Python版RNA-seq分析教程:DEseq2差异表达基因分析
Bulk RNA-seq 分析的一个重要任务是分析差异表达基因,我们可以用
omicverse包 来完成这个任务。在omicverse中,除了最简单的ttest外,在这里,我们介绍一种类似R语言中的Deseq2等包的模型来计算差异表达基因。
原教程地址:https://omicverse.readthedocs.io/en/latest/Tutorials-bulk/t_deseq2/
环境的下载
在这里我们只需要安装omicverse环境即可,有两个方法:
- 一个是使用conda:
conda install omicverse -c conda-forge - 另一个是使用pip:
pip install omicverse -i https://pypi.tuna.tsinghua.edu.cn/simple/。-i的意思是指定清华镜像源,在国内可能会下载地快一些。
详细的安装教程见omicverse官网。
导入包
我们首先导入分析需要用到的所有包,包括omicverse, pandas, numpy, scanpy matplotlib 和 seaborn.
import omicverse as ov
import pandas as pd
import numpy as np
import scanpy as sc
import matplotlib.pyplot as plt
import seaborn as sns
#设定绘图格式,分辨率300dpi等
ov.utils.ov_plot_set()
下载基因集
当我们需要转换基因 id 时,我们需要准备一个映射对文件。在这里,我们预处理了6个基因组 gtf 文件和生成的映射对,包括 T2T-CHM13,GRCh38,GRCh37,GRCm39,danRer7和 danRer11。如果需要转换其他 id,可以使用 gtf 将文件放在 genesets 目录中生成自己的映射。
ov.utils.download_geneid_annotation_pair()
读取数据
data=pd.read_csv('https://raw.githubusercontent.com/Starlitnightly/ov/master/sample/counts.txt',index_col=0,sep='\t',header=1)
#replace the columns `.bam` to ``
data.columns=[i.split('/')[-1].replace('.bam','') for i in data.columns]
data.head()
值得注意的是,我们的数据集并没有经过任何处理,featurecounts比对时用的gtf为GRCm39,所以我们这里用GRCm39来做基因id映射
基因id转换
data=ov.bulk.Matrix_ID_mapping(data,'genesets/pair_GRCm39.tsv')
data.head()
差异表达分析
我们可以非常简单地通过omicverse进行差异表达基因分析,只需要提供一个表达式矩阵。我们首先创建一个 pyDEG 对象,并使用drop_duplicates_index去除重复的基因。由于部分基因名相同,我们的去除保留了表达量最大的基因名。
dds=ov.bulk.pyDEG(data)
dds.drop_duplicates_index()
print('... drop_duplicates_index success')
现在我们可以从表达矩阵中计算差异表达基因,在计算前我们需要输入实验组和对照组。在这里,我们指定 4-3和4-4为实验组,1--1, 1--2为对照组,我们设定method为DEseq2也是支持的,不过流程可能会有一些区别,我们放到下一期讲。
treatment_groups=['4-3','4-4']
control_groups=['1--1','1--2']
result=dds.deg_analysis(treatment_groups,control_groups,
method='DEseq2')
result.head()
Fitting size factors...
... done in 0.00 seconds.
Fitting dispersions...
... done in 1.59 seconds.
Fitting dispersion trend curve...
... done in 2.82 seconds.
logres_prior=1.1538905878789707, sigma_prior=0.25
Fitting MAP dispersions...
... done in 1.57 seconds.
Fitting LFCs...
... done in 1.27 seconds.
Refitting 0 outliers.
Running Wald tests...
... done in 1.33 seconds.
