PSS:你距离NMS-free+提点只有两个卷积层 | 2021论文
论文提出了简单高效的PSS分支,仅需在原网络的基础上添加两个卷积层就能去掉NMS后处理,还能提升模型的准确率,而stop-grad的训练方法也挺有意思的,值得一看
来源:晓飞的算法工程笔记 公众号
论文: Object Detection Made Simpler by Eliminating Heuristic NMS

Introduction
当前主流的目标检测算法训练时大都一个GT对应多个正样本,使得推理时也会多个输出对应一个目标,不得不对结果进行NMS过滤。而论文的目标是设计一个简单的高性能全卷积网络,在不使用NMS情况下,能够进行完全的端到端训练。论文提出的方法十分简单,核心在于添加一个正样本选择分支(positive sample selector, PSS)。
论文的主要贡献如下:
- 检测流程在去掉NMS后变得更加简单,从FCOS到FCOS\(_{PSS}\)的修改能植入到其他的FCN解决方案中。
- 实验证明可以通过引入简单的PSS分支来代替NMS,植入FCOS仅需增加少量的计算量。
- PSS分支十分灵活,本质上相当于可学习的NMS,由于加入PSS分支没有影响到原有结构,可直接去掉PSS分支直接使用NMS。
- 在COCO上,得到与FCOS、ATSS以及最近的NMS-free方法相当或更好的结果。
- 提出的PSS分支可应用于其他anchor-based检测器中,在每个位置一个anchor box的设定下,仅通过PSS分支的动态训练样本选择也能达到不错的结果。
- 同样的想法也可用于其他目标识别任务中,如去掉实例分割中的NMS操作。
Our Method

FCOS\(_{PSS}\)的整体结构如图1所示,仅在FCOS的基础上添加了包含两个卷积层的SPP分支。
Overall Training Objective
完整的训练损失函数为:

\(\mathcal{L}_{fcos}\)为原版FCOS的损失项,包含分类损失、回归损失和center-ness损失。此外,还有PSS分支损失和ranking损失。在训练时\(\lambda_2\)设置为0.25,因为ranking损失对准确率只有些许提升。
PSS损失
PSS分支是NMS-free的关键,如图1所示,该分支的特征图输出为\(\mathbb{R}^{H\times W\times 1}\)。定义\(\sigma(pss)\)为特征图上的一个点,仅当该点为正样本时才设为1,所以可以把PSS分支当作二分类加入训练。但为了借用FCOS多分类的优势,论文将其与分类特征、center-ness特征进行融合:
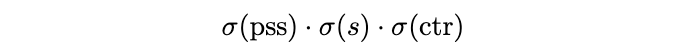
用上面的分数计算focal loss,与原本的FCOS分类的区别是,这里每个GT有且仅有一个正样本。
Ranking损失
论文通过实验发现,在训练时加入ranking损失能提升性能,ranking损失的定义为:

\(\gamma\)代表正负样本间的距离,默认设置为0.5。\(n_{+}\)和\(n_{-}\)为正负样本数量,\(\hat{P}_{i_{+}}(c_{i_{+}})\)为正样本\(i_{+}\)对应类别\(c_{i_{+}}\)的分类分数,\(\hat{P}_{i_{-}}(c_{i_{-}})\)为负样本\(i_{-}\)对应类别\(c_{i_{-}}\)的分类分数。在实验中,取top 100负样本分数进行计算。
One-to-many Label Assignment
一个GT选择多个anchor作为正样本进行训练是当前目标检测广泛采用的一种做法,这样的做法能够极大地简化标注要求,同时也能够兼容数据增强。即使标注位置有些许偏差,也不会改变选择的正样本。另外,多个正样本能够提供更丰富的特征,帮助训练更强大的分类器,比如尺寸不变性、平移不变性。因此,对于原生的FCOS分支的训练依然采用一对多的方式。
One-to-one Label Assignment
一对一的训练方式需要每次为GT选择最佳正样本,选择的时候需要考虑分类匹配程度和定位匹配程度,这里,先定义一个匹配分数\(Q_{i,j}\):

