Akima算法
测量数据的内插已有各种方法,如线性内插、多项式内插、样条函数插值等,但这里的Akima插值法具有独特的优点。
线性内插只顾及其附近两点的影响。
多项式内插时,低阶多项式由于参数较少,内插精度很低,而使用高阶多项式又会使解不稳定,出现“龙格”现象,即内插函数在插值点与实际数据符合得很好,而在插值点外出现较大的偏差。因此人们又在多项式的基础上发展了分片多项式,即样条函数。
样条函数既保持了多项式运算简单的特点,又避免了多项式阶数较高时数值不稳定的缺点,因而得到了广泛的应用。但在样条函数插值中,确定任何一个小区间上的多项式,都要考虑所有数据点对它的影响。这不仅扩大了误差传播的范围,还增加了不少工作量。有时只用内插点附近的几个数据点作为控制点来内插。
Aikma插值法和三次样条函数一样考虑了要素导数值的效应,因而得到的整个插值曲线是光滑的。三次样条函数插值法具有最小模、最佳最优逼近和收敛的特性,而Aikma插值法所得曲线比样条函数插值曲线更光顺,更自然。
https://blog.csdn.net/bluels01/article/details/43561131
Akima算法是一个插值算法,即对于一个已知(Xi,yi)的数据集,为了让曲线看起来平滑、自然,依据现有的数据点,通过插值,多出一些数据点的过程。
C++中的Akima算法
#include <iostream>
#include <vector>
#include <cmath>
// Akima插值函数
double akimaInterpolation(double x, const std::vector<double>& xData, const std::vector<double>& yData) {
int n = xData.size();
int index = 0;
// Find the interval index
for (int i = 0; i < n - 1; ++i) {
if (x >= xData[i] && x <= xData[i + 1]) {
index = i;
break;
}
}
// 计算斜率
std::vector<double> slopes(n - 1); //初始化n-1个默认值为0的元素
for (int i = 0; i < n - 1; ++i) {
double dx = xData[i + 1] - xData[i];
double dy = yData[i + 1] - yData[i];
slopes[i] = dy / dx; //计算每段之间的斜率
}
// 计算权重
std::vector<double> weights(n - 1); //初始化n-1个默认值为0的元素
for (int i = 2; i < n - 2; ++i) {
weights[i] = std::abs(slopes[i + 1] - slopes[i - 1]); //计算这些权重的目的是确定每个间隔附近的斜坡的“强度”。这些权重随后用于插值公式中,以确保插值曲线的平滑性和连续性。
}
// 计算插值
double dx = xData[index + 1] - xData[index];
double t = (x - xData[index]) / dx; //参数 t 表示区间内的归一化位置,取值范围为 0 到 1
//m0、m1、p0和p1是 Akima 插值公式中用于计算插值的系数
double m0 = slopes[index] * dx; //详见代码解析1
double m1 = slopes[index + 1] * dx;
double p0 = (3 * weights[index] - 2 * m0 - m1) / dx; //这里的3,2系数是怎么来的详见代码解析2
double p1 = (3 * weights[index + 1] - m0 - 2 * m1) / dx;
//interpolatedValue 这个公式用于计算最终插值结果,详见代码解析3
double interpolatedValue =
yData[index] * (1 - t) * (1 - t) * (1 + 2 * t) +
yData[index + 1] * t * t * (3 - 2 * t) +
p0 * t * (1 - t) * (1 - t) +
p1 * t * t * (t - 1);
return interpolatedValue;
}
int main() {
std::vector<double> xData = {1, 2, 3, 4, 5};
std::vector<double> yData = {1, 3, 2, 5, 4};
// 假设输入一个x=2.5,y输出多少?
