ThreadLocal 核心源码分析
ThreadLocal 简介
多线程访问同一个共享变量的时候容易出现并发问题,特别是多个线程对一个变量进行写入的时候,为了保证线程安全,一般使用者在访问共享变量的时候需要进行额外的同步措施才能保证线程安全性。ThreadLocal是除了加锁这种同步方式之外的一种保证和规避多线程访问出现线程不安全的方法。当我们在创建一个变量后,如果每个线程对其进行访问的时候访问的都是线程自己的变量这样就不会存在线程不安全问题。
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。
ThreadLocal为变量在每个Thread都创建了一个副本,每个Thread内有自己的实例副本,且该副本只能由当前Thread使用,那就不存在多线程间共享的问题。
ThreadLocal 与 Synchronized 的区别
虽然ThreadLocal模式与Synchronized关键字都用于处理多线程并发访问变量的问题,不过两者处理问题的角度和思路不同。
| Synchronized | ThreadLocal | |
| 原理 | 同步机制采用【以空间换时间】的方式,只提供了一份变量,让不同的线程排队访问 | ThreadLocal采用【以空间换时间】的概念,为每个线程都提供一份变量副本,从而实现同时访问而互不干扰 |
| 侧重点 | 多个线程之间访问资源的【同步】 | 多线程中让每个线程之间的数据相互【隔离】 |
ThreadLocal的内部结构
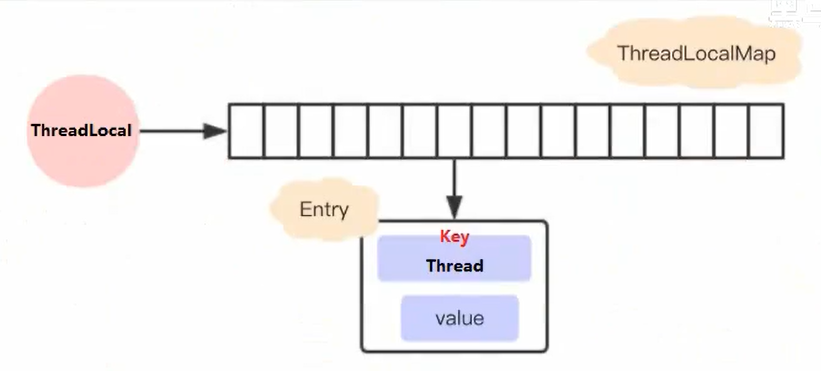
早期的设计
如果我们不去看源代码的话,可能会猜测ThreadLocal是这样子设计的:每个ThreadLocal都创建一个Map,然后用线程作为Map的key,要存储的局部变量作为Map的value,这样就能达到各个线程的局部变量隔离的效果。这是最简单的设计方法,JDK最早期的ThreadLocal确实是这样设计的,但现在早已不是了。
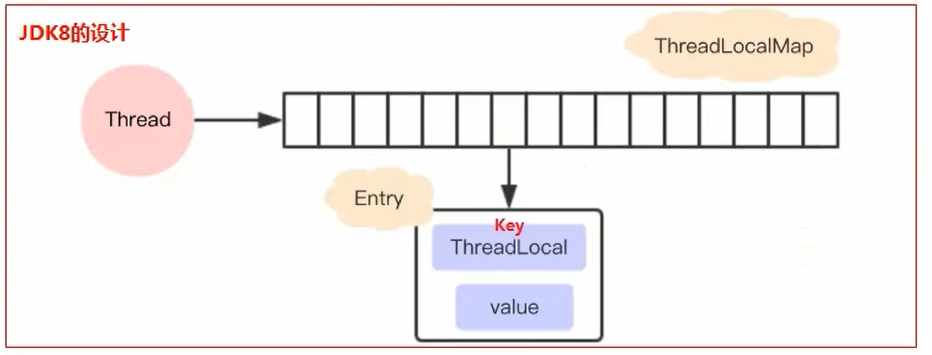
现在的设计
JDK后面优化了设计方案,JDK8中ThreadLocal的设计是:每个Thread维护一个ThreadLocalMap,这个Map的key是ThreadLocal实例本身,value才是真正要存储的值object。具体的过程是这样的:
➹ 每个Thread线程内部都有一个Map(ThreadLocalMap)。
➹ Map里面存储ThreadLocal对象(key)和线程的变量副本(value)。
➹ Thread内部的Map是由ThreadLocal维护的,由ThreadLocal负责向map获取和设置线程的变量值。
➹ 对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成了副本的隔离,互不干扰。
新旧对比
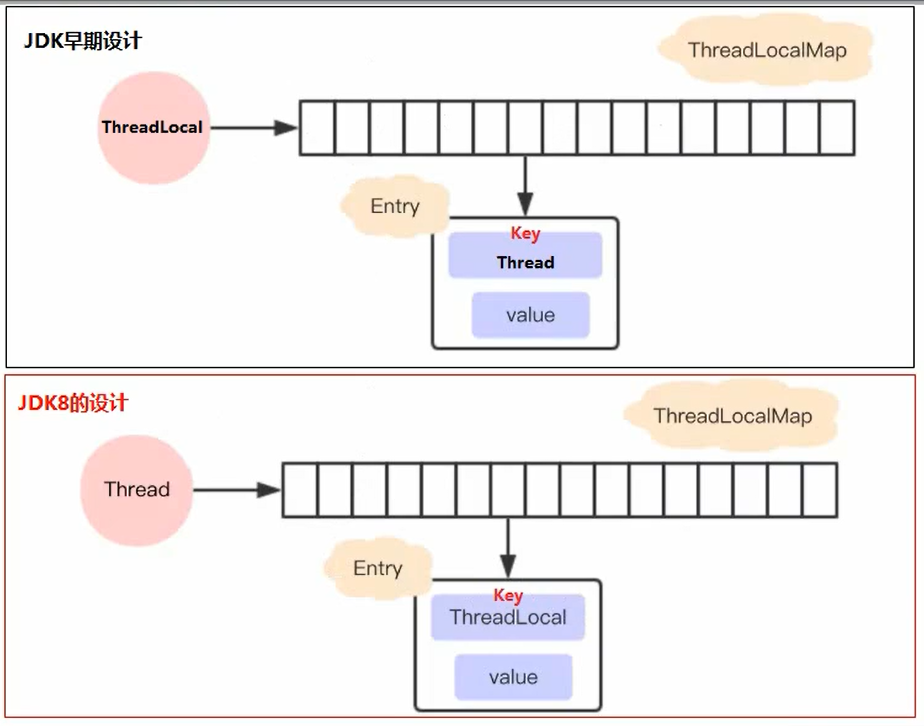
从上面变成JDK8的设计有什么好处?
☂ 每个Map存储的Entry数量变少,因为原来的Entry数量是由Thread决定,而现在是由ThreadLocal决定的。
☃ 真实开发中,Thread的数量远远大于ThreadLocal的数量。
☂ 当Thread销毁的时候,ThreadLocalMap也会随之销毁,因为ThreadLocal是存放在Thread中的,随着Thread销毁而消失,能降低开销。
ThreadLocal核心方法的源码
基于ThreadLocal的内部结构,我们继续分析它的核心方法源码,更深入的了解其操作原理。 除了构造方法之外,ThreadLocal对外暴露的方法有以下4个:
|
方法声明
|
描述
|
|---|---|
|
protected T initialValue()
|
返回当前线程局部变量的初始值
|
|
public void set(T value)
|
返回当前线程绑定的局部变量
|
|
public T get()
|
获取当前线程绑定的局部变量
|
|
