搭建Hadoop2.6.0+Spark1.1.0集群环境
前几篇文章主要介绍了单机模式的hadoop和spark的安装和配置,方便开发和调试。本文主要介绍,真正集群环境下hadoop和spark的安装和使用。
1. 环境准备
集群有三台机器:
master:W118PC01VM01/192.168.0.112
slave1:W118PC02VM01/192.168.0.113
slave2:W118PC03VM01/192.168.0.114
首先配置/etc/hosts中ip和主机名的映射关系:
|
192.168.0.112 W118PC01VM01 192.168.0.113 W118PC02VM01 192.168.0.114 W118PC03VM01 |
其次配置3台机器互相免密码ssh连接,参考《在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境》。
2. 基本安装步骤
(1) 安装Java(本例使用jdk1.7.0_55)和Scala(使用scala2.10.4)。
(2) 安装Hadoop2.6.0集群。
(3) 安装Spark1.1.0集群。
3. Jdk和Scala安装
在master和slave机器的安装路径和环境变量配置保持一致。安装过程参考《在Win7虚拟机下搭建Hadoop2.6.0+Spark1.4.0单机环境》。
4. Hadoop集群安装
4.1. 安装Hadoop并配置环境变量
安装Hadoop2.6.0版本,安装目录如下。在~/.bash_profile中配置环境变量,参考《在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境》。
4.2. 修改Hadoop配置文件
涉及到的hadoop配置文件主要有以下7个:
|
/home/ap/cdahdp/tools/hadoop/etc/hadoop/hadoop-env.sh /home/ap/cdahdp/tools/hadoop/etc/hadoop/yarn-env.sh /home/ap/cdahdp/tools/Hadoop/etc/hadoop/slaves /home/ap/cdahdp/tools/hadoop/etc/hadoop/core-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/hdfs-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/mapred-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/yarn-site.xml |
配置 hadoop-env.sh(修改JAVA_HOME)
|
# The java implementation to use. export JAVA_HOME=/home/ap/cdahdp/tools/jdk1.7.0_55 |
配置 yarn-env.sh (修改JAVA_HOME)
|
# some Java parameters export JAVA_HOME=/home/ap/cdahdp/tools/jdk1.7.0_55 |
配置slaves(增加slave节点)
|
W118PC02VM01 W118PC03VM01 |
配置 core-site.xml(增加hadoop核心配置)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.112:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/ap/cdahdp/app/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml(增加hdfs配置信息,namenode、datanode端口和目录位置)
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.0.112:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/ap/cdahdp/app/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/ap/cdahdp/app/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>【配置磁盘中保留不用作hdfs集群的空间大小,单位是Byte】
<value>10240000000</value>
</property>
</configuration>
配置mapred-site.xml(增加mapreduce配置,使用yarn框架、jobhistory地址以及web地址)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.112:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.112:19888</value>
</property>
</configuration>
配置 yarn-site.xml(增加yarn功能)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.112:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.112:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.112:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.112:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.112:8088</value>
</property>
</configuration>
将配置好的hadoop文件copy到两台slave机器上,配置和路径和master一模一样。
4.3. 格式化namenode
在master和slave机器上分别操作:
|
cd ~/tools/hadoop/bin ./hdfs namenode -format |
4.4. 启停hdfs和yarn
|
cd ~/tools/hadoop/sbin ./start-hdfs.sh ./stop-hdfs.sh ./start-yarn.sh ./stop-yarn.sh |
启动后可以用jps查看进程,通常有这几个:
NameNode、SecondaryNameNode、ResourceManager、DataNode
如果启动异常,可以查看日志,在master机器的/home/ap/cdahdp/tools/hadoop/logs目录。
4.5. 查看集群状态
查看hdfs:http://192.168.0.112:50070/
查看RM:http://192.168.0.112:8088/
4.6. 运行wordcount示例程序
上传几个文本文件到hdfs,路径为/tmp/input/
之后运行:
查看执行结果:

正常运行,表示hadoop集群安装成功。
5. Spark集群部署
5.1. 安装Spark并配置环境变量
安装Spark1.1.0版本,安装目录如下。在~/.bash_profile中配置环境变量。
5.2. 修改Hadoop配置文件
配置slaves(增加slave节点)

