Update(Stage5):DMP项目_业务介绍_框架搭建
DMP (Data Management Platform)
整个课程的内容大致分为如下两个部分
业务介绍
技术实现
对于业务介绍, 比较困难的是理解广告交易过程中各个参与者是干什么的
对于技术实现, 大致就是如下两个步骤
报表
标签化
报表显而易见, 就是查看数据的组成, 查看数据的图形直观特征
标签化是整个项目的目的, 最终其实就要根据标签筛选用户, 但是对于标签化还是有很多东西要做的, 如下
商圈库
打标签
统一用户识别
标签合并 & 衰减
历史合并
1. 项目介绍
背景介绍
DMP的作用和实现方式技术方案
1.1. 广告业务背景
互联网管广告发展至今, 产生了很多非常复杂的概念, 其中环环交错, 不容易理清, 这一章节的主要目的就是尽可能的理清楚整体上的流程, 各个环节的作用
Step 1: 广告主, 广告商, 媒体-

广告主
简单来说就是要发广告的机构和个人
广告商
广告商是中介, 对接广告主和媒体, 广告主告诉广告商我要发广告, 广告商找到媒体进行谈判
媒体
比如说微博, 腾讯, 美团这样的应用和网站, 就是媒体, 它们具有广告展示的位置, 用户在使用这些服务的同时会看到各样的广告
受众
普通的用户, 在享受免费的服务的同时, 被动的接受广告
但是受众是有不同类型的, 可以由标签来表示, 比如说白领, 女性,
20 - 30岁等
Step 2: 小媒体和广告网络-
刚才的结构中有一个非常明显的问题
小媒体有很多
不只有微博腾讯这些媒体, 还有很多其它的垂直小媒体, 比如说一些软件网站, 一些小型的App, 甚至前阵子比较流行的游戏消灭病毒等, 都是小型的媒体
广告主倾向于让更多人看到广告
广告主就倾向于让更多人看到广告, 而且也为了避免麻烦, 所以会找一些大型的媒体来谈合作
但是往往一些小媒体因为更加垂直, 其用户可能更加的精准, 购买意愿也非常好
小媒体的议价能力非常有限
虽然小媒体有小媒体的好处, 但是小媒体太过零散, 如果只是一个小媒体的话, 很难去洽谈出一个比较好的合作
所以小媒体也是要赚钱的, 这个领域其实是一个很大的盘子, 一定会有人为小媒体提供服务, 这种产品, 我们称之为
AdNetwork, 广告网络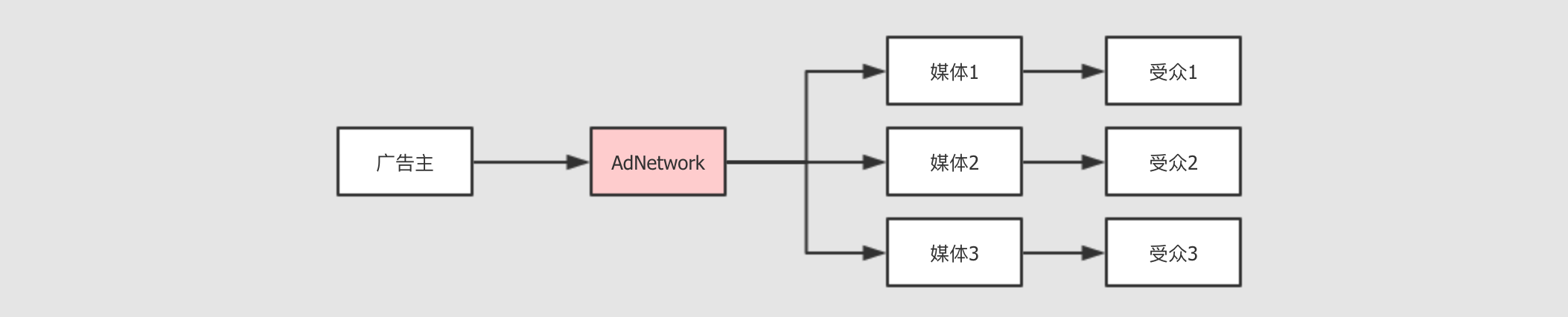
AdNetwork提供如下的服务为广告主提供统一的界面
联络多家媒体, 行成为统一的定价从而销售
Step 3:AdExchange-
虽然有
AdNetwork的引入, 但是很快又会有新的问题AdNetwork不止一家就如同会有很多小媒体, 广告主不知道如何选择一样,
AdNetwork是一种商业模式, 也会有很多玩家, 广告主依然面临这种选择困难小媒体们会选择不同的
AdNetwork每个
AdNetwork之间, 定价策略可能不同, 旗下的小媒体也可能不同, 其实最终广告主是要选择一个靠谱的网站来进行广告展示的, 那么这里就存在一些信息不对称, 如何选择靠谱的AdNetwork从而选择靠谱的媒体呢AdNetwork之间可能存在拆借现象某一个
AdNetwork可能会有一个比较好的资源, 但是一直没卖出去, 而另外一个AdNetwork可能恰好需要用到这个资源, 所以AdNetwork之间可能会有一些拆借显现, 这就让这个市场愈加混乱媒体可能对
AdNetwork的定价策略颇有微词AdNetwork背后有很多媒体, 但是整个定价策略是由AdNetwork来制定的, 虽然AdNetwork往往是非常精密的计算模型, 但是媒体依然可能会感觉自己没有赚到钱
所以滋生了另外一种业务, 叫做
AdExchange, 广告交易平台, 从而试图去从上层再统一一下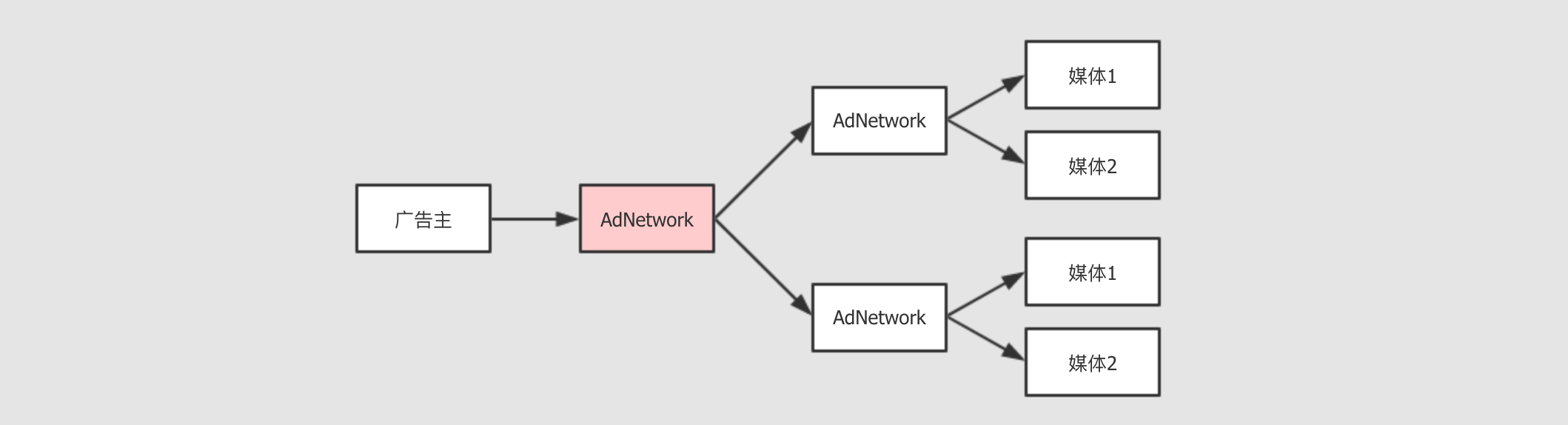
所以,
AdExchange虽然看起来和AdNetwork非常类似, 但是本质上是不同的, 其有以下特点AdExchange不仅会联系AdNetwork, 也会联系一下小媒体甚至有时候
AdNetwork也会找AdExchange发布广告需求AdExchange会提供实时的交易定价, 弥补了AdNetwork独立定价的弊端
Step 4:RTB实时竞价-
本节并不是针对
AdExchange的缺陷引入新的话题, 而是针对AdExchange中的一个定价特点进行详细的说明AdExchange和AdNetwork最大的不同可能要数AdExchange的定价方式了,AdExchange的定价方式是一种事实的定价方式, 其实非常类似于股票的撮合交易
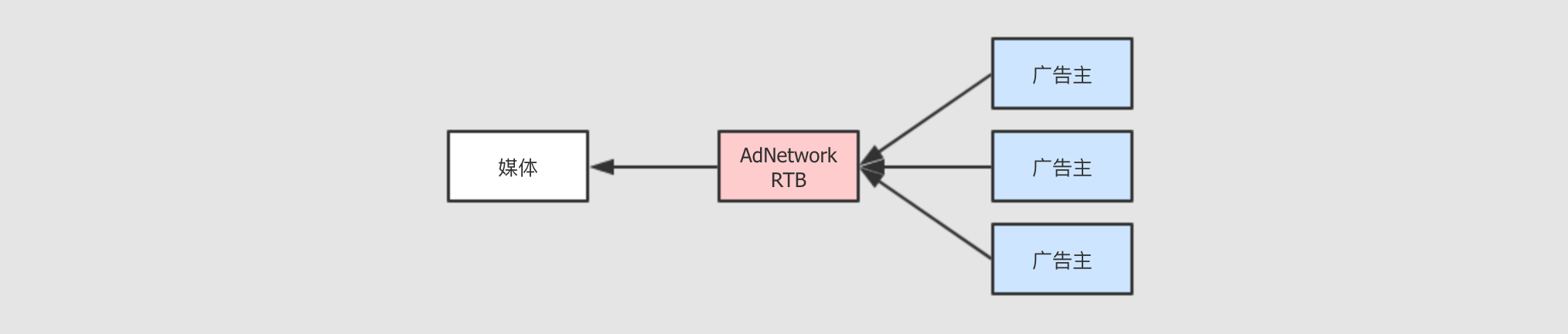
整个过程的步骤大致如下:
媒体发起广告请求给
RTB系统, 请求广告进行展示
广告主根据自己需求决定是否竞价, 以及自己的出价

会有多个广告主同时出价, 价高者得
这样,
RTB就能尽可能的让广告的展示价格更透明更公平,AdExchange得到自己响应的佣金, 媒体得到最大化的广告费, 看起来皆大欢喜, 但是真的是这样吗? Step 5: 广告主如何竞价?-
一切看起来都很好, 如果你站在媒体角度的话, 但是如果你站在广告主的角度上来看, 广告主可能会有两种抱怨
广告主并不是专业从业者
广告主可能会觉得, 你跟我闹呢, 我知道不知道怎么出价你心里每一点数?
