在线问诊 Python、FastAPI、Neo4j — 生成 Cypher 语句
这边只是为了测试,演示效果和思路,实际应用中,可以通过NLP构建CQL
接上一篇的问题分类
question = "请问最近看东西有时候清楚有时候不清楚是怎么回事"
# 最终输出
data = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
question = "干眼常用药有哪些"
# 最终输出
data = {'args': {'干眼': ['disease']}, 'question_types': ['disease_drug']}
question = "干眼哪些不能吃"
data = {'args': {'干眼': ['disease']}, 'question_types': ['disease_not_food']}
构建节点字典
目的,为了拼CQL,查出符合条件的节点详情
def build_nodedict(self, args):
"""
构建节点字典
:param args: {'看东西有时候清楚有时候不清楚': ['symptom']}
:return: 组装成 => {'symptom': '看东西有时候清楚有时候不清楚'}
"""
node_dict = {}
for arg, types in args.items():
for type in types:
if type not in node_dict:
node_dict[type] = [arg]
else:
node_dict[type].append(arg)
return node_dict
# 输入:
{'看东西有时候清楚有时候不清楚': ['symptom']}
# 输出:
{'symptom': ['看东西有时候清楚有时候不清楚']}
构建Cypher CQL语句
# 查询症状会导致哪些疾病
if question_type == 'symptom_disease':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询症状会导致哪些疾病
if question_type == 'symptom_disease':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病常用药品-药品别名记得扩充
if question_type == 'disease_drug':
sql = ["MATCH (m:Disease)-[r:used_drugs]->(n:Drug) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病的忌口
if question_type == 'disease_not_food':
sql = ["MATCH (m:Disease)-[r:noteat_foods]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
node_dict.get('symptom')
Test
if __name__ == '__main__':
handler = QuestionPaser()
question_class = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