double interpolatedValue = akimaInterpolation(2.5, xData, yData);
std::cout << "Interpolated value at x = 2.5: " << interpolatedValue << std::endl;
return 0;
}
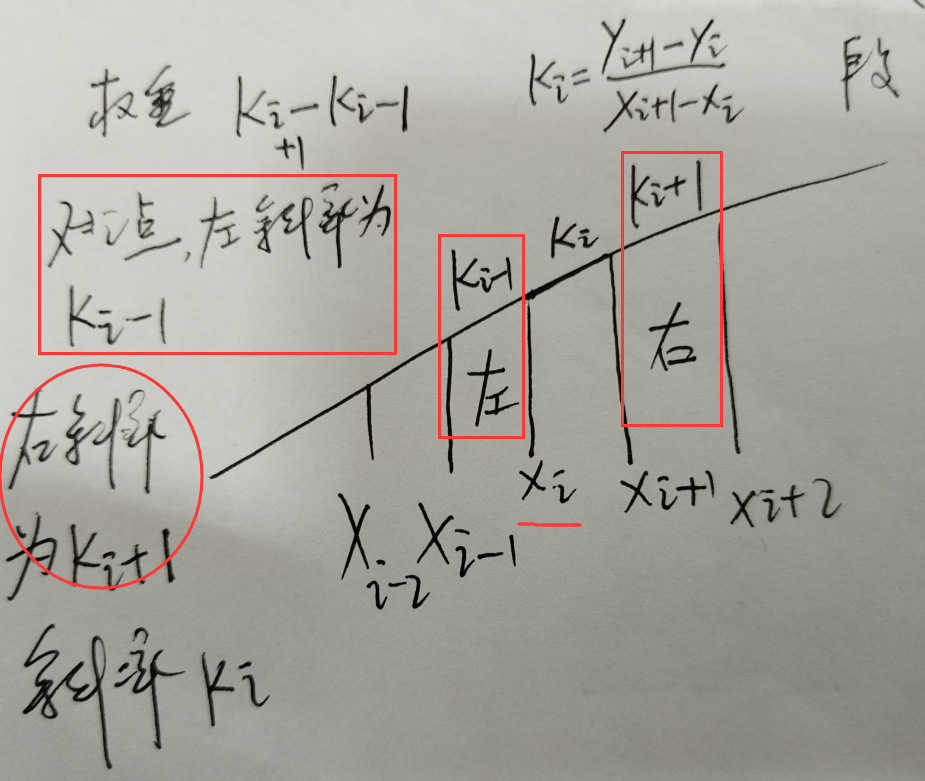
解释一下上面的斜率和权重,斜率是通过相邻点之间 k=dy/dx 来计算。而权重是区间附近斜率对这个区间影响的权重,将点i的左侧斜率slopes[i - 1]和右侧斜率slopes[i + 1]相减得到,存在weights[i]里。权重随后用于插值公式中,以确保插值曲线的平滑性和连续性。
这里展开讲一下:
在 Akima 插值中,插值曲线是通过将分段三次曲线拟合到连续数据点之间的每个区间来构建的。这些三次曲线的斜率在确定插值曲线的形状和行为方面起着至关重要的作用。目标是确保曲线连续并遵循数据的总体趋势,同时避免过度振荡。
通过计算权重算法考虑了相邻区间之间斜率的变化。权重通过捕获数据的局部行为并影响插值过程中每个斜率的“强度”。较大的权重表示区域斜率变化明显,而较小的权重表示区域较平滑。
在执行插值时,将权重合并到插值公式中以调整相邻斜率的贡献。权重充当控制不同区间斜率之间平衡的系数。此调整有助于平滑插值曲线并减少由异常值或噪声数据点引起的突然变化。
代码解析1
m0、m1、p0和p1是 Akima 插值公式中用于计算插值的系数:
m0:此变量表示左相邻区间的调整斜率。将当前区间 (slopes[index]) 的斜率乘以区间宽度 ( dx)得到。
m1:此变量表示右相邻区间的调整斜率。将下一个区间 (slopes[index + 1]) 的斜率乘以区间的宽度 (dx)得到。
p0:此变量表示左相邻区间的调整权重。它是使用当前区间 ( weights[index]) 的权重、左侧区间的调整斜率 ( m0) 和右侧区间的调整斜率 (m1) 计算得到。由公式(3 * weights[index] - 2 * m0 - m1) / dx确定左相邻区间对插值的贡献。
p1:此变量表示右相邻区间的调整权重。它是使用下一个区间的权重 ( weights[index + 1])、左侧区间的调整斜率 (m0) 和右侧区间的调整斜率 (m1) 计算得到。由公式(3 * weights[index + 1] - m0 - 2 * m1) / dx确定右相邻区间对插值的贡献。
代码解析2
公式(3 * weights[index] - 2 * m0 - m1) / dx 和 (3 * weights[index + 1] - m0 - 2 * m1) / dx 是基于Akima插值方案推导出来的。
为了理解推导,让我们考虑 Akima 插值方案的一般形式:
y(x) = p0(x) * y0 + p1(x) * y1 + q0(x) * m0 + q1(x) * m1
在此等式中,y(x)表示特定坐标处的插值x。y0和y1是x两侧的数据点, m0和m1是与数据点关联的斜率。项p0(x)和p1(x)是数据点的权重系数,q0(x)和q1(x)是数据点关联的斜率的权重系数。
为了确定p0(x)和p1(x),Akima 拟合使用三次多项式来确保平滑性和连续性。这些权重系数由斜率的局部行为决定。
通过考虑Akima插值方案,我们可以推导出代码中使用的具体权重公式:
