高斯朴素贝叶斯(Gaussian Naive Bayes)原理与实现——垃圾邮件识别实战
朴素贝叶斯(Naive Bayes):
根据贝叶斯定理和朴素假设提出的朴素贝叶斯模型。
贝叶斯定理:
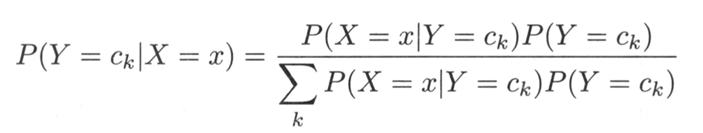
朴素假设(特征条件独立性假设):

代入可知朴素贝叶斯模型计算公式:

因为朴素贝叶斯是用来分类任务,因此:
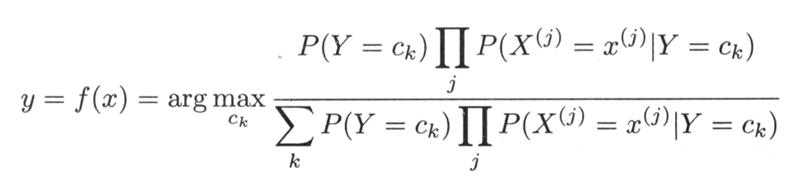
化简可知:
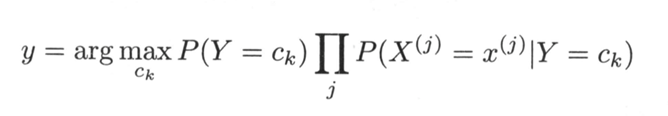
朴素贝叶斯模型除了上式所描述的以外,有三种常用的模型:
1、高斯朴素贝叶斯
2、多项式朴素贝叶斯
3、伯努利朴素贝叶斯
本篇主要是实现高斯朴素贝叶斯,因为它是最常用的一种模型。
高斯朴素贝叶斯:
适用于连续变量,其假定各个特征 _ 在各个类别下是服从正态分布的,算法内部使用正态分布的概率密度函数来计算概率。

_:在类别为的样本中,特征_的均值。
_:在类别为的样本中,特征_的标准差。
高斯朴素贝叶斯代码实现:
注释:
1、var_smoothing和epsilon的目的是防止一些特征的方差为0的情况(比如在垃圾邮件识别的时候,使用词袋模型很容易出现方差为0)
2、计算联合概率时并不使用连乘,对概率取自然对数,乘法变加法,降低计算复杂度,使模型更稳定。