确实, 作为金主, 不能太过为难他们, 每次交易都让广告主出价, 无异于逼迫广告主转投他家
广告主的诉求是投放广告给恰好有需求的人, 而不是看起来好像很酷的媒体
我们讨论到现在, 所有的假设都是基于广告主知道自己该找什么样的媒体投放什么样的广告, 这种假设明显是不成立的, 如果考虑广告主的诉求, 其非常简单, 在同等价格内, 广告效果要好, 所以广告主更关心的事情是你是否让合适的人看到了这些广告
所以,
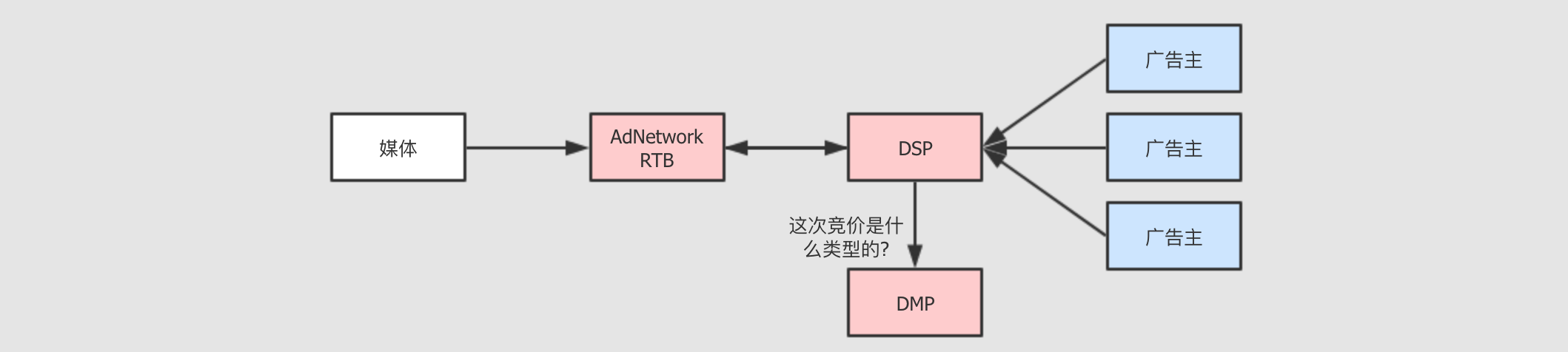
DSP应运而生,DSP全称叫做需求方平台, 主要负责和AdExchange交互, 辅助广告主进行实时竞价
DSP帮助广告主进行RTB中的出价DSP不仅只是出价,DSP帮助广告主全面的进行广告服务, 例如广告主只需要告诉DSP自己对什么类型的受众感兴趣,DSP会帮助广告主进行受众筛选
Step 6:DMP-
DSP最重要的特性是, 能够帮助广告主筛选客户, 换句话说,DSP出现之前广告主针对媒体上的广告位进行广告投放,DSP出现之后, 广告主针对自己想要的目标受众投放广告, 这几乎是一个质的效率提升广告主现在可以针对一些受众的标签来进行广告投放了, 比如说, 一个广告主是卖化妆品的, 他要投放广告给有如下三个标签的用户们,
20岁上下, 女性, 时尚人士, 现在就可以针对这三个标签来告诉DSP如何筛选用户了但是
DSP如何进行用户识别呢?DSP如何知道谁是20岁上下, 女性, 时尚人士?DSP可以自己做, 也可以依赖于第三方. 这个标签化的数据管理项目, 就叫做DMP, 全称叫做Data Management Platform, 即数据管理平台.DMP 所负责的内容非常重要的有两点
收集用户数据
常见的收集方式主要有两种
通过自身的服务和程序进行收集, 例如微博和腾讯有巨大的用户量, 他们自己就可以针对自己的用户进行分析
通过合作而来的一些数据, 这部分在合规范围内, 一般大型的网站或者
App会通过一些不会泄漏用户隐私的ID来标识用户, 给第三方DMP合作使用通过一些不正当的手段获得, 例如说在某网站上传伪装成图片的脚本, 从而获取本网站的用户
Cookie, 这部分涉及一些黑产, 不再详细说明,315晚会也曾经报道过
为用户打上标签
DSP主要通过标签筛选用户, 所以DMP要通过一些大数据的工具来将用户数据打上标签, 这部分其实挺难, 有可能要涉及一些机器学习的算法, 或者图计算
Ps.整个链条中的参与者-
1.2. 技术方案
DMP的主要任务技术方案
- 技术方案
-
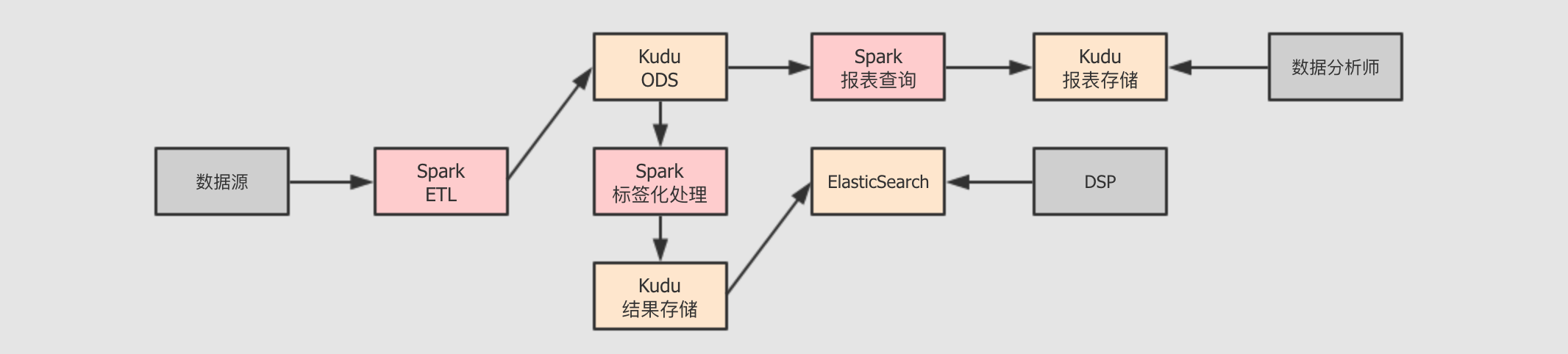
- 从目的上看,
DMP系统可能会有如下的事情要做 -
通过可视化和笔记工具进行数据分析和测试
一般会使用
Zeppelin等工具进行测试和数据探索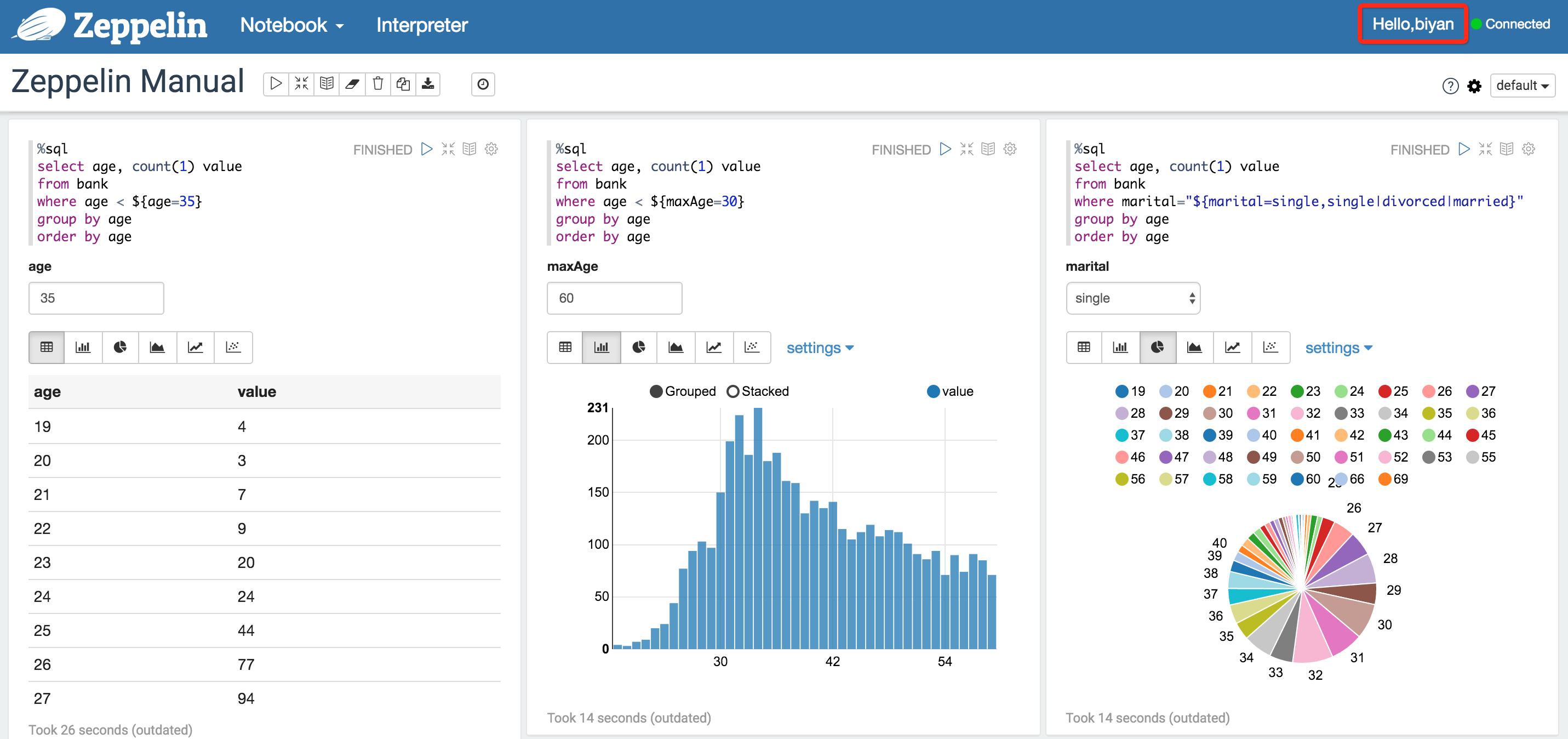
向
DSP提供数据服务一般对外提供数据, 是以接口的形式提供的, 例如提供一个
Http GET接口给DSP,DSP可以调用这个接口实现查询接口一般使用
Spring之类的框架编写Http服务实现这种接口在访问数据库的时候, 就是
OLTP形式了, 要尽快的获取数据,Kudu和HBase较为合适
通过可视化内部展示运营数据
在运营过程中, 产品方可能需要时刻监控运营的一些指标, 例如注册率, 使用率, 接口调用次数等
- 从工程的视角上来看,
DMP的工程分为如下几个部分 -
工程 类型 作用 dmpIDEA ProjectDMP项目的主工程, 编写具体的代码dmp_reportZeppelin NotebookZeppeline的一个笔记, 负责展示DMP进行数据探索和分析时所产生的报表dmp_analysisZeppelin NotebookZeppeline的一个笔记, 负责进行DMP数据的探索, 从中不断试探发现经验 - 真实开发的时候可能遵循如下步骤
-
序号 环境 存储 对应工程 描述 1测试
Kudu测试dmp_analysis先对数据进行探索, 得出规律
2测试
Kudu测试dmp_report归纳数据特征和规律, 通过报表展示
3生产
Kudu生产IDEA dmp project对数据充分理解后, 编写代码进行
ETL操作, 并使用Oozie等工具进行调度执行, 处理过的数据落地到Kudu表中4生产
Kudu生产IDEA dmp project生产中的数据已经经过清洗, 此时可以编写代码进行标签库等一系列的数据分析和挖掘任务, 并将结果落地到
ElasticSearch中, 向DSP提供服务5生产
Kudu生产IDEA dmp project在运营过程中, 会产生一些运营指标, 可以针对运营指标进行数据分析和可视化, 提供给产品部分追踪运营状况. 此步骤应该通过
EChats等工具在后台系统中进行可视化, 使用SQL来分析数据
数据会不断的来, 所以数据的清洗和
ETL过程是不断重复进行的ETL会不断的产生新的洁净数据, 所以标签库也是不断重复进行的运营不断继续,
ETL也不断继续, 所以报表也要周期性提供根据任务的情况和目的不同, 这个周期有可能是
1天,12小时,1个月等
- 从目的上看,
DMP的主要任务-
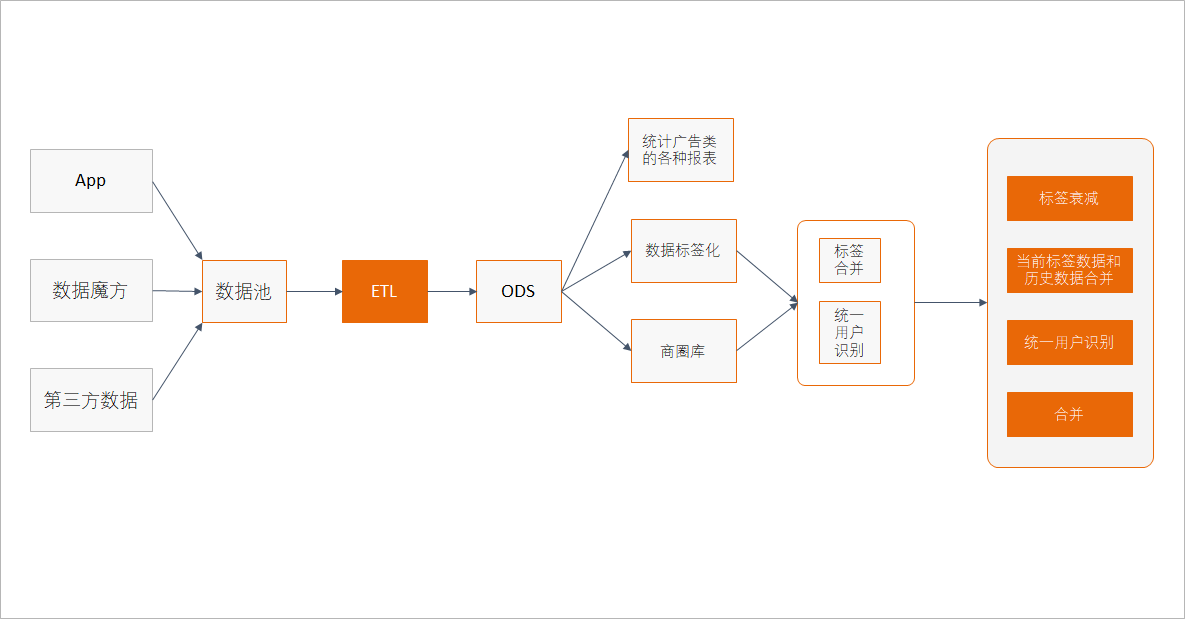
在我们这个学习项目中, 大家只需要了解围绕这个 DMP 有什么样的项目, 以及整体的过程和团队需要做的事情, 但是我们还是要把主要目标放在核心业务上, 我们在整个项目中将学习到如下一些内容
报表生成
标签化以及标签化相关的一系列处理
- 数据集生成
-
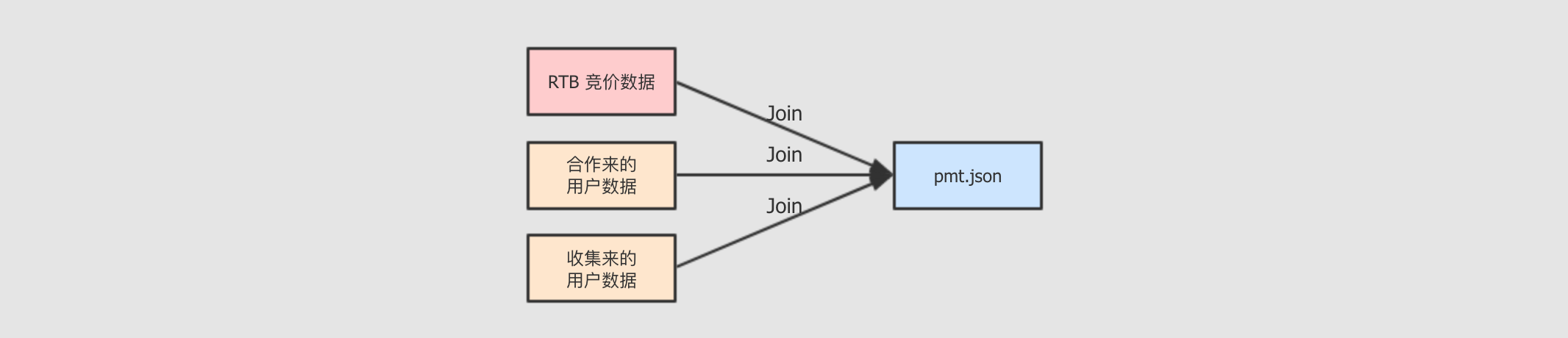
这份数据集生成的步骤有如下
收集数据
数据来自于以往的竞价记录和收集到的用户数据
竞价记录来自于以往的交易
用户数据有可能来自第三方, 也有可能是自己收集(可能性比较小)
合并多个数据源的数据
因为在进行针对 DMP 的数据分析时, 需要用到用户的数据来判定用户的喜好, 也需要竞价数据来判定价格是否合适, 所以需要将这两部分数据合并起来, 再进行数据处理和分析
- 数据集概况
-
数据集是一个 JSON Line 文件, 其中有三千条数据, 每一条数据都是一个独立的 JSON 字符串, 大概长如下样子
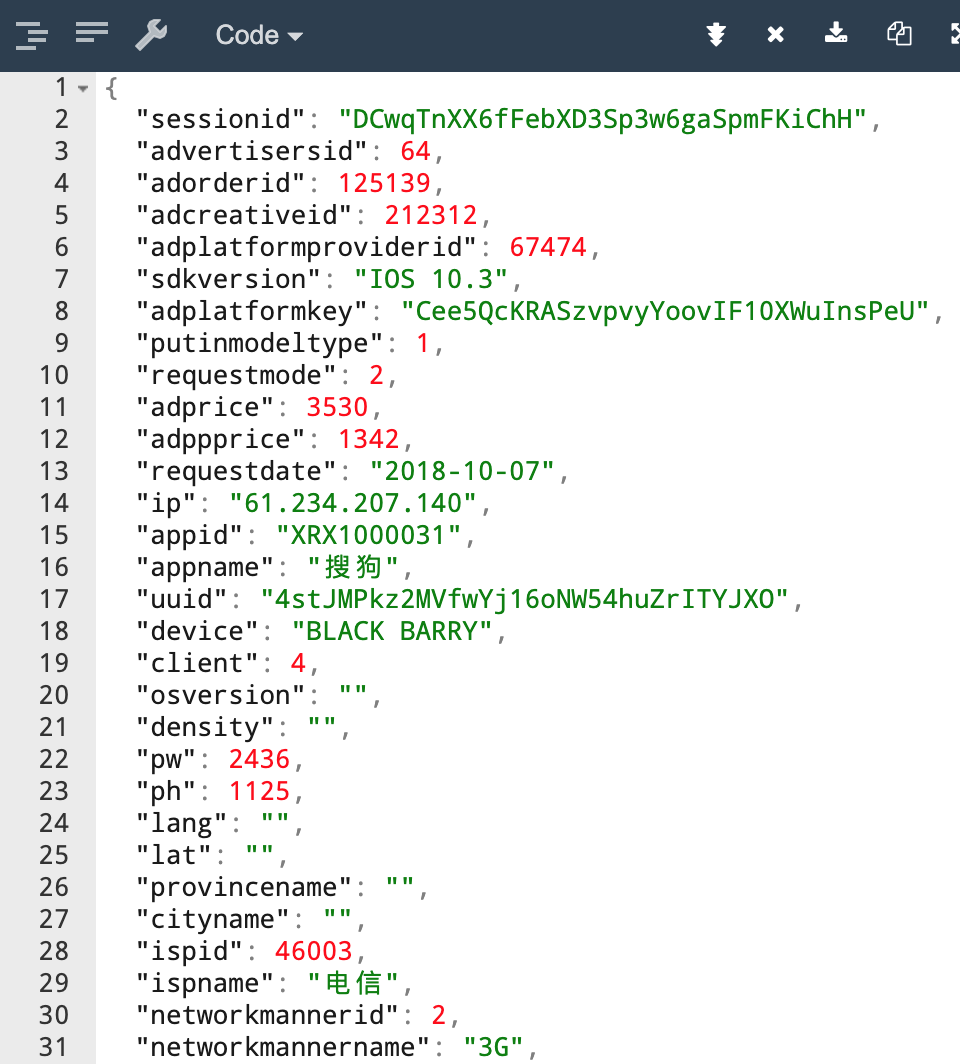
字段 解释 IP设备的真实
IPsessionid会话标识
advertisersid广告主
IDadorderid广告
IDadcreativeid广告创意
ID>= 200000:DSP< 200000:OSS
adplatformproviderid广告平台商
ID>= 100000:rtb< 100000:api
sdkversionnumberSDK版本号adplatformkey平台商
Keyputinmodeltype针对广告主的投放模式
1: 展示量投放2: 点击量投放
requestmode数据请求方式
1: 请求2: 展示3: 点击
adprice广告价格
adppprice平台商价格
requestdate请求时间, 格式为
yyyy-m-dd hh:mm:ssappid应用
IDappname应用名称
uuid设备唯一标识, 比如
IMEI或者AndroidID等device设备型号, 如
Huawei,iPhoneclient设备类型
1:Android2:iOS3:WP
osversion设备操作系统版本, 如
4.0density备屏幕的密度
Android的取值为0.75,1,1.5iOS的取值为1,2
pw设备屏幕宽度
ph设备屏幕高度
longitude设备所在经度
lat设备所在纬度
provincename设备所在省份名称
cityname设备所在城市名称
ispid运营商
IDispname运营商名称
networkmannerid联网方式
ID4G3G2GOperatorOther
networkmannername联网方式名称
iseffective是否可以正常计费
0: 不行1: 可以
isbilling是否收费
0: 未收费1: 已收费
adspacetype广告位类型
1:Banner2: 插屏3: 全屏
adspacetypename广告位类型名称, 如
Banner, 插屏, 全屏devicetype设备类型(1:手机 2:平板)
1: 手机2: 平板
processnode流程节点
1: 请求量KPI2: 有效请求3: 广告请求
apptype应用类型
IDdistrict设备所在县名称
paymode针对平台商的支付模式
1: 展示量投放, CPM2: 点击量投放, CPC
isbid是否是
RTBbidpriceRTB竞价价格winpriceRTB竞价成功价格iswin是否竞价成功
cur结算币种,
USD,RMB等rate汇率
cnywinpriceRTB竞价成功转换成人民币的价格imei手机串码
mac手机
MAC地址idfa手机
APP的广告码openudid苹果设备的识别码
androidid安卓设备的识别码
rtbprovinceRTB省rtbcityRTB市rtbdistrictRTB区rtbstreetRTB街道storeurlAPP的市场下载地址realip真实
IPisqualityapp优选标识
bidfloor底价
aw广告位的宽
ah广告位的高
