2019-05-19 Python之第一个爬虫和测试
一.使用request和get访问某个网页20次并且打印返回状态,内容
扩展:常见状态码含义 200 - 服务器成功返回网页,404 - 请求的网页不存在,403(禁止)服务器拒绝请求,404(未找到)服务器找不到请求的网页,503 - 服务器超时,3xx (重定向)
(1)request库简介:处理HTTP请求的第三方库,建立在urllib3库的基础上
(2)常用函数 get(url[,timeout = n ]), post
delete,head,options,put等等
(3)status_code返回状态。 text返回字符串形式。encoding返回编码方式。content返回二进制形式。注:response.text是解过码的字符串(比如html代码)。当requests发送请求到一个网页时,requests库会推测目标网页的编码,并对其解码,转为字符串(str)。这种方法比较容易出现乱码。
(4)实例代码
import requests
r = requests.get('https://www.sogou.com/', timeout = 4) #使用get方式请求搜狗网站
print("状态码 = {}".format( r.status_code))#输出状态码
print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
(5)输出结果:
状态码 = 200
。。。。。。。。。。。。。。。。省略
编码方式 = UTF-8
二进制形式 = b'<!DOCTYPE。。。。。。。。。。。。省略
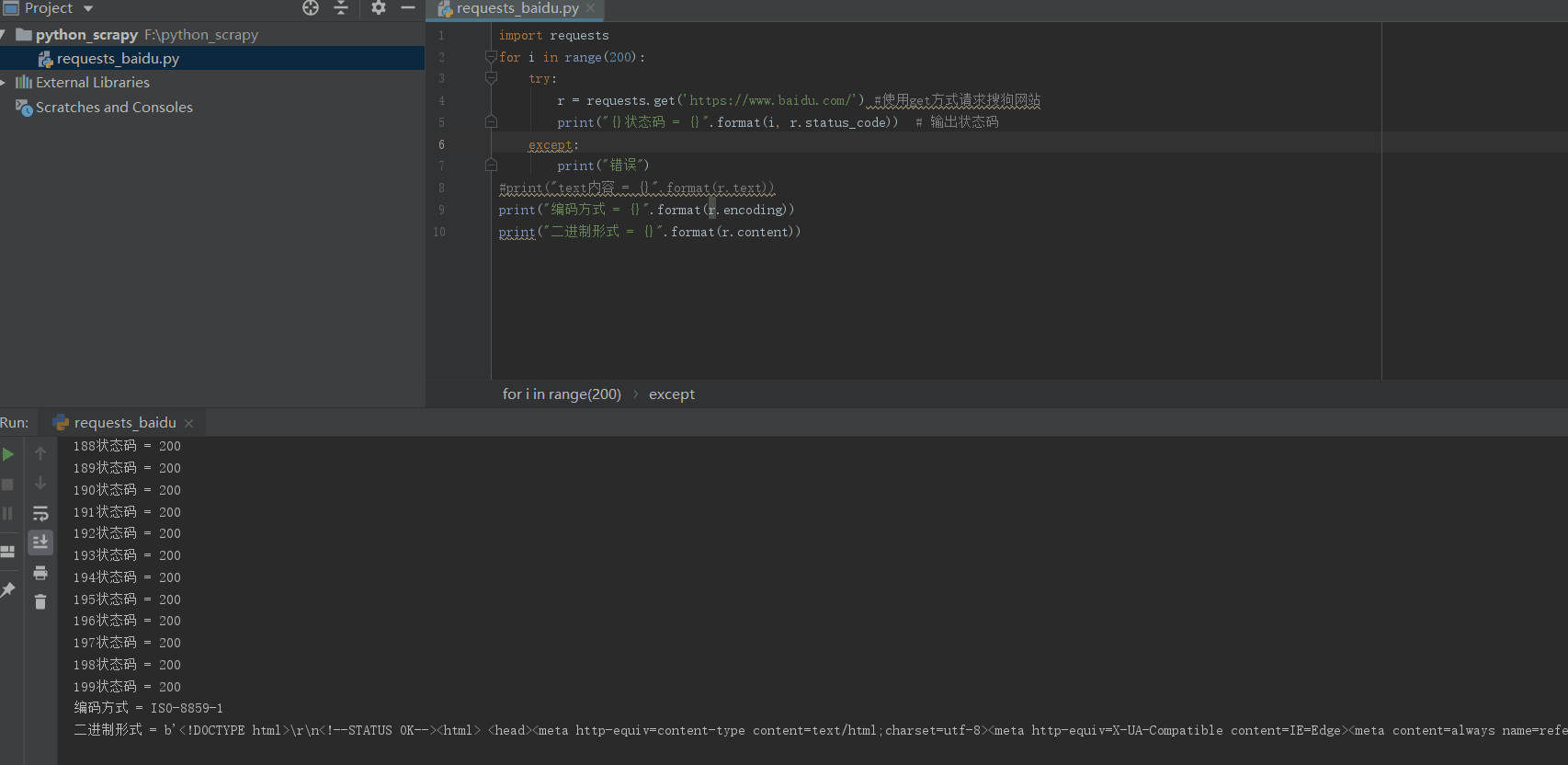
(6)测试连续访问20次的结果
import requests
for i in range(200):
r = requests.get('https://www.baidu.com/') #使用get方式请求搜狗网站
print("状态码 = {}".format(r.status_code)) # 输出状态码
#print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
二.使用beautifulsoup4解析HTML页面格式,提取有用信息
(1)beautifulsoup4库的简介:解析和处理HTML和XML
(2)常用函数head获取<head>内容,title,body,p第一个<p>内容,strings所有程序在web上的字符串,即标签的内容,stripped_strings所有呈现在web上的非空字符串
(3)示例
三.爬取中国大学排名
from bs4 import BeautifulSoup
