mysql千万级数据表,创建表及字段扩展的几条建议
一:概述
当我们设计一个系统时,需要考虑到系统的运行一段时间后,表里数据量大约有多少,如果在初期,就能估算到某几张表数据量非常庞大时(比如聊天消息表),就要把表创建好,这篇文章从创建表,增加数据,以及字段扩展,这几个方面来给出建议。
二:创建表
假如现在我们需要创建IM项目中的聊天消息表,这个表数据量大,读操作远超过写操作,我们都知道,mysql常用的数据库引擎主要有innodb,myisam,这两个数据库引擎主要区别是,innodb支持事务,支持外键,锁是行级锁(行级锁只是针对主键,非主键也会锁全表),myisam不支持事务,不支持外键约束,锁是表级锁,从性能角度分析,myisam要比innodb更好一些,所以在数据库引擎上,我选择myisam,另外在消息发送用户id和消息接收用户id上加索引。
1:数据类型的选择
由于考虑到数据量非常大,所以在字段数据类型选择时,能用数字的就不要用字符串,当然时间类型也要用bigint来代替,不建议使用text类型,在varchar字段上建议创建默认值,比如:default '' ,因为where 使用 is null是全表扫描,数字类型也需要加默认值,比如 num int default 0,如果不加默认值,并且执行insert 语句,也没有对该字段赋值,哪么执行update xxx set num = num +1 时,你会发现sql不报错,然后num的值却没更新到,另外需要在作为条件查询的字段加索引.
2:表分区
在大数据面前,除了数据类型和性能有很大关系之外,我们还可以使用表分区,分表和分库目前还用不上,表分区概念
2.1 表分区概念
range分区:基于属于一个给定连续区间的列值,把多行分配给分区。
list分区:和range分区类似,区别是list分区是基于列值匹配一个离散值集合中的某个值来进行选择。
hash分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含>整数值。
可以使用SHOW VARIABLES LIKE '%partition%';来确定mysql支持的分区类型.
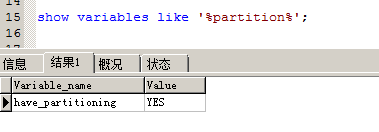
现在我使用range分区,分区字段是pk,完整sql语句如下
CREATE TABLE chatmsg(
cid bigint primary key,
cMsgSendUserId bigint,
cMsgReceiverUserId bigint,
cTime bigint,
cContent varchar(2000) not null default '',
cExt varchar(5000)
) ENGINE=MYISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin
PARTITION BY RANGE (cid) (
PARTITION p0 VALUES LESS THAN (1000000),
PARTITION p1 VALUES LESS THAN (5000000),
PARTITION p2 VALUES LESS THAN (1000000),
PARTITION p3 VALUES LESS THAN MAXVALUE
) ; create index senduserid_index on chatmsg(cMsgSendUserId);
create index receiverid_index on chatmsg(cMsgReceiverUserId);
create index ctime_index on chatmsg(ctime);
三:添加聊天记录。
从建表语句中看到,我们并没有使用外键,所以就需要手动检查外键约束的完整性。
select count(1) from user where uid = 消息发送者id
union all
select count(1) from user where uid = 消息接收者id
当上面的语句返回结果等于2时,才能执行添加语句。优化查询语句,可以参考我的这一篇文章:百万数据量优化方案
四:扩展字段
假如现在表已经产生了5千万条数据,产品经理过来说,小王,聊天记录需要加一个已读或未读的状态,如果此时在正式使用环境去alter tableadd column,可以想像这个操作有多耗时,有可能数据库直接崩溃都说不定,数据量大了,进行alter tableadd column操作数据库真崩溃过,不是危言耸听,还记得在建表的时候,我们创建了一个cExt字段,这个字段我们记录一个json 字符串,其实正确做法还要加一个版本号,这里我就没有加版本号。表里面的数据如下:
select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 100 and cMsgReceiverUserId = 200
union ALL
select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 200 and cMsgReceiverUserId = 100
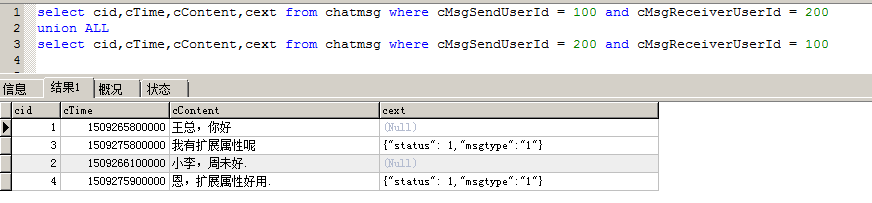
这个方法能解决大部分扩展字段,查询出cext后,然后把该值转换为对像就可以。如果新增的字段,需要出现在where中,就需要根据实际情况进行分析了。
cext扩展字段优点:
(1)可以随时动态扩展属性
(2)新旧两种数据可以同时存在
(3)迁移数据方便,写个小程序将旧版本ext的改为新版本的ext,并修改version
cext扩展字段不足:
(1)cext里的字段无法建立索引
(2)cext里的key值有大量冗余,建议key短一些
五:其它
比如项目初期,产品经理说,小王,我选择任意两个用户,查询这两个人的聊天记录,需要返回这两个用户的昵称,产品经理选择两个用户,我们得到了这两个用户的id,如果直接chat表join user表,性能同样不好,这种情况我们可以考虑使用空间换时间,比如在聊天表中直接创建接收者和发送者的昵称。这个方法表达的意思是,大数据表尽量不要join,性能是不好的,要用其它办法来解决这个问题。当然在正式项目中,具体情况还需要具体分析。
我也会补充一些想法,如果文中有描述错误的地方,希望指出来,谢谢,欢迎大家发表自己的想法,大家共同进步。
mysql千万级数据表,创建表及字段扩展的几条建议的更多相关文章
- MySQL 千万级 数据库或大表优化
首先考虑如下因素: 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数据查询SQL条件:哪些数据项的列名称经常出现在WH ...