1 import numpy as np
2 import collections
3 import math
4 class GaussianNB(object):
5 def __init__(self):
6 self.mp = {} #把y值映射到0-n之间的整数
7 self.n_class = None #类别数
8 self.class_prior= None #先验概率P(Y)
9 self.means = None #均值
10 self.vars = None #方差
11 self.var_smoothing =1e-9 #平滑因子
12 self.epsilon = None #平滑值
13 def _get_class_prior(self,y):
14 cnt = collections.Counter(y)
15 self.n_class = 0
16 for k,v in cnt.items():
17 self.mp[k] = self.n_class
18 self.n_class+=1
19 self.class_prior = np.array([ v/len(y) for k,v in cnt.items()])
20 pass
21 def _get_means(self,xx,y):
22 new_y =np.array([self.mp[i] for i in y])
23 self.means = np.array([ xx[new_y==id].mean(axis=0) for id in range(self.n_class)])
24 # self.means shape: n_class * dims
25 pass
26 def _get_vars(self,xx,y):
27 new_y = np.array([self.mp[i] for i in y])
28 self.vars = np.array([xx[new_y == id].var(axis=0) for id in range(self.n_class)])
29 # self.vars shape: n_class * dims
30 pass
31 def fit(self,X,Y):
32 # X 必须是numpy的array; Y为list,对于X中每个样本的类别
33 self._get_class_prior(Y)
34 self._get_means(X,Y)
35 self._get_vars(X,Y)
36 self.epsilon = self.var_smoothing * self.vars.max() #选取特征中最大的方差作为平滑
37 self.vars = self.vars + self.epsilon #给所有方差加上平滑的值
38 pass
39 def _get_gaussian(self,x,u,var):
40 #计算在类别y下x的条件概率P(xj|y)的对数
41 #return math.log(1 / math.sqrt(2 * math.pi * var) * math.exp(-(x - u) ** 2 / (2 * var)))
42 return -(x - u) ** 2 / (2 * var) - math.log(math.sqrt(2 * math.pi * var))
43 def predict(self,x):
44 dims = len(x)
45 likelihoods = []
46 for id in range(self.n_class): #遍历每类yi,把每个特征的条件概率P(xj|yi)累加
47 likelihoods.append(np.sum([self._get_gaussian(x[j], self.means[id][j], self.vars[id][j]) for j in range(dims)]))
48 # 对先验概率取对数
49 log_class_prior = np.log(self.class_prior)
50 all_pros = log_class_prior + likelihoods
51 #all_pros = self.standardization(all_pros)
52 max_id = all_pros.argmax() #取概率最大的类别的下标
53 for k,v in self.mp.items(): #转换为可读的y值
54 if v== max_id:
55 return k
56 pass
57 def standardization(self,x):
58 mu = np.mean(x)
59 sigma = np.std(x)
60 return (x - mu) / sigma
61
62 # nb = GaussianNB()
63 # xx = np.array([[1,2,3],[11,12,1],[2,1,4],[15,16,1],[8,6,6],[19,13,0]])
64 # y = ['min','max','min','max','min','max']
65 # nb.fit(xx,y)
66 # print(nb.predict(np.array([0,0,0])))
垃圾邮件识别实战:
数据集:Trec06C数据集
笔者获取的数据集是处理过的
处理方式:随机选取:5000封垃圾邮件和5000封正常邮件;
预处理提取邮件正文,去掉换行符、多余空格等UTF-8文本格式,每封邮件正文在文件中保存为一行文本其中前5000 条为垃圾邮件,后5000 条为正常邮件。

