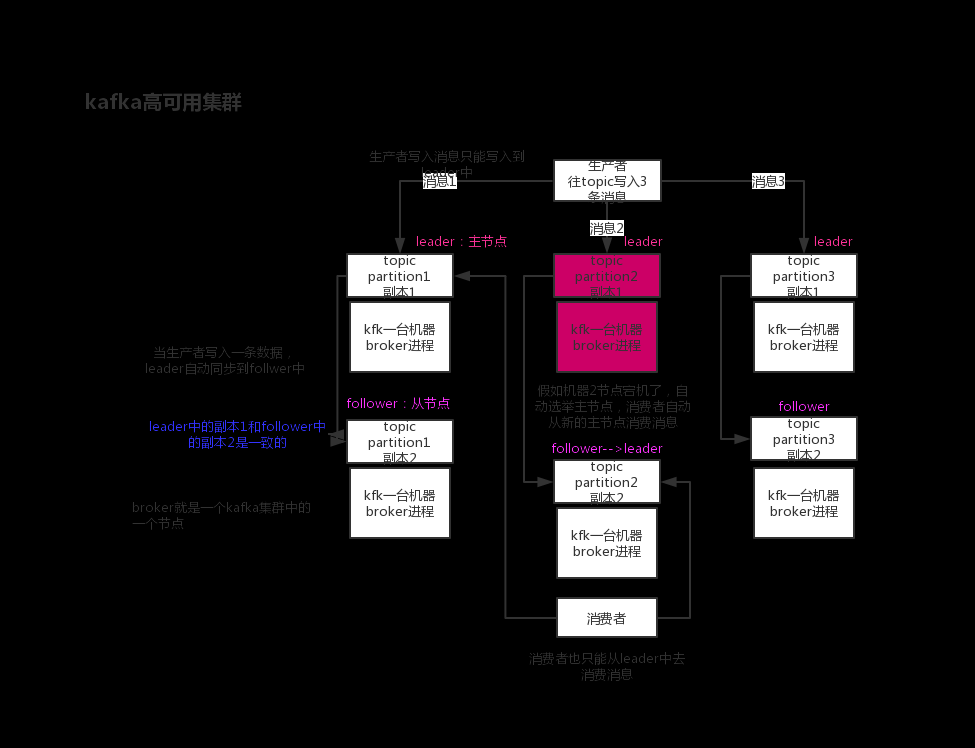
怎么保证RabbitMQ和kafuka集群的高可用性?
<ignore_js_op>
|
|

怎么保证RabbitMQ和kafuka集群的高可用性?的更多相关文章
- RabbitMQ介绍5 - 集群
RabbitMQ内建集群机制,利用Erlang提供的开放电信平台(OTP,Open telecom Platform)通信框架,使得集群很容易进行横向扩展,提高系统吞吐量.这里只讨论集群的概念.原理, ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- RabbitMQ安装、集群搭建、概念解析
RabbitMQ安装.集群搭建.概念解析 基本概念 为什么会产生MQ 1.解耦:采用异步方式实现业务需求达到解耦的目的. 2.缓冲流量,削峰填谷: 问:为什么会有流量冲击? 答:采用"直接调 ...
- RabbitMQ镜像队列集群搭建、与SpringBoot整合
镜像模式 集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失,在实际工作中也是用的最多的,并且实现集群比较的简单. Mirror镜像队列,目的是为了保证 RabbitMQ 数据的高可靠 ...
- RabbitMQ安装以及集群部署
本次记录安装RabbitMQ的过程,只针对MAC下单机版安装.单机集群安装方法以及配置haproxy负载均衡. RabbitMQ单机版本安装 RabbitMQ单机集群安装方法(适合开发练习) Rabb ...
- Centos 6.5 Rabbitmq 安装和集群,镜像部署
centos 6.5 rabbitmq 安装和集群,镜像部署 安装erlang: yum install gcc glibc-devel make ncurses-devel openssl-deve ...
- Linux源码安装RabbitMQ高可用集群
1.环境说明 linux版本:CentOS Linux release 7.9.2009 erlang版本:erlang-24.0 rabbitmq版本:rabbitmq_server-3.9.13 ...
- Redis集群与高可用性技术小结
客户端分片,这种方式需要实现特定的客户端,需要手工配置redis实例并根据算法进行访问,对于redis实例的增减,调整灵活性很差,一般不推荐. 代理分片,常见的有Twemproxy架构(豆瓣创建了co ...
- RabbitMQ 高可用集群搭建及电商平台使用经验总结
面向EDA(事件驱动架构)的方式来设计你的消息 AMQP routing key的设计 RabbitMQ cluster搭建 Mirror queue policy设置 两个不错的RabbitMQ p ...
随机推荐
- [ACTF2020 新生赛]Include
0x00 知识点 本地文件包含 ?file=php://filter/read/convert.base64-encode/resource=index.php ?file=php://filter/ ...
- [RoarCTF 2019]Simple Upload
0x00 知识点 1:Think PHP上传默认路径 默认上传路径是/home/index/upload 2:Think PHP upload()多文件上传 think PHP里的upload()函数 ...
- BZOJ 4855 [Jsoi2016]轻重路径
题解:用树链剖分来维护树链剖分 令d[x]=size[heavyson[x]]-size[lightson[x]] 当d[x]<0时轻重儿子关系改变 用数据结构维护d[x]并找到这些位置改变即可 ...
- 小程序调用wx.chooseLocation接口的时候无法获取权限(ios)
ios手机小程序调用wx.chooseLocation接口的时候,获取权限的时候报authorize:fail:require permission desc这样子的错误,这是由于苹果的安全机制导致需 ...
- SQL基础教程(第2版)第6章 函数、谓词、CASE表达式:6-1 函数
6-1 各种各样的函数 ● 函数的种类很多,无需全都记住,只需要记住具有代表性的函数就可以了,其他的可以在使用时再进行查询. ■函数的种类所谓函数,就是输入某一值得到相应输出结果的功能,输入值称为参数 ...
- ACwing算法基础课听课笔记(第一章,基础算法一)(二分)
二分法: 在看这个视频前,我对于二分法是一头雾水的,又加上这个算法平常从来没写过所以打了一年了还没正式搞过.视频提到ACwing上的一道题,我用自以为聪明的方法去做,结果TLE了,实在丢人,不说了,开 ...
- 精准医疗|研发药物|Encode|roadmap|
生物医学大数据 精准医疗 研发药物:特异性靶点&过表达靶点 Encode &roadmap找组织特异性的表观遗传学标记.TF.DNA甲基化的动态变化等信息. 生物大数据的标准化与整合- ...
- Java中常用的API(一)——Object
概述 如果要问Java为什么是用起来非常舒服的语言,那很大一部分的功劳就是JavaAPI的.API定义了许多封装好的类和方法供我们使用,来处理特定的问题,所以学习常用的API是非常重要的. 同时,面向 ...
- UITableViewCell 的selectedBackgroundView
UITableViewCell中的selectedBackgroundView就是用于当用户点击cell的时候,选择状态的view,你可以对这个view进行颜色或者其他样式等做一些定制,可以达到点击之 ...
- os发展史
01. 操作系统的发展历史 1.1 Unix 1965 年之前的时候,电脑并不像现在一样普遍,它可不是一般人能碰的起的,除非是军事或者学院的研究机构,而且当时大型主机至多能提供30台终端(30个键盘. ...