\(i\)为预测框编号,\(j\)为GT编号,超参数\(\alpha\)用来调整分类和定位间的比值。\(\Omega_j\)表示GT \(j\)的候选正样本,采用FCOS的规则,在GT的中心区域的点对应的anchor均为候选正样本。最后,对所有的GT及其正样本采用二分图匹配,通过匈牙利算法选择最大化\(\sum_{j}Q_{i,j}\)的匹配方案。
Conflict in the Two Classification Loss Terms
在论文提出的方案中,损失项\(\mathcal{L}_{fcos}\)采用一对多的匹配方案,而损失项\(\mathcal{L}_{pss}\)采用一对一的匹配方案,这意味着有部分anchor可能会被同时划分为正样本和负样本,导致模型难以收敛。为此,论文提出了stop-grad的概念,即阻止PSS分支的梯度回传到FCOS中。
Stop Gradient
stop-gradient操作在训练的时候将其中一部分网络设置为常数,定义\(\theta=\{\theta_{fcos},\theta_{pss}\}\)为网络需要优化的参数,训练的目标是求解:

将上述求解分成两个步骤:

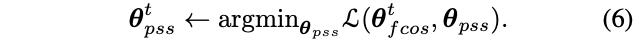
即在一轮迭代中,交替优化参数\(\theta_{fcos}\)和\(\theta_{pss}\)。比如在求解公式5时,\(\theta_{pss}\)的梯度置为零,按作者的说法,这块直接用pytorch的detach()进行分离。另外一种方法是直接分开训练,当求解公式5时,设置\(\theta_{pss}=0\)直到收敛,等同于原本的FCOS训练。而在训练PSS分支时,冻结FCOS参数直到收敛。论文通过实验发现分开训练可以极大地缩短训练时间,但性能稍差些。
Experiment
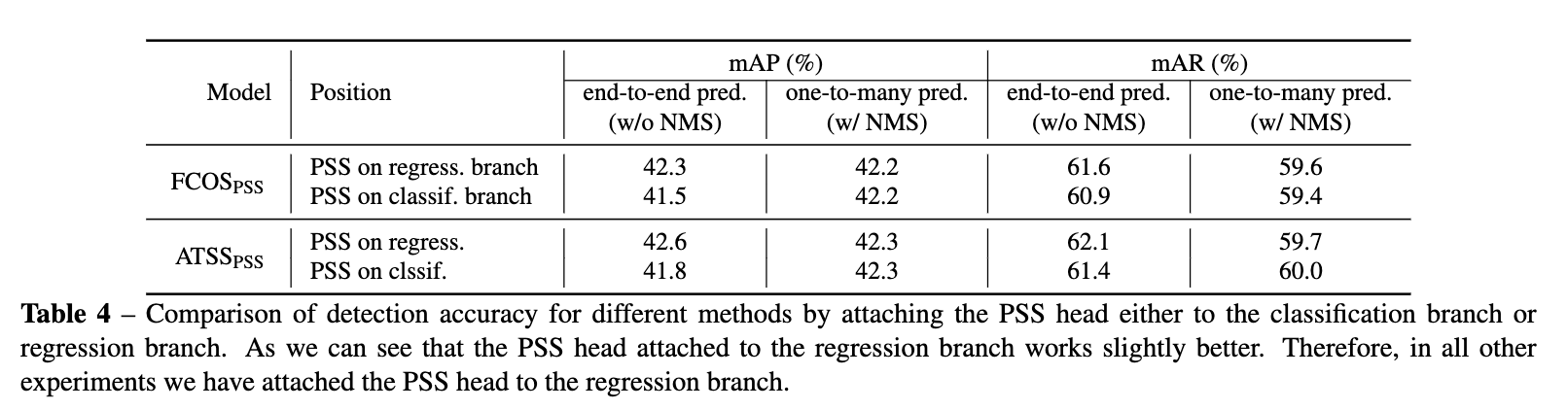
从论文的实验来看,PSS分支+stop grad的效果还是不错的。论文还有很大对比实验,有兴趣的可以去看看。
Conclusion
论文提出了简单高效的PSS分支,仅需在原网络的基础上添加包含两个卷积层就能去掉NMS后处理,还能提升模型的准确率,而stop-grad的训练方法也挺有意思的,值得一看。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

