RDD原理与详解
RDD详解
原文连接 http://xiguada.org/spark_rdd/
RDD(Resilient Distributed Datasets弹性分布式数据集),是spark中最重要的概念,可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。当然,RDD肯定不会这么简单,它的功能还包括容错、集合内的数据可以并行处理等。图1是RDD类的视图。
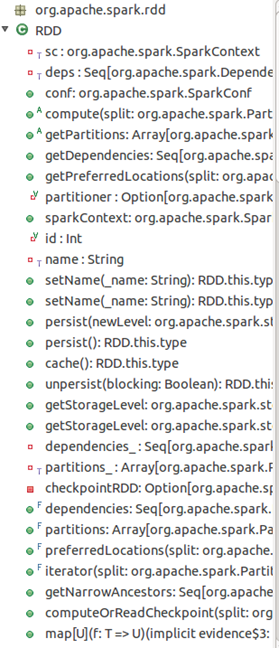
图1
一个简单的例子
下面是一个实用scala语言编写的spark应用(摘自Apache Spark 社区https://spark.apache.org/docs/latest/quick-start.html)。
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application") //设置程序名字
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache() //加载文件为RDD,并缓存
val numAs = logData.filter(line => line.contains("a")).count()//包含a的行数
val numBs = logData.filter(line => line.contains("b")).count()//包含b的行数
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
这个程序只是简单的对输入文件README.md包含'a'和'b'的行分别计数。当然如果你想运行这个程序,需要把YOUR_SPARK_HOME替换为Spark的安装目录。程序中定义了一个RDD:logData,并调用cache,把RDD数据缓存在内存中,这样能防止重复加载文件。filter是RDD提供的一种操作,它能过滤出符合条件的数据,count是RDD提供的另一个操作,它能返回RDD数据集中的记录条数。
RDD操作类型
上述例子介绍了两种RDD的操作:filter与count;事实上,RDD还提供了许多操作方法,如map,groupByKey,reduce等操作。RDD的操作类型分为两类,转换(transformations),它将根据原有的RDD创建一个新的RDD;行动(actions),对RDD操作后把结果返回给driver。例如,map是一个转换,它把数据集中的每个元素经过一个方法处理后返回一个新的RDD;而reduce则是一个action,它收集RDD的所有数据后经过一些方法的处理,最后把结果返回给driver。
RDD的所有转换操作都是lazy模式,即Spark不会立刻计算结果,而只是简单的记住所有对数据集的转换操作。这些转换只有遇到action操作的时候才会开始计算。这样的设计使得Spark更加的高效,例如,对一个输入数据做一次map操作后进行reduce操作,只有reduce的结果返回给driver,而不是把数据量更大的map操作后的数据集传递给driver。
下面分别是transformations和action类型的操作。
Transformations类型的操作

Action类型的操作

更多RDD的操作描述和编程方法请参考社区文档:https://spark.apache.org/docs/latest/programming-guide.html。
RDD底层实现原理
RDD是一个分布式数据集,顾名思义,其数据应该分部存储于多台机器上。事实上,每个RDD的数据都以Block的形式存储于多台机器上,下图是Spark的RDD存储架构图,其中每个Executor会启动一个BlockManagerSlave,并管理一部分Block;而Block的元数据由Driver节点的BlockManagerMaster保存。BlockManagerSlave生成Block后向BlockManagerMaster注册该Block,BlockManagerMaster管理RDD与Block的关系,当RDD不再需要存储的时候,将向BlockManagerSlave发送指令删除相应的Block。

图2 RDD存储原理
RDD cache的原理
RDD的转换过程中,并不是每个RDD都会存储,如果某个RDD会被重复使用,或者计算其代价很高,那么可以通过显示调用RDD提供的cache()方法,把该RDD存储下来。那RDD的cache是如何实现的呢?
RDD中提供的cache()方法只是简单的把该RDD放到cache列表中。当RDD的iterator被调用时,通过CacheManager把RDD计算出来,并存储到BlockManager中,下次获取该RDD的数据时便可直接通过CacheManager从BlockManager读出。
RDD dependency与DAG
RDD提供了许多转换操作,每个转换操作都会生成新的RDD,这是新的RDD便依赖于原有的RDD,这种RDD之间的依赖关系最终形成了DAG(Directed Acyclic Graph)。
RDD之间的依赖关系分为两种,分别是NarrowDependency与ShuffleDependency,其中ShuffleDependency为子RDD的每个Partition都依赖于父RDD的所有Partition,而NarrowDependency则只依赖一个或部分的Partition。下图的groupBy与join操作是ShuffleDependency,map和union是NarrowDependency。

