sql优化原则与技巧
加快sql查询是非常重要的技巧,简单来说加快sql查询的方式有以下几种:
一、索引的引用
1、索引一般可以加速数据的检索速度,加速表与表之间的链接,提高性能,所以在对海量数据进行处理时,考虑到信息量比较大,应该对表建立索引,包括在主键上建立聚簇索引,将聚合索引建立在日期刊上等。索引的优点有很多,但是对于索引的建立,还需要考虑实际情况,而不是对每一个列建立一个索引,比如针对大表的分组、排序等字段,都要建立相应索引,同时还应该考虑建立符合索引。增加索引的同时也有很多不好的方面,首先,创建索引和维护索引都耗费时间,且随着数据量的增加而增加;其次,索引占据物理空间,聚簇索引的空间更大。最后,当对表进行增加、删除和修改的时候,索引也要动态的维护。所以索引的引用有以下几个原则:
(1)当插入数据为表中数据的百分之10以上时,首先需要删除该表的索引来提高数据的插入效率,然后再重新建立索引;
(2)避免在索引列上使用函数或计算,在where字句中,如果索引是函数的一部分,优化器将不再使用索引,将使用全表扫描;例如:
select * from table where hh*10>1000;//低效
select * from table where hh>1000/10;//更高效
(3)尽量避免在索引列上使用not,!=和<>,索引只能告诉什么在表中,而不能告诉什么不在表中,当数据库遇上以上几种符号时,将不再使用索引,使用全表扫描
(4)检索中不要对索引进行处理,如TRIM,TO_DATE,类型转换等,这会破坏索引
(5)避免在索引列上使用IS NULL 或 IS NOT NULL。避免在索引列上使用任何可以为空的列,这样将无法使用此索引。因为空值不存在于索引列中,所以当where字句中对索引进行空值比较,将无法使用该索引。
(6)在索引列上,使用>=代替>,比如:
select * from table where hh>10;//低效
select * from table where hh>=10.0000001//相对高效
二、SQL语句的优化
介绍几种SQL语句的优化技巧:
(1)where字句中的链接顺序
oracle采用自下而上的顺序解析where字句,所以表之间的链接必须写在其他where条件之前,那些可以滤过大量纪录的条件必须写在where字句的末尾,例如:
select * from table e
where h>500
and d=''
and 25<(select count(*)
from table
where count=e.count); //低效 select * from table e
where 25<(select count(*)
from table
where count=e.count);
and h>500
and d='';//更高效
(2)删除全表时,用truncate而不用delete。因为truncate是ddl不是dml(truncate只能在删除全表时使用),例如:
Truncate table account;
比
delete from account;
快1000倍
(3)尽量多使用commit,只要有可能就对程序中每个delete,insert,update使用commit,这样系统会因为commit所释放的资源而大大提高效率。
(4)用exists代替in,可以提高查询的效率。例如:
SELECT * FROM ACCOUNT
WHERE AC_CODE
NOT IN (
SELECT CODE
FROM GOODS
WHERE NUM='') //低效 SELECT * FROM ACCOUNT
WHERE NOT EXISTS
(SELECT CODE
FROM GOODS
WHERE CODE=ACCOUNT.AC_CODE
AND NUM='') //更高效
(5)使用group by
可以将不需要的语句在group by之前过滤掉


(6)避免使用HAVING字句
HAVING字句只有在检索出所有记录之后,才会对结果集进行过滤,这样涉及到排序,统计等操作,如果能通过WHERE字句限制记录的数目,就可以减少开销。用Where子句替换HAVING子句,如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销. (非oracle中)on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把不 符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where也应该比having快点的,因为它过滤数据后 才进行sum,在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字 段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作 用的,所以在这种情况下,两者的结果会不同。在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表 后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里 。
(7)有条件的使用union-all代替union提高效率
(8)在所有查询的SQL语句中要特别注意减少对表的查询,如:

(9)select字句中避免使用*
当想在select字句中列出所有的列时,使用*是一个很方便,但是很低效的方法,因为在oracle中,会通过查询数据字典,将*依次转换为所有的列名,很耗时
(10)Order by语句
ORDER BY语句决定了Oracle如何将返回的查询结果排序。Order by语句对要排序的列没有什么特别的限制,也可以将函数加入列中(象联接或者附加等)。任何在Order by语句的非索引项或者有计算表达式都将降低查询速度。仔细检查order by语句以找出非索引项或者表达式,它们会降低性能。解决这个问题的办法就是重写order by语句以使用索引,也可以为所使用的列建立另外一个索引,同时应绝对避免在order by子句中使用表达式。
(11)带通配符(%)的like语句
目前的需求是这样的,要求在职工表中查询名字中包含cliton的人。可以采用如下的查询SQL语句:
select * from employee where last_name like '%cliton%';
这里由于通配符(%)在搜寻词首出现,所以Oracle系统不使用last_name的索引。在很多情况下可能无法避免这种情况,但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。在下面的查询中索引得到了使用:
select * from employee where last_name like 'c%';
(12)选择最有效率的表名顺序(只在基于规则的优化器中有效):
ORACLE 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表。
(13) 整合简单,无关联的数据库访问:
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
(14)删除重复记录:
最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
(15)使用表的别名(Alias):
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
(16)sql语句用大写的;因为oracle总是先解析sql语句,把小写的字母转换成大写的再执行
(17) 在java代码中尽量少用连接符“+”连接字符串!
(18) 总是使用索引的第一个列:
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 这也是一条简单而重要的规则,当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
三、函数的使用技巧
虽然有时肆意的使用函数,会将性能降低,但是用好函数有时也能提高性能和可读性。如:
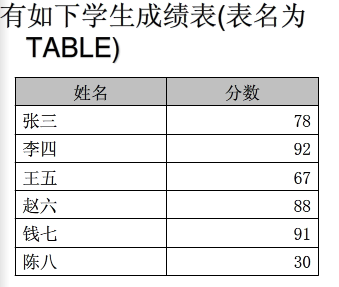



