elasticsearch使用painless的一些简单例子
- 1、背景
- 2、准备数据
- 3、例子
- 3.1 (update)更新文档 id=1 的文档,将 age 加 2岁
- 3.2 (update_by_query)如果 province 是北京的话,就将 age 减少1岁
- 3.3 (ctx.op)如果张三的年龄小于20岁就不处理,否则就删除这个文档
- 3.4 (stored script)如果是湖南省则增加地市字段,值为长沙
- 3.5 (pipeline)通过pipeline如果插入的文档的age<10则放入到index_person_small索引中
- 3.6 function_score中使用script_score算分
- 3.7 script_fields 增加字段
- 3.8 runtime field 增加字段
- 3.9 _reindex 中使用
- 3.10 script query 查询age<25
- 3.11 script 聚合
- 4、painless脚本调试
- 5、脚本中的doc[..]和params._source[..]
- 6、painless脚本中的上下文
1、背景
此篇文档仅仅是简单的记录一下painless的一些简单的例子,防止以后忘记,不过多涉及painless的语法。
2、准备数据
2.1 mapping
PUT /index_person
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"province": {
"type": "keyword"
}
}
}
}
2.2 插入数据
PUT /index_person/_bulk
{"index":{"_id":1}}
{"name":"张三","age":20,"province":"湖北"}
{"index":{"_id":2}}
{"name":"李四","age":25,"province":"北京"}
{"index":{"_id":3}}
{"name":"王五","age":30,"province":"湖南"}
3、例子
3.1 (update)更新文档 id=1 的文档,将 age 加 2岁
POST index_person/_update/1
{
"script": {
"lang": "painless",
"source": """
ctx['_source']['age'] += params['incrAge']
""",
"params": {
"incrAge": 2
}
}
}
3.2 (update_by_query)如果 province 是北京的话,就将 age 减少1岁
POST index_person/_update_by_query
{
"query": {
"term": {
"province": {
"value": "北京"
}
}
},
"script": {
"lang": "painless",
"source": """
ctx['_source']['age'] -= params['decrAge']
