手把手教你用Rancher创建产品质量数据库设置
目标:在本文中,我们将介绍如何运行一个分布式产品质量数据库设置,它由Rancher进行管理,并且保证持久性。为了部署有状态的分布式Cassandra数据库,我们将使用Stateful Sets (有状态集)以及Rancher中的Kubernetes集群。
先决条件:假设您已经有一个由云服务商提供的Kubernetes集群。如果您想在Amazon EC2中使用Rancher 2.0创建K8s集群,可以查看Rancher的资源:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/rke-clusters/node-pools/ec2/。
数据库对业务至关重要,无论是数据丢失还是泄露,都会为企业带来严重的风险。操作错误或体系结构故障都可能导致重大事件和资源的损失,这就需要故障转移系统/过程来减少数据丢失的可能。在将数据库体系结构迁移到Kubernetes之前,必须完成在容器体系结构以及裸机上运行数据库集群的成本效益分析对比,这包括评估恢复时间目标(Recovery Time Objective,RTO)以及恢复数据目标(Recovery Point Objective,RPO)的灾难恢复要求。这些分析在面对数据敏感的应用程序是非常重要,尤其当程序需要真正高可用、针对大规模和冗余需要地理分离、以及应用程序恢复要低延迟时。
在下文的步骤中,我们将分析在Rancher高可用和Kubernetes中可供使用的各种选项,给大家设计产品质量数据库提供参考。
A.有状态系统容器架构的缺点
部署在类似Kubernetes的集群中的容器自然是无状态而且短暂的,这意味着它们不会保持固定的身份,并且当发生错误或重新启动时会发生数据丢失和遗忘。在设计分布式数据库环境时,需要提供高可用性以及容错,这对Kubernetes的无状态体系结构提出了挑战,因为无论是复制还是扩展都需要维护下面的状态:
(1)存储;(2)身份;(3)会话;(4)集群角色。
考虑到我们的容器化应用程序,我们马上就可以看出无状态架构面临的挑战,我们的应用程序需要满足一系列的要求:
我们的数据库需要将数据(Data)和事务(Transactions)存储在文件中,这些文件对每个数据库容器来说都是持久且独有的;
数据库应用程序中的每个容器都需要维护一个固定的身份作为数据库节点,以便我们可以通过名称、地址或者索引将流量路由给它;
需要数据库客户端会话来维护状态,为保证一致性,需确保在状态更改之前,读写事务已经终止,而且出现持久性故障时状态转换不受影响。
个数据库节点都需要在其数据库集群中有持久化的角色,比如主机、副本或者分片,除非它们被特定的应用程序的事件更改,或者由于模式更改了而必须更改。
针对这些挑战,目前的解决方案可能是将PersistentVolume附加到我们Kubernetes pods上,它的生命周期独立于使用它的任何一个pod。但是,PersistentVolume不会向集群节点(即父节点、子节点或种子节点)提供一致的角色分配。集群不能保证在整个应用程序的生命周期中维护数据库状态,说的具体一点就是,新的容器会由非确定的随机名称创建,并且pods可以设置在任何时间按照任何的顺序启动、终止或者缩放。所以我们的挑战依然存在。
B.K8s部署分布式数据库的优点
有这么多在Kubernetes集群中部署分布式数据库的挑战,我们是否还值得付出努力呢?Kubernetes开辟了许多优势和可能性,包括管理大量的数据库服务以及常见的自动化操作,从可恢复性、可靠性和可扩展性来支持其生命周期健康。即使在虚拟化环境中,部署数据库集群的所需的时间和成本也远低于部署裸机集群。
Stateful Sets提供了前一节中所述挑战的前进方向。在1.5版本引入了Stateful Sets之后,Kubernetes现在为存储和身份实现了有状态质量,保证了下面的内容:
每个pod都附有一个持久卷,从pod链接到存储,这解决了A中的存储状态问题;
每个pod都以相同的顺序开始并以相反的顺序终止,这解决了A的会话状态问题;
每个pod都有一个唯一且可确定的名称、地址和序号索引,用于解决A中的身份和集群角色问题。
C.部署带有Headless服务的有状态集
注意:这部分我们会使用到kubectl服务。关于如何使用Rancher来部署kubectl服务可以参考这里:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/kubectl/。
Stateful Set Pods需要headless服务来管理Pods的网络身份。实际上,headless服务具有未定义的集群IP地址,这意味着在服务上没有定义集群IP。相反的,该服务定义具有选择器,当服务被访问的时候,DNS被配置成返回多个地址记录或者地址。此时,服务fqdn将使用相同的选择器映射到服务后面的所有pod IP的所有IP。
现在我们按照这个模板来为Cassandra创建一个Headless服务:

使用get svc命令列出cassandra服务的属性:

用describe svc可以将cassandra服务的属性按照verbose格式输出:

D.为持久卷创建存储类别
在Rancher中,通过本机的Kubernetes API资源、PersistentVolume和PersistentVolumeClaim,我们可以使用各种选项来管理持久存储。Kubernetes中的存储类别告诉了我们哪些存储类别是我们的集群所支持的。我们可以为持久存储设置动态配置来自动创建卷,并将其附加到pod。例如,下面的存储类将AWS作为它的存储提供者,使用类型是gp2,可用区是us-west-2a。

如果需要,还可以创建一个新的存储类,例如:

在创建有状态集时,将根据它的存储类为有状态集pod启动PersistentVolumeClaim。使用动态供应,可以根据PersistentVolumeClaim中请求的存储类为pod动态供应PersistentVolume。
您可也以通过静态供应手动创建持久卷。可以在这里阅读关于静态供应的更多信息:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/volumes-and-storage/。
注意:对于静态供应,要求它具有与Cassandra服务器中的Cassandra节点数量相同的持久卷数量。
E.创建有状态集
现在我们可以创建有状态集,它将提供我们想要的属性:有序的部署和终止、唯一的网络名称和有状态的处理。我们调用下面命令,启动一个Cassandra服务器:

F.验证有状态集
接着,我们调用下面命令验证是否在Cassandra服务器中部署了有状态集:

在创建了有状态集之后,DESIRED和CURRENT应该是相等的,调用get pods命令来查看经有状态集创建的pods的顺序列表。

在节点创建期间,你可以执行nodetool state来查看Cassandra节点是否启动。

G.有状态集的扩缩容
将F步骤中的设置复制x次,调用缩放命令就可以增加或者减少有状态集的大小。在下面的示例中,我们按照x=3进行操作。

调用get statefulsets可以验证是否有状态集已经部署到了Cassandra服务器上。

再次调用get pods来查看有状态集创建的pods顺序。需要注意的是,在部署Cassandra pods时,它们是按照顺序创建的。

我们可以在5分钟后执行nodetool 状态检查,验证Cassandra节点是否已经加入并且形成了一个Cassandra集群。
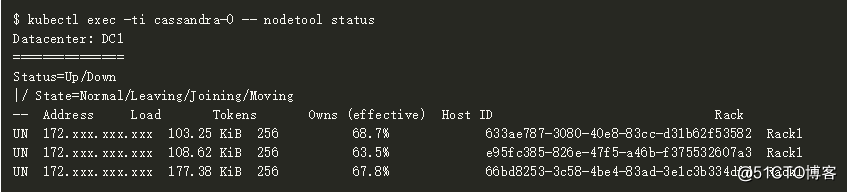
一旦nodetool中节点的状态变更为Up/Normal,我们就可以通过调用CQL来执行大量的数据库操作。
H.调用CQL进行数据库访问和操作
当我们看到状态是U/N,我们就可以调用cqlsh来访问Cassandra容器。
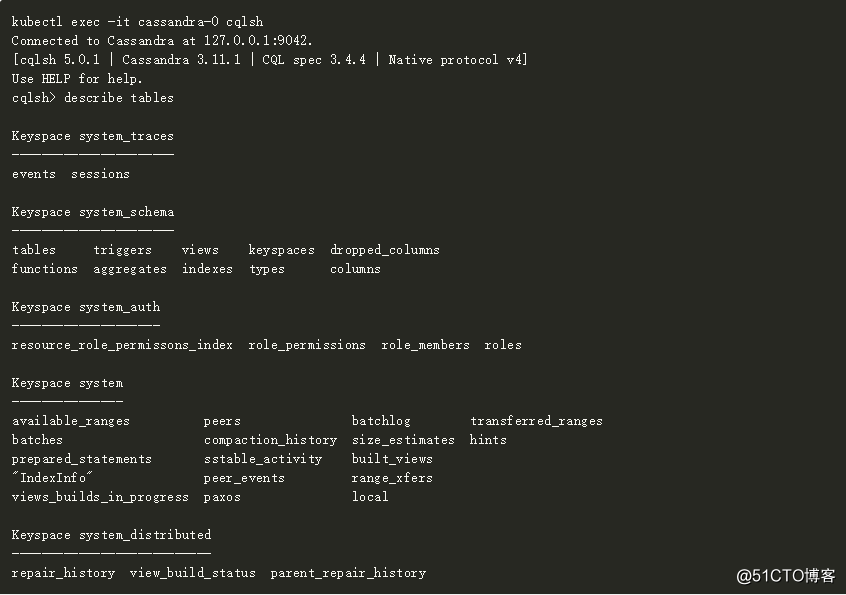
I.使用Cassandra作为高可用无状态数据库服务的持久层
在前面的练习中,我们在K8s集群中部署了一个Cassandra服务,并通过PersistentVolume提供持久存储。然后,我们使用有状态集为Cassandra集群提供有状态处理的属性,并将集群扩展到其他节点。我们现在可以在Cassandra集群中使用CQL模式进行数据库访问和操作。CQL模式的优点是,我们可以轻松地使用自然类型和流畅的api实现无缝数据建模,特别是在设计扩展和时间序列数据模型(如欺诈检测)的解决方案中。此外,CQL利用分区和集群keys来提高数据建模场景中的操作速度。
总 结
在本系列文章的下一篇中,我们将探索如何在“数据库即微服务”或无状态数据库中使用Cassandra作为持久层,利用Cassandra独特的体系结构属性并使用Rancher工具集作为起点。然后,我们将分析cassandra驱动的无状态数据库应用程序的操作性能和延迟,并评估其在设计中,边缘和云之间具有低延迟的高可用性服务的使用价值。
通过结合Cassandra和微服务架构,我们可以探索有状态集数据库的替代方案,改善内存SQL数据库(如SAP HANA)容易出现/ifor read/write事务的延迟的问题,以及HTAP工作负载和NoSQL数据库在执行需要多个表查询或复杂过滤器的高级分析时速度较慢的问题。同时,无状态体系结构可以改善数据库因为内存异常而出现的问题。这些问题都可归因于SQL数据库中内存索引和多模型NoSQL数据库中的高内存使用。有了这两个方面的改进,将可以给大规模查询和时间序列建模提供更好的操作性能。
转载于:https://blog.51cto.com/12462495/2156661
手把手教你用Rancher创建产品质量数据库设置的更多相关文章
- 手把手教你使用C#操作SQLite数据库,新建数据库,创建表,插入,查询,删除,运算符,like
目录: 一.新建项目,添加引用 二.创建数据库 三.创建表 四.插入数据 五.查询数据 六.删除数据 七.运算符 八.like语句 我的环境配置:windows 64,VS,SQLite(点击下 ...
- 手把手教你使用IDEA2020创建SpringBoot项目
一.New Project 二.如图选择Spring Initalizr,选择jdk版本,然后点击Next(注意:SpringBoot2开始至少使用JDK1.8) 三.如图根据自己需要修改,然后点击N ...
- 手把手教你用Mysql-Cluster-7.5搭建数据库集群
前言 当你的业务到达一定的当量,肯定需要一定数量的数据库来负载均衡你的数据库请求,我在之前的博客中已经说明了,如何实现负载均衡,但是还有一个问题就是数据同步,因为负载均衡的前提就是,各个服务器的数据库 ...
- 手把手教你解决无法创建 JPA 工程的问题