imeimd5IMEI的MD5值macmd5MAC的MD5值idfamd5IDFA的MD5值openudidmd5OpenUDID的MD5值androididmd5AndroidID的MD5值imeisha1IMEI的SHA-1值macsha1MAC的SHA-1值idfasha1IDFA的SHA-1值openudidsha1OpenUDID的SHA-1值androididsha1AndroidID的SHA-1值uuidunknowUUID的密文userid平台用户
IDiptype表示
IP库类型1: 为点媒IP库2: 为广告协会的IP地理信息标准库
默认为1
initbidprice初始出价
adpayment转换后的广告消费 (保留小数点后
6位)agentrate代理商利润率
lomarkrate代理利润率
adxrate媒介利润率
title标题
keywords关键字
tagid广告位标识 (当视频流量时值为视频
ID号)callbackdate回调时间, 格式为
yyyy/MM/dd hh:mm:sschannelid频道
IDmediatype媒体类型
email用户邮箱
tel用户电话号码
sex用户性别
age用户年龄
2. 工程创建和框架搭建
创建工程
搭建框架
建立配置框架
Step 1: 创建工程-
- 已经到最后一个阶段了, 不再详细说工程如何创建了, 看一下步骤即可
-
在
IDEA创建Maven工程, 选择存储位置工程命名为
dmp, 注意工程名一般小写, 大家也可以采用自己喜欢的命名方式, 在公司里, 要采用公司的习惯导入
Maven依赖创建
Scala代码目录创建对应的包们
- 创建需要的包
-
包名 描述 com.itheima.dmp.etl放置数据转换任务
com.itheima.dmp.report放置报表任务
com.itheima.dmp.tags放置标签有关的任务
com.itheima.dmp.utils放置一些通用公用的类
- 导入需要的依赖
-
在
DMP中, 暂时先不提供完整的Maven POM文件, 在一开始只导入必备的, 随着项目的进程, 用到什么再导入什么, 以下是必备的Spark全家桶Kudu一套Scala依赖SLF4J日志依赖Junit单元测试Java编译插件Scala编译插件Uber Jar编译插件ShadeCDH Repo仓库, 需要一个CDH的Maven仓库配置是因为用到CDH版本的Kudu
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<hadoopo.version>2.6.1</hadoopo.version>
<kudu.version>1.7.0-cdh5.16.0</kudu.version>
<maven.version>3.5.1</maven.version>
<junit.version>4.12</junit.version>
</properties> <dependencies>
<!-- Spark -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoopo.version}</version>
</dependency> <!-- Kudu client -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.7.0-cdh5.16.1</version>
</dependency> <!-- Kudu Spark -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>1.7.0-cdh5.16.1</version>
</dependency> <!-- Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency> <!-- Unit testing -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>provided</scope>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory> <plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.version}</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> <repositories>
<repository>
<id>cdh.repo</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
Step 2: 框架搭建-
编写
Spark程序的时候, 往往不需要一个非常复杂的框架, 只是对一些基础内容的抽象和封装即可, 但是也要考虑如下问题有哪些任务是要执行的
在做一个项目的时候, 尽量从全局的角度去看, 要考虑到周边的一些环境, 例如说回答自己如下几个问题
问题 初步分析和解答 这个应用有几个入口
这个程序的入口数量是不确定的, 随着工作的进展而变化, 但是至少要有两个入口, 一个是生成报表数据, 一个是处理用户的标签数据
这个应用会放在什么地方执行
分为测试和生产, 测试可以直接使用 IDEA 执行, 生成需要打包并发送到集群执行
这个应用如何调度
这个应用包含了不止一个任务, 最终会由
Oozie,Azkaban,AirFlow等工具去调度执行有哪些操作可能会导致重复代码过多
其实无论是
Spring, 还是Vue, 还是Spark, 这些框架和工具, 最终的目的都是帮助我们消除一些重复的和通用的代码所以既然我们无需在 Spark 的应用中搭建复杂的项目框架, 但是对于重复的代码还是要消除的, 初步来看可能会有如下重复的代码点
各个数据库的访问
配置的读取
Step 3: 建立配置读取工具-
了解配置文件和读取框架
数据读取部分, 有一个比较好用的工具, 叫做
lightbend/config, 它可以读取一种叫做HOCON的配置文件HOCON全称叫做Human-Optimized Config Object Notation, 翻译过来叫做 为人类优化的配置对象表示法HOCON是一种类似于Properties的配置文件格式, 并包含JSON的语法格式, 比较易于使用, 其大致格式如下foo: {
bar: 10,
baz: 12
} foo {
bar = 10,
baz = 12
} foo.bar=10
foo.baz=10以上三种写法是等价的, 其解析结果都是两个字段, 分别叫做
foo.bar和foo.baz读取
HOCON文件格式需要使用lightbend/config, 它的使用非常的简单当配置文件被命名为
application.conf并且被放置于resources时, 可以使用如下方式直接加载val config: Config = ConfigFactory.load()
val bar = config.getInt("foo.bar")
val baz = config.getInt("foo.baz")
创建配置文件
创建配置文件
resource/spark.conf, 并引入如下内容# Worker 心跳超时时间
spark.worker.timeout="500" # RPC 请求等待结果的超时时间
spark.rpc.askTimeout="600s" # 所有网络操作的等待时间, spark.rpc.askTimeout 默认值等同于这个参数
spark.network.timeoout="600s" # 最大使用的 CPU 核心数
spark.cores.max="10" # 任务最大允许失败次数
spark.task.maxFailures="5" # 如果开启推测执行, 开启会尽可能的增快任务执行效率, 但是会占用额外的运算资源
spark.speculation="true" # Driver 是否允许多个 Context
spark.driver.allowMutilpleContext="true" # Spark 序列化的方式, 使用 Kryo 能提升序列化和反序列化的性能
spark.serializer="org.apache.spark.serializer.KryoSerializer" # 每个页缓存, Page 指的是操作系统的内存分配策略中的 Page, 一个 Page 代表一组连续的内存空间
# Spark 在引入钨丝计划以后, 使用 Java 的 Unsafe API 直接申请内存, 其申请单位就是 Page
# 如果 Page 过大, 有可能因为操作系统的策略无法分配而拒绝这次内存申请, 从而报错
# 简单来说, 这个配置的作用是一次申请的内存大小
spark.buffer.pageSize="6m"以上的配置列成表如下
配置项目 描述 spark.worker.timeout如果超过了这个配置项指定的时间,
Master认为Worker已经跪了spark.network.timeout因为
Spark管理一整个集群, 任务可能运行在不同的节点上, 后通过网络进行通信, 一次网络通信有可能因为要访问的节点实效而一直等待, 这个配置项所配置的便是这个等待的超时时间spark.cores.maxSpark整个应用最大能够申请的CPU核心数spark.task.maxFailuresSpark本身是支持弹性容错的, 所以不能因为某一个Task失败了, 就认定整个Job失败, 一般会因为相当一部分Task失败了才会认定Job失败, 否则会进行重新调度, 这个参数的含义是, 当多少个Task失败了, 可以认定Job失败spark.speculation类似
