2019-05-19 Python之第一个爬虫和测试
一.使用request和get访问某个网页20次并且打印返回状态,内容
扩展:常见状态码含义 200 - 服务器成功返回网页,404 - 请求的网页不存在,403(禁止)服务器拒绝请求,404(未找到)服务器找不到请求的网页,503 - 服务器超时,3xx (重定向)
(1)request库简介:处理HTTP请求的第三方库,建立在urllib3库的基础上
(2)常用函数 get(url[,timeout = n ]), post
delete,head,options,put等等
(3)status_code返回状态。 text返回字符串形式。encoding返回编码方式。content返回二进制形式。注:response.text是解过码的字符串(比如html代码)。当requests发送请求到一个网页时,requests库会推测目标网页的编码,并对其解码,转为字符串(str)。这种方法比较容易出现乱码。
(4)实例代码
import requests
r = requests.get('https://www.sogou.com/', timeout = 4) #使用get方式请求搜狗网站
print("状态码 = {}".format( r.status_code))#输出状态码
print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
(5)输出结果:
状态码 = 200
。。。。。。。。。。。。。。。。省略
编码方式 = UTF-8
二进制形式 = b'<!DOCTYPE。。。。。。。。。。。。省略
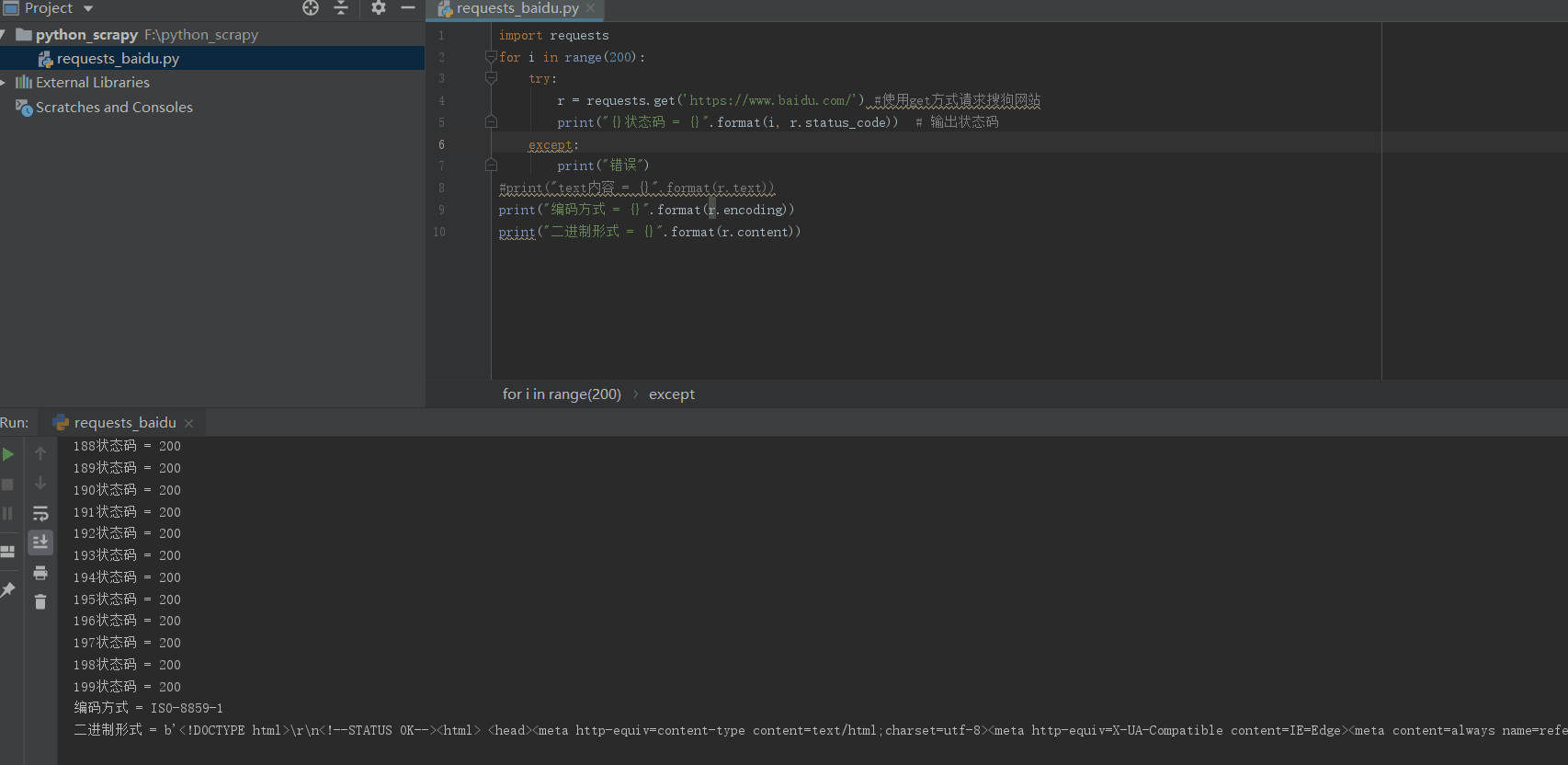
(6)测试连续访问20次的结果
import requests
for i in range(200):
r = requests.get('https://www.baidu.com/') #使用get方式请求搜狗网站
print("状态码 = {}".format(r.status_code)) # 输出状态码
#print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
二.使用beautifulsoup4解析HTML页面格式,提取有用信息
(1)beautifulsoup4库的简介:解析和处理HTML和XML
(2)常用函数head获取<head>内容,title,body,p第一个<p>内容,strings所有程序在web上的字符串,即标签的内容,stripped_strings所有呈现在web上的非空字符串
(3)示例
三.爬取中国大学排名
from bs4 import BeautifulSoup
import requests
import pandas as pd allUniv = [] def getHTMLText(url):
