f' {key}, {value}')
输出:
ADF Statistic: 3.14518568930674
p-value: 1.0
Critial Values:
1%, -3.465620397124192
Critial Values:
5%, -2.8770397560752436
Critial Values:
10%, -2.5750324547306476
KPSS Statistic: 1.313675
p-value: 0.010000
Critial Values:
10%, 0.347
Critial Values:
5%, 0.463
Critial Values:
2.5%, 0.574
Critial Values:
1%, 0.739
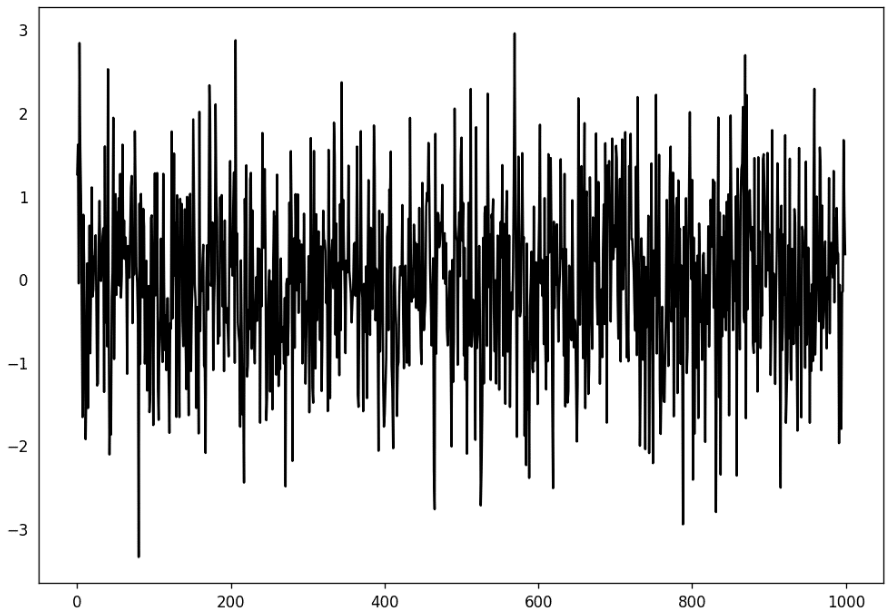
白噪声和*稳序列的区别
白噪声的遵循均值为0的随机分布,没有丝毫的模式可言。用python制造一个白噪声序列,并可视化如下:
randvals = np.random.randn(1000)
pd.Series(randvals).plot(title='Random White Noise', color='k')
去除趋势
- 减去最佳拟合线
- 减去均值线,或者移动*均线
- 减去/除以 利用时间序列分解出的趋势序列
去除季节性
- 季节性窗口内的移动*均法,*滑季节性
- 季节性差分,就是用当前值减去一个季节窗口之前对应的时刻的值
- 减去/除以 利用时间序列分解出的季节性序列
如何判断序列是否有季节性?
- 通过肉眼看图
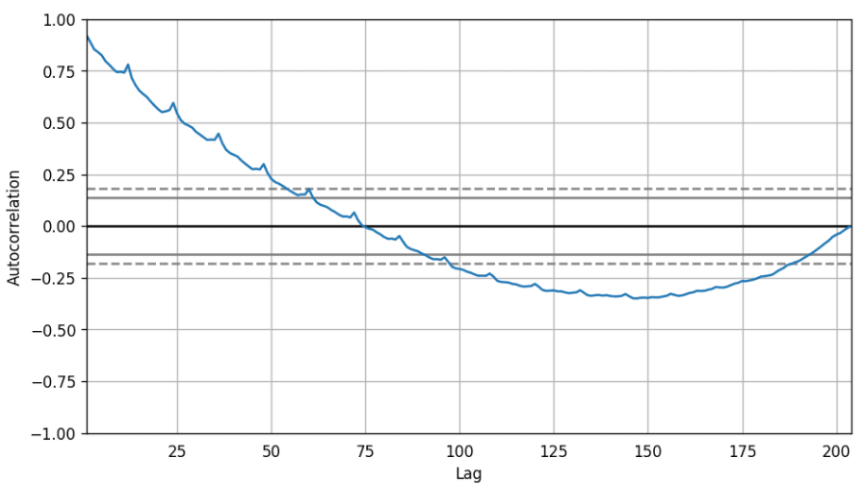
- 通过自相关函数判断
from pandas.plotting import autocorrelation_plot
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv')
# Draw Plot
plt.rcParams.update({'figure.figsize':(9,5), 'figure.dpi':120})
autocorrelation_plot(df.value.tolist())
- 通过时间序列分解出的季节性序列来计算,其思想是越没有季节性,那么Rt的方差和Rt+St的方差越应该区别不大,反之,这个方差的比值越应该小于1,公式如下:
Fs越接*0,越没有季节性,越接*1,季节性越强。
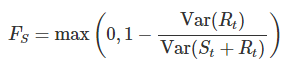
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
用python做时间序列预测四:*稳/非*稳时间序列的更多相关文章
- python做中学(四)main函数的用法
什么场景下会有main函数? 当该python脚本被作为模块(module)引入(import)时,其中的main()函数将不会被执行. main函数的作用? __name__ == '__main_ ...
