Kernel Memory 入门系列: Embedding 简介
Kernel Memory 入门系列: Embedding 简介
在 RAG模式 其实留了一个问题。
我们对于的用户问题的理解和文档的检索并没有提供合适的方法。

当然我们可以通过相对比较传统的方法。
例如对用户的问题进行关键词提取,然后通过关键词检索文档。这样的话,就需要我们提前对文档做好相关关键词的标注,同时也需要关键词能够覆盖到用户可能的提出方式以及表达方法。这样的话,就需要我们对用户的问题有一个很好的预测。用户也需要在提问的时候,能够按照我们的预期进行提问。我们和用户双向猜测,双向奔赴,如果猜对了,那么就可以得到一个比较好的结果。如果猜错了,结果难以想象。
那么有没有一种方法,能够让我们不需要对用户的问题进行预测,也不需要对文档进行关键词标注,就能够得到一个比较好的结果呢?
这个答案就是 Embedding。
Embedding 是什么
Embedding 是一种将高维数据映射到低维空间的方法。在这个低维空间中,数据的相似性和原始空间中的相似性是一致的。这样的话,我们就可以通过低维空间中的相似性来进行检索。
通俗的理解,大语言模型基于大量的文本数据进行训练,得到了一个高维的向量空间,我们可以认为这是一个语义的空间。在这个语义空间中,每一个词或者每个句子都有一个对应的空间坐标。虽然这个坐标系的维度是非常高的,起码都是上百甚至上千的维度,但是我们仍可以想象在二维或者三维空间中的点去理解这个坐标。
然后,我们就可以通过这个向量来判断两段文字是否相似。如果两段文字的向量越接近,那么这两个词的语义就越接近。例如,猫 和 狗 的向量就会比 猫 和 苹果 的向量更加接近。

这个空间坐标和模型的关系更加密切,模型越强大,对于语义的理解越深刻,那么这个空间坐标的效果就越好。所以,寻找或者训练一个好的Embedding模型对于实现一个好的检索系统是非常重要的。
