八、Doris外部表及数据导入
DorisDB提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择最适合自己业务需求的导入方式。
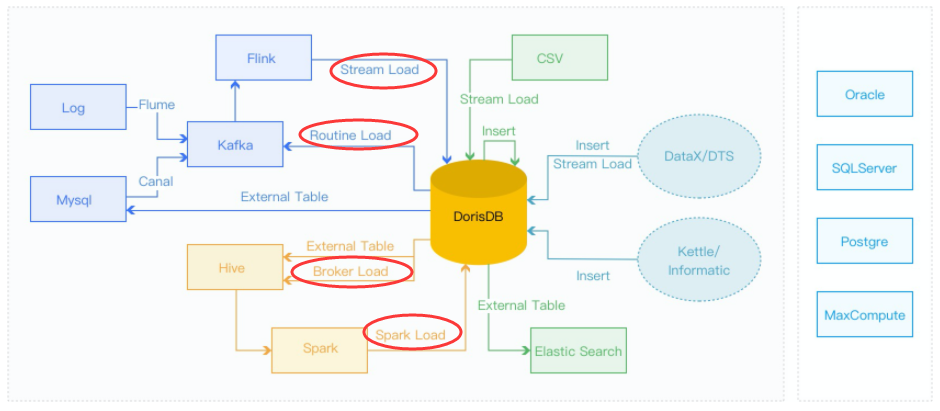
数据导入:
- 1、离线数据导入:如果数据源是Hive/HDFS,推荐采用 Broker Load 导入, 如果数据表很多导入比较麻烦可以考虑使用Hive外表直连查询,性能会比Broker load导入效果差,但是可以避免数据搬迁,如果单表的数据量特别大,或者需要做全局数据字典来精确去重可以考虑 Spark Load 导入。
- 2、实时数据导入:日志数据和业务数据库的binlog同步到Kafka以后,优先推荐通过 Routine load 导入DorisDB,如果导入过程中有复杂的多表关联和ETL预处理可以使用Flink处理以后用 stream load 写入DorisDB
- 3、程序写入DorisDB:推荐使用Stream Load
- 4、Mysql数据导入:推荐使用Mysql外表,insert into new_table select * from external_table 的方式导入
- 5、DorisDB内部导入:可以在DorisDB内部使用 insert into tablename select 的方式导入,可以跟外部调度器配合实现简单的ETL处理
- 6、其他数据源导入:推荐使用 DataX 导入
外部表:
- DorisDB支持以外部表的形式,接入其他数据源。
- 外部表指的是保存在其他数据源中的数据表。
- 目前DorisDB已支持的第三方数据源包括 MySQL、HDFS、ElasticSearch,Hive。
重点目录:
- 1.1 Broker Load
- 1.2 Spark Load
- 1.3 Stream Load
- 1.4 Routine Load
- 2.1 MySQL外部表
- 2.2 ElasticSearch外部表
1.1 Broker Load
在Broker Load模式下,通过部署的 Broker 程序,DorisDB可读取对应数据源(如HDFS, S3、阿里云 OSS、腾讯 COS)上的数据,利用自身的计算资源对数据进行预处理和导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。
1、名词解释
- Broker:Broker 为一个独立的无状态进程,封装了文件系统接口,为 DorisDB 提供读取远端存储系统中文件的能力。
- Plan:导入执行计划,BE会执行导入执行计划将数据导入到DorisDB系统中。
2、语法:
LOAD LABEL db_name.label_name
(data_desc, ...)
WITH BROKER broker_name broker_properties
[PROPERTIES (key1=value1, ... )] data_desc:
DATA INFILE ('file_path', ...)
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY column_separator ]
[FORMAT AS file_type]
[(col1, ...)]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate] broker_properties:
(key2=value2, ...)