图3 RDD dependency
RDD partitioner与并行度
每个RDD都有Partitioner属性,它决定了该RDD如何分区,当然Partition的个数还将决定每个Stage的Task个数。当前Spark需要应用设置Stage的并行Task个数(配置项为:spark.default.parallelism),在未设置的情况下,子RDD会根据父RDD的Partition决定,如map操作下子RDD的Partition与父Partition完全一致,Union操作时子RDD的Partition个数为父Partition个数之和。
如何设置spark.default.parallelism对用户是一个挑战,它会很大程度上决定Spark程序的性能。
RDD原理与详解的更多相关文章
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- HashMap实现原理分析(详解)
1. HashMap的数据结构 http://blog.csdn.net/gaopu12345/article/details/50831631 ??看一下 数据结构中有数组和链表来实现对数据的存 ...
- [GO语言的并发之道] Goroutine调度原理&Channel详解
并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题:Go语言作为一个出道以来就自带 『高并发』光环的富二代编程语言,它的并发(并行)编程肯定是值得开发者去探究的,而Go ...
- iOS---NSAutoreleasePool自动释放原理及详解
前言:当您向一个对象发送一个autorelease消息时,Cocoa就会将该对象的一个引用放入到最新的自动释放池.它仍然是个正当的对象,因此自动释放池 定义的作用域内的其它对象可以向它发送消息.当程序 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- python描述符(descriptor)、属性(property)、函数(类)装饰器(decorator )原理实例详解
1.前言 Python的描述符是接触到Python核心编程中一个比较难以理解的内容,自己在学习的过程中也遇到过很多的疑惑,通过google和阅读源码,现将自己的理解和心得记录下来,也为正在为了该问题 ...
- LVS-DR工作原理图文详解
为了阐述方便,我根据官方原理图另外制作了一幅图,如下图所示:VS/DR的体系结构: 我将结合这幅原理图及具体的实例来讲解一下LVS-DR的原理,包括数据包.数据帧的走向和转换过程. 官方的原理说明:D ...
- React Native 入门到原理(详解)
抛砖引玉(帮你更好的去理解怎么产生的 能做什么) 砖一.动态配置 由于 AppStore 审核周期的限制,如何动态的更改 app 成为了永恒的话题.无论采用何种方式,我们的流程总是可以归结为以下三部曲 ...
随机推荐
- 调用git命令行执行更新的思路
cd /usr/local/software/CloudPlatformUtil/GitLab # CentOS6.5自带的git版本是1.7.1 # 安装高版本git wget -O git.zip ...
- 画图工具除了echarts我使用highcharts
文件 :密码:xewx 官方文档教程地址:https://www.hcharts.cn/docs/basic-color 上手容易,api友好,尽管也有不尽人意的地方,但是它很适合我当前的项目,如果想 ...
- hdu 5117 数学公式展开 + dp
题目大意:有n个灯泡,m个按钮,(1 <= n, m <= 50),每个按钮和ki 个灯泡相关, 按下后,转换这些灯泡的状态,问你所有2^m的按下按钮的 组合中亮着的灯泡的数量的三次方的和 ...
- Vue生命周期总结
查看生命周期图 <!DOCTYPE html> <html> <head> <title></title> <meta http-eq ...
- oracle常用函数整理
oracle常用函数整理 1.绝对值.取余.判断数值正负函数 绝对值:ABS(n) 示例: SELECT ABS(100),ABS(-100),ABS('100') FROM ...
- mac MyEclipse2017 CI10安装破解心得
前段时间也不知弄了什么东西把之前的me弄坏了,于是看看新版本的情况,准备安装个新版本,一看出了ci10,安装之. 破解资源请到这里下载 https://download.csdn.net/downlo ...
- 洛谷——P2384 最短路
P2384 最短路 题目背景 狗哥做烂了最短路,突然机智的考了Bosh一道,没想到把Bosh考住了...你能帮Bosh解决吗? 他会给你10000000000000000000000000000000 ...
- 求高精度幂(poj1001)
Description Problems involving the computation of exact values of very large magnitude and precision ...
- 利用FusionCharts制作统计报表
今天在开发中需要用到统计报表,于是就查找了一下FusionCharts的用法,下面来总结一下利用FusionCharts怎么制作统计报表 1.建表 首先要建立所要统计报表的表,表的字段越多,统计的维度 ...
- 【枚举】【最小表示法】XVII Open Cup named after E.V. Pankratiev Stage 14, Grand Prix of Tatarstan, Sunday, April 2, 2017 Problem F. Matrix Game
给你一个n*m的字符矩阵,将横向(或纵向)全部裂开,然后以任意顺序首尾相接,然后再从中间任意位置切开,问你能构成的字典序最大的字符串. 以横向切开为例,纵向类似. 将所有横排从大到小排序,枚举最后切开 ...