import requests
import pandas as pd allUniv = [] def getHTMLText(url):
try:
r = requests.get(url, timeout=10)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def filUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
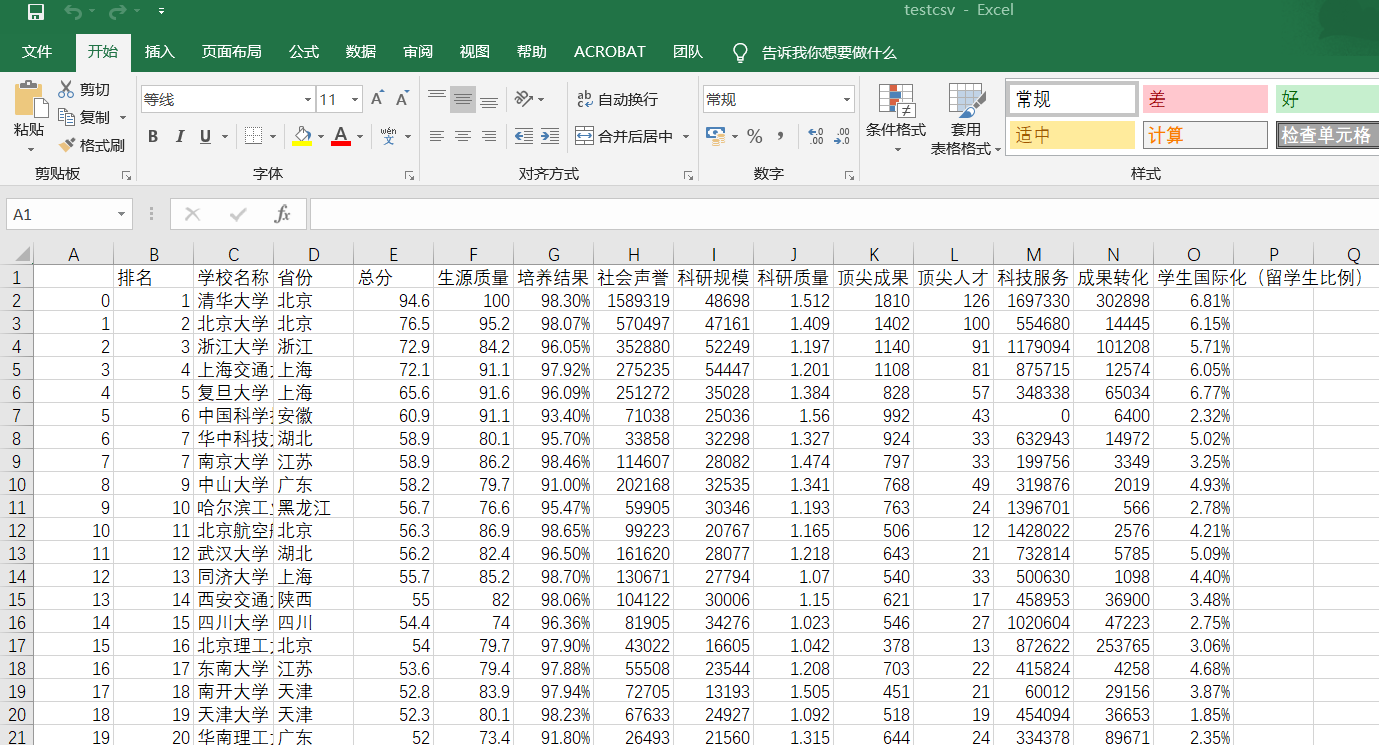
write_csv(allUniv) def write_csv(list):
name = ['排名', '学校名称', '省份', '总分', '生源质量(新生高考成绩得分)', '培养结果(毕业生就业率)', '社会声誉(社会捐赠收入·千元)', '科研规模(论文数量·篇)',\
'科研质量(论文质量·FWCI)', '顶尖成果(高被引论文·篇)', '顶尖人才(高被引学者·人)', '科技服务(企业科研经费·千元)', '成果转化(技术转让收入·千元)', '学生国际化(留学生比例)']
name2 = ['a', 'b', 'c']
test = pd.DataFrame(columns=name, data=list)
test.to_csv('e:/testcsv.csv', encoding='gbk') def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
filUnivList(soup)
print("完成") main()
效果图:
2019-05-19 Python之第一个爬虫和测试的更多相关文章
- 孤荷凌寒自学python第八十天开始写Python的第一个爬虫10
孤荷凌寒自学python第八十天开始写Python的第一个爬虫10 (完整学习过程屏幕记录视频地址在文末) 原计划今天应当可以解决读取所有页的目录并转而取出所有新闻的功能,不过由于学习时间不够,只是进 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3
孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2
孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十一天开始写Python的第一个爬虫
孤荷凌寒自学python第七十一天开始写Python的第一个爬虫 (完整学习过程屏幕记录视频地址在文末) 在了解了requests模块和BeautifulSoup模块后,今天开始真正写一个自己的爬虫代 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