Hadoop,Spark也支持推测执行, 场景是有可能因为某台机器的负载过高, 或者其它原因, 导致这台机器运行能力很差,Spark会根据一些策略检测较慢的任务, 去启动备用任务执行, 使用执行较快的任务的结果, 但是推测执行有个弊端, 就是有可能一个任务会执行多份, 浪费集群资源spark.driver.allowMutilpleContext很少有机会必须一定要在一个
Spark Application中启动多个Context, 所以这个配置项意义不大, 当必须要使用多个Context的时候, 开启此配置即可spark.serializerSpark将任务分发到集群中执行, 所以势必涉及序列化, 这个配置项配置的是使用什么序列化器, 默认是JDK的序列化器, 可以指定为Kyro从而提升性能, 但是如果使用Kyro的话需要序列化的类需要被先注册才能使用spark.buffer.pageSize每个页缓存,
Page指的是操作系统的内存分配策略中的Page, 一个Page代表一组连续的内存空间,Spark在引入钨丝计划以后, 使用Java的Unsafe API直接申请内存, 其申请单位就是Page, 如果Page过大, 有可能因为操作系统的策略无法分配而拒绝这次内存申请, 从而报错, 简单来说, 这个配置的作用是一次申请的内存大小, 一般在报错的时候修改这个配置, 减少一次申请的内存导入配置读取的工具依赖
在
pom.xml中的properties段增加如下内容<config.version>1.3.4</config.version>在
pom.xml中的dependencites段增加如下内容<!-- Config reader -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>${config.version}</version>
</dependency>
配置工具的设计思路
- 在设计一个工具的时候, 第一步永远是明确需求, 我们现在为
SparkSession的创建设置配置加载工具, 其需求如下 -
配置在配置文件中编写
使用
typesafe/config加载配置文件在创建
SparkSession的时候填写这些配置
- 前两点无需多说, 已经自表达, 其难点也就在于如何在
SparkSession创建的时候填入配置, 大致思考的话, 有如下几种方式 -
加载配置文件后, 逐个将配置的项设置给
SparkSessionspark.config("spark.worker.timeout", config.get("spark.worker.timeout"))加载配置文件后, 通过隐式转换为
SparkSession设置配置spark.loadConfig().getOrCreate()
毫无疑问, 第二种方式更为方便
- 在设计一个工具的时候, 第一步永远是明确需求, 我们现在为
创建配置工具类
- 看代码之前, 先了解一下设计目标
-
加载配置文件
spark.conf无论配置文件中有多少配置都全部加载
为
SparkSession提供隐式转换自动装载配置
- 下面是代码, 以及重点解读
-
class SparkConfigHelper(builder: SparkSession.Builder) { private val config: Config = ConfigFactory.load("spark") def loadConfig(): SparkSession.Builder = {
import scala.collection.JavaConverters._ for (entry <- config.entrySet().asScala) {
val value = entry.getValue
val valueType = value.valueType()
val valueFrom = value.origin().filename()
if (valueType == ConfigValueType.STRING && valueFrom != null) {
builder.config(entry.getKey, value.unwrapped().asInstanceOf[String])
}
} builder
}
} object SparkConfigHelper { def apply(builder: SparkSession.Builder): SparkConfigHelper = {
new SparkConfigHelper(builder)
} implicit def setSparkSession(builder: SparkSession.Builder) = {
SparkConfigHelper(builder)
}
}: 加载配置文件 : 因为 Config工具会自动的加载所有的系统变量, 需要通过Origin来源判断, 只接收来自于文件的配置: 判断: 1. 是 String类型, 2. 来自于某个配置文件: 为 SparkSession设置参数: 提供伴生对象的意义在于两点: 1. 更方便的创建配置类, 2. 提供隐式转换, 3. 以后可能需要获取某个配置项 : 提供隐式转换, 将 SparkSession转为ConfigHelper对象, 从而提供配置加载
3. 将数据集中的 IP 转为地域信息
IP转换工具介绍转换
IP转换工具介绍-
- 进行
IP转换这种操作, 一般有如下一些办法 -
方式 描述 优点 缺点 自己编写
一般如果自己编写查找算法的话, 大致有如下几步
找到一个
IP范围 : 省 : 市 : 区这样的数据集读取数据集
将
IP转为数字表示法, 本质上IP就是二进制的点位表示法,192.168.0.1 → 1100 0000 1010 1000 0000 0000 0000 0001 → 3232235521使用
3232235521这样的数字在IP数据集中通过二分法查找对应的省市区
没有第三方库的学习成本
没有数据结构上的支持, 效率低
没有上层的封装, 使用麻烦
第三方库
一般第三方库会有一些数据结构上的优化, 查找速度比二分法会更快一些, 例如
BTree就特别适合做索引, 常见的方式有GeoLite纯真数据库
ip2region
速度快
不麻烦
有上层封装, 用着爽
第三方一般会提供数据集, 数据集会定时更新, 更精准
有轮子就别自己搞了, 怪麻烦的
需要学习第三方工具, 有一定的学习成本, 而且不一定和以后工作中用同样一个工具
- 选用
ip2region这个工具来查找省市名称 -
ip2region的优点工具 数据结构支持 中文支持 GeoLite有
无
纯真
无
有
ip2region有
有
引入
ip2region复制
IP数据集ip2region.db到工程下的dataset目录在
Maven中增加如下代码<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
ip2region的使用val searcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
val data = searcher.btreeSearch(ip)
println(data.getRegion)
- 选用
GeoLite确定经纬度 -
后面需要使用经纬度, 只有
GeoLite可以查找经纬度工具 数据结构支持 中文支持 经纬度支持 GeoLite有
无
有
纯真
无
有
无
ip2region有
有
无
引入
GeoLite将
GeoLite的数据集GeoLiteCity.dat拷贝到工程中dataset目录下在
pom.xml中添加如下依赖<dependency>
<groupId>com.maxmind.geoip</groupId>
<artifactId>geoip-api</artifactId>
<version>1.3.0</version>
</dependency> <dependency>
<groupId>com.maxmind.geoip2</groupId>
<artifactId>geoip2</artifactId>
<version>2.12.0</version>
</dependency>
GeoLite的使用方式val lookupService = new LookupService("dataset/GeoLiteCity.dat", LookupService.GEOIP_MEMORY_CACHE)
val location = lookupService.getLocation("121.76.98.134")
println(location.latitude, location.longitude)
- 进行
IP转换思路梳理-
现在使用不同的视角, 理解一下在这个环节我们需要做的事情
- 工具视角
-

- 数据视角
-

- 要做的事
-
读取数据集
pmt.json将
IP转换为省市设计
Kudu表结构, 创建Kudu表存入
Kudu表
- 挑战和结构
-
现在的任务本质上是把一个
数据集 A转为数据集 B,数据集 A可能不够好,数据集 B相对较好, 然后把数据集 B落地到Kudu, 作为ODS层, 以供其它功能使用但是如果
数据集 A转为数据集 B的过程中需要多种转换呢?