- 提高mysql千万级数据SQL的查询优化30条总结
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- MySQL千万级数据JDBC插入
案例语句: String sql = "LOAD DATA LOCAL INFILE '" + dataFilepath + "' into table " + ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- MySQL千万级大表优化解决方案
MySQL千万级大表优化解决方案 非原创,纯属记录一下. 背景 无意间看到了这篇文章,作者写的很棒,于是乎,本人自私一把,把干货保存下来.:-) 问题概述 使用阿里云rds for MySQL数据库( ...
- mysql循环插入千万级数据
mysql使用存储过程循环插入大量数据,简单的一条条循环插入,效率会很低,需要考虑批量插入. 测试准备: 1.建表: CREATE TABLE `mysql_genarate` ( `id` ) NO ...
- 千万级SQL Server数据库表分区的实现
千万级SQL Server数据库表分区的实现 2010-09-10 13:37 佚名 数据库 字号:T | T 一般在千万级的数据压力下,分区是一种比较好的提升性能方法.本文将介绍SQL Server ...
- mysql千万级测试1亿数据的分页分析测试
本文为本人最近利用几个小时才分析总结出的原创文章,希望大家转载,但是要注明出处 http://blog.sina.com.cn/s/blog_438308750100im0e.html 有什么问题可以 ...
随机推荐
- 【Java框架型项目从入门到装逼】第一节 - Spring框架 IOC的丧心病狂解说
大家好,好久不见,今天我们来一起学习一下关于Spring框架的IOC技术. 控制反转--Spring通过一种称作控制反转(IoC)的技术促进了松耦合.当应用了IoC,一个对象依赖的其它对象会通过被动的 ...
- C# 处理Word自动生成报告 二、数据源例子
还是以学生.语文.数学.分数为例吧, 感觉这个和helloworld都有一拼了. 造一张表如下, 整张报表就围绕这个表转圈了, 顺便说下就是名字如有雷同纯属巧合 新建个存储过程 ALTER PROCE ...
- Linux笔记(固定USB摄像头硬件端口,绑定前后置摄像头)
在Android的系统会有前置摄像头和后置摄像头的定义,摄像头分为SOC类型的摄像头和USB这一类的摄像头,接下要分析就是USB摄像头这一类 . 一般在android或者linux系统中分析一个模块, ...
- 一个RtspServer的设计与实现和RTSP2.0简介
一个RtspServer的设计与实现和RTSP2.0简介 前段时间着手实现了一个RTSP Server,能够正常实现多路RTSP流的直播播放,因项目需要,只做了对H.264和AAC编码的支持,但是 ...
- 神奇的 routing mesh - 每天5分钟玩转 Docker 容器技术(100)
接上一节案例,当我们访问任何节点的 8080 端口时,swarm 内部的 load balancer 会将请求转发给 web_server 其中的一个副本. 这就是 routing mesh 的作用. ...
- java二进制相关基础
转载请注明原创出处,谢谢! 说在前面 之前在JVM菜鸟进阶高手之路十(基础知识开场白)的时候简单提到了二进制相关问题,最近在看RocketMQ的源码的时候,发现涉及二进制的内容蛮多,jdk源码里面也是 ...
- thinkphp5源码解析(1)数据库
前言 tp5的数据库操作全部通过Db类完成,比较符合国人的习惯,比如简单的Db::query().Db::execute(),还有复杂的链式操作Db::where('id=1')->select ...
- VMware中克隆虚拟机出现eth0改变为eth1情况
解决如下: 查看复制虚拟机网卡信息如下: root@jcfx-2 ~]# ifconfig eth1 Link encap:Ethernet HWaddr 00:0C:29:CC:32:63 inet ...
- php使用rc4加密算法
/** * rc4加密算法,解密方法直接再一次加密就是解密 * @param [type] $data 要加密的数据 * @param [type] $pwd 加密使用的key * @retur ...
- UWP Flyout浮动控件
看见没,点击"Options"按钮,浮动出来一个界面,这个界面可以用xaml自定义. 如果要点击的控件又Flyout属性那么,可以直接按照下面用 <Button Conten ...