- 用python做时间序列预测一:初识概念
利用时间序列预测方法,我们可以基于历史的情况来预测未来的情况.比如共享单车每日租车数,食堂每日就餐人数等等,都是基于各自历史的情况来预测的. 什么是时间序列? 时间序列,是指同一个变量在连续且固定的时 ...
- TensorFlow实现时间序列预测
常常会碰到各种各样时间序列预测问题,如商场人流量的预测.商品价格的预测.股价的预测,等等.TensorFlow新引入了一个TensorFlow Time Series库(以下简称为TFTS),它可以帮 ...
- 用python做时间序列预测九:ARIMA模型简介
本篇介绍时间序列预测常用的ARIMA模型,通过了解本篇内容,将可以使用ARIMA预测一个时间序列. 什么是ARIMA? ARIMA是'Auto Regressive Integrated Moving ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- python做量化交易干货分享
http://www.newsmth.NET/nForum/#!article/Python/128763 最近程序化交易很热,量化也是我很感兴趣的一块. 国内量化交易的平台有几家,我个人比较喜欢用的 ...
- 腾讯技术工程 | 基于Prophet的时间序列预测
预测未来永远是一件让人兴奋而又神奇的事.为此,人们研究了许多时间序列预测模型.然而,大部分的时间序列模型都因为预测的问题过于复杂而效果不理想.这是因为时间序列预测不光需要大量的统计知识,更重要的是它需 ...
- 时间序列算法(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)的模型以及需要的概念基础学习笔记梳理
在做很多与时间序列有关的预测时,比如股票预测,餐厅菜品销量预测时常常会用到时间序列算法,之前在学习这方面的知识时发现这方面的知识讲解不多,所以自己对时间序列算法中的常用概念和模型进行梳理总结(但是为了 ...
- facebook开源的prophet时间序列预测工具---识别多种周期性、趋势性(线性,logistic)、节假日效应,以及部分异常值
简单使用 代码如下 这是官网的quickstart的内容,csv文件也可以下到,这个入门以后后面调试加入其它参数就很简单了. import pandas as pd import numpy as n ...
随机推荐
- 从零开始学java(第一天)
上班日学习时间很短,而且很多事情会耽搁,就会写的比较少 近几期的笔记以复习为主,后面会逐渐拓展对我个人来说的新知识 1. 复习了一下typore的语法,方便以后记笔记用 # MarkDown学习(# ...
- 关于com组件的方法,以AE的IFieldsEdit为例
今天,有小伙伴问我,为什么在调用IFieldsEdit接口时,VS无法自动显示出AddFiled方法,而这个方法是确实存在的 在此,做下解答,因为这个方法被隐藏了.TypeLibFunc属性,被用来指 ...
- Qt在linux下实现程序编译后版本号自增的脚本
#! /bin/bash rm -rf temp.cpp num=0 while read line do if [ $num -eq 3 ];then array=(`echo $line | tr ...
- Electron 窗体 BrowserWindow
http://jsrun.net/t/KfkKp https://www.wenjiangs.com/doc/tlsizw1dst https://www.w3cschool.cn/electronm ...
- django目录结构、app概念和三板斧的初步介绍
目录 一.django app(应用)的概念 概念 命令行创建应用 pycharm创建应用 创建应用注意事项 二.django主要目录结构 三.django小白必会三板斧 一.django app(应 ...
- opencv+Linux源码编译安装及引用
(一)下载 opencv下载地址:https://opencv.org/releases/ opencv_contrib下载地址:https://github.com/opencv/opencv_co ...
- 【Java高级编程】IO流学习笔记
目录 IO流 File类 文件/文件夹基础操作 创建文件的完整步骤 IO流 - 节点流 读入文件一个字节(一个字节) [FileInputStream]字节数组的方式读取(读取全部内容) [FileI ...
- MySQL百万级数据量分页查询方法及其优化
1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from product limit start, count 当起始页较小时,查询没有性能问题, ...
- #渗透测试 kioptix level 2靶机通关教程及提权
声明! 文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关,切勿触碰法律底线,否则后果自负!!!! 工具链接:https://pan.quark.cn/s/530656ba55 ...
- 一句话,我让 AI 帮我做了个 P 图网站!
每到过节,不少小伙伴都会给自己的头像 P 个图,加点儿装饰. 比如圣诞节给自己头上 P 个圣诞帽,国庆节 P 个小红旗等等.这是一类比较简单.需求量却很大的 P 图场景,也有很多现成的网站和小程序,能 ...