public void remove()
|
移除当前线程绑定的局部变量
|
以下是这4个方法的详细源码分析:
set方法
/**
* 设置当前线程对应的ThreadLocal的值
* @param value: 将要保存在当前线程对应的ThreadLocal的值
*/
public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLoca1Map对象
ThreadLocalMap map = getMap(t);
// 判断map是否存在
if (map != null) {
// 存在则调用map.set设置此实体entry
map.set(this, value);
} else {
// 1、当前线程Thread不存在ThreadLocalMap对象
// 2、则调用createMap进行ThreadLocalMap对象的初始化
// 3、并将t(当前线程)和va1ue(t对应的值)作为第一个entry存放至ThreadLocalMap中
createMap(t, value);
}
} /**
* 获取当前线程Thread对应维护的ThreadLocalMap
* @param t: 当前线程
* @return 对应维护的ThreadLocalMap
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
} /**
* 创建当前线程Thread对应维护的ThreadLocalMap
* @param t: 当前线程
* @param firstValue: 存放到map中第一个entry的值
*/
void createMap(Thread t, T firstValue) {
// 这里的this是调用此方法的threadLocal
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
set()方法执行流程:
1、首先获取当前线程,并根据当前线程获取一个Map。
2、如果获取的Map不为空,则将参数设置到Map中(当前ThreadLocal的引用作为key)。
3、如果Map为空,则给该线程创建Map,并设置初始化值。
get方法
/**
* 返回当前线程对应此ThreadLocal的值
* @return
*/
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 如果此map存在
if (map != null) {
// 以当前的ThreadLocal为key,调用getEntry获取对应的存储实体e
ThreadLocalMap.Entry e = map.getEntry(this);
// 对e进行判空
if (e != null) {
@SuppressWarnings("unchecked")
// 获取存储实体e对应的 value值,即为我们想要的当前线程对应此ThreadLoca1的值
T result = (T)e.value;
return result;
}
}
// 初始化: 有两种情况要执行当前代码
// 第一种情况: map不存在,表示此线程没有维护的ThreadLocalMap对象
// 第二种情况: map存在,但是没有与当前ThreadLocal关联的entry
return setInitialValue();
} /**
* 初始化
* @return 初始化后的值
*/
private T setInitialValue() {
// 调用initialValue获取初始化的值
// 此方法可以被子类重写,如果不重写默认返回nu11
T value = initialValue();
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 判断map是否存在
if (map != null) {
// 存在,则调用map.set设置此实体entry
map.set(this, value);
} else {