特征提取:使用词袋模型进行特征提取(特征维度33453)
模型训练:模型训练和验证将数据集随机切分为训练集和测试集(40%);使用GaussianNB高斯贝叶斯进行训练。
实验结果:在测试集上准确率达到了97.95%,效果还是不错的
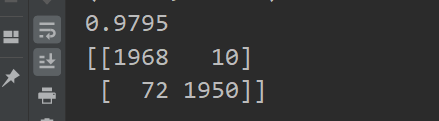
实验代码:
注释:代码跑起来比较慢,主要是因为预测的函数并不是将所有的句子一起预测,而是一句一句预测了。最近没啥空改这个,等下次需要的时候再更新吧。
1 import numpy as np
2 import jieba
3 from sklearn.feature_extraction.text import CountVectorizer
4 from sklearn import model_selection, metrics
5 from GaussianNB import GaussianNB
6 file_path = 'email.txt'
7 file = open(file_path,encoding='utf-8')
8 data = file.readlines()
9 y = ['Spam']*5000+['Normal mail']*5000
10 split_data = []
11 for line in data:
12 split_data.append(' '.join(jieba.lcut(line)))
13 print(split_data[-1])
14 #仅保留长度至少为2个汉字的词
15 cv = CountVectorizer(token_pattern=r"(?u)\b\w\w+\b")
16 xx = cv.fit_transform(split_data).toarray()
17 print(xx.shape)
18
19 x_train, x_test, y_train, y_test = model_selection.train_test_split(xx,y,test_size=0.4)
20 gnb = GaussianNB()
21 gnb.fit(x_train,y_train)
22 y_pre =[]
23 for x in x_test:
24 y_pre.append(gnb.predict(x))
25 print(metrics.accuracy_score(y_test,y_pre))
26 print (metrics.confusion_matrix(y_test, y_pre))
参考资料:
1、《统计学习方法(第二版)》——李航
2、https://zhuanlan.zhihu.com/p/64498790
高斯朴素贝叶斯(Gaussian Naive Bayes)原理与实现——垃圾邮件识别实战的更多相关文章
- PGM:贝叶斯网表示之朴素贝叶斯模型naive Bayes
http://blog.csdn.net/pipisorry/article/details/52469064 独立性质的利用 条件参数化和条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑 ...
- 朴素贝叶斯(Naive Bayes)
1.朴素贝叶斯模型 朴素贝叶斯分类器是一种有监督算法,并且是一种生成模型,简单易于实现,且效果也不错,需要注意,朴素贝叶斯是一种线性模型,他是是基于贝叶斯定理的算法,贝叶斯定理的形式如下: \[P(Y ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 深入理解朴素贝叶斯(Naive Bayes)
https://blog.csdn.net/li8zi8fa/article/details/76176597 朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.朴素贝叶斯原理简 ...
- 朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 模式识别之贝叶斯---朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 【分类算法】朴素贝叶斯(Naive Bayes)
0 - 算法 给定如下数据集 $$T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\},$$ 假设$X$有$J$维特征,且各维特征是独立分布的,$Y$有$K$种取值.则 ...
- 朴素贝叶斯分类器Naive Bayes
优点Naive Bayes classifiers tend to perform especially well in one of the following situations: When t ...
随机推荐
- Linux 主机磁盘繁忙度监控实战shell脚本
Linux 磁盘繁忙度是指磁盘的使用率和活动水平.可以通过一些工具来监测磁盘繁忙度,如 iostat.iotop.sar 等. 其中,iostat 是一个常用的工具,可以提供关于磁盘活动的详细统计信息 ...
- springboot项目自动关闭进程重启脚本
话不多说,先上脚本 kill -15 $(netstat -nlp | grep :9095 | awk '{print $7}' | awk -F"/" '{ print $1 ...
- C++模板介绍
C++ 模板 C++ 模板是一种强大的泛型编程工具,它允许我们编写通用的代码,可以用于处理多种不同的数据类型.模板允许我们在编写代码时将类型作为参数进行参数化,从而实现代码的重用性和灵活性. 在 C+ ...
- 2023年了,复习了一下spring boot配置使用mongodb
前言 MongoDB是一个基于分布式文件存储的开源数据库系统,使用C++语言编写.它是一个介于关系数据库和非关系数据库之间的产品,具有类似关系数据库的功能,但又有一些非关系数据库的特点.MongoDB ...
- 一文搞懂 OTP 双因素认证
GitHub 在 2023 年 3 月推出了双因素认证(two-factor authentication)简称 2FA,并且承诺所有在 GitHub 上贡献的开发者在 2023 年底前启用双因素认证 ...
- windows系统上的大文件拆分合并
上周碰到一个并不算很大的问题,但是也有记录的价值. 从公司带出来的离线补丁包需要传到客户服务器上,但是被告知并不能在现场机器上插U盘,会触发告警.上传只能把U盘上的内容通过私人笔记本刻录到光盘上,插光 ...
- MySql 数据 管理表的操作
管理表的操作 use scoredb; -- 查看数据库中有哪些表 show tables; show tables from bipowernode; -- 查看数据表的基础结构 show colu ...
- Matlab 实现连续PID环节与标记系统-3dB点
Matlab 实现连续PID环节 连续PID环节传递函数: \[\frac{O(s)}{I(s)} = K_P \cdot \left( 1 + \frac{K_{I}}{s} + K_D\cdot ...
- VoIP==Voice over Internet Protocol
基于IP的语音传输(英语:Voice over Internet Protocol,缩写为VoIP)是一种语音通话技术,经由网际协议(IP)来达成语音通话与多媒体会议,也就是经由互联网来进行通信.其他 ...
- 【matplotlib 实战】--漏斗图
漏斗图,形如"漏斗",用于展示数据的逐渐减少或过滤过程.它的起始总是最大,并在各个环节依次减少,每个环节用一个梯形来表示,整体形如漏斗.一般来说,所有梯形的高度应是一致的,这会有助 ...