对于p0(x):权重函数p0(x)决定了左邻域的贡献。在代码中,(3 * weights[index] - 2 * m0 - m1) / dx代表p0(x).
选择特定系数3、-2和1是为了平衡斜率的影响并确保间隔边界处的连续性。这些系数是通过数学分析和优化确定的。
对于p1(x):权重函数p1(x)决定了右邻区间的贡献。在代码中,(3 * weights[index + 1] - m0 - 2 * m1) / dx代表p1(x).同样,选择系数3、-1和-2以实现插值曲线的连续性和平滑性。
导出这些公式中的特定系数是为了最大限度地减少插值误差并保持曲线的连续性。它们是通过数学分析和优化技术确定的,以确保生成的曲线与基础数据点紧密匹配。
代码解析3
yData[index] * (1 - t) * (1 - t) * (1 + 2 * t):这一项代表左边数据点(yData [index]) 对插值的贡献。它乘以三次多项式“(1 - t) * (1 - t) * (1 + 2 * t)”,该多项式取决于参数“t”,范围从 0 到 1。多项式旨在确保左侧数据点的平滑过渡和适当加权。
yData[index + 1] * t * t * (3 - 2 * t):此项表示右侧数据点 (yData[index + 1]) 对插值的贡献。它乘以三次多项式“t * t * (3 - 2 * t)”。与上面类似,这个多项式确保了右侧数据点的平滑过渡和适当加权。
p0 * t * (1 - t) * (1 - t):此项表示左侧相邻区间的调整权重 (p0) 对插值的贡献。它乘以三次多项式“t * (1 - t) * (1 - t)”。该多项式表示左侧相邻区间对插值的影响。
p1 * t * t * (t - 1):此项表示右相邻区间的调整权重 (p1) 对插值的贡献。它乘以三次多项式“t * t * (t - 1)”。该多项式表示右侧邻区间对插值的影响。
该方程结合了相邻数据点的贡献及其相应的权重来计算最终的插值。参数 t 表示区间内的归一化位置,取值范围为 0 到 1。它决定了相邻数据点及其对应区间的相对权重。应用于数据点和权重的三次多项式确保插值曲线的平滑性和连续性。
把上面这些影响因素加一起就是插值点的函数值interpolatedValue了。
备注:以上资料主要来源于以下链接
https://blog.csdn.net/silent_dusbin/article/details/131316458?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-131316458-blog-125541966.235%5Ev43%5Epc_blog_bottom_relevance_base3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-131316458-blog-125541966.235%5Ev43%5Epc_blog_bottom_relevance_base3&utm_relevant_index=2
Akima算法的更多相关文章
- interp1一维数据插值在matlab中的用法
转载:https://ww2.mathworks.cn/help/matlab/ref/interp1.html?s_tid=srchtitle#btwp6lt-2_1 interp1 一维数据插值( ...