使用Embedding进行匹配
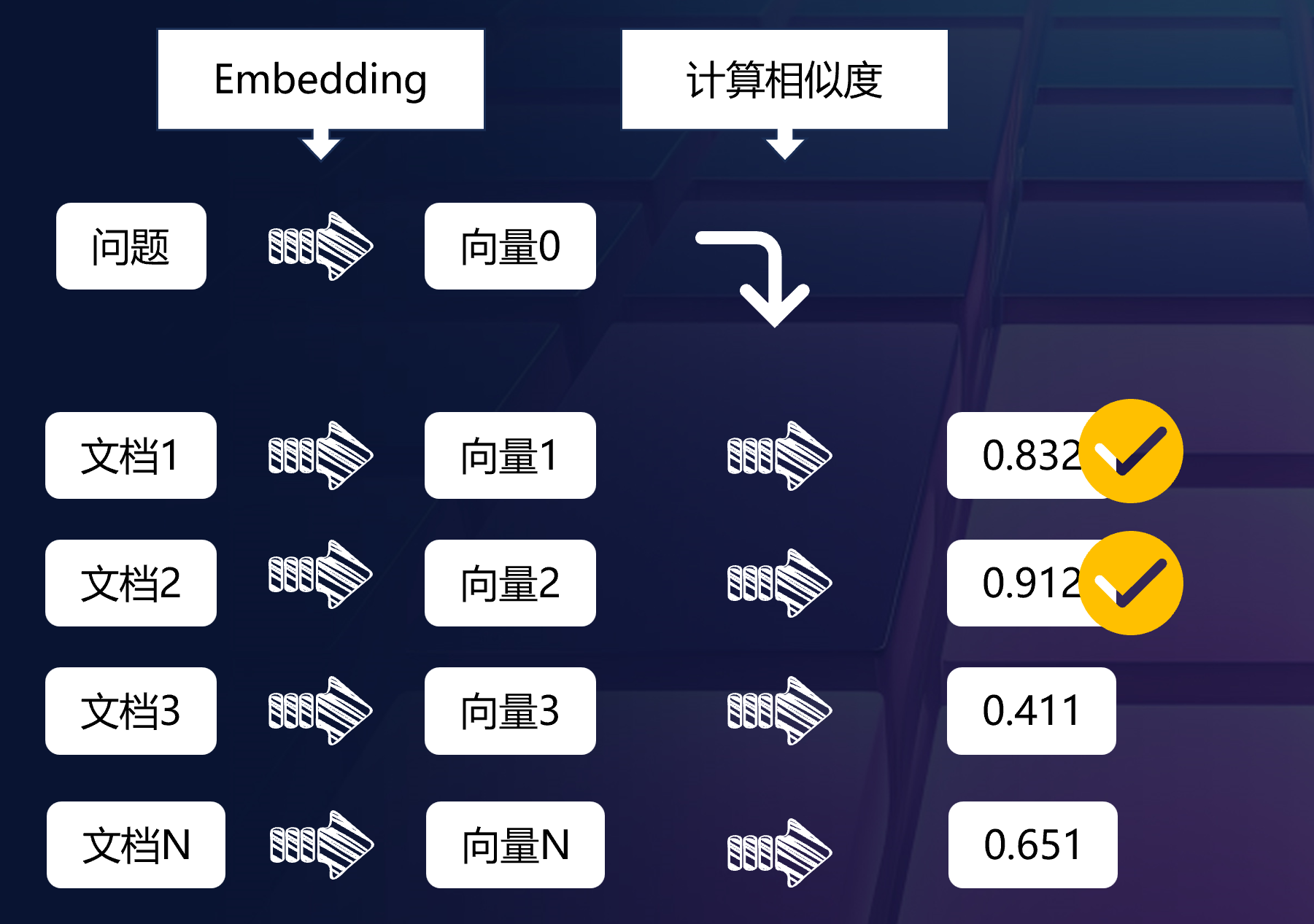
有了Embedding的结果之后,我们就可以看如何使用Embedding进行匹配了。
首先我们需要对用户的提问和我们的文本进行Embedding,得到对应的向量。
通过计算问题的向量与文本的向量的相似性,通常是余弦相似度计算,我们就可以得到一个排序的结果。这个排序的结果就是我们的检索结果。
根据实际模型的表现,选择合适的相似度阈值,然后就可以找到最为相似的内容了。
参考
Kernel Memory 入门系列: Embedding 简介的更多相关文章
- saltstack之基础入门系列文章简介
使用saltstack已有一段时间,最近由于各种原因,特来整理了saltstack基础入门系列文章,已备后续不断查阅(俗话说好记性不如烂笔头),也算是使用此工具的一个总结.saltstack的前六篇文 ...
- Semantic Kernel 入门系列:🥑Memory内存
了解的运作原理之后,就可以开始使用Semantic Kernel来制作应用了. Semantic Kernel将embedding的功能封装到了Memory中,用来存储上下文信息,就好像电脑的内存一样 ...
- C#刷遍Leetcode面试题系列连载(1) - 入门与工具简介
目录 为什么要刷LeetCode 刷LeetCode有哪些好处? LeetCode vs 传统的 OJ LeetCode刷题时的心态建设 C#如何刷遍LeetCode 选项1: VS本地Debug + ...
- Android视频录制从不入门到入门系列教程(一)————简介
一.WHY Android SDK提供了MediaRecorder帮助开发者进行视频的录制,不过这个类很鸡肋,实际项目中应该很少用到它,最大的原因我觉得莫过于其输出的视频分辨率太有限了,满足不了项目的 ...