// 1、当前线程Thread不存在ThreadLocalMap对象
// 2、则调用createMap进行ThreadLocalmap对象的初始化
// 3、并将t(当前线程)和value(t对应的值)作为第一个entry存放至ThreadLocalMap中
createMap(t, value);
}
// 判断this的类型是否属于TerminatingThreadLocal
if (this instanceof TerminatingThreadLocal) {
// 将this进行注册到TerminatingThreadLocal类中
TerminatingThreadLocal.register((TerminatingThreadLocal<?>) this);
}
// 返回设置的值value
return value;
}
get()方法执行流程:
1、首先获取当前线程,根据当前线程获取一个Map。
2、如果获取的Map不为空,则在Map中以ThreadLocal的引用作为key来在Map中获取对应的Entrye,否则转到第4步。
3、如果e不为null,则返回e.value,否则转到第4步。
4、Map为空或者e为空,则通过initialValue函数获取初始值value,然后用ThreadLocal的引用和value作为firstKey和firstValue创建一个新的Map。
setInitialValue()方法的执行逻辑为:
1、获取到value值(这里使用的initialValue默认返回null)。
2、获取到当前线程,根据当前线程查询是否有对应的map。
3、如果当前线程有对应的map,那么就更新值,否则的话就进行创建。
4、最后instance of关键字用来判断this的类型是否属于TerminatingThreadLocal。如果this属于是TerminatingThreadLocal类型的,那么就调用register方法将this进行注册到TerminatingThreadLocal类中。
最后的这段代码用于将终止类型的ThreadLocal实例注册到TerminatingThreadLocal类的静态列表中。这样,在线程退出时,终止类型的ThreadLocal实例会自动从ThreadLocalMap中移除,避免内存泄漏。
总结:
先获取当前线程的ThreadLocal变量,如果存在则返回值,不存在则创建并返回初始值。
remove方法
/**
* 删除当前线程中保存的ThreadLocal对应的实体entry
*/
public void remove() {
// 获取当前线程对象中维护的ThreadLocalMap对象
ThreadLocalMap m = getMap(Thread.currentThread());
// 如果此map存在
if (m != null) {
// 存在则调用map.remove,以当前ThreadLocal为key删除对应的实体entry
m.remove(this);
}
}
remove()方法执行流程:
1、首先获取当前线程,并根据当前线程获取一个Map。
2、如果获取的Map不为空,则移除当前ThreadLocal对象对应的Entry。
initialValue方法
/**
* 返回当前线程对应的ThreadLocal的初始值
*
* 此方法的第一次调用发生在,当线程通过get方法访问此线程的ThreadLoca1值时
* 除非线程先调用了set方法,在这种情况下,initia1Value才不会被这个线程调用。
* 通常情况下,每个线程最多调用一次这个方法。
*
* <p>这个方法仅仅简单的返回nu1l {@code nu11};
* 如果程序员想ThreadLoca1线程局部变量有一个除nu11以外的初始值
* 必须通过子类继承{@code ThreadLoca1} 的方式去重写此方法
* 通常,可以通过匿名内部类的方式实现
*
* @return 当前ThreadLocal的初始值
*/
protected T initialValue() {
return null;
}
