mysql索引小总结
MySql
1.索引
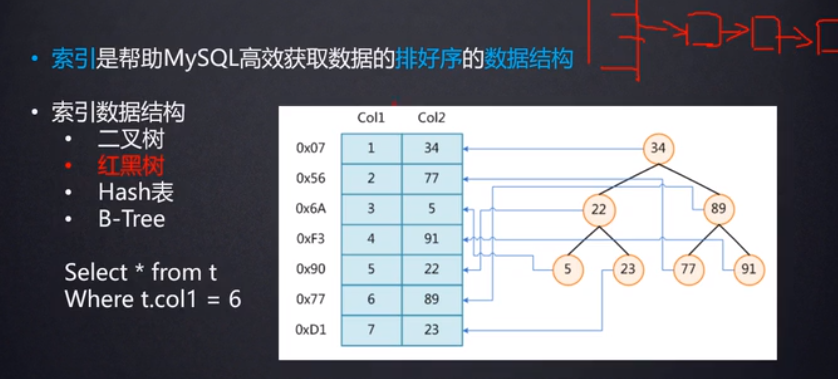
mysql索引默认使用的是B+Tree(B-树的变种版)。也可以使用HASH表。
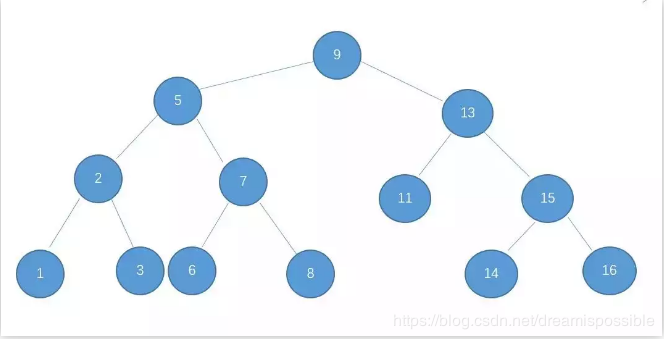
二叉树:
二叉树又称二叉搜索树,二叉排序树,特点如下:
左子树上所有结点值均小于根结点
右子树上所有结点值均大于根结点
结点的左右子树本身又是一颗二叉查找树
二叉查找树中序遍历得到结果是递增排序的结点序列
基于二叉查找树的这种特点,我们在查找某个节点的时候,可以采取类似于二分查找的思想,快速找到某个节点。n 个节点的二叉查找树,正常的情况下,查找的时间复杂度为 O(logn)
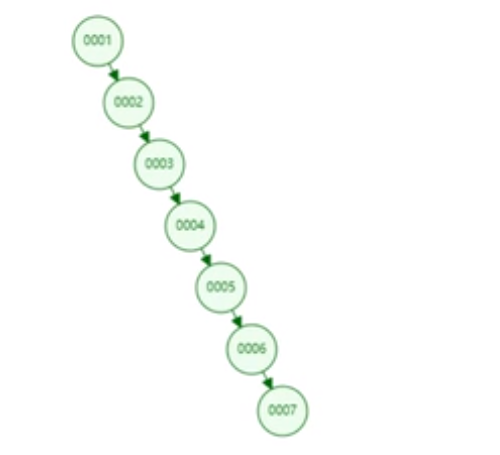
下图是二叉树的缺点:当数据是单边递增/递减 进行插入的时候,二叉查找树退化为近似链表了,这样的二叉查找树的查找时间复杂度顿时由O(logn)变成了 O(n)
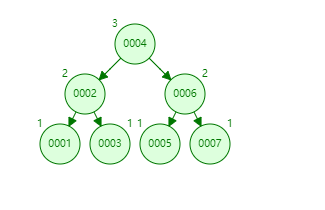
平衡二叉树(AVL二叉树):
平衡二叉树就是为了解决二叉查找树退化成一颗链表而诞生了,平衡树具有如下特点
1.具有二叉查找树的全部特性。
2.每个节点的左子树和右子树的高度差至多等于1,超过就会进行自旋进行平衡。
平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树
红黑树:
红黑树属于平衡二叉树的一种。
