高斯朴素贝叶斯(Gaussian Naive Bayes)原理与实现——垃圾邮件识别实战
朴素贝叶斯(Naive Bayes):
根据贝叶斯定理和朴素假设提出的朴素贝叶斯模型。
贝叶斯定理:
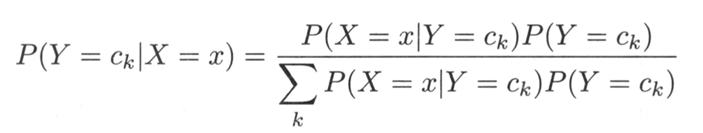
朴素假设(特征条件独立性假设):

代入可知朴素贝叶斯模型计算公式:

因为朴素贝叶斯是用来分类任务,因此:
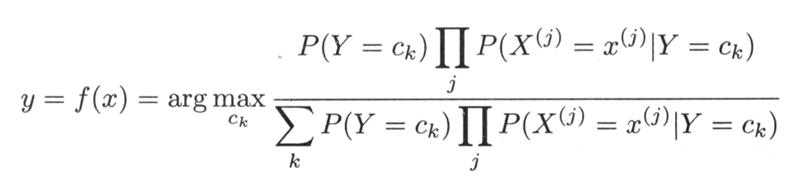
化简可知:
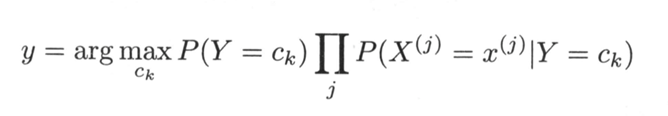
朴素贝叶斯模型除了上式所描述的以外,有三种常用的模型:
1、高斯朴素贝叶斯
2、多项式朴素贝叶斯
3、伯努利朴素贝叶斯
本篇主要是实现高斯朴素贝叶斯,因为它是最常用的一种模型。
高斯朴素贝叶斯:
适用于连续变量,其假定各个特征 _ 在各个类别下是服从正态分布的,算法内部使用正态分布的概率密度函数来计算概率。

_:在类别为的样本中,特征_的均值。
_:在类别为的样本中,特征_的标准差。
高斯朴素贝叶斯代码实现:
注释:
1、var_smoothing和epsilon的目的是防止一些特征的方差为0的情况(比如在垃圾邮件识别的时候,使用词袋模型很容易出现方差为0)
2、计算联合概率时并不使用连乘,对概率取自然对数,乘法变加法,降低计算复杂度,使模型更稳定。


