mysql索引小总结
MySql
1.索引
mysql索引默认使用的是B+Tree(B-树的变种版)。也可以使用HASH表。
二叉树:
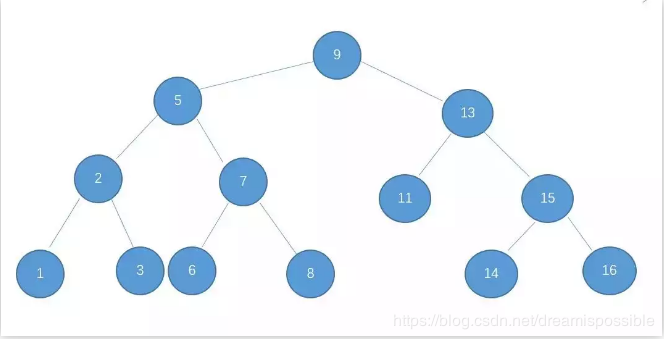
二叉树又称二叉搜索树,二叉排序树,特点如下:
左子树上所有结点值均小于根结点
右子树上所有结点值均大于根结点
结点的左右子树本身又是一颗二叉查找树
二叉查找树中序遍历得到结果是递增排序的结点序列
基于二叉查找树的这种特点,我们在查找某个节点的时候,可以采取类似于二分查找的思想,快速找到某个节点。n 个节点的二叉查找树,正常的情况下,查找的时间复杂度为 O(logn)
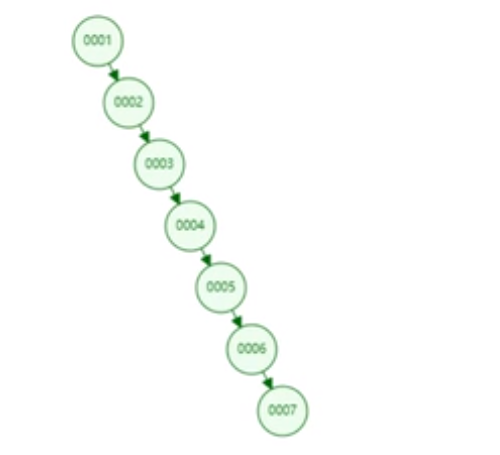
下图是二叉树的缺点:当数据是单边递增/递减 进行插入的时候,二叉查找树退化为近似链表了,这样的二叉查找树的查找时间复杂度顿时由O(logn)变成了 O(n)
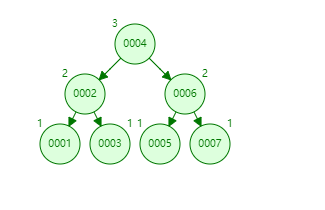
平衡二叉树(AVL二叉树):
平衡二叉树就是为了解决二叉查找树退化成一颗链表而诞生了,平衡树具有如下特点
1.具有二叉查找树的全部特性。
2.每个节点的左子树和右子树的高度差至多等于1,超过就会进行自旋进行平衡。
平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树
红黑树:
红黑树属于平衡二叉树的一种。
为什么mysql索引不使用红黑树,是因为在大数据量下,查找也是相当耗时间的。