""",
"params": {
"decrAge": 1
}
}
}
3.3 (ctx.op)如果张三的年龄小于20岁就不处理,否则就删除这个文档
POST index_person/_update/1
{
"script": {
"lang": "painless",
"source": """
// 这是默认值,表示的是更新值,重新索引记录
ctx.op = 'index';
if(ctx._source.age < 20){
// 表示不处理
ctx.op = 'none';
}else{
// 表示删除这个文档
ctx.op = 'delete';
}
"""
}
}
3.4 (stored script)如果是湖南省则增加地市字段,值为长沙
3.4.1 创建存储脚本
PUT _scripts/add_city
{
"script":{
"lang": "painless",
"source": "ctx._source.city = params.city"
}
}
add_city为脚本的id
3.4.2 使用存储脚本
POST index_person/_update_by_query
{
"query": {
"term": {
"province": {
"value": "湖南"
}
}
},
"script": {
"id": "add_city",
"params": {
"city": "长沙"
}
}
}
3.5 (pipeline)通过pipeline如果插入的文档的age<10则放入到index_person_small索引中
3.5.1 创建pipeline
PUT _ingest/pipeline/pipeline_index_person_small
{
"description": "如果插入的文档的age<10则放入到index_person_small索引中",
"processors": [
{
"script": {
"source": """
if(ctx.age < 10){
ctx._index = 'index_person_small';
}
"""
}
}
]
}
3.5.2 使用pipeline
PUT index_person/_doc/4?pipeline=pipeline_index_person_small
{
"name":"赵六",
"age": 8,
"province":"四川"
}
3.5.3 运行结果

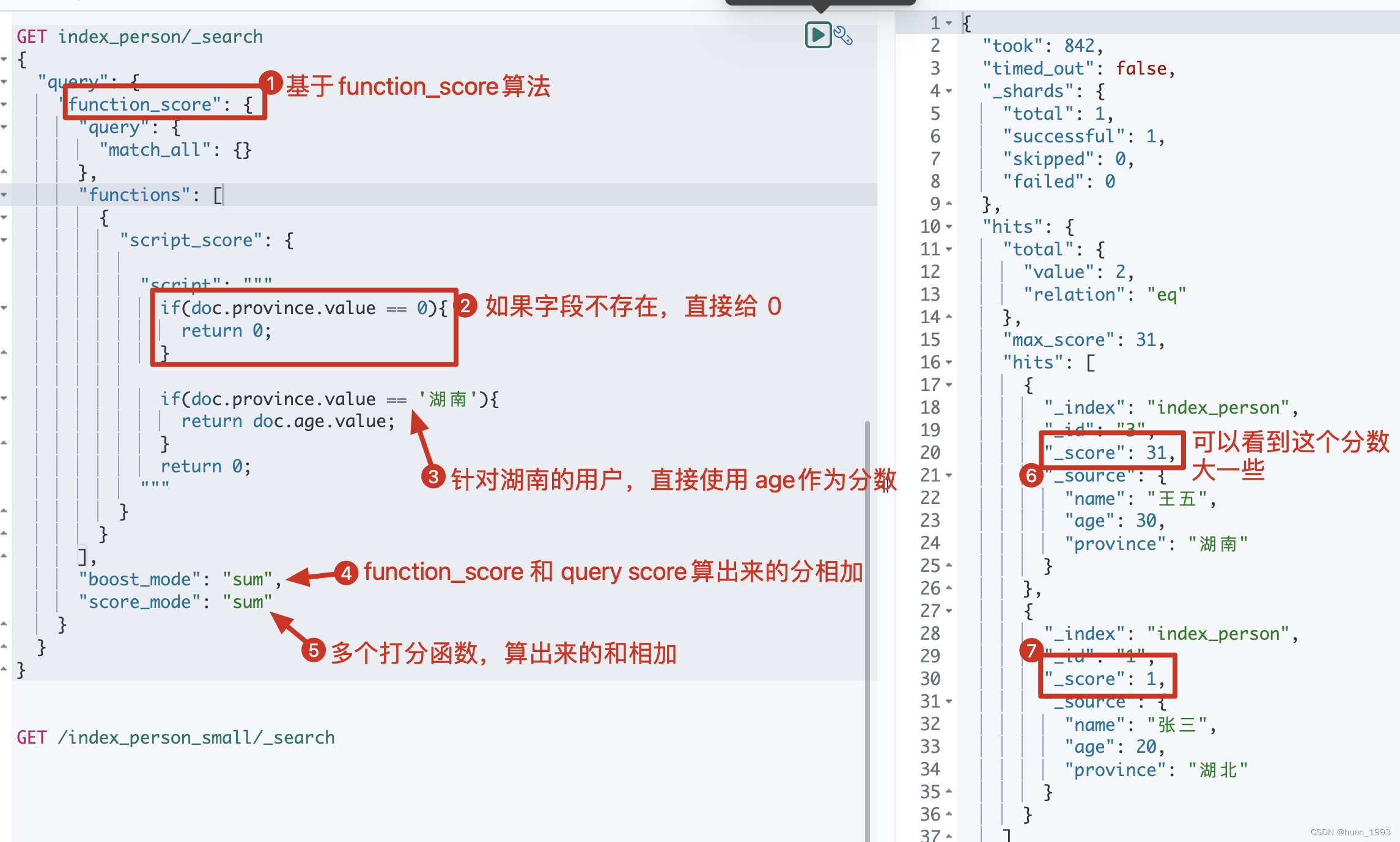
3.6 function_score中使用script_score算分
3.6.1 需求
如果这个用户是湖南的,则使用 age作为分数
3.6.2 dsl
GET index_person/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"functions": [
{
"script_score": {
"script": """
if(doc.province.value == 0){
return 0;
}