1 import numpy as np
2 import collections
3 import math
4 class GaussianNB(object):
5 def __init__(self):
6 self.mp = {} #把y值映射到0-n之间的整数
7 self.n_class = None #类别数
8 self.class_prior= None #先验概率P(Y)
9 self.means = None #均值
10 self.vars = None #方差
11 self.var_smoothing =1e-9 #平滑因子
12 self.epsilon = None #平滑值
13 def _get_class_prior(self,y):
14 cnt = collections.Counter(y)
15 self.n_class = 0
16 for k,v in cnt.items():
17 self.mp[k] = self.n_class
18 self.n_class+=1
19 self.class_prior = np.array([ v/len(y) for k,v in cnt.items()])
20 pass
21 def _get_means(self,xx,y):
22 new_y =np.array([self.mp[i] for i in y])
23 self.means = np.array([ xx[new_y==id].mean(axis=0) for id in range(self.n_class)])
24 # self.means shape: n_class * dims
25 pass
26 def _get_vars(self,xx,y):
27 new_y = np.array([self.mp[i] for i in y])
28 self.vars = np.array([xx[new_y == id].var(axis=0) for id in range(self.n_class)])
29 # self.vars shape: n_class * dims
30 pass
31 def fit(self,X,Y):
32 # X 必须是numpy的array; Y为list,对于X中每个样本的类别
33 self._get_class_prior(Y)
34 self._get_means(X,Y)
35 self._get_vars(X,Y)
36 self.epsilon = self.var_smoothing * self.vars.max() #选取特征中最大的方差作为平滑
37 self.vars = self.vars + self.epsilon #给所有方差加上平滑的值
38 pass
39 def _get_gaussian(self,x,u,var):
40 #计算在类别y下x的条件概率P(xj|y)的对数
41 #return math.log(1 / math.sqrt(2 * math.pi * var) * math.exp(-(x - u) ** 2 / (2 * var)))
42 return -(x - u) ** 2 / (2 * var) - math.log(math.sqrt(2 * math.pi * var))
43 def predict(self,x):
44 dims = len(x)
45 likelihoods = []
46 for id in range(self.n_class): #遍历每类yi,把每个特征的条件概率P(xj|yi)累加
47 likelihoods.append(np.sum([self._get_gaussian(x[j], self.means[id][j], self.vars[id][j]) for j in range(dims)]))
48 # 对先验概率取对数
49 log_class_prior = np.log(self.class_prior)
50 all_pros = log_class_prior + likelihoods
51 #all_pros = self.standardization(all_pros)
52 max_id = all_pros.argmax() #取概率最大的类别的下标
53 for k,v in self.mp.items(): #转换为可读的y值
54 if v== max_id:
55 return k
56 pass
57 def standardization(self,x):
58 mu = np.mean(x)
59 sigma = np.std(x)
60 return (x - mu) / sigma
61
62 # nb = GaussianNB()
63 # xx = np.array([[1,2,3],[11,12,1],[2,1,4],[15,16,1],[8,6,6],[19,13,0]])
64 # y = ['min','max','min','max','min','max']
65 # nb.fit(xx,y)
66 # print(nb.predict(np.array([0,0,0])))
垃圾邮件识别实战:
数据集:Trec06C数据集
笔者获取的数据集是处理过的
处理方式:随机选取:5000封垃圾邮件和5000封正常邮件;
预处理提取邮件正文,去掉换行符、多余空格等UTF-8文本格式,每封邮件正文在文件中保存为一行文本其中前5000 条为垃圾邮件,后5000 条为正常邮件。