initialValue()方法的作用是返回该线程局部变量的初始值:
✎ 这个方法是一个延迟调用方法,从上面的代码我们得知,在set方法还未调用而先调用了get方法时才执行,并且仅执行1次。
✎ 这个方法缺省实现直接返回一个null。
✎ 如果想要一个除null之外的初始值,可以重写此方法。(备注:该方法是一个protected的方法,显然是为了让子类覆盖而设计的)
ThreadLocalMap源码分析
在分析ThreadLocal方法的时候,我们了解到ThreadLocal的操作实际上是围绕ThreadLocalMap展开的。ThreadLocalMap的源码相对比较复杂,我们从以下三个方面进行讨论。
基本结构
ThreadLocalMap是ThreadLocal的内部类,没有实现Map接口,用独立的方式实现了Map的功能,其内部的Entry也是独立实现。
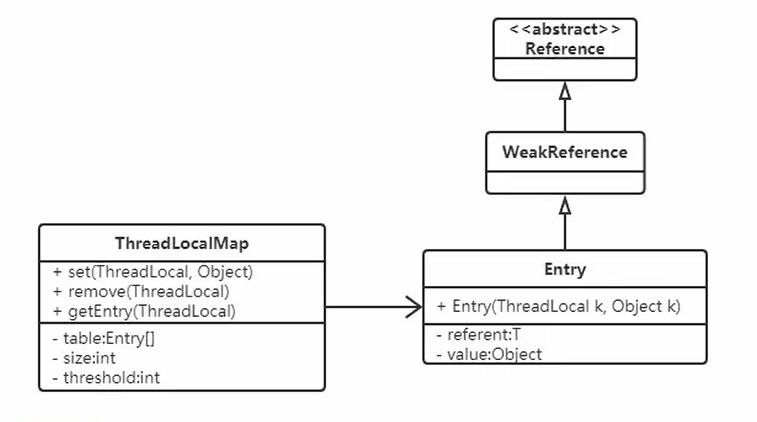
成员变量
/**
* 初始容量 - 必须是2的整次幂
**/
private static final int INITIAL_CAPACITY = 16; /**
*存放数据的table ,Entry类的定义在下面分析,同样,数组的长度必须是2的整次幂
**/
private Entry[] table; /**
*数组里面entrys的个数,可以用于判断table当前使用量是否超过阈值
**/
private int size = 0; /**
*进行扩容的阈值,表使用量大于它的时候进行扩容
**/
private int threshold; // Default to 0
跟HashMap类似, INITIAL_CAPACITY 代表这个Map的初始容量; table 是一个Entry类型的数组,用于存储数据; size 代表表中的存储数目; threshold 代表需要扩容时对应的size的阈值。
存储结构 - Entry
/*
* Entry继承WeakRefefence,并且用ThreadLocal作为key。
* 如果key为nu11(entry.get()==nu11),意味着key不再被引用,
* 因此这时候entry也可以从table中清除。
*/
static class Entry extends weakReference<ThreadLocal<?>>{
object value; Entry(ThreadLocal<?>k,object v){
super(k);
value = v;
}
}
在ThreadLocalMap中,也是用Entry来保存K-V结构数据的。不过Entry中的key只能是ThreadLocal对象,这点在构造方法中已经限定死了。
另外,Entry继承WeakReference,也就是key(ThreadLocal)是弱引用,其目的是将ThreadLocal对象的生命周期和线程生命周期解绑。
弱引用和内存泄漏
有些程序员在使用ThreadLocal的过程中会发现有内存泄漏的情况发生,就猜测这个内存泄漏跟Entry中使用了弱引用的key有关系,这个理解其实是不对的。
我们先来回顾这个问题中涉及的几个名词概念,再来分析问题。
内存泄漏相关概念
内存溢出(Memory overflow):是指没有足够的内存提供申请者使用。
内存泄漏(Memory leak):是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统溃等严重后果。内存泄漏的堆积终将导致内存溢出。
弱引用相关概念
Java中的引用有4种类型:强、软、弱、虚。当前这个问题主要涉及到强引用和弱引用:
强引用(Strong Reference):就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾回收器就不会回收这种对象。
弱引用(Weak Reference):垃圾回收器一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
如果key使用强引用,会出现内存泄漏吗?