if(doc.province.value == '湖南'){
return doc.age.value;
}
return 0;
"""
}
}
],
"boost_mode": "sum",
"score_mode": "sum"
}
}
}
3.6.3 运行结果
3.7 script_fields 增加字段
GET index_person/_search
{
"query": {"match_all": {}},
"fields": [
"double_age"
],
"script_fields": {
"double_age": {
"script": {
"lang": "painless",
"source": "doc.age.value * 2"
}
}
}
}
3.8 runtime field 增加字段
3.8.1 需求
针对age<25的文档,返回double_age字段,否则不处理。
3.8.2 dsl
GET index_person/_search
{
"query": {
"match_all": {}
},
"fields": [
"double_age"
],
"runtime_mappings": {
"double_age":{
"type": "keyword",
"script": """
if(doc.age.size() == 0){
return;
}
if(doc.age.value < 25){
emit(doc.age.value * 2 + '');
}
"""
}
}
}
在runtime field 中,需要使用emit来返回数据,但是不是emit(null)
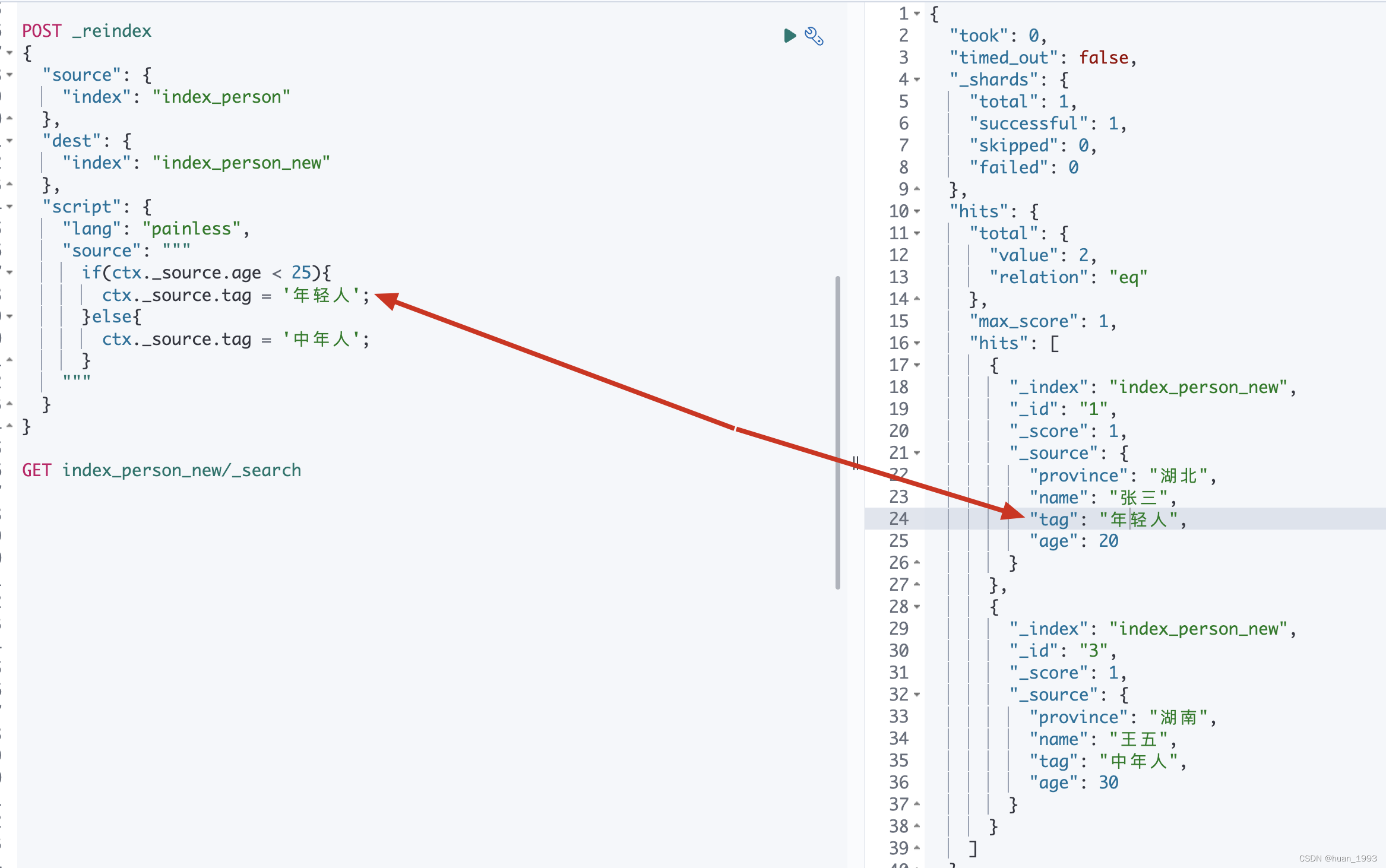
3.9 _reindex 中使用
3.9.1 dsl
POST _reindex
{
"source": {
"index": "index_person"
},
"dest": {
"index": "index_person_new"
},
"script": {
"lang": "painless",
"source": """
if(ctx._source.age < 25){
ctx._source.tag = '年轻人';
}else{
ctx._source.tag = '中年人';
}
"""
}
}
3.9.2 运行结果
3.10 script query 查询age<25
GET index_person/_search
{
"query": {
"script": {
"script": {
"lang": "painless",
"source": """
if(doc.age.size() == 0){
return false;
}
return doc.age.value < 25;
"""
}
}
}
}
3.11 script 聚合
GET index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"script": {
"lang": "painless",
"source": """
