Kernel Memory 入门系列: Embedding 简介
Kernel Memory 入门系列: Embedding 简介
在 RAG模式 其实留了一个问题。
我们对于的用户问题的理解和文档的检索并没有提供合适的方法。

当然我们可以通过相对比较传统的方法。
例如对用户的问题进行关键词提取,然后通过关键词检索文档。这样的话,就需要我们提前对文档做好相关关键词的标注,同时也需要关键词能够覆盖到用户可能的提出方式以及表达方法。这样的话,就需要我们对用户的问题有一个很好的预测。用户也需要在提问的时候,能够按照我们的预期进行提问。我们和用户双向猜测,双向奔赴,如果猜对了,那么就可以得到一个比较好的结果。如果猜错了,结果难以想象。
那么有没有一种方法,能够让我们不需要对用户的问题进行预测,也不需要对文档进行关键词标注,就能够得到一个比较好的结果呢?
这个答案就是 Embedding。
Embedding 是什么
Embedding 是一种将高维数据映射到低维空间的方法。在这个低维空间中,数据的相似性和原始空间中的相似性是一致的。这样的话,我们就可以通过低维空间中的相似性来进行检索。
通俗的理解,大语言模型基于大量的文本数据进行训练,得到了一个高维的向量空间,我们可以认为这是一个语义的空间。在这个语义空间中,每一个词或者每个句子都有一个对应的空间坐标。虽然这个坐标系的维度是非常高的,起码都是上百甚至上千的维度,但是我们仍可以想象在二维或者三维空间中的点去理解这个坐标。
然后,我们就可以通过这个向量来判断两段文字是否相似。如果两段文字的向量越接近,那么这两个词的语义就越接近。例如,猫 和 狗 的向量就会比 猫 和 苹果 的向量更加接近。

这个空间坐标和模型的关系更加密切,模型越强大,对于语义的理解越深刻,那么这个空间坐标的效果就越好。所以,寻找或者训练一个好的Embedding模型对于实现一个好的检索系统是非常重要的。
使用Embedding进行匹配
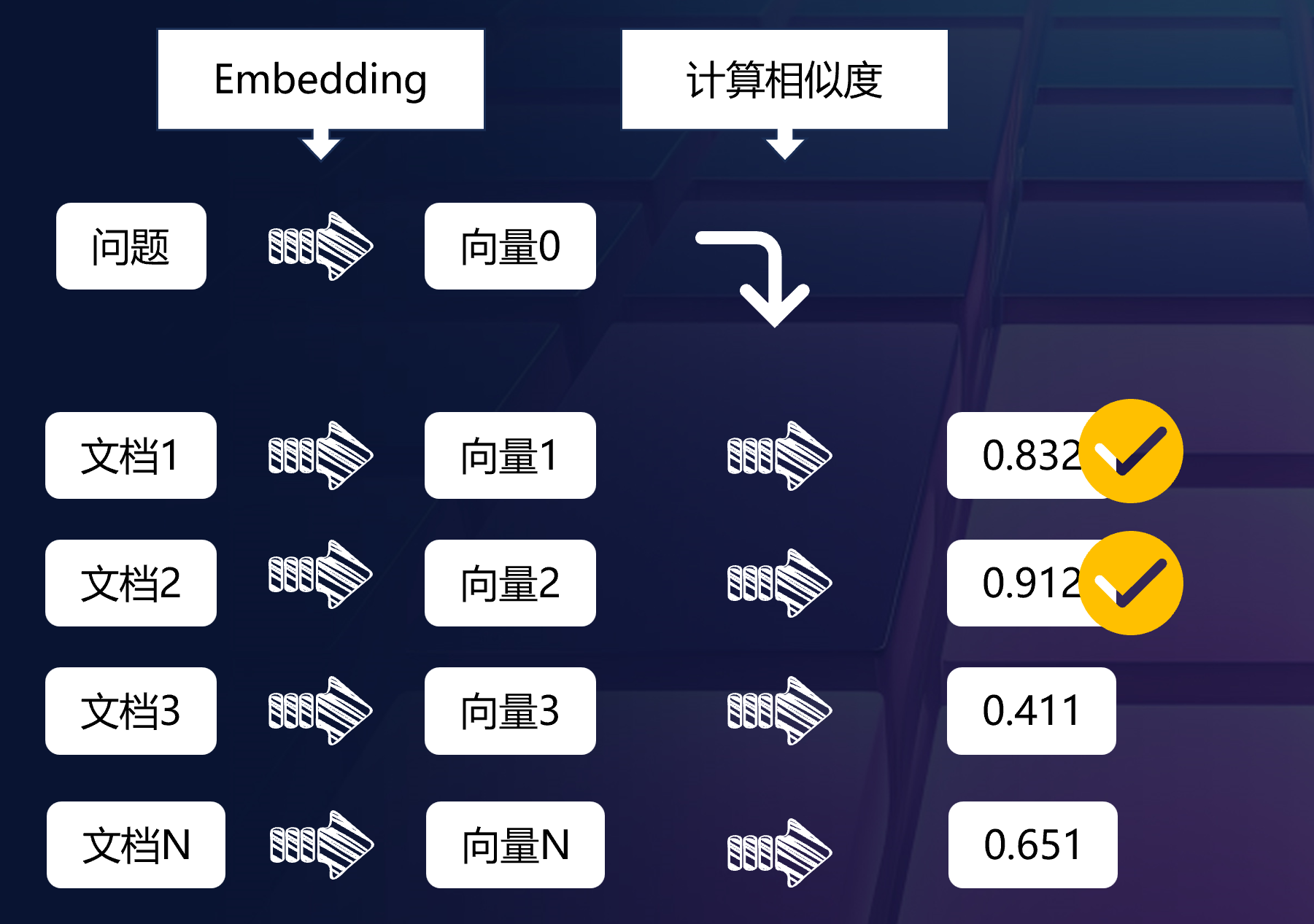
有了Embedding的结果之后,我们就可以看如何使用Embedding进行匹配了。
首先我们需要对用户的提问和我们的文本进行Embedding,得到对应的向量。
通过计算问题的向量与文本的向量的相似性,通常是余弦相似度计算,我们就可以得到一个排序的结果。这个排序的结果就是我们的检索结果。
根据实际模型的表现,选择合适的相似度阈值,然后就可以找到最为相似的内容了。
参考
Kernel Memory 入门系列: Embedding 简介的更多相关文章
- saltstack之基础入门系列文章简介
使用saltstack已有一段时间,最近由于各种原因,特来整理了saltstack基础入门系列文章,已备后续不断查阅(俗话说好记性不如烂笔头),也算是使用此工具的一个总结.saltstack的前六篇文 ...