假设ThreadLocalMap中的key使用了强引用,那么会出现内存泄漏吗?此时ThreadLocal的内存图(实线表示强引用)如下:
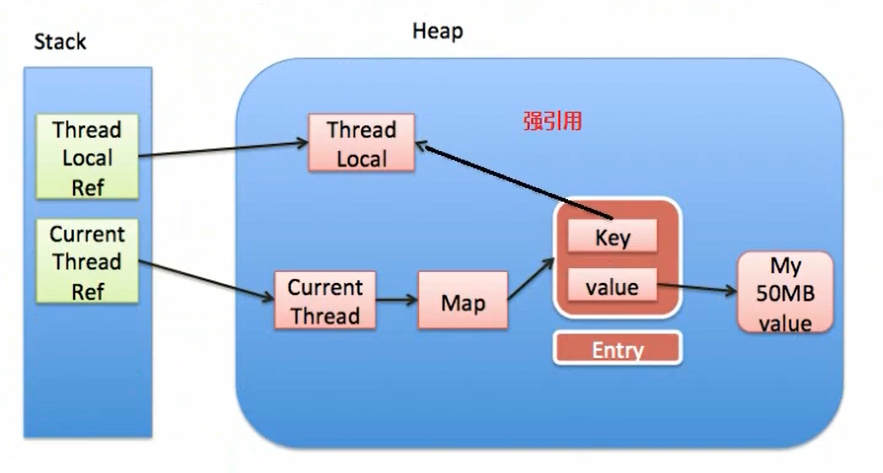
假设在业务代码中使用完了ThreadLocal,ThreadLocal Ref被回收,但是,由于ThreadLocalMap的Entry强引用了ThreadLocal,造成threadLocal对象无法被回收。
因此,在没有手动删除这个Entry以及CurrentThread依然运行的前提下,始终有强引用链CurrentThread Ref->CurrentThread->ThreadLocalMap->Entry ,Entry就不会被回收(Entry中包括了ThreadLocal实例和value),导致Entry内存泄漏。
也就是说,ThreadLocalMap中的key使用了强引用,无法完全避免内存泄漏。
如果key使用弱引用,会出现内存泄漏吗?
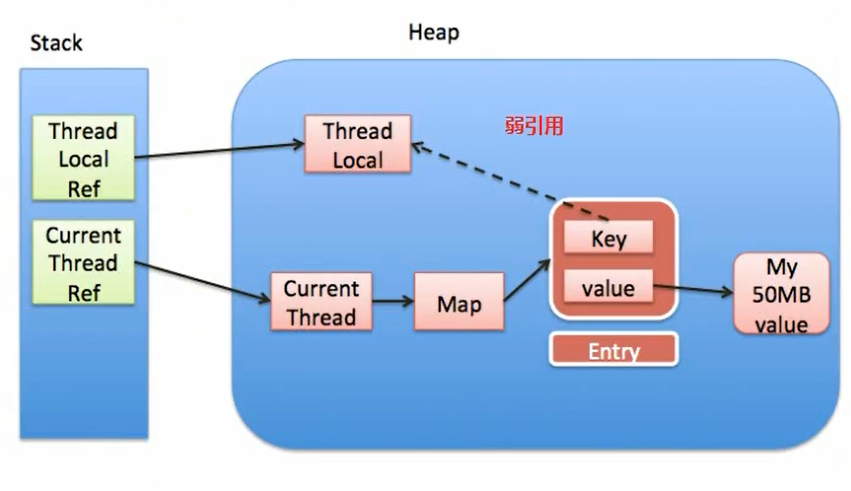
同样假设在业务代码中使用完了ThreadLocal,ThreadLocal Ref被回收了。由于ThreadLocalMap只持有ThreadLocal的弱引用,没有任何强引用指向threadlocal实例,所以Threadlocal就可以顺利被GC回收,此时Entry中的key=null。
但是,在没有手动删除这个Entry以及CurrentThread依然运行的前提下,也存在有强引用链 CurrentThread Ref->CurrentThread->ThreadLocalMap->Entry->value ,value不会被回收,而这块value永远不会被访问到了,导致value内存泄漏。
也就是说,ThreadLocalMap中的key使用了弱引用,也有可能内存泄漏。
出现内存泄漏的真实原因
比较以上两种情况,我们就会发现,内存泄漏的发生跟ThreadLocalMap中的key是否使用弱引用是没有关系的。那么内存泄漏的的真正原因是什么呢?
