Llama2-Chinese项目:2.2-大语言模型词表扩充
因为原生LLaMA对中文的支持很弱,一个中文汉子往往被切分成多个token,因此需要对其进行中文词表扩展。思路通常是在中文语料库上训练一个中文tokenizer模型,然后将中文tokenizer与LLaMA原生tokenizer进行合并,最终得到一个扩展后的tokenizer模型。国内Chinese-LLaMA-Alpaca开源项目详细说明了词表扩展[2]。
一.对LLaMA tokenizer扩充自定义的词表
原版LLaMA模型的词表大小是32K,其主要针对英语进行训练,下面对其扩充20K中文词表,如下所示:
python merge_tokenizers.py \
--llama_tokenizer_dir r'L:/20230902_Llama1/llama-7b-hf' \
--chinese_sp_model_file r'./chinese_sp.model'
- llama_tokenizer_dir:指向存放原版LLaMA tokenizer的目录
- chinese_sp_model_file:指向用sentencepiece训练的中文词表文件
说明:在中文通用语料上训练的20K中文词表下载链接参考[3],如何构建垂直领域的中文词表下次分享。
二.merge_tokenizers.py注释
1.本文环境
本文环境为Windows10,Python3.10,CUDA 11.8,GTX 3090(24G),内存24G。
2.merge_tokenizers.py代码
import os
from transformers import LlamaTokenizer
from sentencepiece import sentencepiece_model_pb2 as sp_pb2_model
import sentencepiece as spm
import argparse
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "python"
# parser = argparse.ArgumentParser() # 创建一个ArgumentParser对象
# parser.add_argument('--llama_tokenizer_dir', default=r'L:/20230902_Llama1/llama-7b-hf', type=str, required=True) # 添加参数
# parser.add_argument('--chinese_sp_model_file', default='./chinese_sp.model', type=str) # 添加参数
# args = parser.parse_args() # 解析参数
# llama_tokenizer_dir = args.llama_tokenizer_dir # 这里是LLaMA tokenizer的路径
# chinese_sp_model_file = args.chinese_sp_model_file # 这里是Chinese tokenizer的路径
llama_tokenizer_dir = r'L:/20230902_Llama1/llama-7b-hf' # 这里是LLaMA tokenizer的路径
chinese_sp_model_file = r'./chinese_sp.model' # 这里是Chinese tokenizer的路径
# 加载tokenizer
llama_tokenizer = LlamaTokenizer.from_pretrained(llama_tokenizer_dir) # 加载LLaMA tokenizer
chinese_sp_model = spm.SentencePieceProcessor() # 定义Chinese tokenizer
chinese_sp_model.Load(chinese_sp_model_file) # 加载Chinese tokenizer
llama_spm = sp_pb2_model.ModelProto() # 定义LLaMA tokenizer的sentencepiece model
llama_spm.ParseFromString(llama_tokenizer.sp_model.serialized_model_proto()) # 从LLaMA tokenizer中加载sentencepiece model
chinese_spm = sp_pb2_model.ModelProto() # 定义Chinese tokenizer的sentencepiece model