说明:
1)、Label:导入任务的标识。每个导入任务,都有一个数据库内部唯一的Label。Label是用户在导入命令中自定义的名称。
- 通过这个Label,用户可以查看对应导入任务的执行情况,并且Label可以用来防止用户导入相同的数据。
- 当导入任务状态为FINISHED时,对应的Label就不能再次使用了。
- 当 Label 对应的导入任务状态为CANCELLED时,可以再次使用该Label提交导入作业。
2)、data_desc:每组 data_desc表述了本次导入涉及到的数据源地址,ETL 函数,目标表及分区等信息。
示例 :参见:https://www.kancloud.cn/dorisdb/dorisdb/2146000
1.2 Spark Load
Spark Load 通过外部的 Spark 资源实现对导入数据的预处理,提高 DorisDB 大数据量的导入性能并且节省 Doris 集群的计算资源。主要用于初次迁移、大数据量导入 DorisDB 的场景(数据量可到TB级别)
1、基本原理

Spark Load 任务的执行主要分为以下几个阶段:
- 1、用户向 FE 提交 Spark Load 任务;
- 2、FE 调度提交 ETL 任务到 Spark 集群执行。
- 3、Spark 集群执行 ETL 完成对导入数据的预处理。包括全局字典构建(BITMAP类型)、分区、排序、聚合等。
- 4、ETL 任务完成后,FE 获取预处理过的每个分片的数据路径,并调度相关的 BE 执行 Push 任务。
- 5、BE 通过 Broker 读取数据,转化为 DorisDB 存储格式。
- 6、FE 调度生效版本,完成导入任务。
2、预处理流程:
- 1、从数据源读取数据,上游数据源可以是HDFS文件,也可以是Hive表。
- 2、对读取到的数据完成字段映射、表达式计算,并根据分区信息生成分桶字段bucket_id。
- 3、根据DorisDB表的Rollup元数据生成RollupTree。
- 4、遍历RollupTree,进行分层的聚合操作,下一个层级的Rollup可以由上一个层的Rollup计算得来。
- 5、每次完成聚合计算后,会对数据根据bucket_id进行分桶然后写入HDFS中。
- 6、后续Broker会拉取HDFS中的文件然后导入DorisDB BE节点中。
3、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146001
1.3 Stream Load
Stream Load 是一种同步的导入方式,用户通过发送 HTTP 请求将本地文件或数据流导入到 DorisDB 中。Stream Load 同步执行导入并返回导入结果。用户可直接通过请求的返回值判断导入是否成功。
1、主要流程:
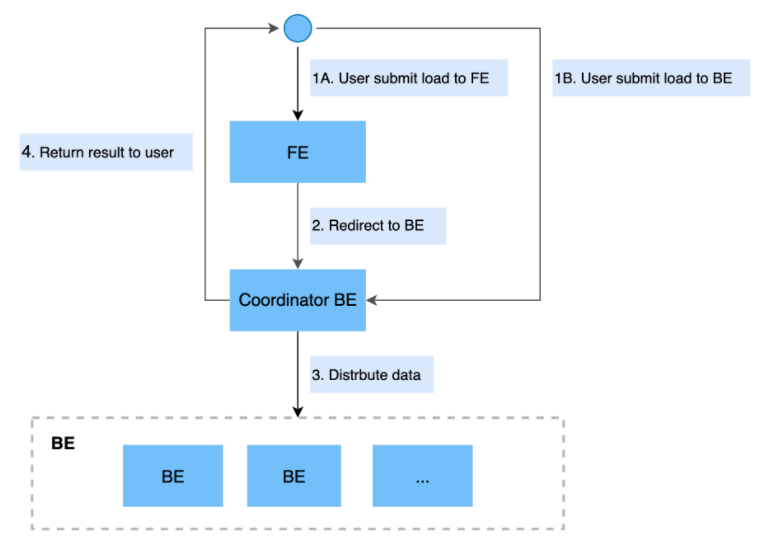
说明:
- Stream Load 中,用户通过HTTP协议提交导入命令。
- 如果提交到FE节点,则FE节点会通过HTTP redirect指令将请求转发给某一个BE节点,用户也可以直接提交导入命令给某一指定BE节点。
- 该BE节点作为Coordinator节点,将数据按表schema划分并分发数据到相关的BE节点。
- 导入的最终结果由 Coordinator节点返回给用户。
2、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146002