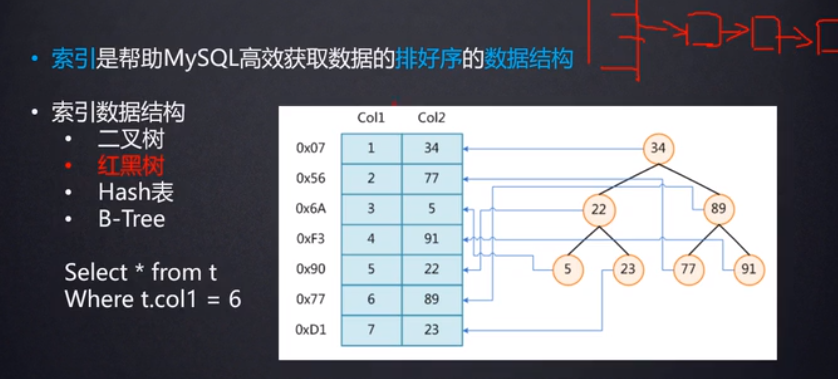
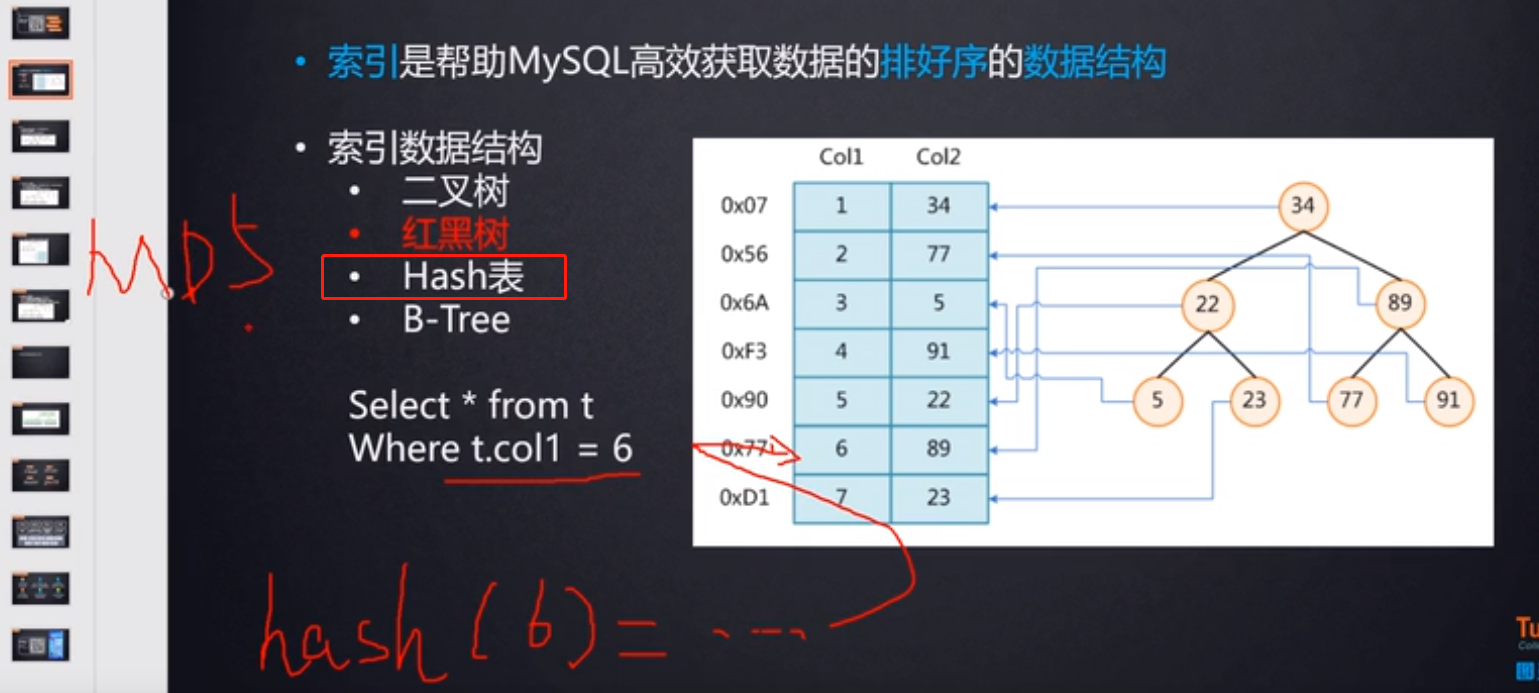
Hash表:
索引的数据结构也可以使用Hash表来实现,根据索引字段的值,比如下面图中查找col1=6的数据,是根据Hash(6)算法来得到这行数据的散列值(可以认为是这行数据再磁盘上的地址),再从磁盘中取到数据,但是如果是范围查找,比如查找col1>6的数据,对于这种范围查找,Hash表实现的索引就不太适合了。
tip:
平衡树(AVL)是为了解决 二叉查找树(BST)退化为链表的情况。
红黑树(RBT)是为了解决 平衡树 在删除等操作需要频繁调整的情况
2.B-Tree(B树)
B树叶子节点没有使用指针连接,所以对于范围查找,也不合适。

3.B+树
mysql索引数据类型默认使用B+树。
B-Tree(B树)和B+Tree(B+树)的区别:
B树的叶子节点没有使用指针连接,B+树使用双指针连接前后节点。

4.mysql存储引擎
myisam和innodb存储引擎是形容表的,每张表使用的存储引擎是可以不同的。


5.为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
第一原因:如果使用UUID这种不是自增,也不是整型的主键,查找的时候根据索引字段的值从索引树中一层层比较去查找到最终的数据,参考下面的图,根据整型主键查找要比UUID这种字符串主键查找时,比较的时候要快。
第二原因:UUID占用字节大于整型字节,消耗存储资源。

至于为什么推荐自增呢?