为什么mysql索引不使用红黑树,是因为在大数据量下,查找也是相当耗时间的。
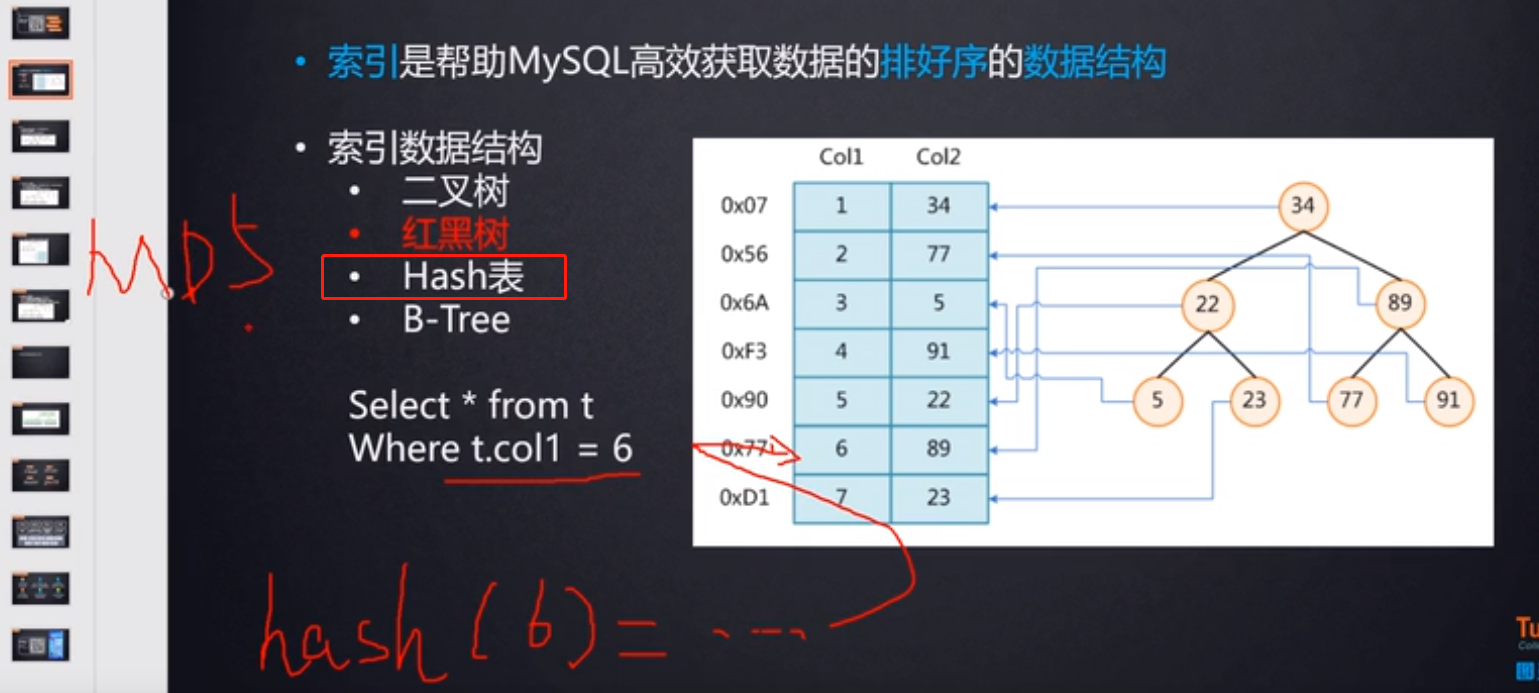
Hash表:
索引的数据结构也可以使用Hash表来实现,根据索引字段的值,比如下面图中查找col1=6的数据,是根据Hash(6)算法来得到这行数据的散列值(可以认为是这行数据再磁盘上的地址),再从磁盘中取到数据,但是如果是范围查找,比如查找col1>6的数据,对于这种范围查找,Hash表实现的索引就不太适合了。
tip:
平衡树(AVL)是为了解决 二叉查找树(BST)退化为链表的情况。
红黑树(RBT)是为了解决 平衡树 在删除等操作需要频繁调整的情况
2.B-Tree(B树)
B树叶子节点没有使用指针连接,所以对于范围查找,也不合适。

3.B+树
mysql索引数据类型默认使用B+树。
B-Tree(B树)和B+Tree(B+树)的区别:
B树的叶子节点没有使用指针连接,B+树使用双指针连接前后节点。

4.mysql存储引擎
myisam和innodb存储引擎是形容表的,每张表使用的存储引擎是可以不同的。


5.为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
第一原因:如果使用UUID这种不是自增,也不是整型的主键,查找的时候根据索引字段的值从索引树中一层层比较去查找到最终的数据,参考下面的图,根据整型主键查找要比UUID这种字符串主键查找时,比较的时候要快。
第二原因:UUID占用字节大于整型字节,消耗存储资源。

至于为什么推荐自增呢?
