AdaBoost理解
AdaBoost是一种准确性很高的分类算法,它的原理是把K个弱分类器(弱分类器的意思是该分类器的准确性较低),通过一定的组合(一般是线性加权进行组合),组合成一个强的分类器,提高分类的准确性。
因此,要想使用AdaBoost,需要首先找几个弱的分类器出来,然后进行组合。这些弱分类器,其实可以自己指定,自己随意给出,但效果就不能保证。
要想通过AdaBoost得到一个准确性高的分类器,需要小心设计这些弱分类器。我自己理解,弱分类器可以采用最简单的形式,即二分法(二元分类器),取一个阈值v,某个特征小于v的是一类,该特征大于v的是另一类,至于这个阈值取多少合适,可以通过这个分类器的错误率(被错误分类的样本数除以总的样本数)来决定,若取阈值为v1得到的二元分类器的错误率为e1,而取阈值为v2的错误率e2,若e2<e1,说明v2更合适。还可以多取几个阈值,从中找出最佳的。《机器学习实战》解释了AdaBoost原理,但后面的代码让人不明白它到底在干啥。故自己理解之后,在此记录。
下面两篇文章可以帮助理解AdaBoost的算法过程和原理推导过程:
(1) AdaBoost算法过程: Adaboost算法原理分析和实例+代码
其中,sign(a1*h1(x)+a2*h2(X)+a3*h3(x)),其中sign(*)表示取*的正负号,若*为正数,则sign(*)返回1,否则返回-1。而例子中:
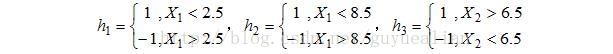
最后的分类器 f3(x)=0.4236h1(x) + 0.6496h2(x)+0.9229h3(x),这里的h1(x)里面的x只是代表特征的意思,在这个例子中有x1,x2两个特征,因此,应该把两个特征都带进h1,h2,h3当中去。
例如,其中样本9 X9=(9,8),x1=9,x2=8,因此,h1(X)=-1,h2(X)=-1,h3(X)=1,于是f3(x)=0.4236*(-1)+0.6496*(-1)1+0.9229*1=-0.150299<0,因此f3(x)给出的分类结果为-1,分类结果是正确的。
(2) AdaBoost原理和推导: Adaboost 算法的原理与推导
Bagging和Boosting都是集成学习的一种实现方式,算是一种框架和思路,不是一个算法,因为它里面的弱分类器可以用决策树、svm、神经网络等各种算法进行组合。
另外,Bagging与Boosting的差别:https://www.cnblogs.com/liuwu265/p/4690486.html
bagging是从大数据集中随机抽样N次,形成N个不同的训练集,每个训练集得到一个弱分类器,再把这些弱分类器通过投票等方式进行组合,形成一个强分类器;而boosting是对同一个训练集迭代地进行训练,每次找出一个错误率最低的弱分类器,然后根据这个弱分类器的错误率计算更新每个样本的权重,这个权重将在下轮寻找错误率最低的弱分类器当中用到,因为错误率的计算方法就是把被弱分类器错分的样本的权重求和即为下一个弱分类器的错误率。详见:
https://blog.csdn.net/ruiyiin/article/details/77114072 (仔细看bagging和boosting的示意图)及
小象学院的“详解AdaBoost算法”(田野)这一课程,及小象学院“机器学习”课程的“12提升”的pdf文档中adaboost的举例 和 Adaboost 算法的原理与推导
https://blog.csdn.net/hero_boke/article/details/78991722
AdaBoost理解的更多相关文章
- [11-2] adaboost理解
以二分类问题为例({-1,+1}) adaboost步骤: 1.初始化u1=(1/N,1/N,-,1/N) 2.找到h,使最小化,记该h为g:计算作为该g的权重 3.更新ui: 4.重复2,3得到T个 ...
- 深入理解Adaboost算法
理解算法确实是欲速则不达,唯有一步一步慢慢看懂,然后突然觉得写的真的太好了,那才是真的有所理解了. Adaboost的两点关键点: 1. 如何根据弱模型的表现更新训练集的权重: 2. 如何根据弱模型的 ...
- Adaboost新理解
Adaboost有几个难点: 1.弱分类器的权重怎么理解? 误差大的弱分类器权重小,误差小的弱分类器权重大.这很好理解.在台湾大学林轩田老师的视频中,推导说,这个权值实际上貌似梯度下降,权值定义成1/ ...
- Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在"强可学习"和"弱科学习"的概念上来说就是我们通过对多个弱可学习的算法进行"组合 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习——AdaBoost元算法
当做重要决定时,我们可能会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题也是这样,这就是元算法(meta-algorithm)背后的思路. 元算法是对其他算法进行组合的一种方式,其中最流行的一 ...
- Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记) 一.Bagging (并行bootstrap)& Boosting(串行) 随机森林实际上是bagging的思路,而GBD ...
- adaboost原理与实践
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器).其算法本身是通过改变数据分布来实现的,它根据 ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
随机推荐
- Thinkphp 缓存RCE
5.0.0<=ThinkPHP5<=5.0.10 . 漏洞利用条件: 1.基于tp5开发的代码中使用了Cache::set 进行缓存 2.在利用版本范围内 3.runtime目录可以 ...
- request中跟路径有关的api的分析
最近重在研究struts的源码,其中涉及到了request中的几个api,看了文档后还是觉得不清楚,所以在自己原来的工程中 测试了一下各个api的具体效果.在这里跟大家分享一下. 这是我具体测试的代码 ...
- 数据预处理 —— padding数据
1. 论Conv2d()里的padding和Conv2d()前padding的区别及重要性. 小生建议,尽量少用Conv2d()里的填充方式,换成自定义填充方式(强烈建议). 小生为何这样建议 ...
- vue滑动吸顶以及锚点定位
Vue项目中需要实现滑动吸顶以及锚点定位功能.template代码如下: <template> <div class="main"> <div id= ...
- 关于fromdata的上传文件问题
<div <label>上传pdf</label> <input id="fileId" type="file" accep ...
- 推荐 10个 NB的 IDEA 插件,开发效率至少提升一倍
友情提示:插件虽好,可不要贪装哦,装多了会 卡 .卡 .卡 ~ 正经干活用的 分享一点自己工作中得心应手的IDEA插件,可不是在插件商店随随便便搜的,都经过实战检验,用过的都说好.可能有一些大家用过的 ...
- [Alink漫谈之三] AllReduce通信模型
[Alink漫谈之三] AllReduce通信模型 目录 [Alink漫谈之三] AllReduce通信模型 0x00 摘要 0x01 MPI是什么 0x02 Alink 实现MPI的思想 0x03 ...
- 前端面试题-TCP和UDP的区别
TCP和UDP的区别 (1)TCP是面向连接的,udp是无连接的即发送数据前不需要先建立链接. (2)TCP提供可靠的服务.也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UD ...
- Postman学习宝典(一)
前言:网上看到的比较好的Postman教程,既然已经有了,我就不重复造轮子了,直接copy过来. 资源来源于:米阳MeYoung Postman 入门1- 安装.变量.代理 简介 Postman 是一 ...
- 从X86指令深扒JVM的位移操作
概述 之所以会写这个,主要是因为最近做的一个项目碰到了一个移位的问题,因为位移操作溢出导致结果不准确,本来可以点到为止,问题也能很快解决,但是不痛不痒的感觉着实让人不爽,于是深扒了下个中细节,直到看到 ...