所以, 从面向对象的角度上来说, 需要一套机制, 能够组织不同的功能协同运行
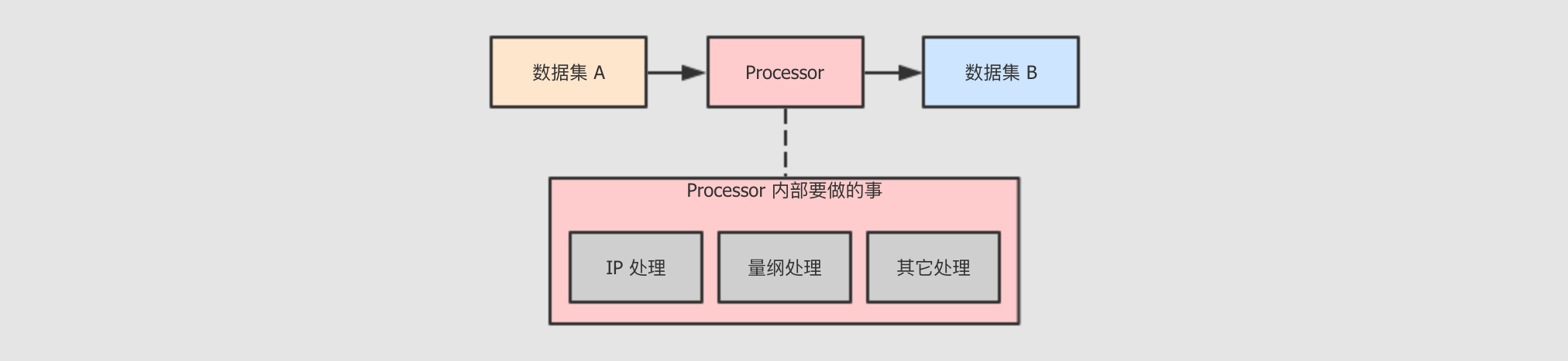
所以我们可以使用一个名为
PmtETLProcessor的类代表针对数据集 A到数据集 B的转换, 然后抽象出单位更小的负责具体某一个转换步骤的节点, 集成到PmtETLProcessor中, 共同完成任务
- 参数配置
-
为了让程序行为更可控制, 所以一般会在编写程序之前先大致计划以下程序中可能使用到的一些参数
Kudu的表名Kudu表的复制因子ODS层的表名
规划好以后, 着手创建配置文件
resource/kudu.conf# Server properties
kudu.common.master="192.168.169.101:7051,192.168.169.102:7051,192.168.169.103:7051"
kudu.common.factor=1 # Table name
kudu.name.pmt_ods="ODS_"
Kudu的支持库-
- 为了方便
Kudu的使用, 所以要创建一个Kudu的Helper, 大致需求如下 -
需求 原始调用方式 理想调用方式 创建表
KuduContext.createTable()SparkSession.createKuduTable()通过
DataFrame将数据保存到Kudu表DataFrame.write.options(…).kuduDataFrame.saveAsKuduTable KuduHelper的设计-
KuduHelper的设计思路两句话可以总结尽可能的不在处理类中读取配置文件
尽可能的提供易于调用的接口
class KuduHelper {
private var spark: SparkSession = _
private var dataset: Dataset[Any] = _ def this(spark: SparkSession) = {
this()
this.spark = spark
} def this(dataset: Dataset[Any]) = {
this(dataset.sparkSession)
this.dataset = dataset
} private val config = ConfigFactory.load("kudu")
private val KUDU_MASTERS = config.getString("kudu.common.master")
private val kuduContext = new KuduContext(KUDU_MASTERS, spark.sparkContext) def createKuduTable(tableName: String, schema: Schema): Unit = {
if (kuduContext.tableExists(tableName)) {
kuduContext.deleteTable(tableName)
} import scala.collection.JavaConverters._
val options = new CreateTableOptions()
.setNumReplicas(config.getInt("kudu.common.factor"))
.addHashPartitions(List("uuid").asJava, 6) kuduContext.createTable(tableName, schema, options)
} def saveToKudu(tableName: String): Unit = {
import org.apache.kudu.spark.kudu._ dataset.write
.option("kudu.table", tableName)
.option("kudu.master", KUDU_MASTERS)
.mode(SaveMode.Append)
.kudu
} } object KuduHelper { implicit def sparkToKuduContext(spark: SparkSession): Unit = {
new KuduHelper(spark)
} implicit def datasetToKuduContext(dataset: Dataset[Any]): Unit = {
new KuduHelper(dataset)
} def formattedDate(): String = {
FastDateFormat.getInstance("yyyyMMdd").format(new Date)
}
}: 主题设计思路就是将 SparkSession或者DataFrame隐式转换为KuduHelper, 在KuduHelper中提供帮助方法: 将 SparkSession转为KuduHelper时调用: 将 Dataset转为KuduHelper时调用: 在 Helper内部读取配置文件, 创建KuduContext: 此方法就是设计目标 SparkSession.createKuduTable(tableName)中被调用的方法: 此方法就是设计目标 DataFrame.saveToKudu(tableName)中被调用的方法: 将 SparkSession转为KuduHelper: 将 Dataset转为KuduHelper: 提供一个统一的生成日期的方法, 给外部使用
- 为了方便
ETL代码编写-
创建
PmtETLProcessor类PmtETLProcessor类负责整个ETL过程, 但是不复杂中间过程中具体的数据处理, 具体数据如何转换, 要做什么事情由具体的某个Converter类负责object PmtETLProcessor { def main(args: Array[String]): Unit = {
import com.itheima.dmp.utils.SparkConfigHelper._
import com.itheima.dmp.utils.KuduHelper._ // 创建 SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("pmt_etl")
.loadConfig()
.getOrCreate() import spark.implicits._ // 读取数据
val originDataset = spark.read.json("dataset/pmt.json") }
}创建
IPConverter类处理IP转换的问题IPConverter主要解决如下问题原始数据集中有一个
ip列, 要把ip这一列数据转为五列, 分别是ip,Longitude,latitude,region,city, 从而扩充省市信息和经纬度信息将新创建的四列数据添加到原数据集中
object IPConverter { def process(dataset: Dataset[Row]): Dataset[Row] = {
val dataConverted: RDD[Row] = dataset
.rdd
.mapPartitions(convertIPtoLocation) val schema = dataset.schema
.add("region", StringType)
.add("city", StringType)
.add("longitude", DoubleType)
.add("latitude", DoubleType) val completeDataFrame = dataset
.sparkSession
.createDataFrame(dataConverted, schema) completeDataFrame
} def convertIPtoLocation(iterator: Iterator[Row]): Iterator[Row] = {
val searcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db") val lookupService = new LookupService(
"dataset/GeoLiteCity.dat",
LookupService.GEOIP_MEMORY_CACHE) iterator.map(row => {
val ip = row.getAs[String]("ip") val regionData = searcher.btreeSearch(ip).getRegion.split("\\|")
val region = regionData(2)
val city = regionData(3) val location = lookupService.getLocation(ip)
val longitude = location.longitude.toDouble
val latitude = location.latitude.toDouble val rowSeq = row.toSeq :+ region :+ city :+ longitude :+ latitude
Row.fromSeq(rowSeq)
})
}
}: 通过 mapPartitions算子, 对每一个分区数据调用convertIPtoLocation进行转换, 需要注意的是, 这个地方已经被转为RDD了, 而不是DataFrame, 因为DataFrame在转换中不能更改Schema: convertIPtoLocation主要做的事情是扩充原来的row, 增加四个新的列: 获取省市中文名 : 获取经纬度 : 根据原始 row生成新的row, 新的row中包含了省市和经纬度信息: 新的 row对象的RDD结合 被扩充过的Schema, 合并生成新的DataFrame返回给Processor在
PmtETLProcessor中调用IPConverterobject PmtETLProcessor { def main(args: Array[String]): Unit = {
... val originDataset = spark.read.json("dataset/pmt.json") // 调用 IPConverter, 传入 originDataset, 生成包含经纬度和省市的 DataFrame
val ipConvertedResult = IPConverter.process(originDataset) // 要 Select 的列们, 用于组织要包含的结果集中的数据
// 因为太多, 不再此处展示, 若要查看, 请移步代码工程
val selectRows: Seq[Column] = Seq(...) // 选中相应的列
ipConvertedResult.select(selectRows:_*).show()
}通过以上的代码, 已经在数据集中扩展了地理位置相关的信息, 接下来可以存入
Kudu了
DMP (Data Management Platform)
整个课程的内容大致分为如下两个部分
业务介绍
技术实现
对于业务介绍, 比较困难的是理解广告交易过程中各个参与者是干什么的
对于技术实现, 大致就是如下两个步骤
报表
标签化
报表显而易见, 就是查看数据的组成, 查看数据的图形直观特征
标签化是整个项目的目的, 最终其实就要根据标签筛选用户, 但是对于标签化还是有很多东西要做的, 如下
商圈库
打标签
统一用户识别
标签合并 & 衰减
历史合并
1. 项目介绍
背景介绍
DMP的作用和实现方式技术方案
1.1. 广告业务背景
互联网管广告发展至今, 产生了很多非常复杂的概念, 其中环环交错, 不容易理清, 这一章节的主要目的就是尽可能的理清楚整体上的流程, 各个环节的作用
Step 1: 广告主, 广告商, 媒体-
广告主
简单来说就是要发广告的机构和个人
广告商
广告商是中介, 对接广告主和媒体, 广告主告诉广告商我要发广告, 广告商找到媒体进行谈判
媒体
比如说微博, 腾讯, 美团这样的应用和网站, 就是媒体, 它们具有广告展示的位置, 用户在使用这些服务的同时会看到各样的广告
受众
普通的用户, 在享受免费的服务的同时, 被动的接受广告
但是受众是有不同类型的, 可以由标签来表示, 比如说白领, 女性,
20 - 30岁等
Step 2: 小媒体和广告网络-
刚才的结构中有一个非常明显的问题
小媒体有很多
不只有微博腾讯这些媒体, 还有很多其它的垂直小媒体, 比如说一些软件网站, 一些小型的App, 甚至前阵子比较流行的游戏消灭病毒等, 都是小型的媒体
广告主倾向于让更多人看到广告
广告主就倾向于让更多人看到广告, 而且也为了避免麻烦, 所以会找一些大型的媒体来谈合作
但是往往一些小媒体因为更加垂直, 其用户可能更加的精准, 购买意愿也非常好
小媒体的议价能力非常有限
虽然小媒体有小媒体的好处, 但是小媒体太过零散, 如果只是一个小媒体的话, 很难去洽谈出一个比较好的合作
所以小媒体也是要赚钱的, 这个领域其实是一个很大的盘子, 一定会有人为小媒体提供服务, 这种产品, 我们称之为
AdNetwork, 广告网络AdNetwork提供如下的服务为广告主提供统一的界面
联络多家媒体, 行成为统一的定价从而销售
Step 3:AdExchange-
虽然有
AdNetwork的引入, 但是很快又会有新的问题AdNetwork不止一家就如同会有很多小媒体, 广告主不知道如何选择一样,
AdNetwork是一种商业模式, 也会有很多玩家, 广告主依然面临这种选择困难小媒体们会选择不同的
AdNetwork每个
AdNetwork之间, 定价策略可能不同, 旗下的小媒体也可能不同, 其实最终广告主是要选择一个靠谱的网站来进行广告展示的, 那么这里就存在一些信息不对称, 如何选择靠谱的AdNetwork从而选择靠谱的媒体呢AdNetwork之间可能存在拆借现象某一个
AdNetwork可能会有一个比较好的资源, 但是一直没卖出去, 而另外一个AdNetwork可能恰好需要用到这个资源, 所以AdNetwork之间可能会有一些拆借显现, 这就让这个市场愈加混乱媒体可能对
AdNetwork的定价策略颇有微词AdNetwork背后有很多媒体, 但是整个定价策略是由AdNetwork来制定的, 虽然AdNetwork往往是非常精密的计算模型, 但是媒体依然可能会感觉自己没有赚到钱
所以滋生了另外一种业务, 叫做
AdExchange, 广告交易平台, 从而试图去从上层再统一一下所以,
AdExchange虽然看起来和AdNetwork非常类似, 但是本质上是不同的, 其有以下特点AdExchange不仅会联系AdNetwork, 也会联系一下小媒体甚至有时候
AdNetwork也会找AdExchange发布广告需求AdExchange会提供实时的交易定价, 弥补了AdNetwork独立定价的弊端
Step 4:RTB实时竞价-
本节并不是针对
AdExchange的缺陷引入新的话题, 而是针对AdExchange中的一个定价特点进行详细的说明AdExchange和AdNetwork最大的不同可能要数AdExchange的定价方式了,AdExchange的定价方式是一种事实的定价方式, 其实非常类似于股票的撮合交易整个过程的步骤大致如下:
媒体发起广告请求给
RTB系统, 请求广告进行展示广告主根据自己需求决定是否竞价, 以及自己的出价
会有多个广告主同时出价, 价高者得
这样,
RTB就能尽可能的让广告的展示价格更透明更公平,AdExchange得到自己相应的佣金, 媒体得到最大化的广告费, 看起来皆大欢喜, 但是真的是这样吗? Step 5: 广告主如何竞价?-
一切看起来都很好, 如果你站在媒体角度的话, 但是如果你站在广告主的角度上来看, 广告主可能会有两种抱怨
广告主并不是专业从业者
广告主可能会觉得, 你跟我闹呢, 我知道不知道怎么出价你心里没一点数?