1.4 Routine Load
Routine Load 是一种例行导入方式,DorisDB通过这种方式支持从Kafka持续不断的导入数据,并且支持通过SQL控制导入任务的暂停、重启、停止
1、基本原理
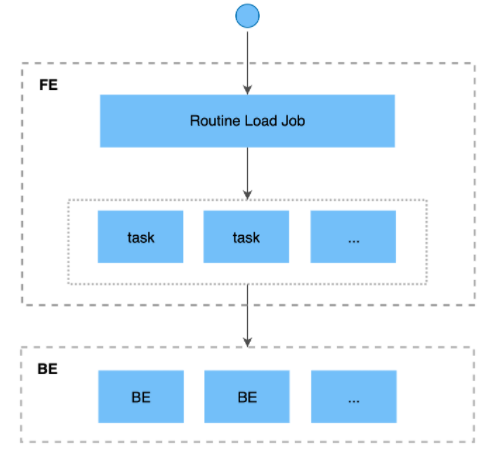
导入流程说明:
- 1、用户通过支持MySQL协议的客户端向 FE 提交一个Kafka导入任务。
- 2、FE将一个导入任务拆分成若干个Task,每个Task负责导入指定的一部分数据。
- 3、每个Task被分配到指定的 BE 上执行。在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。
- 4、BE导入完成后,向 FE 汇报。
- 5、FE 根据汇报结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
- 6、FE 会不断的产生新的 Task,来完成数据不间断的导入。
2、基本操作参见:https://www.kancloud.cn/dorisdb/dorisdb/2146003
2.1 MySQL外部表
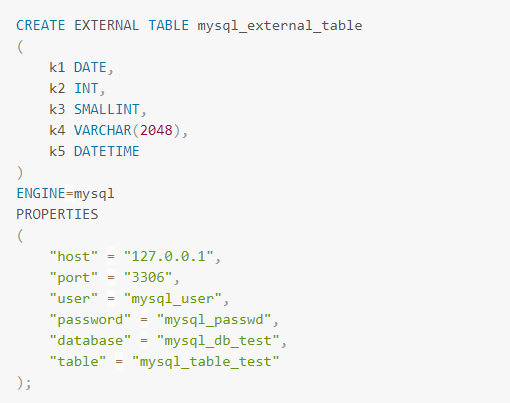
星型模型中,数据一般划分为维度表和事实表。维度表数据量少,但会涉及UPDATE操作。目前DorisDB中还不直接支持UPDATE操作(可以通过Unique数据模型实现),在一些场景下,可以把维度表存储在MySQL中,查询时直接读取维度表。
在使用MySQL的数据之前,需在DorisDB创建外部表,与之相映射。DorisDB中创建MySQL外部表时需要指定MySQL的相关连接信息,如下图。
2.2 ElasticSearch外部表
DorisDB与ElasticSearch都是目前流行的分析系统,DorisDB强于大规模分布式计算,ElasticSearch擅长全文检索。DorisDB支持ElasticSearch访问的目的,就在于将这两种能力结合,提供更完善的一个OLAP解决方案。
1、建表示例
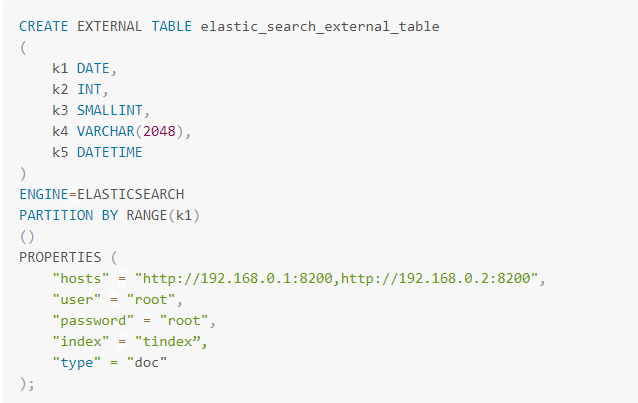
2、谓词下推
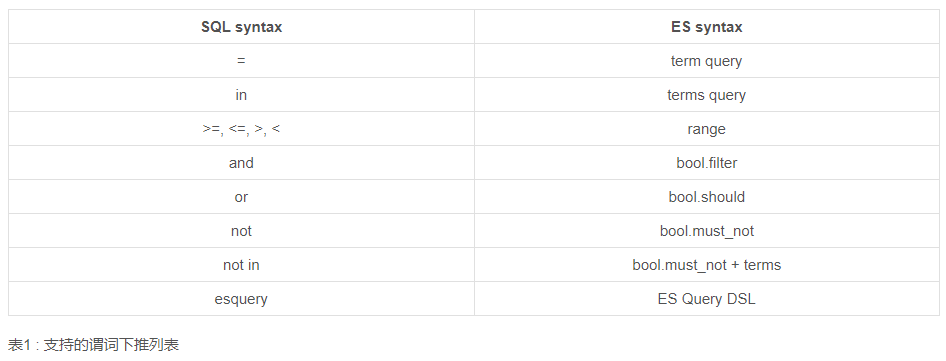
DorisDB支持对ElasticSearch表进行谓词下推,把过滤条件推给ElasticSearch进行执行,让执行尽量靠近存储,提高查询性能。目前支持哪个下推的算子如下表。
3、详细说明参见:https://www.kancloud.cn/dorisdb/dorisdb/2146013
参考资料:
八、Doris外部表及数据导入的更多相关文章
- mysql 开发进阶篇系列 50 表的数据导入(load data infile,mysqlimport )
一.概述 上篇讲到的表的数据导出(select .. into outfile 或者mysqldump),这篇继续讲表的数据导入,导入也同样有二个方法,分别是load data infile... 和 ...
- 两种方法将oracle数据库中的一张表的数据导入到另外一个oracle数据库中
oracle数据库实现一张表的数据导入到另外一个数据库的表中的方法有很多,在这介绍两个. 第一种,把oracle查询的数据导出为sql文件,执行sql文件里的insert语句,如下: 第一步,导出sq ...