return doc.province
"""
},
"size": 10
}
},
"agg_age":{
"avg": {
"script": "params._source.age"
}
}
}
}
4、painless脚本调试

可以通过Debug.explain来进行一些简单的调试。
5、脚本中的doc[..]和params._source[..]
doc[..]:使用doc关键字,将导致该字段的术语被加载到内存(缓存),这将导致更快的执行,但更多的内存消耗。此外,doc[…]表示法只允许简单的值字段(您不能从中返回json对象),并且仅对非分析或基于单个术语的字段有意义。然而,如果可能的话,使用doc仍然是访问文档值的推荐方法。
params[_source][..]: 每次使用_source都必须加载和解析, 因此使用_source会相对而言要慢点。

6、painless脚本中的上下文
详细了解,请参考这个文档https://www.elastic.co/guide/en/elasticsearch/painless/current/painless-contexts.html
elasticsearch使用painless的一些简单例子的更多相关文章
- Hibernate4.2.4入门(一)——环境搭建和简单例子
一.前言 发下牢骚,这段时间要做项目,又要学框架,搞得都没时间写笔记,但是觉得这知识学过还是要记录下.进入主题了 1.1.Hibernate简介 什么是Hibernate?Hibernate有什么用? ...
- AgileEAS.NET SOA 中间件平台.Net Socket通信框架-简单例子-实现简单的服务端客户端消息应答
一.AgileEAS.NET SOA中间件Socket/Tcp框架介绍 在文章AgileEAS.NET SOA 中间件平台Socket/Tcp通信框架介绍一文之中我们对AgileEAS.NET SOA ...
- spring mvc(注解)上传文件的简单例子
spring mvc(注解)上传文件的简单例子,这有几个需要注意的地方1.form的enctype=”multipart/form-data” 这个是上传文件必须的2.applicationConte ...
- ko 简单例子
Knockout是在下面三个核心功能是建立起来的: 监控属性(Observables)和依赖跟踪(Dependency tracking) 声明式绑定(Declarative bindings) 模板 ...
- mysql定时任务简单例子
mysql定时任务简单例子 ? 1 2 3 4 5 6 7 8 9 如果要每30秒执行以下语句: [sql] update userinfo set endtime = now() WHE ...
- java socket编程开发简单例子 与 nio非阻塞通道
基本socket编程 1.以下只是简单例子,没有用多线程处理,只能一发一收(由于scan.nextLine()线程会进入等待状态),使用时可以根据具体项目功能进行优化处理 2.以下代码使用了1.8新特 ...
