【Spring】BeanFactory解析bean详解
package bean;
public class TestBean {
private String beanName = "beanName";
public String getBeanName() {
return beanName;
}
public void setBeanName(String beanName) {
this.beanName = beanName;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.1.xsd">
<bean id="testBean" class="bean.TestBean">
</beans>
public class BeanTest {
private static final java.util.logging.Logger logger = LoggerFactory.getLogger(BeanTest.class);
@Test
public void getBeanTest() {
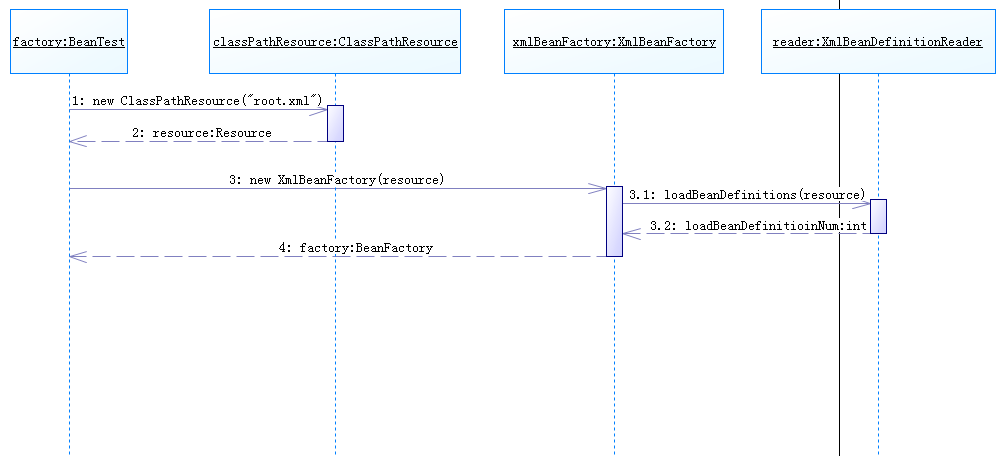
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("root.xml"));
TestBean bean = factory.getBean("testBean");
logger.info(bean.getBeanName);
}
}
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
}
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
private Class<?> documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
private ProblemReporter problemReporter = new FailFastProblemReporter();
private ReaderEventListener eventListener = new EmptyReaderEventListener();
private SourceExtractor sourceExtractor = new NullSourceExtractor();
private NamespaceHandlerResolver namespaceHandlerResolver;
private DocumentLoader documentLoader = new DefaultDocumentLoader();
private EntityResolver entityResolver;
private ErrorHandler errorHandler = new SimpleSaxErrorHandler(logger);
}
public abstract class AbstractBeanDefinitionReader implements EnvironmentCapable, BeanDefinitionReader {
protected final Log logger = LogFactory.getLog(getClass());
private final BeanDefinitionRegistry registry;
private ResourceLoader resourceLoader;
private ClassLoader beanClassLoader;
private Environment environment;
private BeanNameGenerator beanNameGenerator = new DefaultBeanNameGenerator();
}
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("root.xml"));
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
// 通过属性记录已加载的资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
// 从resource中获取对应的InputStream,用于下面构造InputSource
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 调用doLoadBeanDefinitions方法
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
}
/* 省略一堆catch */
}
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
public class DefaultDocumentLoader implements DocumentLoader {
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
}
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(getEnvironment());
// 还没注册bean前的BeanDefinition加载个数
int countBefore = getRegistry().getBeanDefinitionCount();
// 加载注册bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 本次加载注册的BeanDefinition个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 下面对bean进行处理
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
<bean id="testBean" class="bean.TestBean">
<tx:annotation-driven />
XmlBeanFactory加载bean的整个过程基本就讲解到这里了。
【Spring】BeanFactory解析bean详解的更多相关文章
- Spring自动装配Bean详解
1. Auto-Wiring ‘no’ 2. Auto-Wiring ‘byName’ 3. Auto-Wiring ‘byType 4. Auto-Wirin ...
- Spring二 Bean详解
Bean详解 Spring框架的本质其实是:通过XML配置来驱动Java代码,这样就可以把原本由java代码管理的耦合关系,提取到XML配置文件中管理.这样就实现了系统中各组件的解耦,有利于后期的升级 ...