我们会发现,在以上两种内存泄漏的情况中,都有两个前提:
✘ 没有手动删除这个Entry。
✘ CurrentThread依然运行。
第一点很好理解,只要在使用完ThreadLocal,调用其remove方法删除对应的Entry,就能避免内存泄漏。
第二点稍微复杂一点,由于ThreadLocalMap是Thread的一个属性,被当前线程所引用,所以它的生命周期跟Thread一样长。那么在使用完ThreadLocal的使用,如果当前Thread也随之执行结束,ThreadLocalMap自然也会被GC回收,从根源上避免了内存泄漏。
综上,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread-样长,如果没有手动删除对应key就会导致内存泄漏。
为什么要使用弱引用?
根据刚才的分析,我们知道了:无论ThreadLocalMap中的key使用哪种类型引用都无法完全避免内存泄漏,跟使用弱引用没有关系。
要避免内存泄漏有两种方式:
使用完ThreadLocal,调用其remove方法删除对应的Entry。
使用完ThreadLocal,当前Thread也随之运行结束。
相对第一种方式,第二种方式显然更不好控制,特别是使用线程池的时候,线程结束是不会销毁的,而是接着放入了线程池中。
也就是说,只要记得在使用完ThreadLocal及时的调用remove,无论key是强引用还是弱引用都不会出现内存泄漏问题。
那么为什么key要用弱引用呢?
事实上,在ThreadLocalMap中的set/get方法中,会对key为null(也即是ThreadLocal为null)进行判断,如果为null的话,那么是会对value置为null。
这就意味着使用完ThreadLocal,CurrentThread依然运行的前提下,就算忘记调用remove方法,弱引用比强引用可以多一层保障:弱引用的ThreadLocal会被回收,对应的value在下一次ThreadLocalMap调用set、get、remove中的任一方法的时候会被清除,从而避免内存泄漏。
Hash冲突的解决
Hash冲突的解决是Map中的一个重要内容。我们以Hash冲突的解决为线索,来研究一下ThreadLocalMap的核心源码。
首先从ThreadLocal的set方法入手:
ThreadLocal的set方法
/**
* 设置当前线程对应的ThreadLocal的值
* @param value: 将要保存在当前线程对应的ThreadLocal的值
*/
public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的ThreadLoca1Map对象
ThreadLocalMap map = getMap(t);
// 判断map是否存在
if (map != null) {
// 存在则调用map.set设置此实体entry
map.set(this, value);
} else {
// 1、当前线程Thread不存在ThreadLocalMap对象
// 2、则调用createMap进行ThreadLocalMap对象的初始化
// 3、并将t(当前线程)和va1ue(t对应的值)作为第一个entry存放至ThreadLocalMap中
createMap(t, value);
}
} /**
* 获取当前线程Thread对应维护的ThreadLocalMap
* @param t: 当前线程
* @return 对应维护的ThreadLocalMap
*/
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
} /**
* 创建当前线程Thread对应维护的ThreadLocalMap
* @param t: 当前线程
* @param firstValue: 存放到map中第一个entry的值
*/
void createMap(Thread t, T firstValue) {
// 这里的this是调用此方法的threadLocal
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
这个方法我们刚才分析过,其作用是设置当前线程绑定的局部变量。
1、首先获取当前线程,并根据当前线程获取一个Map。
2、如果获取的Map不为空,则将参数设置到Map中(当前ThreadLocal的引用作为key)(这里调用了ThreadLocalMap的set方法)。
3、如果Map为空,则给该线程创建Map,并设置初始值(这里调用了ThreadLocalMap的构造方法)。
这段代码有两个地方分别涉及到ThreadLocalMap的两个方法,我们接着分析这两个方法
ThreadLocalMap的构造方法
/**
* @param firstKey: 本ThreadLocal实例(this)
* @param firstValue: 要保存的线程本地变量
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化table
table = new Entry[INITIAL_CAPACITY];
// 计算索引(重点代码)
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 设置值
table[i] = new Entry(firstKey, firstValue);
size = 1;
// 设置阈值
setThreshold(INITIAL_CAPACITY);
}
构造函数首先创建一个长度为16的Entry数组,然后计算出firstKey对应的索引,然后存储到table中,并设置size和threshold。
重点分析: int i = firstKey.threadLocalHashCode & ( INITIAL_CAPACITY - 1)
关于:threadLocalHashCode
private final int threadLocalHashCode = nextHashCode(); /**