确实, 作为金主, 不能太过为难他们, 每次交易都让广告主出价, 无异于逼迫广告主转投他家
广告主的诉求是投放广告给恰好有需求的人, 而不是看起来好像很酷的媒体
我们讨论到现在, 所有的假设都是基于广告主知道自己该找什么样的媒体投放什么样的广告, 这种假设明显是不成立的, 如果考虑广告主的诉求, 其非常简单, 在同等价格内, 广告效果要好, 所以广告主更关心的事情是你是否让合适的人看到了这些广告
所以,
DSP应运而生,DSP全称叫做需求方平台, 主要负责和AdExchange交互, 辅助广告主进行实时竞价DSP帮助广告主进行RTB中的出价DSP不仅只是出价,DSP帮助广告主全面的进行广告服务, 例如广告主只需要告诉DSP自己对什么类型的受众感兴趣,DSP会帮助广告主进行受众筛选
Step 6:DMP-
DSP最重要的特性是, 能够帮助广告主筛选客户, 换句话说,DSP出现之前广告主针对媒体上的广告位进行广告投放,DSP出现之后, 广告主针对自己想要的目标受众投放广告, 这几乎是一个质的效率提升广告主现在可以针对一些受众的标签来进行广告投放了, 比如说, 一个广告主是卖化妆品的, 他要投放广告给有如下三个标签的用户们,
20岁上下, 女性, 时尚人士, 现在就可以针对这三个标签来告诉DSP如何筛选用户了但是
DSP如何进行用户识别呢?DSP如何知道谁是20岁上下, 女性, 时尚人士?DSP可以自己做, 也可以依赖于第三方. 这个标签化的数据管理项目, 就叫做DMP, 全称叫做Data Management Platform, 即数据管理平台.DMP 所负责的内容非常重要的有两点
收集用户数据
常见的收集方式主要有两种
通过自身的服务和程序进行收集, 例如微博和腾讯有巨大的用户量, 他们自己就可以针对自己的用户进行分析
通过合作而来的一些数据, 这部分在合规范围内, 一般大型的网站或者
App会通过一些不会泄漏用户隐私的ID来标识用户, 给第三方DMP合作使用通过一些不正当的手段获得, 例如说在某网站上传伪装成图片的脚本, 从而获取本网站的用户
Cookie, 这部分涉及一些黑产, 不再详细说明,315晚会也曾经报道过
为用户打上标签
DSP主要通过标签筛选用户, 所以DMP要通过一些大数据的工具来将用户数据打上标签, 这部分其实挺难, 有可能要涉及一些机器学习的算法, 或者图计算
Ps.整个链条中的参与者-
1.2. 技术方案
DMP的主要任务技术方案
- 技术方案
-
- 从目的上看,
DMP系统可能会有如下的事情要做 -
通过可视化和笔记工具进行数据分析和测试
一般会使用
Zeppelin等工具进行测试和数据探索向
DSP提供数据服务一般对外提供数据, 是以接口的形式提供的, 例如提供一个
Http GET接口给DSP,DSP可以调用这个接口实现查询接口一般使用
Spring之类的框架编写Http服务实现这种接口在访问数据库的时候, 就是
OLTP形式了, 要尽快的获取数据,Kudu和HBase较为合适
通过可视化内部展示运营数据
在运营过程中, 产品方可能需要时刻监控运营的一些指标, 例如注册率, 使用率, 接口调用次数等
- 从工程的视角上来看,
DMP的工程分为如下几个部分 -
工程 类型 作用 dmpIDEA ProjectDMP项目的主工程, 编写具体的代码dmp_reportZeppelin NotebookZeppeline的一个笔记, 负责展示DMP进行数据探索和分析时所产生的报表dmp_analysisZeppelin NotebookZeppeline的一个笔记, 负责进行DMP数据的探索, 从中不断试探发现经验 - 真实开发的时候可能遵循如下步骤
-
序号 环境 存储 对应工程 描述 1测试
Kudu测试dmp_analysis先对数据进行探索, 得出规律
2测试
Kudu测试dmp_report归纳数据特征和规律, 通过报表展示
3生产
Kudu生产IDEA dmp project对数据充分理解后, 编写代码进行
ETL操作, 并使用Oozie等工具进行调度执行, 处理过的数据落地到Kudu表中4生产
Kudu生产IDEA dmp project生产中的数据已经经过清洗, 此时可以编写代码进行标签库等一系列的数据分析和挖掘任务, 并将结果落地到
ElasticSearch中, 向DSP提供服务5生产
Kudu生产IDEA dmp project在运营过程中, 会产生一些运营指标, 可以针对运营指标进行数据分析和可视化, 提供给产品部分追踪运营状况. 此步骤应该通过
EChats等工具在后台系统中进行可视化, 使用SQL来分析数据
数据会不断的来, 所以数据的清洗和
ETL过程是不断重复进行的ETL会不断的产生新的洁净数据, 所以标签库也是不断重复进行的运营不断继续,
ETL也不断继续, 所以报表也要周期性提供根据任务的情况和目的不同, 这个周期有可能是
1天,12小时,1个月等
- 从目的上看,
DMP的主要任务-
在我们这个学习项目中, 大家只需要了解围绕这个 DMP 有什么样的项目, 以及整体的过程和团队需要做的事情, 但是我们还是要把主要目标放在核心业务上, 我们在整个项目中将学习到如下一些内容
报表生成
标签化以及标签化相关的一系列处理
- 数据集生成
-
这份数据集生成的步骤有如下
收集数据
数据来自于以往的竞价记录和收集到的用户数据
竞价记录来自于以往的交易
用户数据有可能来自第三方, 也有可能是自己收集(可能性比较小)
合并多个数据源的数据
因为在进行针对 DMP 的数据分析时, 需要用到用户的数据来判定用户的喜好, 也需要竞价数据来判定价格是否合适, 所以需要将这两部分数据合并起来, 再进行数据处理和分析
- 数据集概况
-
数据集是一个 JSON Line 文件, 其中有三千条数据, 每一条数据都是一个独立的 JSON 字符串, 大概长如下样子
字段 解释 IP设备的真实
IPsessionid会话标识
advertisersid广告主
IDadorderid广告
IDadcreativeid广告创意
ID>= 200000:DSP< 200000:OSS
adplatformproviderid广告平台商
ID>= 100000:rtb< 100000:api
sdkversionnumberSDK版本号adplatformkey平台商
Keyputinmodeltype针对广告主的投放模式
1: 展示量投放2: 点击量投放
requestmode数据请求方式
1: 请求2: 展示3: 点击
adprice广告价格
adppprice平台商价格
requestdate请求时间, 格式为
yyyy-m-dd hh:mm:ssappid应用
IDappname应用名称
uuid设备唯一标识, 比如
IMEI或者AndroidID等device设备型号, 如
Huawei,iPhoneclient设备类型
1:Android2:iOS3:WP
osversion设备操作系统版本, 如
4.0density备屏幕的密度
Android的取值为0.75,1,1.5iOS的取值为1,2
pw设备屏幕宽度
ph设备屏幕高度
longitude设备所在经度
lat设备所在纬度
provincename设备所在省份名称
cityname设备所在城市名称
ispid运营商
IDispname运营商名称
networkmannerid联网方式
ID4G3G2GOperatorOther
networkmannername联网方式名称
iseffective是否可以正常计费
0: 不行1: 可以
isbilling是否收费
0: 未收费1: 已收费
adspacetype广告位类型
1:Banner2: 插屏3: 全屏
adspacetypename广告位类型名称, 如
Banner, 插屏, 全屏devicetype设备类型(1:手机 2:平板)
1: 手机2: 平板
processnode流程节点
1: 请求量KPI2: 有效请求3: 广告请求
apptype应用类型
IDdistrict设备所在县名称
paymode针对平台商的支付模式
1: 展示量投放, CPM2: 点击量投放, CPC
isbid是否是
RTBbidpriceRTB竞价价格winpriceRTB竞价成功价格iswin是否竞价成功
cur结算币种,
USD,RMB等rate汇率
cnywinpriceRTB竞价成功转换成人民币的价格imei手机串码
mac手机
MAC地址idfa手机
APP的广告码openudid苹果设备的识别码
androidid安卓设备的识别码
rtbprovinceRTB省rtbcityRTB市rtbdistrictRTB区rtbstreetRTB街道storeurlAPP的市场下载地址realip真实
IPisqualityapp优选标识
bidfloor底价
aw广告位的宽
ah广告位的高
imeimd5IMEI的MD5值macmd5MAC的MD5值idfamd5IDFA的MD5值openudidmd5OpenUDID的MD5值androididmd5AndroidID的MD5值imeisha1IMEI的SHA-1值macsha1MAC的SHA-1值idfasha1IDFA的SHA-1值openudidsha1OpenUDID的SHA-1值androididsha1AndroidID的SHA-1值uuidunknowUUID的密文userid平台用户
IDiptype表示
IP库类型1: 为点媒IP库2: 为广告协会的IP地理信息标准库
默认为1
initbidprice初始出价
adpayment转换后的广告消费 (保留小数点后
6位)agentrate代理商利润率
lomarkrate代理利润率
adxrate媒介利润率
title标题
keywords关键字
tagid广告位标识 (当视频流量时值为视频
ID号)callbackdate回调时间, 格式为
yyyy/MM/dd hh:mm:sschannelid频道
IDmediatype媒体类型
email用户邮箱
tel用户电话号码
sex用户性别
age用户年龄
2. 工程创建和框架搭建
创建工程
搭建框架
建立配置框架
Step 1: 创建工程-
- 已经到最后一个阶段了, 不再详细说工程如何创建了, 看一下步骤即可
-
在
IDEA创建Maven工程, 选择存储位置工程命名为
dmp, 注意工程名一般小写, 大家也可以采用自己喜欢的命名方式, 在公司里, 要采用公司的习惯导入
Maven依赖创建
Scala代码目录创建对应的包们
- 创建需要的包
-
包名 描述 com.itheima.dmp.etl放置数据转换任务
com.itheima.dmp.report放置报表任务
com.itheima.dmp.tags放置标签有关的任务
com.itheima.dmp.utils放置一些通用公用的类
- 导入需要的依赖
-
在
DMP中, 暂时先不提供完整的Maven POM文件, 在一开始只导入必备的, 随着项目的进程, 用到什么再导入什么, 以下是必备的Spark全家桶Kudu一套Scala依赖SLF4J日志依赖Junit单元测试Java编译插件Scala编译插件Uber Jar编译插件ShadeCDH Repo仓库, 需要一个CDH的Maven仓库配置是因为用到CDH版本的Kudu
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<hadoopo.version>2.6.1</hadoopo.version>
<kudu.version>1.7.0-cdh5.16.0</kudu.version>
<maven.version>3.5.1</maven.version>
<junit.version>4.12</junit.version>
</properties> <dependencies>
<!-- Spark -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoopo.version}</version>
</dependency> <!-- Kudu client -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.7.0-cdh5.16.1</version>
</dependency> <!-- Kudu Spark -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>1.7.0-cdh5.16.1</version>
</dependency> <!-- Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency> <!-- Unit testing -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>provided</scope>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory> <plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.version}</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> <repositories>
<repository>
<id>cdh.repo</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
Step 2: 框架搭建-
编写
Spark程序的时候, 往往不需要一个非常复杂的框架, 只是对一些基础内容的抽象和封装即可, 但是也要考虑如下问题有哪些任务是要执行的
在做一个项目的时候, 尽量从全局的角度去看, 要考虑到周边的一些环境, 例如说回答自己如下几个问题
问题 初步分析和解答 这个应用有几个入口
这个程序的入口数量是不确定的, 随着工作的进展而变化, 但是至少要有两个入口, 一个是生成报表数据, 一个是处理用户的标签数据
这个应用会放在什么地方执行
分为测试和生产, 测试可以直接使用 IDEA 执行, 生成需要打包并发送到集群执行
这个应用如何调度
这个应用包含了不止一个任务, 最终会由
Oozie,Azkaban,AirFlow等工具去调度执行有哪些操作可能会导致重复代码过多
其实无论是
Spring, 还是Vue, 还是Spark, 这些框架和工具, 最终的目的都是帮助我们消除一些重复的和通用的代码所以既然我们无需在 Spark 的应用中搭建复杂的项目框架, 但是对于重复的代码还是要消除的, 初步来看可能会有如下重复的代码点
各个数据库的访问
配置的读取
Step 3: 建立配置读取工具-
了解配置文件和读取框架
数据读取部分, 有一个比较好用的工具, 叫做