try:
r = requests.get(url, timeout=10)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def filUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
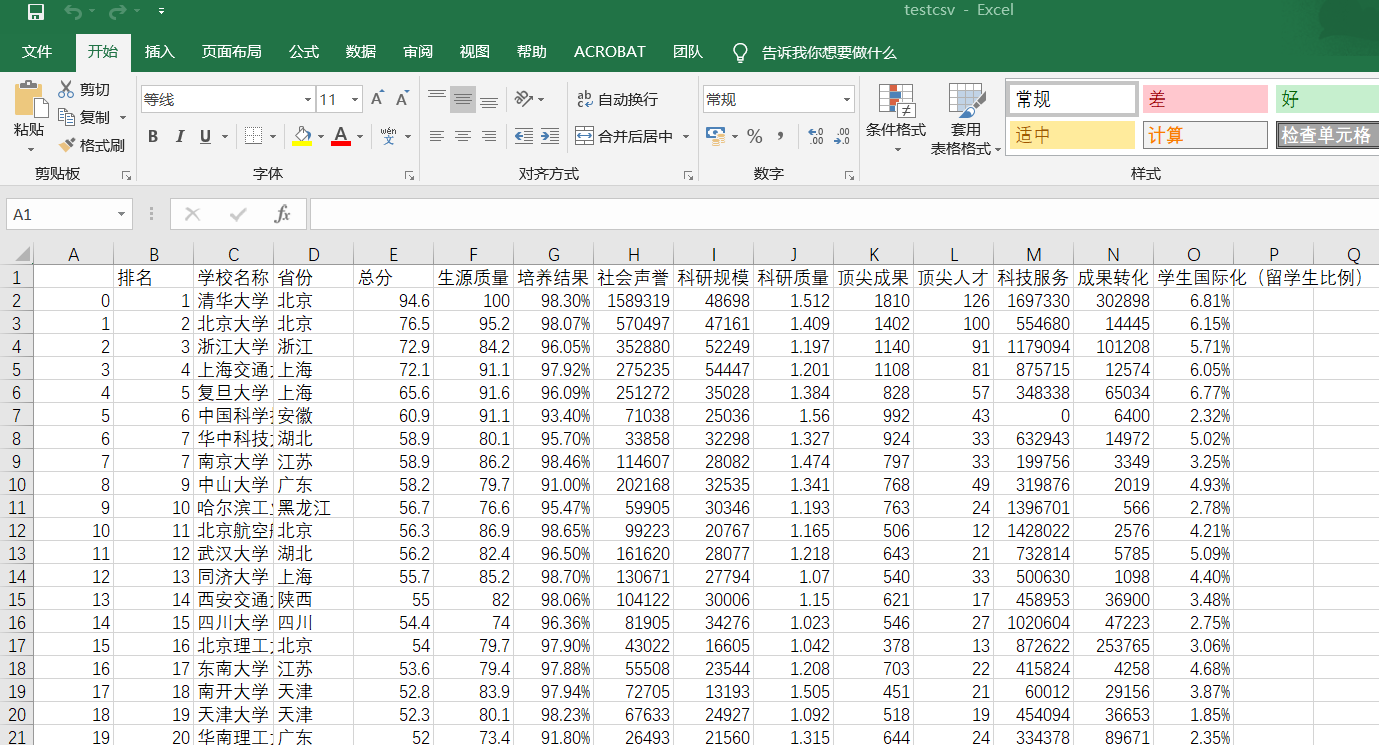
write_csv(allUniv) def write_csv(list):
name = ['排名', '学校名称', '省份', '总分', '生源质量(新生高考成绩得分)', '培养结果(毕业生就业率)', '社会声誉(社会捐赠收入·千元)', '科研规模(论文数量·篇)',\
'科研质量(论文质量·FWCI)', '顶尖成果(高被引论文·篇)', '顶尖人才(高被引学者·人)', '科技服务(企业科研经费·千元)', '成果转化(技术转让收入·千元)', '学生国际化(留学生比例)']
name2 = ['a', 'b', 'c']
test = pd.DataFrame(columns=name, data=list)
test.to_csv('e:/testcsv.csv', encoding='gbk') def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
filUnivList(soup)
print("完成") main()
效果图:
2019-05-19 Python之第一个爬虫和测试的更多相关文章
- 孤荷凌寒自学python第八十天开始写Python的第一个爬虫10
孤荷凌寒自学python第八十天开始写Python的第一个爬虫10 (完整学习过程屏幕记录视频地址在文末) 原计划今天应当可以解决读取所有页的目录并转而取出所有新闻的功能,不过由于学习时间不够,只是进 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3
孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2
孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十一天开始写Python的第一个爬虫
孤荷凌寒自学python第七十一天开始写Python的第一个爬虫 (完整学习过程屏幕记录视频地址在文末) 在了解了requests模块和BeautifulSoup模块后,今天开始真正写一个自己的爬虫代 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
随机推荐
- 菜鸟教程-python中的包