是因为叶子节点(最下面一行的节点),每个叶子节点的存储数量是有限的,如果使用的是自增主键,每次插入新数据的时候,都是再叶子节点的尾部进行插入。
如果使用的是UUID这种无规律的主键,新数据插入的时候,可能要插入到前面叶子节点,比如上图的20-30中间,如果此时图中20-30这个节点已经存储到了16kb(一页16k),那么就要将这个节点分裂,再进行插入,最后再将树做一次平衡。如果这样的情况,不如自增主键,每次都是尾插入,树的平衡相对稳定。
未完,待更新...
说明:博文纯属学习总结,如有理解错误偏差之处,欢迎各路大神指正。
注:本博客中如有侵权内容,请联系博主立即删除。
mysql索引小总结的更多相关文章
- 《MySQL面试小抄》索引考点一面总结
<MySQL面试小抄>索引考点一面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟 囧囧表示:面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点!!! ...
- 《MySQL面试小抄》索引考点二面总结
<MySQL面试小抄>索引考点二面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
随机推荐
- PHP 面向对象的数据库操作
一.面向对象 fetch_all() 抓取所有的结果行并且以关联数据,数值索引数组,或者两者皆有的方式返回结果集. fetch_array() 以一个关联数组,数值索引数组,或者两者皆有的方式抓取一行 ...
- net core获取appsetting.json的另外一种思路(全局,实时变化无需重启项目)
最近在写net core的项目,在非controller和service里面需要用到appsetting.json文件里面的一些配置,查资料大概有几种思路: 注入,然后config.GetSectio ...
- UIAutomator2的API文档(三)
1.UI对象识别器Selector 用法d(text='Clock', className='android.widget.TextView') 支持以下参数,详细信息可参考UiSelector Ja ...
- 剑指Offer之跳台阶
题目描述 一只青蛙一次可以跳上1级台阶,也可以跳上2级.求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果). 解法1:递归解法 public int JumpFloor(int t ...
- 基于Hadoop不同版本搭建hive集群(附配置文件)
本教程采用了两种方案 一种是hive-1.21版本,hadoop版本为hadoop2.6.5 还有一种是主要讲基于hadoop3.x hive的搭建 先来第一种 一.本地方式(内嵌derby) 步骤 ...
- 【C++】赋值过程中类型转换
注意:以下内容摘自文献[1],修改了部分内容. 1.赋值过程中的类型转换 如果赋值运算符两侧的类型不一致,但都是数值型或字符型时,在赋值时自动进行类型转换. (1) 将浮点型数据(包括单.双精度)赋给 ...
- 读了这一篇,让你少踩 ArrayList 的那些坑
我是风筝,公众号「古时的风筝」,一个不只有技术的技术公众号,一个在程序圈混迹多年,主业 Java,另外 Python.React 也玩儿的 6 的斜杠开发者. Spring Cloud 系列文章已经完 ...
- [Firefox附加组件]0001.入门
Firefox 火狐浏览器,拥有最快.最安全的上网体验,并且火狐拥有超过一万个的 扩展(add-ons),提供各种不同的扩展功能,您可以简单的下载.安装这些扩展以增强您的火狐功能,帮助您更好.更个性化 ...
- & 异步使用场景
异步的使用场景: 1.不涉及共享资源,或对共享资源只读,即非互斥操作 2.没有时序上的严格关系 3.不需要原子操作,或可以通过其他方式控制原子性 4.常用于IO操作等耗时操作,因为比较影响客户体验和使 ...
- Rocket - regmapper - RegisterCrossing
https://mp.weixin.qq.com/s/82iLT-fmDg9Comp2p9bxKg 简单介绍RegisterCrossing的实现. 1. BusyRegisterCrossing 简 ...