* AtomicInteger是一个提供原子操作的Integer类,通过线程安全的方式操作加减,适合高并发情况下的使用
*/
private static AtomicInteger nextHashCode =
new AtomicInteger(); /**
* 特殊的hash值
*/
private static final int HASH_INCREMENT = 0x61c88647; private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
这里定义了一个Atomiclnteger类型,每次获取当前值并加上 HASH_INCREMENT , HASH_INCREMENT = 0x61c88647 ,这个值跟斐波那契数列(黄金分割数)有关,其主要目的就是为了让哈希码能均匀的分布在2的n次方的数组里,也就是Entry table中,这样做可以尽量避免hash冲突。
关于:threadLocalHashCode &(INITIAL_CAPACITY-1)
计算hash的时候里面采用了 hashCode &(size-1) 的算法,这相当于取模运算 hashCode % size 的一个更高效的实现。正是因为这种算法,我们要求size必须是2的整次幂,这也能保证保证在索引不越界的前提下,使得hash发生冲突的次数减小。
ThreadLocalMap的Get方法
/**
* ThreadLocalMap的set方法
* @param key
* @param value
*/
private void set(ThreadLocal<?> key, Object value) { Entry[] tab = table;
int len = tab.length;
// 计算索引(重点代码,刚才分析过了)
int i = key.threadLocalHashCode & (len-1);
// 使用线性探测法查找元素(重点代码)
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
// 若ThreadLocal对应的 key 存在,直接覆盖之前的值
if (e.refersTo(key)) {
e.value = value;
return;
}
// 若key为nu11,但是值不为nu11,说明之前的ThreadLocal对象已经被回收了
// 当前数组中的 Entry 是一个陈旧(stale)的元素
if (e.refersTo(null)) {
// 用新元素替换陈旧的元素,这个方法进行了不少的垃圾清理动作,防止内存泄漏
replaceStaleEntry(key, value, i);
return;
}
}
// ThreadLocal对应的key不存在并且没有找到陈旧的元素,则在空元素的位置创建一个新的Entry.
tab[i] = new Entry(key, value);
int sz = ++size;
// cleansomeslots用于清除那些e.get()==nu11的元素,
// 这种数据key关联的对象已经被回收,所以这个Entry(table[index])可以被置nu11。
// 如果没有清除任何entry,并且当前使用量达到了负载因子所定义的值(长度的2/3),那么进行rehash(执行一次全表的扫描清理工作)
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
} /**
* 获取环形数组的下一个索引
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
ThreadLocalMap的Get方法代码执行流程:
1、首先还是根据key计算出索引i,然后查找位置上的Entry。
2、若是Entry已经存在,并且key等于传入的key,那么这时候直接给这个Entry赋新的value值。
3、若是Entry已经存在,但是key为null,则调用replaceStaleEntry来更换这个key为空的Entry。
4、若是Entry不存在,不断循环检测,直到遇到为null的地方,这时候要是还没在循环过程中return,那么就在这个null的位置新建一个Entry,并且插入,同时size增加1。
5、最后调用cleanSomeSlots,清理key为null的Entry,最后返回是否清理了Entry,接下来再判断size是否>= threshold达到了rehash的条件,达到的话就会调用rehash函数执行一次全表的扫描清理。
线性探测法解决Hash冲突
该方法依次探测下一个地址,直到有空的地址后插入,若整个空间都找不到空余的地址,则产生溢出。
举个例子,假设当前table长度为16,也就是说如果计算出来key的hash值为14,如果table[14]上已经有值,并且其key与当前key不一致,那么就发生了hash冲突,这个时候将14+1得到15,取table[15]进行判断,这个时候如果还是冲突会回到0,取table[0],以此类推,直到可以插入。
按照上面的描述,可以把Entry table看成一个环形数组。
ThreadLocal 核心源码分析的更多相关文章
- 并发编程之 SynchronousQueue 核心源码分析
前言 SynchronousQueue 是一个普通用户不怎么常用的队列,通常在创建无界线程池(Executors.newCachedThreadPool())的时候使用,也就是那个非常危险的线程池 ^ ...
- iOS 开源库系列 Aspects核心源码分析---面向切面编程之疯狂的 Aspects
Aspects的源码学习,我学到的有几下几点 Objective-C Runtime 理解OC的消息分发机制 KVO中的指针交换技术 Block 在内存中的数据结构 const 的修饰区别 block ...
- HashMap的结构以及核心源码分析
摘要 对于Java开发人员来说,能够熟练地掌握java的集合类是必须的,本节想要跟大家共同学习一下JDK1.8中HashMap的底层实现与源码分析.HashMap是开发中使用频率最高的用于映射(键值对 ...