- 一个简单例子:贫血模型or领域模型
转:一个简单例子:贫血模型or领域模型 贫血模型 我们首先用贫血模型来实现.所谓贫血模型就是模型对象之间存在完整的关联(可能存在多余的关联),但是对象除了get和set方外外几乎就没有其它的方法,整个 ...
- [转] 3个学习Socket编程的简单例子:TCP Server/Client, Select
以前都是采用ACE的编写网络应用,最近由于工作需要,需要直接只用socket接口编写CS的代码,重新学习这方面的知识,给出自己所用到的3个简单例子,都是拷贝别人的程序.如果你能完全理解这3个例子,估计 ...
- jsonp的简单例子
jsonp的简单例子 index.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8&q ...
- Java-马士兵设计模式学习笔记-观察者模式-AWT简单例子
1.AWT简单例子 TestFrame.java import java.awt.Button; import java.awt.Frame; import java.awt.event.Action ...
随机推荐
- 【Unity3D】Unity3D技术栈
1 前言 本文梳理了笔者在学习 Unity3D 的过程中,对 Unity3D 的理解和学习路线,以帮助读者循序渐进地学习 Unity3D,后续笔者仍会持续更新 Unity3D 相关技术栈,并同步到 ...
- 正则表达式(Regular Expression)详解
1 前言 正则表达式主要用于复杂文本处理,如模式匹配.格式检验.文本替换等.常用的通配符有: ^, $, *, ., , -, +, ?, &, |, (), [], {} 2 String中 ...
- Centos7虚拟机安装后的环境配置工作
虚拟机安装配置 选择[基础设施服务器],勾选:开发工具和调试工具 关闭防火墙 systemctl stop firewalld.service systemctl disable firewalld. ...
- 如何用Apipost校验响应结果
数据校验的意义 我们可以通过 json-schema 预先定义接口的数据返回格式,当接口完成后,我们可以通过匹配 实际响应结果 和 预先定义的接口格式 ,来发现接口问题.如下图: 数据校验的设置 我们 ...
- C++检测句柄的权限
主要是依靠NtQueryObject函数,其中需要传入ObjectBasicInformation参数 PUBLIC_OBJECT_BASIC_INFORMATION结构包含可用于对象的全部信息的子集 ...
- 海康摄像头开发笔记(一):连接防爆摄像头、配置摄像头网段、设置rtsp码流、播放rtsp流、获取rtsp流、调优rtsp流播放延迟以及录像存储
前言 Hik防爆摄像头录像,因为防爆摄像头会有对应的APP软件,与普通的网络摄像头和球机不一样,默认认为它不可以通过web网页配置,所以弄了个来实测确认. 经测试实际上也是可以通过web网页配置 ...
- 在写dockerfile时替换国内源
众所周知,Debian是linux发行版中官方源最难用的一个,这个傻逼源让我再构建docker镜像时卡了很久. 那么能不能替换构建dockerfile时使用的源呢?显然是可以的 在与Docke ...
- 【LeetCode链表#10】删除链表中倒数第n个节点(双指针)
删除链表倒数第N个节点 力扣题目链接(opens new window) 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点. 进阶:你能尝试使用一趟扫描实现吗? 示例 1: 输入:he ...
- Vue3学习(二十)- 富文本插件wangeditor的使用
写在前面 学习.写作.工作.生活,都跟心情有很大关系,甚至有时候我更喜欢一个人独处,戴上耳机coding的感觉. 明显现在的心情,比中午和上午好多了,心情超棒的,靠自己解决了两个问题: 新增的时候点击 ...
- python部署项目为什么要用Nginx和uWSGI
一.测试运行python项目 1.1 Flask项目 说明1:当我们直接用编译器运行Flask项目的时候,会有一个提示:意思就是:这是开发环境的服务器,不能用于生产环境的部署,请使用WSGI的服务器替 ...