Log2 fold change & Wald test p-value: condition Treatment vs Control
在计算完差异表达基因后,我们会发现一个重要的事情,就是低表达基因有很多,如果我们不对其进行过滤,会影响后续火山图的绘制,我们设定基因的平均表达量大于1作为阈值,将平均表达量低于1的基因全部过滤掉。
print(result.shape)
result=result.loc[result['log2(BaseMean)']>1]
print(result.shape)
我们还需要设置 Foldchange 的阈值,我们准备了一个名为 foldchange_set 的方法函数来完成。此函数根据 log2FC 分布自动计算适当的阈值,但您也可以手动输入阈值。该函数有三个参数:
- fc_threshold: 差异表达倍数的阈值,-1为自动计算
- pval_threshold: 差异表达基因的p-value过滤值,默认为0.05,在有些情况下可以设定为0.1,意味着统计学差异不显著。
- logp_max: p值的最大值,由于部分p值过小,甚至为0,取对数后火山图绘制较为困难,我们可以设定一个上限,高于这个上限的p值全部统一。
# -1 means automatically calculates
dds.foldchange_set(fc_threshold=-1,
pval_threshold=0.05,
logp_max=6)
差异表达的结果可视化
omicverse除了有较为完善的分析能力外,还有极强的可视化能力。首先是火山图,我们使用 plot_volcano函数来实现。该函数可以绘制你感兴趣的基因或高表达的基因。您需要输入一些参数:
- title: 火山图的标题
- figsize: 图像大小
- plot_genes: 需要绘制的基因,格式为list。如
['Gm8925','Snorc'] - plot_genes_num: 需要绘制的基因数,该参数与
plot_genes互斥,如果我们没有指定需要绘制的基因,可以自动绘制前n个高差异表达倍数的基因。
此外,我们还可以指定绘制的颜色等,具体的参数可以使用help(dds.plot_volcano)来查看
dds.plot_volcano(title='DEG Analysis',figsize=(4,4),
plot_genes_num=8,plot_genes_fontsize=12,)
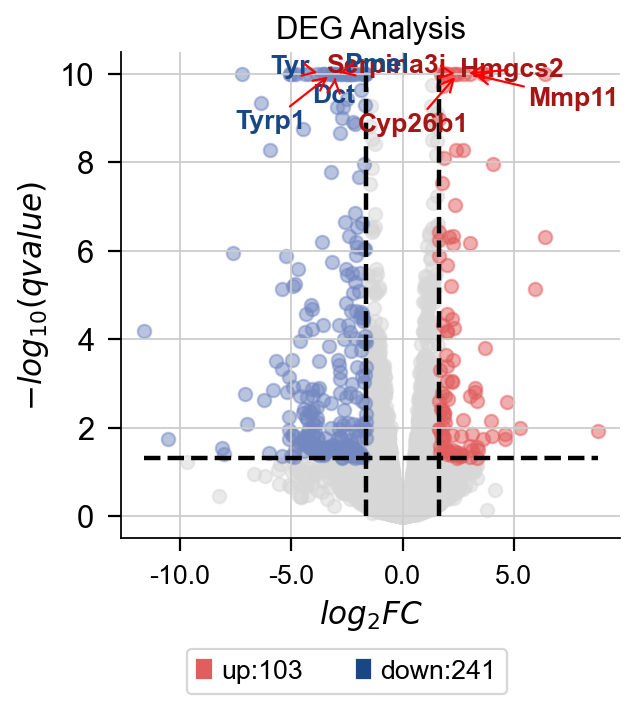 差异表达火山图
差异表达火山图
如果我们想绘制特定的基因的箱线图,我们也可以使用 plot_boxplot 函数来完成该任务。
dds.plot_boxplot(genes=['Ckap2','Lef1'],treatment_groups=treatment_groups,