- 快速入门系列--WebAPI--03框架你值得拥有
接下来进入的是俺在ASP.NET学习中最重要的WebAPI部分,在现在流行的互联网场景下,WebAPI可以和HTML5.单页应用程序SPA等技术和理念很好的结合在一起.所谓ASP.NET WebAPI ...
- linux入门系列12--磁盘管理之分区、格式化与挂载
前面系列文章讲解了VI编辑器.常用命令.防火墙及网络服务管理,本篇将讲解磁盘管理相关知识. 本文将会介绍大量的Linux命令,其中有一部分在"linux入门系列5--新手必会的linux命令 ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- Go语言入门系列(五)之指针和结构体的使用
Go语言入门系列前面的文章: Go语言入门系列(二)之基础语法总结 Go语言入门系列(三)之数组和切片 Go语言入门系列(四)之map的使用 1. 指针 如果你使用过C或C++,那你肯定对指针这个概念 ...
- 机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测
1. 机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测 1.1 LightGBM原理简介 LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个 ...
随机推荐
- 《Kali渗透基础》06. 主动信息收集(三)
@ 目录 1:服务识别 1.1:NetCat 1.2:Socket 1.3:dmitry 1.4:nmap 2:操作系统识别 2.1:Scapy 2.2:nmap 2.3:p0f 3:SNMP 扫描 ...
- 多重断言插件之pytest-assume的简单使用
背景: pytest-assume是Pytest框架的一个扩展,它允许在单个测试用例中多次断言.通常情况下,当一个断言失败时,测试会立即停止执行,而pytest-assume允许我 们继续执行剩余的断 ...
- pythonapi接口怎么对接?
Python API接口对接是使用Python语言开发应用程序时,与外部API接口进行交互的一种方式.API(应用程序接口)是一种定义了程序或系统如何与另一个程序或系统进行交互的协议.通过使用Py ...
- phpstudy搭建虚拟域名
phpstudy搭建虚拟域名 先使用phpstudy搭建好对应的环境 打开phpstudy控制面板,点击 其他选项菜单,选择 站点域名管理 输入网站虚拟域名,比如我这里DVWA靶场,我就写 www.d ...
- Solidity-变量和数据类型[复合类型_1]
复合类型的数据包括:array(数组).struct(结构体)和mapping(映射),其中array和struct也称为引用类型. 复合类型 数组(array) 数组(array)是一种用于存储相同 ...
- 简化车辆登记流程:利用腾讯云OCR实现自动化信息识别
项目中有一块,需要用到上传车牌车牌号到系统里,用了下腾讯云的ocr车牌号识别做了个小功能.通过腾讯云的orc识别,将车牌号录入到后台. 一,首先我们需要登录到腾讯云,然后搜索一下orc或者车牌号 ...
- 基于间隔密度的概念漂移检测算法mdm-DDM
概念漂移 概念漂移是数据流挖掘领域中一个重要的研究点.传统的机器学习算法在操作时通常假设数据是静态的,其数据分布不会随着时间发生变化.然而对于真实的数据流来说,由于数据流天生的时间性,到达的数据的 ...
- MySQL实战实战系列 04 深入浅出索引(上)
提到数据库索引,我想你并不陌生,在日常工作中会经常接触到.比如某一个 SQL 查询比较慢,分析完原因之后,你可能就会说"给某个字段加个索引吧"之类的解决方案.但到底什么是索引,索引 ...
- 开源.NetCore通用工具库Xmtool使用连载 - 扩展动态对象篇
[Github源码] <上一篇> 介绍了Xmtool工具库中的图形验证码类库,今天我们继续为大家介绍其中的扩展动态对象类库. 扩展动态对象是整个工具库中最重要的一个设计.在软件开发过程中, ...
- linux常见命令(四)
用于查看日期和时间的相关命令 cal date hwclock cal:显示日历信息 命令语音:cal [选项] [[[日]月]年] 选项 选项含义 -j 显示出给定月中的每一天是一年总的第几天(从1 ...