PSS:你距离NMS-free+提点只有两个卷积层 | 2021论文的更多相关文章
- jQuery为开发插件提拱了两个方法:jQuery.fn.extend(); jQuery.extend();
jQuery为开发插件提拱了两个方法,分别是: jQuery.fn.extend(); jQuery.extend(); jQuery.fn jQuery.fn = jQuery.prototype ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- YOLOv1到YOLOv3的演变过程及每个算法详解
1,YOLOv1算法的简介 YOLO算法使用深度神经网络进行对象的位置检测以及分类,主要的特点是速度够快,而且准确率也很高,采用直接预测目标对象的边界框的方法,将候选区和对象识别这两个阶段合二为一, ...
- 卷积神经网络(CNN)在句子建模上的应用
之前的博文已经介绍了CNN的基本原理,本文将大概总结一下最近CNN在NLP中的句子建模(或者句子表示)方面的应用情况,主要阅读了以下的文献: Kim Y. Convolutional neural n ...
- 论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)
论文原址:https://arxiv.org/abs/1902.05093 github:https://github.com/lingtengqiu/Deeperlab-pytorch 摘要 本文提 ...
- CNN 模型压缩与加速算法综述
本文由云+社区发表 导语:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一. 前言 自从AlexNet一举夺得 ...
- Faster RCNN代码理解(Python)
转自http://www.infocool.net/kb/Python/201611/209696.html#原文地址 第一步,准备 从train_faster_rcnn_alt_opt.py入: 初 ...
- [置顶]
Deep Learning 学习笔记
一.文章来由 好久没写原创博客了,一直处于学习新知识的阶段.来新加坡也有一个星期,搞定签证.入学等杂事之后,今天上午与导师确定了接下来的研究任务,我平时基本也是把博客当作联机版的云笔记~~如果有写的不 ...
- Object Detection: To Be Higher Accuracy and Faster
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/51597496 在深度学习中有一类研究热 ...
- 中文版 R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN: Object Detection via Region-based Fully Convolutional Networks 摘要 我们提出了基于区域的全卷积网络,以实现准确和高效的目标 ...
随机推荐
- 细说 QUEST CENTRAL FOR DB2 八宗罪
作为一个从事oracle plsql开发2年的程序员,如今跳槽从事DB2数据仓库项目. 以PL/SQL Developer为参考,以下简称PLSQL,细说QUEST CENTRAL FOR DB2 5 ...
- Go微服务框架go-kratos实战学习07:consul 作为服务注册和发现中心
一.Consul 简介 consul 是什么 HashiCorp Consul 是一种服务网络解决方案,它能够管理服务之间以及跨本地和多云环境和运行时的安全网络连接.Consul 它能提供服务发现.服 ...
- redis7源码分析:redis 单线程模型解析,一条get命令执行流程
有了下文的梳理后 redis 启动流程 再来解析redis 在单线程模式下解析并处理客户端发来的命令 1. 当 client fd 可读时,会回调readQueryFromClient函数 void ...
- stat模块
# stat模块定义了常数和函数,并用这些来解释os.stat().os.fstat()和os.lstat()的结果(如果这些在该平台上存在的话). stat.S_ISREG(mode) # 判断mo ...
- 安装SQL Server 具有不支持的属性(Compressed)集。
安装sqlserver 2014报错信息 D:\Program Files\Microsoft SQL Server 具有不支持的属性(Compressed)集.请通过使用文件夹属性对话框从该文件夹中 ...
- kafka节点故障恢复原理
Kafka的LEO和HW LEO LEO是Topic每一个副本的最后的偏移量offset+1 HW(高水位线) High WaterMark是所有副本中,最小的LEO Follower副本所在节点宕机 ...
- 【Azure 媒体服务】在Azure Media Service门户中使用HLS模式传输视频流,播放视频步骤
问题描述 如何在Azure Media Service门户中使用HLS模式传输视频流,播放视频步骤 问题解决 第一步:在 Media Service 这边点击资产.上传本地视频资源作为Media Se ...
- rpa:小红书为例讲解界面选取和界面库选取两种元素选择方式的区别执行js获取数据
上文有讲到rpa从安装到第一个小例子的运行,这篇文章我们讲解rpa的两种元素选择方式说明:界面选取和界面库选取. 首先,我们需要知道为什么需要选取元素,以及选取了元素之后有什么作用? 现在有一种这样的 ...
- Rust 开发的高性能 Python 包管理工具,可替换 pip、pip-tools 和 virtualenv
最近,我在 Python 潮流周刊 中分享了一个超级火爆的项目,这还不到一个月,它在 Github 上已经拿下了 8K star 的亮眼成绩,可见其受欢迎程度极高!国内还未见有更多消息,我趁着周末把一 ...
- 万字博文让我们携手一起走进bs4的世界【python Beautifulsoup】bs4入门 find()与find_all()
目录 Beautiful Soup BeautifulSoup类的基本元素 1.Tag的name 2.Tag的attrs(属性) 3.Tag的NavigableString 二.遍历文档树 下行遍历 ...