- B树——算法导论(25)
B树 1. 简介 在之前我们学习了红黑树,今天再学习一种树--B树.它与红黑树有许多类似的地方,比如都是平衡搜索树,但它们在功能和结构上却有较大的差别. 从功能上看,B树是为磁盘或其他存储设备设计的, ...
- 分布式系列文章——Paxos算法原理与推导
Paxos算法在分布式领域具有非常重要的地位.但是Paxos算法有两个比较明显的缺点:1.难以理解 2.工程实现更难. 网上有很多讲解Paxos算法的文章,但是质量参差不齐.看了很多关于Paxos的资 ...
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 红黑树——算法导论(15)
1. 什么是红黑树 (1) 简介 上一篇我们介绍了基本动态集合操作时间复杂度均为O(h)的二叉搜索树.但遗憾的是,只有当二叉搜索树高度较低时,这些集合操作才会较快:即当树的高度较高(甚至一种极 ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- 虚拟dom与diff算法 分析
好文集合: 深入浅出React(四):虚拟DOM Diff算法解析 全面理解虚拟DOM,实现虚拟DOM
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 46张PPT讲述JVM体系结构、GC算法和调优
本PPT从JVM体系结构概述.GC算法.Hotspot内存管理.Hotspot垃圾回收器.调优和监控工具六大方面进行讲述.(内嵌iframe,建议使用电脑浏览) 好东西当然要分享,PPT已上传可供下载 ...
随机推荐
- #Kruskal重构树,Dijkstra,倍增#洛谷 4768 [NOI2018]归程
题目传送门 分析 首先Dijkstra是必需的(关于SPFA,它死了233) 无向图,所以先求出1号节点到所有点的距离,然后肯定希望起点能驾驶到离一号点最短的汽车可到的地方 但是怎么办,考虑海拔大的边 ...
- #博弈论#HDU 2516 取石子游戏
题目 \(n\)个石子,两人轮流取.先取者第1次可以取任意多个, 但不能全部取完.以后每次取的石子数不能超过上次取子数的2倍. 取完者胜.先取者负输出"Second win".先取 ...
- Java 数学运算与条件语句全解析
Java Math Java 的 Math 类 拥有许多方法,允许您在数字上执行数学任务. 常用方法: Math.max(x, y): 找到 x 和 y 的最大值 Math.min(x, y): 找到 ...
- RabbitMQ 06 工作队列模式
工作队列模式结构图: 这种模式非常适合多个工人等待任务到来的场景.任务有多个,一个一个丢进消息队列,工人也有很多个,就可以将这些任务分配个各个工人,让他们各自负责一些任务,并且做的快的工人还可以多完成 ...
- Qt通过UDP发送广播
// x.h QUdpSocket* udp = nullptr; // UDP对象 void createUdpAndSendData(); // 创建UDP对象和发送广播数据 void dropU ...
- The First 寒假集训の小总结
转眼间十五天的寒假集训已经结束,也学习到了许多新知识,dp,线段树,单调栈和单调队列......,假期过得还是很有意义的,虽然我的两次考试成绩不尽人意(只能怪我自己没有好好理解知识点还有好好做题),但 ...
- redis 简单整理——redis 准备篇[一]
前言 简单整理一下redis. 正文 为什么使用redis? 速度快 1.1 内存执行 1.2 c语言编写,速度相对快一些 1.3 单线程,比较符合这种存储模式 2 丰富的数据结构 3 丰富的功能机制 ...
- Vue-flask 展示小电影
显示小电影 前端Vue <body> <div id="app"> <button @click="handleLoad"> ...
- 力扣1127(MySQL)-用户购买平台(困难)
题目: 支出表: Spending 这张表记录了用户在一个在线购物网站的支出历史,该在线购物平台同时拥有桌面端('desktop')和手机端('mobile')的应用程序.这张表的主键是 (user_ ...
- Apache ShenYu 网关正式支持 Dubbo3 服务代理
简介: 本文介绍了如何通过 Apache ShenYu 网关访问 Dubbo 服务,主要内容包括从简单示例到核心调用流程分析,并对设计原理进行了总结. 作者:刘良 Apache Dubbo 在去年发布 ...