- Spark GraphX图计算核心源码分析【图构建器、顶点、边】
一.图构建器 GraphX提供了几种从RDD或磁盘上的顶点和边的集合构建图形的方法.默认情况下,没有图构建器会重新划分图的边:相反,边保留在默认分区中.Graph.groupEdges要求对图进行重新 ...
- jquery事件核心源码分析
我们从绑定事件开始,一步步往下看: 以jquery.1.8.3为例,平时通过jquery绑定事件最常用的是on方法,大概分为下面3种类型: $(target).on('click',function( ...
- 迷你版jQuery——zepto核心源码分析
前言 zepto号称迷你版jQuery,并且成为移动端dom操作库的首选 事实上zepto很多时候只是借用了jQuery的名气,保持了与其基本一致的API,其内部实现早已面目全非! 艾伦分析了jQue ...
- SynchronousQueue核心源码分析
一.SynchronousQueue的介绍 SynchronousQueue是一个不存储元素的阻塞队列.每一个put操作必须等待一个take操作,否则不能继续添加元素.SynchronousQueue ...
- FutureTask核心源码分析
本文主要介绍FutureTask中的核心方法,如果有错误,欢迎大家指出! 首先我们看一下在java中FutureTask的组织关系 我们看一下FutureTask中关键的成员变量以及其构造方法 //表 ...
- Java内存管理-掌握类加载器的核心源码和设计模式(六)
勿在流沙筑高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 上一篇文章介绍了类加载器分类以及类加载器的双亲委派模型,让我们能够从整体上对类加载器有 ...
- HTTP流量神器Goreplay核心源码详解
摘要:Goreplay 前称是 Gor,一个简单的 TCP/HTTP 流量录制及重放的工具,主要用 Go 语言编写. 本文分享自华为云社区<流量回放工具之 goreplay 核心源码分析> ...
随机推荐
- 来电科技:基于 Flink + Hologres 的实时数仓演进之路
简介: 本文将会讲述共享充电宝开创企业来电科技如何基于 Flink + Hologres 构建统一数据服务加速的实时数仓 作者:陈健新,来电科技数据仓库开发工程师,目前专注于负责来电科技大数据平台离线 ...
- Git基础使用指南-命令详解
Software is like sex: it's better when it's free. -- Linus Torvalds 前情须知 -O- 工作流程 首先要明确的是Git的工作流程,你使 ...
- Anaconda环境下GPT2-Chinese的基本使用记录
偶然在看到了这个项目,感觉很厉害,于是就折腾了下,跑了一跑 项目地址:https://github.com/Morizeyao/GPT2-Chinese 如果Github下载太慢的可以用这个代下载:h ...
- SpringBoot实现WebSocket发送接收消息 + Vue实现SocketJs接收发送消息
SpringBoot实现WebSocket发送接收消息 + Vue实现SocketJs接收发送消息 参考: 1.https://www.mchweb.net/index.php/dev/887.htm ...
- Asp-Net-Core开发笔记:进一步实现非侵入性审计日志功能
前言 上次说了利用 AOP 思想实现了审计日志功能,不过有同学反馈还是无法实现完全无侵入,于是我又重构了一版新的. 回顾一下:Asp-Net-Core开发笔记:实现动态审计日志功能 现在已经可以实现对 ...
- python3解析FreeSWITCH会议室列表信息
操作系统 :CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 Python版本:3.9.12 进行FreeSWITCH会议室相关功能开发过程中,会遇到需要解析会议室列表信息并进行 ...
- 【爬虫案例】用Python爬大麦网任意城市的近期演出活动!
目录 一.爬取目标 二.展示爬取结果 三.讲解代码 四.同步视频 五.附完整源码 一.爬取目标 大家好,我是@马哥python说 ,一枚10年程序猿. 今天分享一期python爬虫案例,爬取目标是大麦 ...
- protobuf 文档
文档地址: https://golang-tech-stack.com/tutorial/pb 学习视频: https://www.bilibili.com/video/BV1Y3411j7EM?p= ...
- Unity新的MeshData API学习
在新版本的Unity中提供了MeshDataArray和MeshData等多个API,使Mesh数据操作支持多线程:以更好的支持DOTS. API文档:https://docs.unity3d.com ...
- 解决linux家目录模板文件被删之后显示不正常的问题
想必经常使用linux的小伙伴都遇到过下面这种情况: 下面讲解遇到这种问题之后如何解决: [root@node5 ~]# rm -rf /home/elk/.bash* [root@node5 ~]# ...