特征提取:使用词袋模型进行特征提取(特征维度33453)
模型训练:模型训练和验证将数据集随机切分为训练集和测试集(40%);使用GaussianNB高斯贝叶斯进行训练。
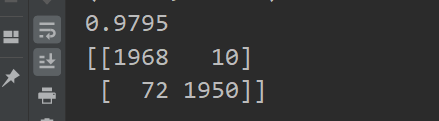
实验结果:在测试集上准确率达到了97.95%,效果还是不错的
实验代码:
注释:代码跑起来比较慢,主要是因为预测的函数并不是将所有的句子一起预测,而是一句一句预测了。最近没啥空改这个,等下次需要的时候再更新吧。
1 import numpy as np
2 import jieba
3 from sklearn.feature_extraction.text import CountVectorizer
4 from sklearn import model_selection, metrics
5 from GaussianNB import GaussianNB
6 file_path = 'email.txt'
7 file = open(file_path,encoding='utf-8')
8 data = file.readlines()
9 y = ['Spam']*5000+['Normal mail']*5000
10 split_data = []
11 for line in data:
12 split_data.append(' '.join(jieba.lcut(line)))
13 print(split_data[-1])
14 #仅保留长度至少为2个汉字的词
15 cv = CountVectorizer(token_pattern=r"(?u)\b\w\w+\b")
16 xx = cv.fit_transform(split_data).toarray()
17 print(xx.shape)
18
19 x_train, x_test, y_train, y_test = model_selection.train_test_split(xx,y,test_size=0.4)
20 gnb = GaussianNB()
21 gnb.fit(x_train,y_train)
22 y_pre =[]
23 for x in x_test:
24 y_pre.append(gnb.predict(x))
25 print(metrics.accuracy_score(y_test,y_pre))
26 print (metrics.confusion_matrix(y_test, y_pre))
参考资料:
1、《统计学习方法(第二版)》——李航
2、https://zhuanlan.zhihu.com/p/64498790
高斯朴素贝叶斯(Gaussian Naive Bayes)原理与实现——垃圾邮件识别实战的更多相关文章
- PGM:贝叶斯网表示之朴素贝叶斯模型naive Bayes
http://blog.csdn.net/pipisorry/article/details/52469064 独立性质的利用 条件参数化和条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑 ...
- 朴素贝叶斯(Naive Bayes)
1.朴素贝叶斯模型 朴素贝叶斯分类器是一种有监督算法,并且是一种生成模型,简单易于实现,且效果也不错,需要注意,朴素贝叶斯是一种线性模型,他是是基于贝叶斯定理的算法,贝叶斯定理的形式如下: \[P(Y ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 深入理解朴素贝叶斯(Naive Bayes)
https://blog.csdn.net/li8zi8fa/article/details/76176597 朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.朴素贝叶斯原理简 ...
- 朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 模式识别之贝叶斯---朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 【分类算法】朴素贝叶斯(Naive Bayes)
0 - 算法 给定如下数据集 $$T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\},$$ 假设$X$有$J$维特征,且各维特征是独立分布的,$Y$有$K$种取值.则 ...
- 朴素贝叶斯分类器Naive Bayes
优点Naive Bayes classifiers tend to perform especially well in one of the following situations: When t ...
随机推荐
- 深入了解商品详情API接口的使用方法与数据获取
作为程序员,了解和熟悉如何调用API接口获取淘宝商品数据是非常重要的.在现今的电商环境中,准确.及时地获取商品详情信息对于开发者和商家来说至关重要.本文将以程序员的视角,详细介绍如何调用API接口 ...
- LeetCode952三部曲之二:小幅度优化(137ms -> 122ms,超39% -> 超51%)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<LeetCode952三部曲& ...
- Tongweb远程调试
最近,在对项目进行国产化时,要求springboot项目容器换成tongweb.在部署中,有个问题一直无法在本地重现,搜了下网上资料,基本没法实现,所以我整理了下.注意,项目包代码必须与本地代码保持一 ...
- C#应用程序的多语言方案 - 开源研究系列文章
今天讲讲笔者自创的C#应用程序多语言的方案. 这个多语言方案,主要是对应用的窗体及其控件进行检索,然后根据控件的名称进行在语言字典里进行检索获取到对应的语言文本进行赋值显示的.笔者对网上的多语言方案进 ...
- 分拣平台API安全治理实战 | 京东物流技术团队
导读 本文主要基于京东物流的分拣业务平台在生产环境遇到的一些安全类问题,进行定位并采取合适的解决方案进行安全治理,引出对行业内不同业务领域.不同类型系统的安全治理方案的探究,最后笔者也基于自己在金融领 ...
- 探索抽象同步队列 AQS
by emanjusaka from https://www.emanjusaka.top/archives/8 彼岸花开可奈何 本文欢迎分享与聚合,全文转载请留下原文地址. 前言 AbstractQ ...
- Springboot简单功能示例-6 使用加密数据源并配置日志
springboot-sample 介绍 springboot简单示例 跳转到发行版 查看发行版说明 软件架构(当前发行版使用) springboot hutool-all 非常好的常用java工具库 ...
- Redis和Memcache区别,优缺点对比(转)
转自 https://www.cnblogs.com/JavaBlackHole/p/7726195.html 1. Redis和Memcache都是将数据存放在内存中,都是内存数据库.不过memca ...
- SQLPLUS使用及Oracle表空间设定自动扩展
起因:ERP不能登陆,Oracle无法访问,报错如下 后联系鼎捷se提供以下解决方案: 该问题是由于Oracle审计表AUD$数据过大导致数据库异常,现已登录DB服务器使用oracle账号执行语句tr ...
- VTable——不只是高性能的多维数据分析表格
导读 VTable: 不只是高性能的多维数据分析表格,更是行列间创作的方格艺术家! VTable是字节跳动开源可视化解决方案 VisActor 的组件之一. 在现代应用程序中,表格组件是不可或缺的一部 ...