随机推荐
- [BJDCTF 2nd]old-hack
进入首页: 首页告诉了我们是thinkphp5的漏洞. 知道了是哪个版本的话就搜一搜喽:最后发现是thinkphp5.0.23的命令执行 payload_1:查看根目录文件,发现flag位置 http ...
- angualrjs 总结 随记(二)
表单控制变量form 控制变量 //字段是否未更改 fromName.inputFieldName.$pristine //字段是否更改 fromName.inputFieldName.$dirty ...
- 全国职业技能大赛信息安全管理与评估-第三阶段-弱口令自动爆破+读取Flag脚本
自动爆破SSH弱口令+读取Flag #coding=utf-8 import paramiko sshc = paramiko.SSHClient() sshc.set_missing_host_ke ...
- cmdb简介
目录: 1.为啥要做cmdb
- leetcode 签到 面试题40. 最小的k个数
题目 输入整数数组 arr ,找出其中最小的 k 个数.例如,输入4.5.1.6.2.7.3.8这8个数字,则最小的4个数字是1.2.3.4. 示例 1: 输入:arr = [3,2,1], k = ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 从阿里、腾讯的面试真题中总结了这11个Redis高频面试题
前言 现在大家的工作生活基本已经是回归正轨了,最近也是迎来了跳槽面试季,有些人已经拿到了一两个offer了. 这段时间收集了阿里.腾讯.百度.京东.美团.字节跳动等公司的Java面试题,总结了Redi ...
- 纯干货 C# 通过 RFC_READ_TABLE 读取 SAP TABLE
SAP系统又称企业管理解决方案,是全球企业管理软件与解决方案的技术领袖,同时也是市场领导者.通过其应用软件.服务与支持,SAP持续不断向全球各行业企业提供全面的企业级管理软件解决方案. 在实际开发过程 ...
- 2-SAT(HDU-3062 party)
2-SAT(HDU-3062 party) 解决问题类型: 书本定义:给一个布尔方程,判断是否存在一组解使整个方程为真,被称为布尔方程可满足性问题(SAT) 因为本题只有0,1(丈夫 妻子只能去一个人 ...
- Rust入坑指南:居安思危
任何事情都是相对的,就像Rust给我们的印象一直是安全.快速,但实际上,完全的安全是不可能实现的.因此,Rust中也是会有不安全的代码的. 严格来讲,Rust语言可以分为Safe Rust和Unsaf ...