cql = handler.parser_main(question_class)
print(cql)
输出:
# 输入
question_class = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
# 输出
[{'question_type': 'symptom_disease', 'sql': ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '看东西有时候清楚有时候不清楚' return m.name, r.name, n.name"]}]
# 输入:
question_class = {'args': {'干眼': ['disease']}, 'question_types': ['disease_drug']}
# 输出:
[{'question_type': 'disease_drug', 'sql': ["MATCH (m:Disease)-[r:used_drugs]->(n:Drug) where m.name = '干眼' return m.name, r.name, n.name"]}]
# 输入:
question_class = {'args': {'干眼': ['disease']}, 'question_types': ['disease_not_food']}
# 输出:
[{'question_type': 'disease_not_food', 'sql': ["MATCH (m:Disease)-[r:noteat_foods]->(n:Foods) where m.name = '干眼' return m.name, r.name, n.name"]}]
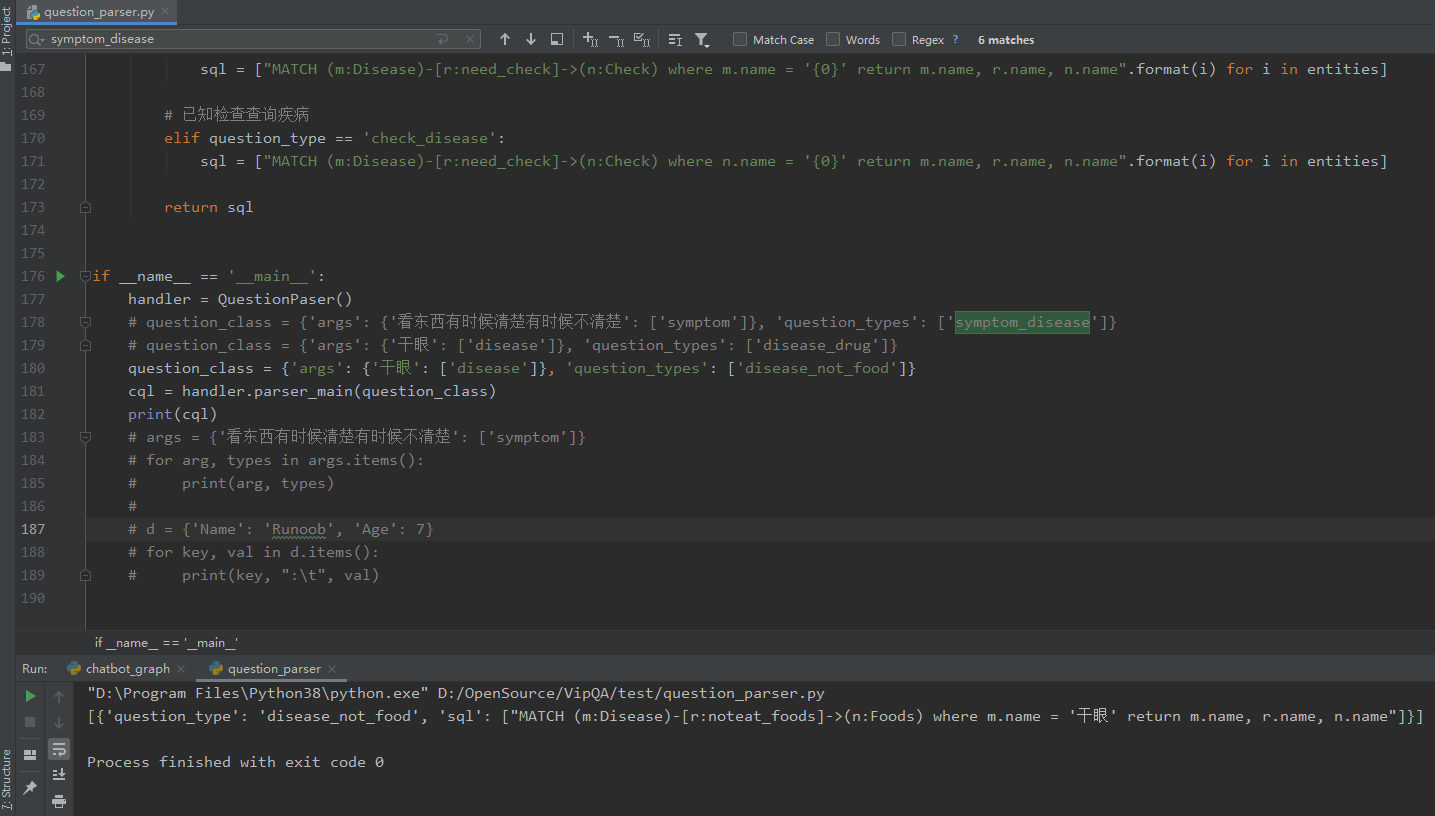
后面根据 生成的 CQL语句,查询出知识图谱中对应的数据,
源代码地址:https://gitee.com/VipSoft/VipQA
在线问诊 Python、FastAPI、Neo4j — 生成 Cypher 语句的更多相关文章
- neo4j中cypher语句多个模糊查询
总结一下经验: neo4j中,cypher语句的模糊查询,好像是个正则表达式结构. 对于一个属性的多个模糊查询,可以使用如下写法: 比如,查询N类型中,属性attr包含'a1'或者'a2'的所有节点. ...
- neo4j常用cypher语句
阅读更多 1.删除带有关系的节点 a.先删除关系 match (n:Node)-[r:关系名称]-() where (n...条件) delete r b.删除节点 match (n:Node ...
- neo4j 基本概念和Cypher语句总结
下面是一个介绍基本概念的例子,参考链接Graph database concepts: (1) Nodes(节点) 图谱的基本单位主要是节点和关系,他们都可以包含属性,一个节点就是一行数据,一个关系也 ...
- CYPHER 语句(Neo4j)
CYPHER 语句(Neo4j) 创建电影关系图 新增 查找 修改 删除 导入 格式转换 创建电影关系图 CREATE (TheMatrix:Movie {title:'The Matrix', re ...