lightbend/config, 它可以读取一种叫做HOCON的配置文件HOCON全称叫做Human-Optimized Config Object Notation, 翻译过来叫做 为人类优化的配置对象表示法HOCON是一种类似于Properties的配置文件格式, 并包含JSON的语法格式, 比较易于使用, 其大致格式如下foo: {
bar: 10,
baz: 12
} foo {
bar = 10,
baz = 12
} foo.bar=10
foo.baz=10以上三种写法是等价的, 其解析结果都是两个字段, 分别叫做
foo.bar和foo.baz读取
HOCON文件格式需要使用lightbend/config, 它的使用非常的简单当配置文件被命名为
application.conf并且被放置于resources时, 可以使用如下方式直接加载val config: Config = ConfigFactory.load()
val bar = config.getInt("foo.bar")
val baz = config.getInt("foo.baz")
创建配置文件
创建配置文件
resource/spark.conf, 并引入如下内容# Worker 心跳超时时间
spark.worker.timeout="500" # RPC 请求等待结果的超时时间
spark.rpc.askTimeout="600s" # 所有网络操作的等待时间, spark.rpc.askTimeout 默认值等同于这个参数
spark.network.timeoout="600s" # 最大使用的 CPU 核心数
spark.cores.max="10" # 任务最大允许失败次数
spark.task.maxFailures="5" # 如果开启推测执行, 开启会尽可能的增快任务执行效率, 但是会占用额外的运算资源
spark.speculation="true" # Driver 是否允许多个 Context
spark.driver.allowMutilpleContext="true" # Spark 序列化的方式, 使用 Kryo 能提升序列化和反序列化的性能
spark.serializer="org.apache.spark.serializer.KryoSerializer" # 每个页缓存, Page 指的是操作系统的内存分配策略中的 Page, 一个 Page 代表一组连续的内存空间
# Spark 在引入钨丝计划以后, 使用 Java 的 Unsafe API 直接申请内存, 其申请单位就是 Page
# 如果 Page 过大, 有可能因为操作系统的策略无法分配而拒绝这次内存申请, 从而报错
# 简单来说, 这个配置的作用是一次申请的内存大小
spark.buffer.pageSize="6m"以上的配置列成表如下
配置项目 描述 spark.worker.timeout如果超过了这个配置项指定的时间,
Master认为Worker已经跪了spark.network.timeout因为
Spark管理一整个集群, 任务可能运行在不同的节点上, 后通过网络进行通信, 一次网络通信有可能因为要访问的节点实效而一直等待, 这个配置项所配置的便是这个等待的超时时间spark.cores.maxSpark整个应用最大能够申请的CPU核心数spark.task.maxFailuresSpark本身是支持弹性容错的, 所以不能因为某一个Task失败了, 就认定整个Job失败, 一般会因为相当一部分Task失败了才会认定Job失败, 否则会进行重新调度, 这个参数的含义是, 当多少个Task失败了, 可以认定Job失败spark.speculation类似
Hadoop,Spark也支持推测执行, 场景是有可能因为某台机器的负载过高, 或者其它原因, 导致这台机器运行能力很差,Spark会根据一些策略检测较慢的任务, 去启动备用任务执行, 使用执行较快的任务的结果, 但是推测执行有个弊端, 就是有可能一个任务会执行多份, 浪费集群资源spark.driver.allowMutilpleContext很少有机会必须一定要在一个
Spark Application中启动多个Context, 所以这个配置项意义不大, 当必须要使用多个Context的时候, 开启此配置即可spark.serializerSpark将任务分发到集群中执行, 所以势必涉及序列化, 这个配置项配置的是使用什么序列化器, 默认是JDK的序列化器, 可以指定为Kyro从而提升性能, 但是如果使用Kyro的话需要序列化的类需要被先注册才能使用spark.buffer.pageSize每个页缓存,
Page指的是操作系统的内存分配策略中的Page, 一个Page代表一组连续的内存空间,Spark在引入钨丝计划以后, 使用Java的Unsafe API直接申请内存, 其申请单位就是Page, 如果Page过大, 有可能因为操作系统的策略无法分配而拒绝这次内存申请, 从而报错, 简单来说, 这个配置的作用是一次申请的内存大小, 一般在报错的时候修改这个配置, 减少一次申请的内存导入配置读取的工具依赖
在
pom.xml中的properties段增加如下内容<config.version>1.3.4</config.version>在
pom.xml中的dependencites段增加如下内容<!-- Config reader -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>${config.version}</version>
</dependency>
配置工具的设计思路
- 在设计一个工具的时候, 第一步永远是明确需求, 我们现在为
SparkSession的创建设置配置加载工具, 其需求如下 -
配置在配置文件中编写
使用
typesafe/config加载配置文件在创建
SparkSession的时候填写这些配置
- 前两点无需多说, 已经自表达, 其难点也就在于如何在
SparkSession创建的时候填入配置, 大致思考的话, 有如下几种方式 -
加载配置文件后, 逐个将配置的项设置给
SparkSessionspark.config("spark.worker.timeout", config.get("spark.worker.timeout"))加载配置文件后, 通过隐式转换为
SparkSession设置配置spark.loadConfig().getOrCreate()
毫无疑问, 第二种方式更为方便
- 在设计一个工具的时候, 第一步永远是明确需求, 我们现在为
创建配置工具类
- 看代码之前, 先了解一下设计目标
-
加载配置文件
spark.conf无论配置文件中有多少配置都全部加载
为
SparkSession提供隐式转换自动装载配置
- 下面是代码, 以及重点解读
-
class SparkConfigHelper(builder: SparkSession.Builder) { private val config: Config = ConfigFactory.load("spark") def loadConfig(): SparkSession.Builder = {
import scala.collection.JavaConverters._ for (entry <- config.entrySet().asScala) {
val value = entry.getValue
val valueType = value.valueType()
val valueFrom = value.origin().filename()
if (valueType == ConfigValueType.STRING && valueFrom != null) {
builder.config(entry.getKey, value.unwrapped().asInstanceOf[String])
}
} builder
}
} object SparkConfigHelper { def apply(builder: SparkSession.Builder): SparkConfigHelper = {
new SparkConfigHelper(builder)
} implicit def setSparkSession(builder: SparkSession.Builder) = {
SparkConfigHelper(builder)
}
}: 加载配置文件 : 因为 Config工具会自动的加载所有的系统变量, 需要通过Origin来源判断, 只接收来自于文件的配置: 判断: 1. 是 String类型, 2. 来自于某个配置文件: 为 SparkSession设置参数: 提供伴生对象的意义在于两点: 1. 更方便的创建配置类, 2. 提供隐式转换, 3. 以后可能需要获取某个配置项 : 提供隐式转换, 将 SparkSession转为ConfigHelper对象, 从而提供配置加载
3. 将数据集中的 IP 转为地域信息
IP转换工具介绍转换
IP转换工具介绍-
- 进行
IP转换这种操作, 一般有如下一些办法 -
方式 描述 优点 缺点 自己编写
一般如果自己编写查找算法的话, 大致有如下几步
找到一个
IP范围 : 省 : 市 : 区这样的数据集读取数据集
将
IP转为数字表示法, 本质上IP就是二进制的点位表示法,192.168.0.1 → 1100 0000 1010 1000 0000 0000 0000 0001 → 3232235521使用
3232235521这样的数字在IP数据集中通过二分法查找对应的省市区
没有第三方库的学习成本
没有数据结构上的支持, 效率低
没有上层的封装, 使用麻烦
第三方库
一般第三方库会有一些数据结构上的优化, 查找速度比二分法会更快一些, 例如
BTree就特别适合做索引, 常见的方式有GeoLite纯真数据库
ip2region
速度快
不麻烦
有上层封装, 用着爽
第三方一般会提供数据集, 数据集会定时更新, 更精准
有轮子就别自己搞了, 怪麻烦的
需要学习第三方工具, 有一定的学习成本, 而且不一定和以后工作中用同样一个工具
- 选用
ip2region这个工具来查找省市名称 -
ip2region的优点工具 数据结构支持 中文支持 GeoLite有
无
纯真
无
有
ip2region有
有
引入
ip2region复制
IP数据集ip2region.db到工程下的dataset目录在
Maven中增加如下代码<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
ip2region的使用val searcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
val data = searcher.btreeSearch(ip)
println(data.getRegion)
- 选用
GeoLite确定经纬度 -
后面需要使用经纬度, 只有
GeoLite可以查找经纬度工具 数据结构支持 中文支持 经纬度支持 GeoLite有
无
有
纯真
无
有
无
ip2region有
有
无
引入
GeoLite将
GeoLite的数据集GeoLiteCity.dat拷贝到工程中dataset目录下在
pom.xml中添加如下依赖<dependency>
<groupId>com.maxmind.geoip</groupId>
<artifactId>geoip-api</artifactId>
<version>1.3.0</version>
</dependency> <dependency>
<groupId>com.maxmind.geoip2</groupId>
<artifactId>geoip2</artifactId>
<version>2.12.0</version>
</dependency>
GeoLite的使用方式val lookupService = new LookupService("dataset/GeoLiteCity.dat", LookupService.GEOIP_MEMORY_CACHE)
val location = lookupService.getLocation("121.76.98.134")
println(location.latitude, location.longitude)
- 进行
IP转换思路梳理-
现在使用不同的视角, 理解一下在这个环节我们需要做的事情
- 工具视角
-
- 数据视角
-
- 要做的事
-
读取数据集
pmt.json将
IP转换为省市设计
Kudu表结构, 创建Kudu表存入
Kudu表
- 挑战和结构
-
现在的任务本质上是把一个
数据集 A转为数据集 B,数据集 A可能不够好,数据集 B相对较好, 然后把数据集 B落地到Kudu, 作为ODS层, 以供其它功能使用但是如果
数据集 A转为数据集 B的过程中需要多种转换呢?所以, 从面向对象的角度上来说, 需要一套机制, 能够组织不同的功能协同运行
所以我们可以使用一个名为
PmtETLProcessor的类代表针对数据集 A到数据集 B的转换, 然后抽象出单位更小的负责具体某一个转换步骤的节点, 集成到PmtETLProcessor中, 共同完成任务
- 参数配置
-
为了让程序行为更可控制, 所以一般会在编写程序之前先大致计划以下程序中可能使用到的一些参数
Kudu的表名Kudu表的复制因子ODS层的表名
规划好以后, 着手创建配置文件
resource/kudu.conf# Server properties
kudu.common.master="192.168.169.101:7051,192.168.169.102:7051,192.168.169.103:7051"
kudu.common.factor=1 # Table name
kudu.name.pmt_ods="ODS_"
Kudu的支持库-
- 为了方便
Kudu的使用, 所以要创建一个Kudu的Helper, 大致需求如下 -
需求 原始调用方式 理想调用方式 创建表
KuduContext.createTable()SparkSession.createKuduTable()通过
DataFrame将数据保存到Kudu表DataFrame.write.options(…).kuduDataFrame.saveAsKuduTable KuduHelper的设计-
KuduHelper的设计思路两句话可以总结尽可能的不在处理类中读取配置文件
尽可能的提供易于调用的接口
class KuduHelper {
private var spark: SparkSession = _