control_groups=control_groups,figsize=(2,3),fontsize=12,
legend_bbox=(2,0.55))
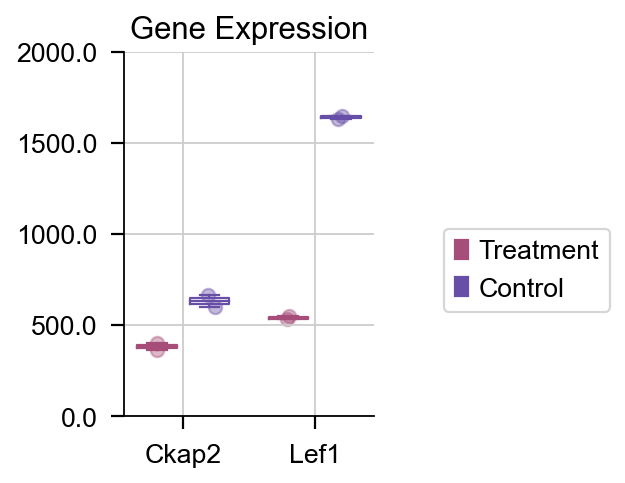 差异表达箱线图
差异表达箱线图
通路富集分析
在差异表达基因计算出来后,我们需要直接进行的下一步分析往往是看差异表达的基因与哪些通路相关,这里我们常用的方法是富集分析。omicverse可以一键完成富集分析并且可视化。
我们封装了gseapy 包进入omicverse,其中包括 GSEA 富集分析的相关功能。我们优化了包的输出,并给出了一些更好看的图形绘制功能
类似地,我们首先需要下载通路数据库。我们已经准备好了五个基因集,可以使用 ov.utils.download_pathway_database()进行自动下载。除此之外,你还可以在以下网站找到你感兴趣的基因集: https://maayanlab.cloud/enrichr/#libraries
ov.utils.download_pathway_database()
#读取通路基因集,我们读取Wiki通路数据库
pathway_dict=ov.utils.geneset_prepare('genesets/WikiPathways_2019_Mouse.txt',organism='Mouse')
与此前选取差异表达的基因进行通路富集分析不同,在这里,我们使用基因的差异倍数和p值进行排序,进行GSEA分析。我们使用以下公式计算基因的顺序。
rnk=dds.ranking2gsea()
们使用 ov.bulk.pyGSEA 构造一个 GSEA 对象来执行通路富集分析。
gsea_obj=ov.bulk.pyGSEA(rnk,pathway_dict)
enrich_res=gsea_obj.enrichment()
通路富集分析的结果被存放在enrich_res变量中,我们使用.head()函数来查看
gsea_obj.enrich_res.head()
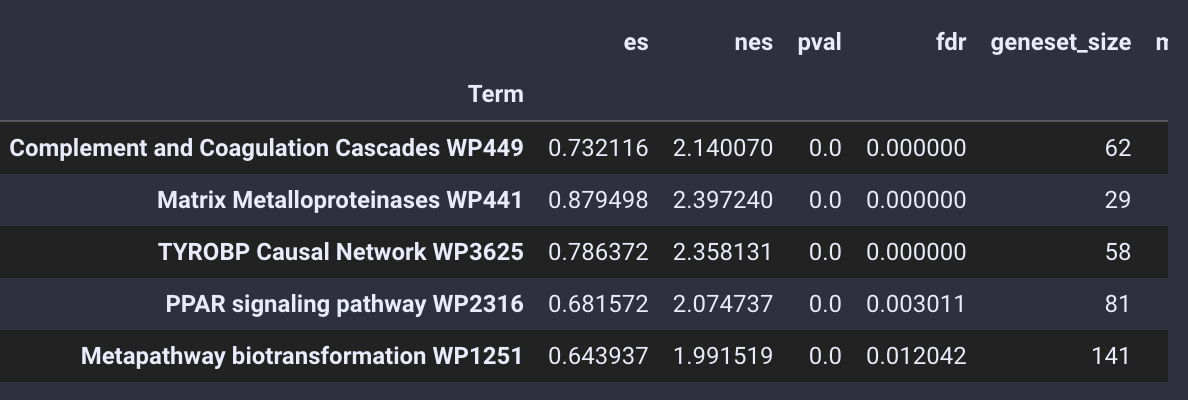 通路富集结果
通路富集结果
为了可视化通路富集的结果,我们使用.plot_enrichment函数来完成该目的.
- num: 需要展示的通路富集结果,默认是前10条.
- node_size: 点的大小标注值. 默认是[5,10,15].
- cax_loc: 图注的横坐标. 默认值 2.
- cax_fontsize: 图注的字体大小,默认值 12.
- fig_title: 富集结果的标题.
- fig_xlabel: 富集结果的横坐标标题,默认值是'Fractions of genes'.
- figsize: 图像大小,默认值是(2,4).