- python批量生成SQL语句
1,首先写一条能运行成功插入SQL的语句 INSERT INTO sign_guest(realname,phone,email,sign,event_id)VALUES("jack&quo ...
- Day2 Python的运算符及三大语句控制结构
Python的运算符 Python语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 Python的三大语句控制结构: ...
- python脚本批量生成数据
在平时的工作中,经常会遇到造数据,特别是性能测试的时候更是需要大量的数据.如果一条条的插入数据库或者一条条的创建数据,效率未免有点低.如何快速的造大量的测试数据呢?在不熟悉存储过程的情况下,今天给大家 ...
- Neo4j之Cypher学习总结
Cypher 语句 Cypher是图形数据库Neo4j的声明式查询语言. Cypher语句规则和具备的能力: Cypher通过模式匹配图数据库中的节点和关系,来提取信息或者修改数据. Cypher语句 ...
- Python - 条件控制、循环语句 - 第十二天
Python 条件控制.循环语句 end 关键字 关键字end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符,实例如下: Python 条件语句是通过一条或多条语句的执行结果(True 或 ...
- Cypher 语句实战
Cypher 语句实战 下载和安装 Neo4j windows 桌面版- 环境设置 https://www.w3cschool.cn/neo4j/neo4j_exe_environment_setup ...
随机推荐
- c++中vector容器的用法
C语言中const关键字是constant的缩写,通常翻译为常量.常数等,它可以修饰变量.数组.指针.函数参数. vector 是向量类型,它可以容纳许多类型的数据,如若干个整数,所以称其为容器.ve ...
- Kotlin协程-那些理不清乱不明的关系
Kotlin的协程自推出以来,受到了越来越多Android开发者的追捧.另一方面由于它庞大的API,也将相当一部分开发者拒之门外.本篇试图从协程的几个重要概念入手,在复杂API中还原出它本来的面目,以 ...
- 让AI支持游戏更自然、更直观:基于情感分析的AI游戏体验和交互设计
目录 引言 随着游戏市场的不断发展,人工智能技术的应用也越来越广泛.其中,情感分析技术在游戏中的应用,可以让游戏更加自然.直观,同时提高游戏的用户体验.本文将介绍如何让 AI 支持游戏更自然.更直观: ...
- php处理emoji表情 存数据库
PHP 处理emoji表情 存数据库 直接过滤掉 1 function filter_emoji($str) { 2 $regex = '/(\\\u[ed][0-9a-f]{3})/i'; 3 $s ...
- Composer 镜像原理 (3) —— 完结篇
相关文章 Composer 镜像原理 (1) -- 初识 Composer Composer 镜像原理 (2) -- composer.json Composer 镜像原理 (3) -- 完结篇 上一 ...
- iframe与主窗口通信
1. 引言 <iframe> 元素是 HTML 中的一个标签,用于在当前页面中嵌入另一个页面 使用 <iframe> 可以实现以下功能: 嵌入其他网页:可以将其他网页嵌入到当前 ...
- IIS 应用程序池 PowerShell 脚本更改高级属性的方法
## IIS WebAdmin Module Import-Module WebAdministration $AppPool = "mqttService(8011)" $Sit ...
- chrome pre 自动换行
问题引出 当我想要使用chrome的打印功能生成一份关于md的pdf版本的时候发现有的代码块没有自动换行,生成的PDF没有自动换行,导致部分信息无法阅读 处理方式 把有自动换行的部分处理一下,在md文 ...
- Xshell远程连接虚拟机及连接故障排查
用Xshell 远程连接虚拟机 如果按前面博客装好虚拟机,会发现刚装好的虚拟机直接连Xshell连不上,宿主机也ping不通虚拟机,这就需要修改VMware的默认网络配置 修改步骤: 1.在VMwar ...
- [USACO22DEC] Cow College B 题解
洛谷 P8897 AcWing 4821 题目描述 有\(n\)头奶牛,每头奶牛愿意交的最大学费为\(c_i\),问如何设置学费,可以使赚到的钱最多. \(1\le n\le 10^5,1\le c_ ...