原创播客,如需转载请注明出处.原文地址:http://www.cnblogs.com/crawl/p/7703803.html ------------------------------------ ...
- 手把手教你通过SQL注入盗取数据库信息
目录 数据库结构 注入示例 判断共有多少字段 判断字段显示位置 显示出登录用户和数据库名 查看所有数据库 获取对应数据库的表 获取对应表的字段名称 获取用户密码 SQL注入(SQL Injection ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- 建议收藏,从零开始创建一个Activiti工作流,手把手教你完成
环境配置 项目环境: JDK1.8 tomcat7 maven3.5 开发工具: IDEA activiti7 创建项目 目标:创建一个maven项目,集成Activiti,并自动生成25张数据库表 ...
- 手把手教你做个人 app
我们都知道,开发一个app很大程度依赖服务端:服务端提供接口数据,然后我们展示:另外,开发一个app,还需要美工协助切图.没了接口,没了美工,app似乎只能做成单机版或工具类app,真的是这样的吗?先 ...
随机推荐
- 【数据库】MySQL数据库(三)
一.MySQL当中的索引: 数组当中我们见过索引:它的好处就是能够快速的通过下标.索引将一个信息查到:或者说 能够快速的定位到一个信息: 1.MySQL中的索引是什么? 它是将我们表中具有索引的那个字 ...
- 基于 Spring Cloud 的微服务架构实践指南(下)
show me the code and talk to me,做的出来更要说的明白 本文源码,请点击learnSpringCloud 我是布尔bl,你的支持是我分享的动力! 一.引入 上回 基于 S ...
- rest_framework-序列化-1
序列化 定义模型类 from django.db import models # Create your models here. class StuModel(models.Model): SEX_ ...
- easy-mock 本地部署(挤需体验三番钟,里造会干我一样,爱象节款mock)
前言 很多小伙伴问我怎么在自己公司的项目里面添加配置mock,在vue项目里面都知道怎么配置mock,在大型前端项目里面就一脸疑惑了. 我就回答他,你今天会在vue项目里面用,那天换公司是用angul ...
- 中阶 d04.1 xml解析
##XML 解析 > 其实就是获取元素里面的字符数据或者属性数据. ###XML解析方式(面试常问) > 有很多种,但是常用的有两种. * DOM * SAX ——遍历聚合对象中的元素
模式概述 模式定义 模式结构图 模式伪代码 模式改进 模式应用 模式在JDK中的应用 模式在开源项目中的应用 模式总结 说明:设计模式系列文章是读刘伟所著<设计模式的艺术之道(软件开发人员内功修 ...
- 学习Salesforce | Einstein业务机会评分怎么玩
Einstein 业务机会评分(Opportunity Scoring)是销售团队的得力助手,通过分数以及研究影响分数的因素,确定业务机会的优先级,赢得更多交易. Einstein 业务机会评分可以给 ...
- Extjs更新grid
基于Extjs4.2 原理是创建一个新的store,来覆盖原有的store. //创建数据 var newdatas = { name: "ly", age: 17, adress ...
- MySQL 归纳总结
1.MySQL存储引擎 主要使用的就是两个存储引擎,分别是InnoDB和MyISAM. InnoDB InnoDB是MySQL的默认存储引擎.InnoDB采用MVCC来支持高并发,并且实现了四个标准的 ...
- mac上搭建mysql环境配置和Navicat连接mysql
mac上搭建mysql环境配置 1.下载mysql for mac: https://downloads.mysql.com/archives/community/ 注意:mysql版本要和你的MAC ...