- cmap: 图像颜色条,默认值是'YlGnBu'.
gsea_obj.plot_enrichment(num=10,node_size=[10,20,30],
cax_loc=2.5,cax_fontsize=12,
fig_title='Wiki Pathway Enrichment',fig_xlabel='Fractions of genes',
figsize=(2,4),cmap='YlGnBu',
text_knock=2,text_maxsize=30)
 通路富集结果
通路富集结果
不仅仅是基本的富集分析,pyGSEA 还可以帮助我们用绘制GSEA的排序图,我们需要选择想绘制的通路,给定通路的Term位置,例如0 是Complement and Coagulation Cascades WP449 ,1 是 Matrix Metalloproteinases WP441
gsea_obj.enrich_res.index[:5]
Index(['Complement and Coagulation Cascades WP449',
'Matrix Metalloproteinases WP441', 'TYROBP Causal Network WP3625',
'PPAR signaling pathway WP2316',
'Metapathway biotransformation WP1251'],
dtype='object', name='Term')
我们可以使用.plot_gsea完成绘制。
- term_num: 需要绘制的通路在index的位置
- gene_set_title: 通路标题,可自定义,如果原index中的太长
fig=gsea_obj.plot_gsea(term_num=1,
gene_set_title='Matrix Metalloproteinases',
figsize=(3,4),
cmap='RdBu_r',
title_fontsize=14,
title_y=0.95)
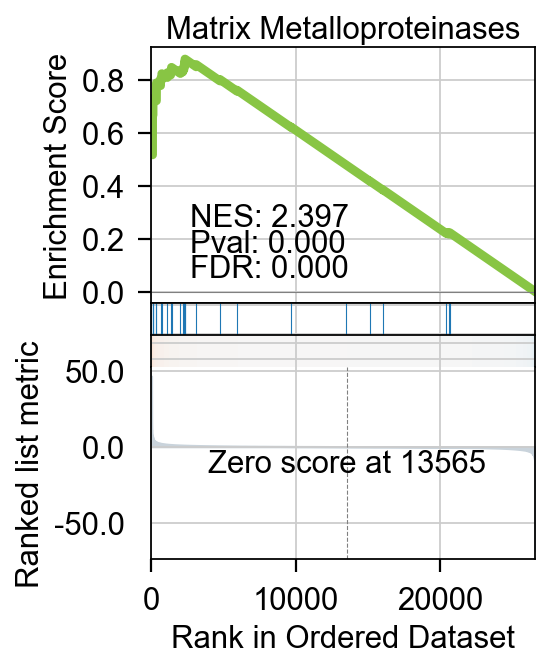 GSEA富集可视化
GSEA富集可视化
Python版RNA-seq分析教程:DEseq2差异表达基因分析的更多相关文章
- RNA-seq差异表达基因分析之TopHat篇
RNA-seq差异表达基因分析之TopHat篇 发表于2012 年 10 月 23 日 TopHat是基于Bowtie的将RNA-Seq数据mapping到参考基因组上,从而鉴定可变剪切(exon-e ...
- 差异基因分析:fold change(差异倍数), P-value(差异的显著性)
在做基因表达分析时必然会要做差异分析(DE) DE的方法主要有两种: Fold change t-test fold change的意思是样本质检表达量的差异倍数,log2 fold change的意 ...
- python版的MCScan绘图
最近发现了python版的MCScan,是个大宝藏.由于走了不少弯路,终于画出美图,赶紧记录下来. github地址 https://github.com/tanghaibao/jcvi/wiki/M ...
- 《zw版·Halcon-delphi系列原创教程》cgal与opencv,Halcon
<zw版·Halcon-delphi系列原创教程>cgal与opencv,Halcon opencv作为少有的专业开源图像软件,虽然功能,特别是几何计算方面,不如Halcon,不过因为开源 ...
- 《zw版·Halcon-delphi系列原创教程》 Halcon分类函数013,shape模型
<zw版·Halcon-delphi系列原创教程> Halcon分类函数013,shape模型 为方便阅读,在不影响说明的前提下,笔者对函数进行了简化: :: 用符号“**”,替换:“pr ...