private var dataset: Dataset[Any] = _ def this(spark: SparkSession) = {
this()
this.spark = spark
} def this(dataset: Dataset[Any]) = {
this(dataset.sparkSession)
this.dataset = dataset
} private val config = ConfigFactory.load("kudu")
private val KUDU_MASTERS = config.getString("kudu.common.master")
private val kuduContext = new KuduContext(KUDU_MASTERS, spark.sparkContext) def createKuduTable(tableName: String, schema: Schema): Unit = {
if (kuduContext.tableExists(tableName)) {
kuduContext.deleteTable(tableName)
} import scala.collection.JavaConverters._
val options = new CreateTableOptions()
.setNumReplicas(config.getInt("kudu.common.factor"))
.addHashPartitions(List("uuid").asJava, 6) kuduContext.createTable(tableName, schema, options)
} def saveToKudu(tableName: String): Unit = {
import org.apache.kudu.spark.kudu._ dataset.write
.option("kudu.table", tableName)
.option("kudu.master", KUDU_MASTERS)
.mode(SaveMode.Append)
.kudu
} } object KuduHelper { implicit def sparkToKuduContext(spark: SparkSession): Unit = {
new KuduHelper(spark)
} implicit def datasetToKuduContext(dataset: Dataset[Any]): Unit = {
new KuduHelper(dataset)
} def formattedDate(): String = {
FastDateFormat.getInstance("yyyyMMdd").format(new Date)
}
}: 主题设计思路就是将 SparkSession或者DataFrame隐式转换为KuduHelper, 在KuduHelper中提供帮助方法: 将 SparkSession转为KuduHelper时调用: 将 Dataset转为KuduHelper时调用: 在 Helper内部读取配置文件, 创建KuduContext: 此方法就是设计目标 SparkSession.createKuduTable(tableName)中被调用的方法: 此方法就是设计目标 DataFrame.saveToKudu(tableName)中被调用的方法: 将 SparkSession转为KuduHelper: 将 Dataset转为KuduHelper: 提供一个统一的生成日期的方法, 给外部使用
- 为了方便
ETL代码编写-
创建
PmtETLProcessor类PmtETLProcessor类负责整个ETL过程, 但是不复杂中间过程中具体的数据处理, 具体数据如何转换, 要做什么事情由具体的某个Converter类负责object PmtETLProcessor { def main(args: Array[String]): Unit = {
import com.itheima.dmp.utils.SparkConfigHelper._
import com.itheima.dmp.utils.KuduHelper._ // 创建 SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("pmt_etl")
.loadConfig()
.getOrCreate() import spark.implicits._ // 读取数据
val originDataset = spark.read.json("dataset/pmt.json") }
}创建
IPConverter类处理IP转换的问题IPConverter主要解决如下问题原始数据集中有一个
ip列, 要把ip这一列数据转为五列, 分别是ip,Longitude,latitude,region,city, 从而扩充省市信息和经纬度信息将新创建的四列数据添加到原数据集中
object IPConverter { def process(dataset: Dataset[Row]): Dataset[Row] = {
val dataConverted: RDD[Row] = dataset
.rdd
.mapPartitions(convertIPtoLocation) val schema = dataset.schema
.add("region", StringType)
.add("city", StringType)
.add("longitude", DoubleType)
.add("latitude", DoubleType) val completeDataFrame = dataset
.sparkSession
.createDataFrame(dataConverted, schema) completeDataFrame
} def convertIPtoLocation(iterator: Iterator[Row]): Iterator[Row] = {
val searcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db") val lookupService = new LookupService(
"dataset/GeoLiteCity.dat",
LookupService.GEOIP_MEMORY_CACHE) iterator.map(row => {
val ip = row.getAs[String]("ip") val regionData = searcher.btreeSearch(ip).getRegion.split("\\|")
val region = regionData(2)
val city = regionData(3) val location = lookupService.getLocation(ip)
val longitude = location.longitude.toDouble
val latitude = location.latitude.toDouble val rowSeq = row.toSeq :+ region :+ city :+ longitude :+ latitude
Row.fromSeq(rowSeq)
})
}
}: 通过 mapPartitions算子, 对每一个分区数据调用convertIPtoLocation进行转换, 需要注意的是, 这个地方已经被转为RDD了, 而不是DataFrame, 因为DataFrame在转换中不能更改Schema: convertIPtoLocation主要做的事情是扩充原来的row, 增加四个新的列: 获取省市中文名 : 获取经纬度 : 根据原始 row生成新的row, 新的row中包含了省市和经纬度信息: 新的 row对象的RDD结合 被扩充过的Schema, 合并生成新的DataFrame返回给Processor在
PmtETLProcessor中调用IPConverterobject PmtETLProcessor { def main(args: Array[String]): Unit = {
... val originDataset = spark.read.json("dataset/pmt.json") // 调用 IPConverter, 传入 originDataset, 生成包含经纬度和省市的 DataFrame
val ipConvertedResult = IPConverter.process(originDataset) // 要 Select 的列们, 用于组织要包含的结果集中的数据
// 因为太多, 不再此处展示, 若要查看, 请移步代码工程
val selectRows: Seq[Column] = Seq(...) // 选中相应的列
ipConvertedResult.select(selectRows:_*).show()
}通过以上的代码, 已经在数据集中扩展了地理位置相关的信息, 接下来可以存入
Kudu了
Update(Stage5):DMP项目_业务介绍_框架搭建的更多相关文章
- 从零开始--Spring项目整合(1)使用maven框架搭建项目
这些年一直在用spring的框架搭建项目,现在开始我们从零开始利用Spring框架来搭建项目,目前我能想到有Spring.SpringMVC.SpringJDBC.Mybatis.WebSockt.R ...
- 多测师讲解jmeter _基本介绍_(001)高级讲师肖sir
jmeter讲课课程 一.Jmeter简介 Jmeter是由Apache公司开发的一个纯Java的开源项目,即可以用于做接口测试也可以用于做性能测试. Jmeter具备高移植性,可以实现跨平台运行. ...
- 基于SSH2的OA项目1.0_20161206_需求分析与框架搭建
1. SSH项目 OA项目,办公自动化,将公司的数据,文档,流程实现在系统中的管理. 降低人员交流过程中的成本.提高办公的效率. 2 .系统管理 主要实现系统权限的管理,不同的用户登陆后看到菜单项不一 ...
- 项目实战 - 原理讲解<-> Keras框架搭建Mtcnn人脸检测平台
Mtcnn它是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型主要采用了三个级联的网络,采用候选框加分类器的思想,进行快速高效的人脸检测.这三个级联的网络分别是快速生成 ...
- 零开始:NetCore项目权限管理系统:基础框架搭建
有兴趣的同学可以一起做 喜欢NetCore的朋友,欢迎加群QQ:86594082 源码地址:https://github.com/feiyit/SoaProJect 新建一个空的解决方案,建立对应的解 ...
- 金蝶K/3 跟踪语句_业务单据
跟踪语句_业务单据_BOM select * from t_TableDescription where Ftablename like '%ICBOM%' order by FFieldName o ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- JavaWeb_(Mybatis框架)主配置文件介绍_四
系列博文: JavaWeb_(Mybatis框架)JDBC操作数据库和Mybatis框架操作数据库区别_一 传送门 JavaWeb_(Mybatis框架)使用Mybatis对表进行增.删.改.查操作_ ...
- 您好,想问一下目前哪些营业厅可以办理NFC-SIM卡的更换业务?_百度知道
您好,想问一下目前哪些营业厅可以办理NFC-SIM卡的更换业务?_百度知道 您好,想问一下目前哪些营业厅可以办理NFC-SIM卡的更换业务? 2013-06-14 10:39 maxre ...
随机推荐
- codeforces div2 603 C. Everyone is a Winner!(二分)
题目链接:https://codeforces.com/contest/1263/problem/C 题意:给你一个数字n,求n/k有多少个不同的数 思路:首先K大于n时,n/k是0.然后k取值在1到 ...
- 全网最全!小白搭建hexo+Github/Gitee/Coding
Hexo是一个快速.简洁且高效的博客框架.Hexo使用Markdown解析文章,在几秒内,即可利用靓丽的主题生成静态网页. 本站内容已全部转移到https://www.myyuns.ltd,具体请移步 ...
- SQLAlchemy -高级查询
查询 # -*- coding: utf-8 -*- from sqlalchemy.orm import sessionmaker from SQLAlchemy.create import ...
- java的动态绑定和多态
public class Shape { public void area() { System.out.println("各种形状的面积..."); } public stati ...
- 基于XML装配bean的解析-Bean的作用域
一.Bean的种类1.普通bean:<bean id="" class="A"> ,spring直接创建A实例,并返回. 2.FactoryBe ...
- vs rdlc 设置Tablix 在新页面重复表头
设置方法: 1.选中Tablix控件 2.点开三角形 3.选择高级模式 4.在行组 下 选择静态,然后看右边的属性 5.将属性设置为如下 就可以让Tablix控件实现在新页中带表头
- Java实现定时器的四种方式
package com.wxltsoft.tool; import org.junit.Test; import java.util.Calendar; import ja ...
- 哈希 Perl第六章
哈希元素赋值: $hash{$some_key} = ‘something' 访问整个哈希: %some_hash = (’a' , '0' , 'b' , '1' , 'c' , '3') @a ...
- spring简要回顾
spring内容 spring容器: @Repository @Service @Controller @Component <bean id="类名首字母小写">默认 ...
- C#面向对象三大特性:继承
什么是继承 定义:继承是面向对象编程语言中的一个重要特性,当一个类A能够获取另一个类B中所有非私有的数据和操作的定义作为自己的部分或全部成分时,就称这两个类之间具有继承关系.被继承的类B称为父类或基类 ...