转载自:http://www.runoob.com/python/python-modules.html 包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python ...
- alsa-lib及alsa-utils成功移植(转载)
准备工作 alsa-lib版本:alsa-lib-1.0.23.tar.bz2 alsa-util版本:alsa-utils-1.0.23.tar.bz2 其他版本的alsa-lib和alsa-uti ...
- CF1327D Infinite Path 题解
原题链接 太坑了我谔谔 简要题意: 求一个排列的多少次幂能达到另一个排列.排列的幂定义见题.(其实不是新定义的,本来就是这么乘的) 很显然,这不像快速幂那样可以结合律. 既然这样,就从图入手. 将 \ ...
- 算法学习 八皇后问题的递归实现 java版 回溯思想
1.问题描述 八皇后问题是一个以国际象棋为背景的问题:如何能够在 8×8 的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行.纵行或 ...
- 数据源管理 | 主从库动态路由,AOP模式读写分离
本文源码:GitHub·点这里 || GitEE·点这里 一.多数据源应用 1.基础描述 在相对复杂的应用服务中,配置多个数据源是常见现象,例如常见的:配置主从数据库用来写数据,再配置一个从库读数据, ...
- 10.map
map Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现 . map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用. map定义 ...
- 面试官:ThreadLocal的应用场景和注意事项有哪些?
前言 ThreadLocal主要有如下2个作用 保证线程安全 在线程级别传递变量 保证线程安全 最近一个小伙伴把项目中封装的日期工具类用在多线程环境下居然出了问题,来看看怎么回事吧 日期转换的一个工具 ...
- 深入理解Java AIO(二)—— AIO源码解析
深入理解Java AIO(二)—— AIO源码解析 这篇只是个占位符,占个位置,之后再详细写(这个之后可能是永远) 所以这里只简单说一下我看了个大概的实现原理,具体的等我之后更新(可能不会更新了) 当 ...
- Python终端打印彩色文字
终端彩色文字 class Color_f: black = 30 red = 31 green = 32 yellow= 33 blue = 34 fuchsia=35 cyan = 36 white ...
- iOS 13DarkMode暗黑模式
iOS 13系统的iPhone 在设置-->显示与亮度 -->选择深色 即开启暗黑模式 1.暗黑模式关闭 1.1 APP开发未进行暗黑适配,出现顶部通知栏字体颜色无法改变始终为白色.可以全 ...