- Semantic Kernel 入门系列:🥑Memory内存
了解的运作原理之后,就可以开始使用Semantic Kernel来制作应用了. Semantic Kernel将embedding的功能封装到了Memory中,用来存储上下文信息,就好像电脑的内存一样 ...
- C#刷遍Leetcode面试题系列连载(1) - 入门与工具简介
目录 为什么要刷LeetCode 刷LeetCode有哪些好处? LeetCode vs 传统的 OJ LeetCode刷题时的心态建设 C#如何刷遍LeetCode 选项1: VS本地Debug + ...
- Android视频录制从不入门到入门系列教程(一)————简介
一.WHY Android SDK提供了MediaRecorder帮助开发者进行视频的录制,不过这个类很鸡肋,实际项目中应该很少用到它,最大的原因我觉得莫过于其输出的视频分辨率太有限了,满足不了项目的 ...
- 快速入门系列--WebAPI--03框架你值得拥有
接下来进入的是俺在ASP.NET学习中最重要的WebAPI部分,在现在流行的互联网场景下,WebAPI可以和HTML5.单页应用程序SPA等技术和理念很好的结合在一起.所谓ASP.NET WebAPI ...
- linux入门系列12--磁盘管理之分区、格式化与挂载
前面系列文章讲解了VI编辑器.常用命令.防火墙及网络服务管理,本篇将讲解磁盘管理相关知识. 本文将会介绍大量的Linux命令,其中有一部分在"linux入门系列5--新手必会的linux命令 ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- Go语言入门系列(五)之指针和结构体的使用
Go语言入门系列前面的文章: Go语言入门系列(二)之基础语法总结 Go语言入门系列(三)之数组和切片 Go语言入门系列(四)之map的使用 1. 指针 如果你使用过C或C++,那你肯定对指针这个概念 ...
- 机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测
1. 机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测 1.1 LightGBM原理简介 LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个 ...
随机推荐
- 智能AI 的应用场景
小凡智能AI是一款基于人工智能技术开发的助软件,能够帮助用户解决各种各样的问题,提高工作效率和生活质量.它的应用范围广泛,涵盖了工作.学习.健康等多个方面,为用户提供了全方位的服务支持. 在工作方面, ...
- OpenCASCADE 显示对象设置不可选中
原有的选中模式代码: static Standard_Integer SelectionMode (const TopAbs_ShapeEnum theShapeType) { switch (the ...
- FFmpeg中的常用结构体分析
一.前言 在学习使用FFmpeg进行编解码时,我们有必要先去熟悉FFmpeg中的常用结构体,只有对它们的含义和用途有深刻的了解,我们才能为后面的学习打下坚实的基础.所以,这篇文章将会介绍这些常用的结构 ...
- Java开发面试--Redis专区
1. 什么是Redis?它的主要特点是什么? 答: Redis是一个开源的.基于内存的高性能键值对存储系统.它主要用于缓存.数据存储和消息队列等场景. 高性能:Redis将数据存储在内存中,并采用单线 ...
- Vue源码学习(六):(支线)渲染函数中with(),call()的使用以及一些思考
好家伙, 昨天,在学习vue源码的过程中,看到了这个玩意 嘶,看不太懂,研究一下 1.上下文 这段出现vue模板编译的虚拟node部分 export function renderMixin( ...
- Journey -「CQOI 2021」
Day -1 Thu. & Fri. 恰逢学校运动会,于是向班主任申请了不去,然后就在机房坐着.不美好的事情可能就是文化课老师还留了这两天的作业,不过-> 一旦放弃了作业,什么都好说了呢 ...
- apollo多环境部署
一.环境准备 jdk : 1.8+ mysql 5.6.5+ 二.安装包下载 https://github.com/ctripcorp/apollo/releases 下载如下三个压 ...
- 【RocketMQ】Rebalance负载均衡总结
消费者负载均衡,是指为消费组下的每个消费者分配订阅主题下的消费队列,分配了消费队列消费者就可以知道去消费哪个消费队列上面的消息,这里针对集群模式,因为广播模式,所有的消息队列可以被消费组下的每个消费者 ...
- heygen模型接口 简单使用 java版
HeyGen - AI Spokesperson Video Creator 官网地址 Create a video (heygen.com) api地址 简介: 公司最近对ai方面业务比较感兴趣了 ...
- 分布式事务 —— SpringCloud Alibaba Seata
Seata 简介 传统的单体应用中,业务操作使用同一条连接操作不同的数据表,一旦出现异常就可以整体回滚.随着公司的快速发展.业务需求的变化,单体应用被拆分成微服务应用,原来的单体应用被拆分成多个独立的 ...