chinese_spm.ParseFromString(chinese_sp_model.serialized_model_proto()) # 从Chinese tokenizer中加载sentencepiece model
# 输出tokens的信息
print(len(llama_tokenizer), len(chinese_sp_model)) # 两个tokenizer的词表大小;输出为32000、20000
print(llama_tokenizer.all_special_tokens) # LLaMA tokenizer的special tokens;输出为['']
print(llama_tokenizer.all_special_ids) # LLaMA tokenizer的special tokens对应的id;输出为[0]
print(llama_tokenizer.special_tokens_map) # LLaMA tokenizer的special tokens;输出为{'bos_token': '', 'eos_token': '', 'unk_token': ''}
# 将Chinese tokenizer的词表添加到LLaMA tokenizer中(合并过程)
llama_spm_tokens_set = set(p.piece for p in llama_spm.pieces) # LLaMA tokenizer的词表
print(len(llama_spm_tokens_set)) # LLaMA tokenizer的词表大小;输出为32000
print(f"Before:{len(llama_spm_tokens_set)}") # LLaMA tokenizer的词表大小;输出为Before:32000
for p in chinese_spm.pieces: # 遍历Chinese tokenizer的词表
piece = p.piece # Chinese tokenizer的词
if piece not in llama_spm_tokens_set: # 如果Chinese tokenizer的词不在LLaMA tokenizer的词表中
new_p = sp_pb2_model.ModelProto().SentencePiece() # 创建一个新的sentencepiece
new_p.piece = piece # 设置sentencepiece的词
new_p.score = 0 # 设置sentencepiece的score
llama_spm.pieces.append(new_p) # 将sentencepiece添加到LLaMA tokenizer的词表中
print(f"New model pieces: {len(llama_spm.pieces)}") # LLaMA tokenizer的词表大小;输出为New model pieces: 49953
# 保存LLaMA tokenizer
output_sp_dir = 'merged_tokenizer_sp' # 这里是保存LLaMA tokenizer的路径
output_hf_dir = 'merged_tokenizer_hf' # 这里是保存Chinese-LLaMA tokenizer的路径
os.makedirs(output_sp_dir, exist_ok=True) # 创建保存LLaMA tokenizer的文件夹
with open(output_sp_dir + '/chinese_llama.model', 'wb') as f:
f.write(llama_spm.SerializeToString())
tokenizer = LlamaTokenizer(vocab_file=output_sp_dir + '/chinese_llama.model') # 创建LLaMA tokenizer
tokenizer.save_pretrained(output_hf_dir) # 保存Chinese-LLaMA tokenizer
print(f"Chinese-LLaMA tokenizer has been saved to {output_hf_dir}") # 保存Chinese-LLaMA tokenizer
# 测试tokenizer
llama_tokenizer = LlamaTokenizer.from_pretrained(llama_tokenizer_dir) # LLaMA tokenizer
chinese_llama_tokenizer = LlamaTokenizer.from_pretrained(output_hf_dir) # Chinese-LLaMA tokenizer
print(tokenizer.all_special_tokens) # LLaMA tokenizer的special tokens;输出为['<s>', '</s>', '<unk>']
