神经网络 误差逆传播算法推导 BP算法
误差逆传播算法是迄今最成功的神经网络学习算法,现实任务中使用神经网络时,大多使用BP算法进行训练。
给定训练集\(D={(x_1,y_1),(x_2,y_2),......(x_m,y_m)},x_i \in R^d,y_i \in R^l\),即输入示例由\(d\)个属性描述,输出\(l\)个结果。如图所示,是一个典型的单隐层前馈网络,它拥有\(d\)个输入神经元、\(l\)个输出神经元、\(q\)个隐层神经元,其中,\(\theta_j\)表示第\(j\)个神经元的阈值,\(\gamma_h\)表示隐层第\(h\)个神经元的阈值,输入层第\(i\)个神经元与隐层第\(h\)个神经元连接的权值是\(v_{ih}\),隐层第\(h\)个神经元与输出层第\(j\)个神经元连接的权值是\(w_{hj}\)。
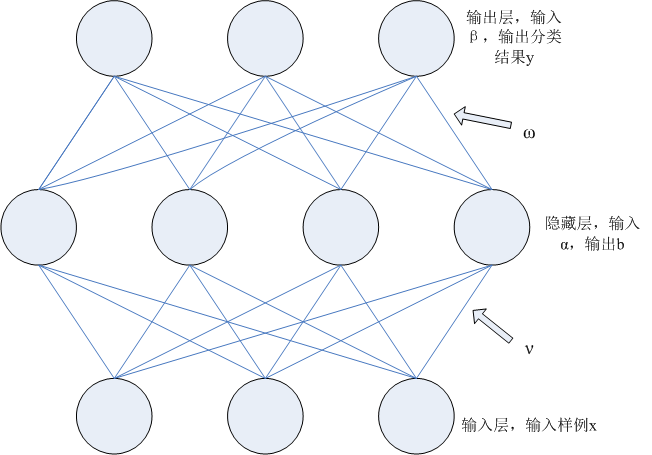
于是,按照神经网络的传输法则,隐层第\(h\)个神经元接收到的输入\(\alpha_h=\sum_{i=1}^dv_{ih}x_i\),输出\(b_h=f(\alpha_h-\gamma_h)\),输出层\(j\)第个神经元的输入\(\beta_j=\sum_{h=1}^qw_{hj}b_h\),输出\(\widehat{y}_j^k=f(\beta_j-\theta_j)\),其中\(f\)函数是“激活函数”,\(\gamma_h\)和\(\theta_j\)分别是隐藏层和输出层的阈值,选择Sigmoid函数\(f(x)=\frac{1}{1+e^{-x}}\)作为激活函数。
对训练样例\((x_k,y_k)\),通过神经网络后的输出是\(\widehat{y}_k=(\widehat{y}_1^k,\widehat{y}_2^k,......,\widehat{y}_l^k)\),则其均方误差为
\[E_k=\frac{1}{2}\sum_{j=1}^{l}(\widehat{y}_j^k-y_j^k)^2(1)\]
为了使输出的均方误差最小,我们以均方误差对权值的负梯度方向进行调整,给定学习率\(\eta\),
\[\Delta w_{ij}=-\eta\frac{\partial E_k}{\partial w_{ij}}\ (2)
\]这里为什么是取负梯度方向呢?因为我们是要是均方误差最小,而
\(w\)的更新估计式为\[w=w+\Delta w (3)
\]如果,\(\frac{\partial E_k}{\partial w_{ij}}>0\),则表明减小\(w\)才能减小均方误差,所以\(\Delta w\)应该小于零,反之,如果\(\frac{\partial E_k}{\partial w_{ij}}<0\),则表明增大\(w\)的值可以减小均方误差,所以所以\(\Delta w\)应该大于零,所以在这里取负的偏导,以保证权值的改变是朝着减小均方误差的方向进行。
在这个神经网络中,\(E_k\)是有关\(\widehat{y}_j^k\)的函数,\(\widehat{y}_j^k\)是有关\(\beta_j\)的函数,而\(\beta_j\)是有关\(w_{ij}\)的函数,所以有
\[\frac{\partial E_k}{\partial w_{ij}}=\frac{\partial E_k}{\partial \widehat{y}_j^k}.\frac{\partial \widehat{y}_j^k}{\partial \beta_j}. \frac{\partial \beta_j}{\partial w_{ij}} (4)
\]显然,
\[\frac{\partial \beta_j}{\partial w_{ij}}=b_h (5)
\]而对Sigmoid函数有
\[f'(x)=f(x)(1-f(x)) (6)
\]所以