- sql 从一个库中取某个表的数据导入到另一个库中相同结构的表中
sql 2008 从一个库中把 某个表中的数据导入到另一个库中的具有相同结构的表中 use 库1 go insert into 库1.dbo.表1 select * from 库2.dbo.表1 ...
- 使用oracle外部表进行数据泵卸载数据
数据泵卸载Oracle9i引入了外部表,作为向数据库中读取数据的一种方法.Oracle 10g则从另一个方向引入了这个特性,可以使用CREATE TABLE语句创建外部数据,从而由数据库卸载数据.从O ...
- sqlserver怎么将excel表的数据导入到数据库中
在数据库初始阶段,我们有些数据在EXCEL中做好之后,需要将EXCEL对应列名(导入后对应数据库表的字段名),对应sheet(改名为导入数据库之后的表名)导入指定数据库, 相当于导入一张表的整个数据. ...
- 22.把hive表中数据导入到mysql中
先通过可视化工具链接mysql,在链接的时候用sqoop 用户登录 在数据库userdb下新建表 保存,输入表名upflow 现在我们需要把hive里面的数据通过sqoop导入到mysql里面 sqo ...
- SqlServer批量Sql一个表的数据导入到另一个数据
一个表的导入: SET IDENTITY_INSERT [master_new].[dbo].[OpinionList] ON INSERT INTO [master_new].[dbo].[Opin ...
- springboot使用EasyExcel,导出数据到Excel表格,并且将Excel表中数据导入
一.导出至Excel 1.导入依赖 导出方法需要使用到fastJson的依赖,这里也直接导入 点击查看代码 <!--阿里的easyexcel--> <dependency> & ...
- SQLServer将一个表的数据导入到另一个表
1.假如A表存在 insert into A(a,b,c) (select a,b,c from B) 2.假如A表不存在 select a,b,c into A from B 3.假如需要跨数据库 ...
- Oracle数据库中将一个数据库中一张表的数据导入到另外一张表
INSERT INTO DBTHNEW.L_MEMBER_ROLE_REL SELECT *FROM DBTH.L_MEMBER_ROLE_REL
随机推荐
- verilog之时钟信号的编写2
verilog之时钟信号的编写2 1.时钟信号的特点 时钟信号除了可以根据时序一个个变化列举出来,还可以利用其循环的变化的特点,使用循环执行语句always来实现.这种方法实现的时钟信号可以一直执行且 ...
- Mybatis使用JDBC实现数据库批量添加
1.spring注入数据源 @Resource(name = "dataSource") private DataSource dataSource; 2.连接数据库批量添加 pu ...
- c语言的printf常用的一些转换说明符及其含义
整数类型: %d: 十进制整数 (decimal: 十进制的) %u: 无符号整数 (unsigned: 无符号的) %i: 十进制整数 (integer: 整数) %o: 八进制数 (octal: ...
- 【转载】Vue路由 hash与history 的区别
[转载]Vue路由 hash与history 的区别 两种路由模式原因 对于 Vue 这类渐进式前端开发框架, 为了构建 SPA(单页面应用), 需要引入前端路由系统, 这也就是 Vue-Router ...
- Supervisor 安装与使用
一.Supervisor 介绍 Supervisor 是一个用 Python 编写的进程管理工具,它可以用于监控和控制类 UNIX 操作系统上的多个进程.它是一个客户端/服务器系统,其中 Superv ...
- 一文总结ACE代码框架
一.前言 ACE_Engine框架是OpenAtom OpenHarmony(简称"OpenHarmony")的UI开发框架,为开发者提供在进行应用UI开发时所必需的各种组件,以及 ...
- 在python中通过面向对象方式,实现烤地瓜案例
例子:烤地瓜,不同时间,反馈不同状态,并给不同状态地瓜加入不同味道 烤地瓜时间 0-3分钟,生的 4-7分钟,半生不熟的 8-12分钟,熟了 12分钟以上,已烤熟,糊了 用户可以按自己的意思添加调料 ...
- 掌握 xUnit 单元测试中的 Mock 与 Stub 实战
引言 上一章节介绍了 TDD 的三大法则,今天我们讲一下在单元测试中模拟对象的使用. Fake Fake - Fake 是一个通用术语,可用于描述 stub或 mock 对象. 它是 stub 还是 ...
- SQL 转置计算
转置即旋转数据表的横纵方向,常用来改变数据布局,以便用新的角度观察.有些转置算法比较简单,比如行转列.列转行.双向转置:有些算法变化较多,比如动态转置.转置时跨行计算.关联转置等.这些转置算法对日常工 ...
- 论文研究区域图的制作方法:ArcGIS
本文介绍基于ArcMap软件,绘制论文中研究区域示意图.概况图等的方法. 最近需要绘制与地学有关论文.文献中的研究区域概况图.对于这一类图片,我个人比较喜欢基于ArcMap与PPT结合的方式来 ...