print(tokenizer.all_special_ids) # LLaMA tokenizer的special tokens对应的id;输出为[0, 1, 2]
print(tokenizer.special_tokens_map) # LLaMA tokenizer的special tokens;输出为{'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>'}
text = '''白日依山尽,黄河入海流。欲穷千里目,更上一层楼。
The primary use of LLaMA is research on large language models, including'''
print("Test text:\n", text) # 测试文本
print(f"Tokenized by LLaMA tokenizer:{llama_tokenizer.tokenize(text)}") # 测试LLaMA tokenizer
# 输出结果
# Tokenized by LLaMA tokenizer:['▁', '白', '日', '<0xE4>', '<0xBE>', '<0x9D>', '山', '<0xE5>', '<0xB0>', '<0xBD>', ',', '黄', '河', '入', '海', '流', '。', '<0xE6>', '<0xAC>', '<0xB2>', '<0xE7>', '<0xA9>', '<0xB7>', '千', '里', '目', ',', '更', '上', '一', '<0xE5>', '<0xB1>', '<0x82>', '<0xE6>', '<0xA5>', '<0xBC>', '。', '<0x0A>', 'The', '▁primary', '▁use', '▁of', '▁L', 'La', 'MA', '▁is', '▁research', '▁on', '▁large', '▁language', '▁models', ',', '▁including']
print(f"Tokenized by Chinese-LLaMA tokenizer:{chinese_llama_tokenizer.tokenize(text)}") # 测试Chinese-LLaMA tokenizer
# 输出结果
# Tokenized by Chinese-LLaMA tokenizer:['▁白', '日', '依', '山', '尽', ',', '黄河', '入', '海', '流', '。', '欲', '穷', '千里', '目', ',', '更', '上', '一层', '楼', '。', '<0x0A>', 'The', '▁primary', '▁use', '▁of', '▁L', 'La', 'MA', '▁is', '▁research', '▁on', '▁large', '▁language', '▁models', ',', '▁including']
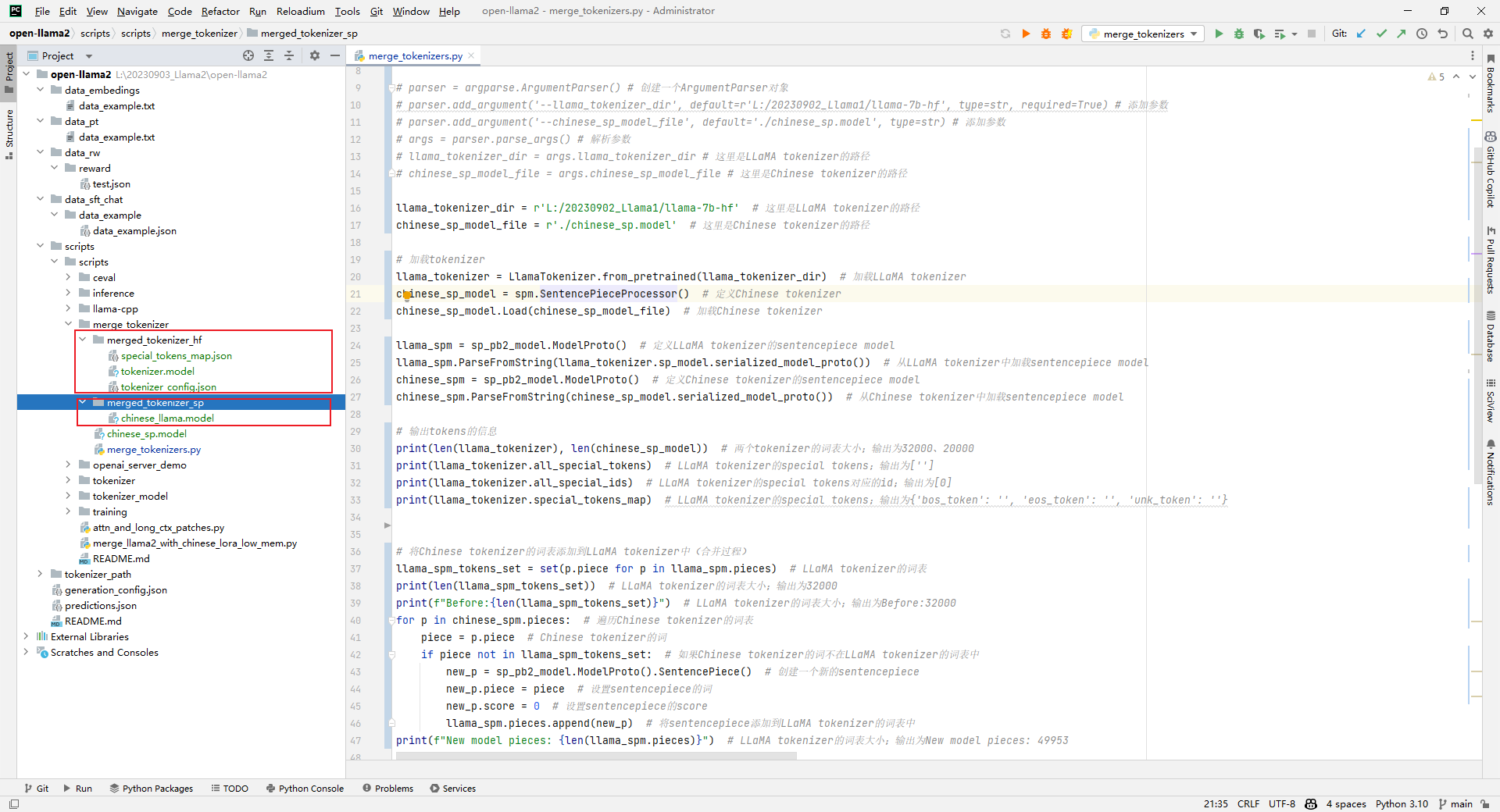
3.生成的目录
参考文献:
[1]是否有基于Llama-2的增量训练模型:https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/817
[2]https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/merge_tokenizer/merge_tokenizers.py
[3]https://github.com/ymcui/Chinese-LLaMA-Alpaca/tree/main/scripts/merge_tokenizer/chinese_sp.model
[4]下载Chinese-LLaMA-Alpaca:git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
[5]下载llama-7b-hf:git lfs clone https://huggingface.co/yahma/llama-7b-hf
Llama2-Chinese项目:2.2-大语言模型词表扩充的更多相关文章
- Golang优秀开源项目汇总, 10大流行Go语言开源项目, golang 开源项目全集(golang/go/wiki/Projects), GitHub上优秀的Go开源项目
Golang优秀开源项目汇总(持续更新...)我把这个汇总放在github上了, 后面更新也会在github上更新. https://github.com/hackstoic/golang-open- ...