\[\begin{aligned}g_j&=-\frac{\partial E_k}{\partial\widehat{y}_j^k}. \frac{\partial\widehat{y}_j^k}{\partial\beta_j}\\
&=-(\widehat{y}^k_j-y^k_j)f'(\beta_j-\theta_j)\\
&=-(\widehat{y}^k_j-y^k_j)f(\beta_j-\theta_j)(1-f(\beta_j-\theta_j))\\
&=-(\widehat{y}^k_j-y^k_j)\widehat{y}^k_j(1-\widehat{y}^k_j)\end{aligned} (7)
\]将式(7)代入式(3)和式(4),就得到BP算法中关于\(\Delta w_{ij}\)的更新公式
\[\Delta w_{ij}=\eta g_jb_h (8)
\]类似可得,
\[\Delta \theta_j=-\eta g_j (9)
\]\[\Delta v_{ih}=\eta e_hx_i (10)
\]\[\Delta \gamma_h=-\eta e_h (11)
\]其中,式(10)和式(11)中
\[\begin{aligned}e_h&=-\frac{\partial E_k}{\partial b_h}.\frac{\partial b_h}{\partial \alpha_h}\\&=-\sum_{j=1}^l\frac{\partial E_k}{\partial \beta_j}.\frac{\partial \beta_j}{\partial b_h}f'(\alpha_h-\gamma_h)\\&=\sum_{j=1}^lw_{hi}g_jf'(\alpha_h-\gamma_h)\\&=b_h(1-b_h)\sum_{j=1}^lw_{hj}g_j\end{aligned} (12)\]
至此,误差逆传播算法的推导已经完成,我们可以回过头看看,该算法为什么被称为误差逆传播算法呢?误差逆传播,顾名思义是让误差沿着神经网络反向传播,根据上面的推导, \(\Delta w_{ij}=-\eta(\widehat{y}^k_j-y^k_j).\frac{\partial \widehat{y}_j^k}{\partial \beta_j}.b_h=\eta g_jb_h\),其中,\((\widehat{y}^k_j-y^k_j)\)是输出误差,\(\frac{\partial \widehat{y}_j^k}{\partial \beta_j}\) 是输出层节点的输出\(y\)对于输入\(\beta\)的偏导数,可以看做是误差的调节因子,我们称\(g_j\)为“调节后的误差”;而\(\Delta v_{ih}=\eta e_hx_i\),\(e_h=b_h(1-b_h)\sum_{j=1}^lw_{hj}g_j=\frac{\partial b_h}{\partial \alpha_h}\sum_{j=1}^lw_{hj}g_j\),所以\(e_h\)可以看做是“调节后的误差”\(g_j\)通过神经网络后并经过调节的误差,并且我们可以看出:权值的调节量=学习率x调节后的误差x上层节点的输出,算是对于误差逆向传播法表面上的通俗理解,有助于记忆。
神经网络 误差逆传播算法推导 BP算法的更多相关文章
- 神经网络和误差逆传播算法(BP)
本人弱学校的CS 渣硕一枚,在找工作的时候,发现好多公司都对深度学习有要求,尤其是CNN和RNN,好吧,啥也不说了,拿过来好好看看.以前看习西瓜书的时候神经网络这块就是一个看的很模糊的块,包括台大的视 ...
- 误差逆传播(error BackPropagation, BP)算法推导及向量化表示
1.前言 看完讲卷积神经网络基础讲得非常好的cs231后总感觉不过瘾,主要原因在于虽然知道了卷积神经网络的计算过程和基本结构,但还是无法透彻理解卷积神经网络的学习过程.于是找来了进阶的教材Notes ...