- Spring框架系列(8) - Spring IOC实现原理详解之Bean实例化(生命周期,循环依赖等)
上文,我们看了IOC设计要点和设计结构:以及Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的:容器中存放的是Bean的定义即Be ...
- spring在IoC容器中装配Bean详解
1.Spring配置概述 1.1.概述 Spring容器从xml配置.java注解.spring注解中读取bean配置信息,形成bean定义注册表: 根据bean定义注册表实例化bean: 将bean ...
- Spring Bean 详解
Spring Bean 详解 Ioc实例化Bean的三种方式 1 创建Bean 1 使用无参构造函数 这也是我们常用的一种.在默认情况下,它会通过反射调⽤⽆参构造函数来创建对象.如果类中没有⽆参构造函 ...
- (转)java之Spring(IOC)注解装配Bean详解
java之Spring(IOC)注解装配Bean详解 在这里我们要详细说明一下利用Annotation-注解来装配Bean. 因为如果你学会了注解,你就再也不愿意去手动配置xml文件了,下面就看看 ...
- Spring IoC @Autowired 注解详解
前言 本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本.因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析. 我们平时使用 Spring 时,想要 依赖 ...
- Spring IoC 公共注解详解
前言 本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本.因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析. 什么是公共注解?公共注解就是常见的Java ...
- Spring框架系列(6) - Spring IOC实现原理详解之IOC体系结构设计
在对IoC有了初步的认知后,我们开始对IOC的实现原理进行深入理解.本文将帮助你站在设计者的角度去看IOC最顶层的结构设计.@pdai Spring框架系列(6) - Spring IOC实现原理详解 ...
随机推荐
- C#推送RTMP到SRS通过VLC进行取流播放!!
前面一篇文章简单的介绍了下如何利用SRS自带的播放地址进行观看RTMP直播流,也就是说是使用SRS的内置demo进行Test,但是进行视频直播肯定不可能使用那样的去开发,不开源的东西肯定不好用.由于在 ...
- 4105: [Thu Summer Camp 2015]平方运算
首先嘛这道题目只要知道一个东西就很容易了:所有循环的最小公约数<=60,成一条链的长度最大为11,那么我们就可以用一个很裸的方法.对于在链上的数,我们修改直接暴力找出并修改.对于在环上的数,我们 ...
- 读书笔记 effective c++ Item 19 像设计类型(type)一样设计
1. 你需要重视类的设计 c++同其他面向对象编程语言一样,定义了一个新的类就相当于定义了一个新的类型(type),因此作为一个c++开发人员,大量时间会被花费在扩张你的类型系统上面.这意味着你不仅仅 ...
- 【前端】:jQuery上
前言: 今天写一篇jQuery,发现内容太多了,那就分成两篇写吧--写完jQuery基础知识后会再写一些jQuery实例~~ jQuery下载.jQuery是一个兼容多浏览器的javascript库, ...
- 三种预处理器px2rem
CSS单位rem 在W3C规范中是这样描述rem的: font size of the root element. 移动端越来越多人使用rem,推荐淘宝开源框架lib-flexible 今天来介绍一下 ...
- 前端学PHP之日期与时间
前面的话 在Web程序开发时,时间发挥着重要的作用,不仅在数据存储和显示时需要日期和时间的参与,好多功能模块的开发,时间通常都是至关重要的.网页静态化需要判断缓存时间.页面访问消耗的时间需要计算.根据 ...
- 0CSS样式表与HTML结合的方法
从此王子和公主幸福的生活在了一起:) 层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文 ...
- css修炼宝典
前端岗位目前确实十分火热,但是就业压力也很大:前一段时间与大学同学交谈,他向我哭诉说去一个机构学习了前端工程师,我心底里为他高兴,因为他马上就可以月薪突破10K了,可是不幸的是他说去北京面试一个月,还 ...
- js设置当前页面始终为框架最顶层
使用iframe做的页面,当session失效时,登录页面会显示在iframe里面 解决办法判断登录页面是否为顶层页面,不是的话刷新顶层页面
- Struts2框架(8)---Struts2的输入校验
Struts2的输入校验 在我们项目实际开发中在数据校验时,分为两种,一种是前端校验,一种是服务器校验: 客户端校验:主要是通过jsp写js脚本,它的优点很明显,就是输入错误的话提醒比较及时,能够减轻 ...