是因为叶子节点(最下面一行的节点),每个叶子节点的存储数量是有限的,如果使用的是自增主键,每次插入新数据的时候,都是再叶子节点的尾部进行插入。
如果使用的是UUID这种无规律的主键,新数据插入的时候,可能要插入到前面叶子节点,比如上图的20-30中间,如果此时图中20-30这个节点已经存储到了16kb(一页16k),那么就要将这个节点分裂,再进行插入,最后再将树做一次平衡。如果这样的情况,不如自增主键,每次都是尾插入,树的平衡相对稳定。
未完,待更新...
说明:博文纯属学习总结,如有理解错误偏差之处,欢迎各路大神指正。
注:本博客中如有侵权内容,请联系博主立即删除。
mysql索引小总结的更多相关文章
- 《MySQL面试小抄》索引考点一面总结
<MySQL面试小抄>索引考点一面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟 囧囧表示:面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!! ...
- 《MySQL面试小抄》索引考点二面总结
<MySQL面试小抄>索引考点二面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
随机推荐
- js时间格式转换,传入时间戳,第二哥参数是格式,也可不传
export function parseTime(time, pattern) { if (arguments.length === 0 || !time) { return null } cons ...
- Redis学习笔记(4)
一.Redis主从复制 1. 概念 为了避免服务的单点故障,会把数据复制到多个副本放在不同的服务器上,且这些拥有数据副本的服务器可以用于处理客户端的读请求,扩展整体的性能.我们把这种机制称之为主从复制 ...
- 【C++】常见易犯错误之数值类型取值溢出与截断(3)
0. 前言 本节是“[C++]常见易犯错误之数值类型取值溢出与截断(1)” 的补充,主要探讨浮点型的取值溢出. 1. 相关知识 (1) 浮点型数据取值范围如下: 单精度型 float 3.4 * 1 ...
- [JavaWeb基础] 003.JAVA访问Mysql数据库
上面两篇讲解了简单的JSP + Servlet的搭建和请求,那么后面我们肯定要用到数据交互,也就是操纵数据库的数据,包括对数字的增加,删除,修改,查询.我们就用简单的MySql来做例子 我们需要引入驱 ...
- Robot Framework(15)- 扩展关键字
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html 前言 什么是扩展 ...
- [apue] 一个工业级、跨平台的 tcp 网络服务框架:gevent
作为公司的公共产品,经常有这样的需求:就是新建一个本地服务,产品线作为客户端通过 tcp 接入本地服务,来获取想要的业务能力. 与印象中动辄处理成千上万连接的 tcp 网络服务不同,这个本地服务是跑在 ...
- 被缠上了,小王问我怎么在 Spring Boot 中使用 JDBC 连接 MySQL
上次帮小王入了 Spring Boot 的门后,他觉得我这个人和蔼可亲.平易近人,于是隔天小王又微信我说:"二哥,快教教我,怎么在 Spring Boot 项目中使用 JDBC 连接 MyS ...
- Rocket - util - HeterogeneousBag
https://mp.weixin.qq.com/s/5hNM4yeQjaLvAJzgMG9PGQ 介绍HeterogeneousBag的实现. 1. 基本介绍 一个口袋(bag ...
- Chisel3 - model - Builder
https://mp.weixin.qq.com/s/THqyhoLbbuXXAtdQXRQDdA 介绍构建硬件模型的Builder. 1. DynamicContext 动态上下文 ...
- JAVASE(十三) 异常处理
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.异常体系结构 说明: |-----Throwable |-----Error :没针对性代码进行 ...