- 人工智能起步-反向回馈神经网路算法(BP算法)
人工智能分为强人工,弱人工. 弱人工智能就包括我们常用的语音识别,图像识别等,或者为了某一个固定目标实现的人工算法,如:下围棋,游戏的AI,聊天机器人,阿尔法狗等. 强人工智能目前只是一个幻想,就是自 ...
- 人工神经网络反向传播算法(BP算法)证明推导
为了搞明白这个没少在网上搜,但是结果不尽人意,最后找到了一篇很好很详细的证明过程,摘抄整理为 latex 如下. (原文:https://blog.csdn.net/weixin_41718085/a ...
- 深度学习——前向传播算法和反向传播算法(BP算法)及其推导
1 BP算法的推导 图1 一个简单的三层神经网络 图1所示是一个简单的三层(两个隐藏层,一个输出层)神经网络结构,假设我们使用这个神经网络来解决二分类问题,我们给这个网络一个输入样本,通过前向运算得到 ...
- Backpropagation反向传播算法(BP算法)
1.Summary: Apply the chain rule to compute the gradient of the loss function with respect to the inp ...
- BP(back propagation)误差逆传播神经网络
[学习笔记] BP神经网络是一种按误差反向传播的神经网络,它的基本思想还是梯度下降法,中间隐含层的误差和最后一层的误差存在一定的数学关系,(可以计算出来),就像误差被反向传回来了,所以顾名思义BP.想 ...
- 多层神经网络BP算法 原理及推导
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解).当网络的层次大于等于3层(输入层+隐藏层(大于 ...
- BP神经网络算法推导及代码实现笔记zz
一. 前言: 作为AI入门小白,参考了一些文章,想记点笔记加深印象,发出来是给有需求的童鞋学习共勉,大神轻拍! [毒鸡汤]:算法这东西,读完之后的状态多半是 --> “我是谁,我在哪?” 没事的 ...
随机推荐
- 深入理解javascript函数进阶系列第一篇——高阶函数
前面的话 前面的函数系列中介绍了函数的基础用法.从本文开始,将介绍javascript函数进阶系列,本文将详细介绍高阶函数 定义 高阶函数(higher-order function)指操作函数的函数 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- 怎么配置Jupyter Notebook默认启动目录?
前言 系统环境:win10 x64:跟环境也没啥关系,在LInux下也一样... 前段时间重换了系统后,发现Jupyter Notebook的默认启动目录不太对呀,所以,就翻到了以前的笔记,还是记在这 ...
- c# textbox的滚动条总是指向最底端
当我第一次添加滚动条时候,我发现滚动条总是跑向上方,经过研究 解决方案如下: this.textBox1.Focus(); 获取焦点 this.textBox1.Select(this.textBox ...
- 直播一:H.264编码基础知识详解
一.编码基础概念 1.为什么要进行视频编码? 视频是由一帧帧图像组成,就如常见的gif图片,如果打开一张gif图片,可以发现里面是由很多张图片组成.一般视频为了不让观众感觉到卡顿,一秒钟至少需要16帧 ...
- 基于‘BOSS直聘的招聘信息’分析企业到底需要什么样的PHP程序员
原文地址:http://www.jtahstu.com/blog/scrapy_zhipin_php.html 基于'BOSS直聘的招聘信息'分析企业到底需要什么样的PHP程序员 标签(空格分隔): ...
- Java内存模型—JMM
有时候编译器.处理器的优化会导致runtime与我们设想的不一样,为此Java对编译器和处理器做了一些限制,JAVA内存模型(JMM)将这些抽象出来,这样编写代码时就无需考虑那么多底层细节,并保证& ...
- Unix:关于一个file在file system和disk中占用空间
參考文献: Harley Hahns:Guide to Unix and Linux. Chap 24 -->首先要有的关键概念:the amount of "disk space&q ...
- @Autowired注解在抽象类中实效的原因分析
最近在工作中遇到这个问题,在抽象类中使用Autowired这个注解,注入mybatis的dao时,总是出现空指针异常,通过日志的打印,发现是这个dao注入失败为空.然后通过new出spring上下文对 ...
- eclipse 代码 editor 界面出现奇怪符号解决
Preferences->General->Editors->Text Editors->去掉 Show whitespace characters->apply