其他的一些方法可以参考http://www.cnblogs.com/ziyiFly/archive/2008/12/24/1361380.html
sql优化原则与技巧的更多相关文章
- 我的mysql数据库sql优化原则
原文 我的mysql数据库sql优化原则 一.前提 这里的原则 只是针对mysql数据库,其他的数据库 某些是殊途同归,某些还是存在差异.我总结的也是mysql普遍的规则,对于某些特殊情况得特殊对待. ...
- (转)SQL 优化原则
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用 系统提交实际应用后,随着数据库中数据的增加,系 ...
- Oracle SQL 优化原则(实用篇)
由于SQL优化优化起来比较复杂,并且还受环境限制,在开发过程中,写SQL必须遵循以下几点原则: 1.Oracle 采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他Where ...
- SQL 优化原则
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用 系统提交实际应用后,随着数据库中数据的增加,系 ...
- SQL优化原则(转)
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...
- Oracle SQL优化原则
原文:http://bbs.landingbj.com/t-0-240353-1.html 1.选用适合的 ORACLE 优化器 2.访问 Table 的方式 3.共享SQL语句 共享的语句必须满足三 ...
- 复杂sql优化步骤与技巧
数据管理型系统,由于用户的要求或者系统设计要求,会出现大量表进行join,还要进行大量统计性数据查询展示,甚至数据权限控制等操作.最后会导致sql异常复杂,随着数据量增加,或者只是应用到生产环境(正式 ...
- 一些sql优化原则
1.我们在设计表的时候,尽量让字段拥有默认值,尽量不要让字段的值为null. 因为,在 where 子句中对字段进行 null 值判断(is null或is not null)将导致引擎放弃使用索引而 ...
- sql优化原则
尽量使用性能高的比如left join等,尽量减少数据查询的column,尽量不要查询冗余数据,like的话“%%”是没有 办法使用索引的,但是“%”是可以使用索引的 having以前一直不知道到底真 ...
随机推荐
- Gitlab一键端的安装汉化及问题解决(2017/12/14目前版本为10.2.4)
Gitlab的安装汉化及问题解决 一.前言 Gitlab需要安装的包太TM多了,源码安装能愁死个人,一直出错,后来发现几行命令就装的真是遇到的新大陆一样... ... 装完之后感觉太简单,加了汉化补丁 ...
- 过渡与动画 - steps调速函数&CSS值与单位之ch
写在前面 上一篇中我们熟悉五种内置的缓动曲线和(三次)贝塞尔曲线,并且基于此完成了缓动效果. 但是如果我们想要实现逐帧动画,基于贝塞尔曲线的调速函数就显得有些无能为力了,因为我们并不需要帧与帧之间的过 ...
- 小白的Python之路 day1 变量
Python之路,Day1 - Python基础1 变量 变量用于存储在计算机程序中引用和操作的信息.它们还提供了一种用描述性名称标记数据的方法,这样我们的程序就能更清晰地被读者和我们自己理解.将变量 ...
- springBoot数据库连接池常用配置
在配置文件中添加配置如下(我使用的是多数据源): spring.datasource.primary.url=jdbc\:mysql\://localhost\:3306/test?useUnicod ...
- springboot(一)
1,使用springboot开发需要以下配置: : Maven | Gradle | Ant | Starters code工具:IDE | Packaged | Maven | Gradle 系统要 ...
- es6+require混合开发,兼容es6 module,import,export
近一年,一直很忙,做了不少的项目,不过都不是太满意,毕竟是别人的作品,不好意思写出来.最近打算开发一个es6的项目,项目中用到require,本文主要讲解es6的module规范怎么与require的 ...
- ML—高斯判别分析
华电北风吹 天津大学认知计算与应用重点实验室 日期:2015/12/11 高斯判别分析属于生成模型,模型终于学习一个特征-类别的联合概率. 0 多维正态分布 确定一个多维正态分布仅仅须要知道分布的均值 ...
- Vue深度学习(5)-过渡效果
简介 通过 Vue.js 的过渡系统,你可以轻松的为 DOM 节点被插入/移除的过程添加过渡动画效果.Vue 将会在适当的时机添加/移除 CSS 类名来触发 CSS3 过渡/动画效果,你也可以提供相应 ...
- 在Docker中运行asp.net core 跨平台应用程序
概述 Docker已经热了有一两年了,而且我相信这不是一个昙花一现的技术,而是一个将深远影响我们日后开发和部署.运营应用系统的一种创新(很多人将其作为devops的一种非常重要的基石).学习docke ...
- mybatis if-else(写法)
mybaits 中没有else要用chose when otherwise 代替 范例一 <!--批量插入用户--> <insert id="insertBusinessU ...