配置spark-env.sh(设置spark运行的环境变量)
把spark-env.sh.template复制为spark-env.sh

将配置好的spark文件copy到两台slave机器上,配置和路径和master一模一样。
5.3. Spark的启停
|
cd ~/tools/spark/sbin ./start-all.sh ./stop-all.sh |
5.4. 查看集群状态
spark集群的web管理页面:http://192.168.0.112:8080/
spark WEBUI页面:http://192.168.0.112:4040/
启动spark-shell控制台:
5.5. 运行示例程序
往hdfs上上传一个文本文件README.txt:
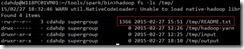
在spark-shell控制台执行:
统计README.txt中有多少单词:

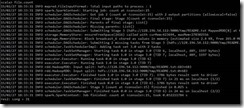
过滤README.txt包括The单词有多少行:
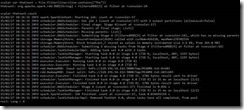
正常运行,表示Spark集群安装成功。
搭建Hadoop2.6.0+Spark1.1.0集群环境的更多相关文章
- Kubernetes的搭建与配置(一):集群环境搭建
1.环境介绍及准备: 1.1 物理机操作系统 物理机操作系统采用Centos7.3 64位,细节如下. [root@localhost ~]# uname -a Linux localhost.loc ...
- 搭建 MongoDB分片(sharding) / 分区 / 集群环境
1. 安装 MongoDB 三台机器 关闭防火墙 systemctl stop firewalld.service 192.168.252.121 192.168.252.122 192.168.25 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- 不卸载ceph重新获取一个干净的集群环境
不卸载ceph重新获取一个干净的集群环境 标签(空格分隔): ceph ceph环境搭建 运维 部署了一个ceph集群环境,由于种种原因需要回到最开始完全clean的状态,而又不想卸载ceph客户端或 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 分享一份关于Hadoop2.2.0集群环境搭建文档
目录 一,准备环境 三,克隆VM 四,搭建集群 五,Hadoop启动与测试 六,安装过程中遇到的问题及其解决方案 一,准备环境 PC基本配置如下: 处理器:Intel(R) Core(TM) i5-3 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(七)针对hadoop2.9.0启动DataManager失败问题
DataManager启动失败 启动过程中发现一个问题:slave1,slave2,slave3都是只启动了DataNode,而DataManager并没有启动: [spark@slave1 hado ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- js-js和HTML的两种结合方式
第一种: - 使用一个标签 <script type="text/javascript"> js代码; </script> 第二种: - 使用script标 ...
- Python-约束和异常处理
今天我们来说一说类的规范以及程序出现错误后我们要怎么进行处理 一.类的约束 首先,你要清楚,约束是对类的约束,比如,现在你是一个项目经理,然后呢,你给手下的人分活,张三你处理一下普通用户登录,李四你处 ...
- web前端优化之内容优化
前端内容优化主要有以下几条: 1.尽量减少http请求 (1)合并文件,把多个css文件合并在一起: (2)css Sprites,把css相关的background元素进行背景图绝对定位: (3)图 ...
- 按需引入antd
使用create-react-app创建项目的时候,官网推荐使用 babel-plugin-import 对antd 按需引入文件.但是配置文件在项目里没有. 可以直接在package.json里加上 ...
- .NET开源工作流RoadFlow-Bug修改-1.8.2表单验证时ueditor编辑非空验证无效
RoadFlow生成的表单,Ueditor编辑器不能进行非空验证的BUG修改: 1.修改控制器:WorkFlowFormDesignerController红框处: 2.修改js文件:Scripts/ ...
- nginx 两台机器 出现退款失败问题
今天早上来公司后,测试人员告诉我 退款失败了.上周五还好好的,怎么这周三就出问题了,赶快让测试发来订单号,查询数据库,查询日志,发现还是以前的问题: search hit TOP, continuin ...
- ArcGIS 10.1 如何连接数据库(转)
原文地址:http://blog.csdn.net/arcgis_cs/article/details/7750893 ArcGIS 10.1如何连接数据库 最近在使用ArcGIS 10.1的数据库, ...
- Tomcat你很少使用的安全管理SecurityManager
试想一下,如果你的JSP页面中包含一句代码“System.exit(1);”,你的web应用访问到该JSP时,会发生什么? 一般使用tomcat可能都没有注意到这个问题,本篇主要讲述tomcat 6中 ...
- ubuntu 16.04 virtualbox could not insert 'vboxdrv': Required key not available 问题解决方法
从 内核版本 4.4.0-20 开始,在开启了 Secure Boot 的电脑上,未注册的 kernel 模块不再允许执行,所以如果想在保持 Secure Boot 的情况下依然允许执行,我们需要做的 ...
- February 1 2017 Week 5 Wednesday
If you can't get a miracle, become one. 如果奇迹没有眷顾你,那就让自己变成奇迹吧. If you think you are bad luck, you did ...