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- .net项目中上传大图片失败
.net项目中有时用户提出要上传大图片,一张图片有可能十几兆,本来用的第三方的上传控件,有限制图片上传大小的设置,以前设置的是2M.按照用户的要求,以为直接将限制图片上传大小的设置改下就可以了,但是当 ...
- 《深度访谈:华为开源数据格式 CarbonData 项目,实现大数据即席查询秒级响应》
深度访谈:华为开源数据格式 CarbonData 项目,实现大数据即席查询秒级响应 Tina 阅读数:146012016 年 7 月 13 日 19:00 华为宣布开源了 CarbonData ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- python接口自动化(四十二)- 项目结构设计之大结局(超详解)
简介 这一篇主要是将前边的所有知识做一个整合,把各种各样的砖块---模块(post请求,get请求,logging,参数关联,接口封装等等)垒起来,搭建一个房子.并且有很多小伙伴对于接口项目测试的框架 ...
- 更好的在 Git 项目中保存大文件(Git LFS 的使用)
珠玉在前, 大家可以参考 Git LFS的使用 - 简书 为什么要用 Git LFS 原有的 Git 是文本层面的版本控制, 为代码这种小文件设计的, 保存大文件会导致 repo 非常臃肿, push ...
随机推荐
- 临时表、视图与系统函数_Lab2
MySQL数据库操作 Lab1.md body { font-family: var(--vscode-markdown-font-family, -apple-system, BlinkMacSys ...
- jmeter生成随机英文的几种方法
第一种:用BeanShell后置处理程序 1.写脚本 import java.util.Random; String random(int s_length) { strings= &qu ...
- Angular2 通过自定义指令限制输入框输入类型
** 温馨提示:如需转载本文,请注明内容出处.** 本文链接:https://www.cnblogs.com/grom/p/16814577.html 在input控件中,使用type="n ...
- Memcached的基本操作
一.Memcache使用场景1.非持久化存储:对数据存储要求不高2.分布式存储:不适合单机使用3.key/value存储:格式简单,不支持list,array数据格式二.系统类$m=new Memca ...
- 虹科技术|Redis企业版数据库:实现金融服务IT现代化!
随着新冠肺炎和技术创新推动企业进入新的数字时代,金融行业客户现在需要一种快速.简单且根据需求量身定制的数字银行体验.这就需要银行进行转型,以提供更加数字化的服务,但无论战略.方法,还是满足消费者极高期 ...
- OpenTiny Vue 支持 Vue2.7 啦!
你好,我是 Kagol. 前言 上个月发布了一篇 Vue2 升级 Vue3 的文章. 少年,该升级 Vue3 了! 里面提到使用了 ElementUI 的 Vue2 项目,可以通过 TinyVue 和 ...
- 推荐一个 AI 绘图工具!将草图变成精美的图片!
大家好,我是 Java陈序员. 要说 2023 年科技圈什么最火,当属 ChatGPT!自从 ChatGPT 爆火之后,各种 AI 工具层出不穷.AI 对话.AI 写文案.AI 写代码..... 今天 ...
- Node02-包管理工具
前言:代码共享 模块化的编程思想,支持将代码划分成一个个小的.独立的结构. 我们可以通过模块化的方式来封装自己的代码,将之封装成一个个工具: 我们可以让同事通过导入的方式来使用这些工具,甚至也可以将这 ...
- super学习
2022-10-02 16:27:38 super super代表的是"当前对象(this)"的父类型特征 概念 1.super是一个关键字,全部小写. 2.super和this对 ...
- .NET 程序员-开源项目【藏】
Json.NET http://json.codeplex.com/ Json.Net是一个读写Json效率比较高的.Net框架.Json.Net 使得在.Net环境下使用Json更加简单.通过Lin ...