- 《zw版·Halcon-delphi系列原创教程》 Halcon分类函数006, image,影像处理(像素图)
<zw版·Halcon-delphi系列原创教程> Halcon分类函数006, image,影像处理(像素图) 为方便阅读,在不影响说明的前提下,笔者对函数进行了简化: :: 用符号“* ...
- Wireshark数据抓包教程之认识捕获分析数据包
Wireshark数据抓包教程之认识捕获分析数据包 认识Wireshark捕获数据包 当我们对Wireshark主窗口各部分作用了解了,学会捕获数据了,接下来就该去认识这些捕获的数据包了.Wiresh ...
- RNA -seq
RNA -seq RNA-seq目的.用处::可以帮助我们了解,各种比较条件下,所有基因的表达情况的差异. 比如:正常组织和肿瘤组织的之间的差异:检测药物治疗前后,基因表达的差异:检测发育过程中,不同 ...
- Spark (Python版) 零基础学习笔记(一)—— 快速入门
由于Scala才刚刚开始学习,还是对python更为熟悉,因此在这记录一下自己的学习过程,主要内容来自于spark的官方帮助文档,这一节的地址为: http://spark.apache.org/do ...
- ROS Learning-013 beginner_Tutorials (编程) 编写ROS服务版的Hello World程序(Python版)
ROS Indigo beginner_Tutorials-12 编写ROS服务版的Hello World程序(Python版) 我使用的虚拟机软件:VMware Workstation 11 使用的 ...
随机推荐
- INFINI Labs 产品更新 | Easysearch 1.8.0 发布数据写入限流功能
INFINI Labs 产品又更新啦~,包括 Easysearch v1.8.0.Gateway.Console.Agent.Loadgen v1.25.0.本次各产品更新了很多亮点功能,如 Easy ...
- Kubernetes监控手册06-监控APIServer
写在前面 如果是用的公有云托管的 Kubernetes 集群,控制面的组件都交由云厂商托管的,那作为客户的我们就省事了,基本不用操心 APIServer 的运维.个人也推荐使用云厂商这个服务,毕竟 K ...
- 玩爆你的手机联系人--T9搜索
自己研究了好几天联系人的T9搜索算法, 先分享出来给大家看看. 欢迎指教.如果有大神有更好的T9搜索算法, 那更好啊,大家一起研究研究,谢谢. 第一部分是比较简单的获取手机联系人. 获取联系人 ...
- Spring Boot 使用 拦截器 实现 token 验证
Spring Boot 使用 拦截器 实现 token 验证 整体思路:1.写一个工具类封装生成.校验和解析 token 的方法:2.在注册和登录时生成 token ,生成的 token 存入 red ...
- @Async异步方法对异常的处理,从内层向外层抛出机制
@Async异步方法对异常的处理,从内层向外层抛出机制 @RequestMapping(value = "/test", method = RequestMethod.GET) p ...
- 18-Docker资源限制
背景 若容器使用的计算机资源不加限制,那么,可能会耗光整个计算机资源. 如代码里有bug,出现了死循环,且创建了很多线程. 在Docker中,可以使用Cgroup技术限制CPU.Block IO.RA ...
- 【动手学深度学习】第三章笔记:线性回归、SoftMax 回归、交叉熵损失
这章感觉没什么需要特别记住的东西,感觉忘了回来翻一翻代码就好. 3.1 线性回归 3.1.1 线性回归的基本元素 1. 线性模型 \(\boldsymbol{x}^{(i)}\) 是一个列向量,表示第 ...
- 基恩士PLC数据 转 Modbus RTU TCP项目案例
1 案例说明 1. 设置网关采集基恩士PLC数据 2. 把采集的数据转成Modbus协议转发给其他系统. var code = "244226f8-1eed-48e4 ...
- win10系统常用命令(netstat、ping、telnet、sc、netsh命令)
netstat命令 1. 查找端口占用 netstat -ano netstat -ano | findstr 5000 ping命令 ping 192.168.1.1 ping baidu.com ...
- Nuxt3 的生命周期和钩子函数(八)
title: Nuxt3 的生命周期和钩子函数(八) date: 2024/6/30 updated: 2024/6/30 author: cmdragon excerpt: 摘要:本文介绍了Nuxt ...