基于nodejs模拟浏览器post请求爬取json数据
今天想爬取某网站的后台传来的数据,中间遇到了很多阻碍,花了2个小时才请求到数据,所以我在此总结了一些经验。
首先,放上我所爬取的请求地址http://api.chuchujie.com/api/?v=1.0;
下面我们开始爬取数据。
一.写一个基于nodejs的爬虫
1.引入所需模块
这里需要引入http模块(nodejs用来向浏览器发送http请求的模块)和querystring模块(把前台传过来的对象形式的参数转化成字符串形式);
var http = require("http"); //http 请求
//var https = require("https"); //https 请求
var querystring = require("querystring");
2.配置http.router(options,fn)参数options
在配置中,重点在于模拟浏览器请求头,一般必须模拟Cookie,User-Agent(访问设备系统),Content-Type,有的需要模拟更多。在这里,我们的这个目标并没有Cookie,所以不用传。
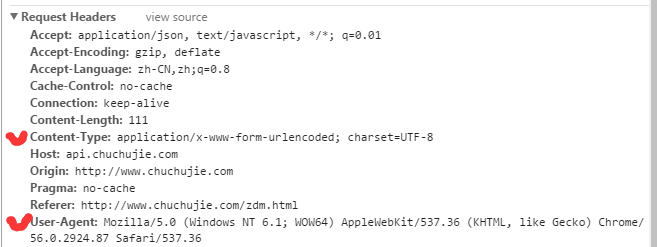
3.给目标后台发起http post请求得到数据
var req = http.request(options, function (res) {
var json = ""; //定义json变量来接收服务器传来的数据
console.log(res.statusCode);
//res.on方法监听数据返回这一过程,"data"参数表示数数据接收的过程中,数据是一点点返回回来的,这里的chunk代表着一条条数据
res.on("data", function (chunk) {
json += chunk; //json由一条条数据拼接而成
})
//"end"是监听数据返回结束,callback(json)利用回调传参的方式传给后台结果再返回给前台
res.on("end", function () {
callback(json);
})
})
req.on("error", function () {
console.log('error')
})
//这是前台参数的一个样式,这里的参数param由后台的路由模块传过来,而后台的路由模块参数是前台传来的
// var obj = {
// query: '{"function":"newest","module":"zdm"}',
// client: '{"gender":"0"}',
// page: 1
//}
req.write(querystring.stringify(param)); //post 请求传参
req.end(); //必须要要写,
4.模块化导出
完整的spider代码
/**
* Created by Administrator on 2017/2/12.
*/
var http = require("http"); //http 请求
//var https = require("https"); //https 请求
var querystring = require("querystring");
function request(path,param,callback) {
var options = {
hostname: 'api.chuchujie.com',
port: 80, //端口号 https默认端口 443, http默认的端口号是80
path: path,
method: 'POST',
headers: {
"Connection": "keep-alive",
"Content-Length": 111,
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
}//伪造请求头
}; var req = http.request(options, function (res) { var json = ""; //定义json变量来接收服务器传来的数据
console.log(res.statusCode);
//res.on方法监听数据返回这一过程,"data"参数表示数数据接收的过程中,数据是一点点返回回来的,这里的chunk代表着一条条数据
res.on("data", function (chunk) {
json += chunk; //json由一条条数据拼接而成
})
//"end"是监听数据返回结束,callback(json)利用回调传参的方式传给后台结果再返回给前台
res.on("end", function () {
callback(json);
})
}) req.on("error", function () {
console.log('error')
})
//这是前台参数的一个样式,这里的参数param由后台的路由模块传过来,而后台的路由模块参数是前台传来的
// var obj = {
// query: '{"function":"newest","module":"zdm"}',
// client: '{"gender":"0"}',
// page: 1
//}
req.write(querystring.stringify(param)); //post 请求传参
req.end(); //必须要要写, }
module.exports = request;
基于nodejs模拟浏览器post请求爬取json数据的更多相关文章
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- httpClient模拟浏览器发请求
一.介绍 httpClient是Apache公司的一个子项目, 用来提高高效的.最新的.功能丰富的支持http协议的客户端编程工具包.完成可以模拟浏览器发起请求行为. 二.简单使用例子 : 模拟浏览器 ...
- 使用HttpClient配置代理服务器模拟浏览器发送请求调用接口测试
在调用公司的某个接口时,直接通过浏览器配置代理服务器可以请求到如下数据: 请求url地址:http://wwwnei.xuebusi.com/rd-interface/getsales.jsp?cid ...
- 爬虫学习(四)——post请求爬取
百度翻译爬取数据 import urllib.requestimport urllib.parsepost_url = "https://fanyi.baidu.com/sug"h ...
- NodeJs本地搭建服务器,模拟接口请求,获取json数据
最近在学习Node.js,虽然就感觉学了点皮毛,感觉这个语言还不错,并且也会一步步慢慢的学着的,这里实现下NodeJs本地搭建服务器,模拟接口请求,获取json数据. 具体的使用我就不写了,这个博客写 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 一个月入门Python爬虫,轻松爬取大规模数据
Python爬虫为什么受欢迎 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得 ...
- 爬虫(十):AJAX、爬取AJAX数据
1. AJAX 1.1 什么是AJAX AJAX即“Asynchronous JavaScript And XML”(异步JavaScript和XML)可以使网页实现异步更新,就是不重新加载整个网页的 ...
随机推荐
- Brackets - 强大免费的开源跨平台Web前端开发工具IDE (HTML/CSS/Javascript代码编辑器)
Brackets 是一个免费.开源且跨平台的 HTML/CSS/JavaScript 前端 WEB 集成开发环境 (IDE工具).该项目由 Adobe 创建和维护,根据MIT许可证发布,支持 Wind ...
- 配置FMS发布/HDS/HLS流
一.前言 安装完FMS4.5以后就有了apache2.2,由于在FMS安装目录里面,他是对外面已经安装的是没有影响的,默认情况向, FMS监听80端口接收traffic然后传递给Apache的8134 ...
- 用反射技术替换工厂种的switch分支(14)
首先给大家拜个晚年,祝大家新春快乐,万事如意,鸡年大吉. 好了,前面我们讲了很多的工厂模式,其中,有个很明显的特点,工厂中,有一个方法,里面有很多的swich case 分支,我们前面说过,我们可以 ...
- 算法笔记_017:递归执行顺序的探讨(Java)
目录 1 问题描述 2 解决方案 2.1 问题化简 2.2 定位输出测试 2.3 回顾总结 1 问题描述 最近两天在思考如何使用蛮力法解决旅行商问题(此问题,说白了就是如何求解n个不同字母的所有不同排 ...
- [转载] HTTP协议详解
转自:http://blog.csdn.net/gueter/archive/2007/03/08/1524447.aspx Author :Jeffrey 引言 HTTP是一个属于应用层的面向对象的 ...
- 模拟java的split函数,分割字符串,类似于java的split方法
/*自定义oracle的分割函数*//*定义一个type,用户接收返回的数据集合类型*/create or replace type splitType as table of varchar2(40 ...
- webservice_模拟报文测试
一.WebService测试小工具STORM 二.利用MyEclipse的WebService视图调用webservice Ø 除了客户端生成代码编写程序调用之外.还可以用MyEclipse提供 ...
- 一篇文章搞定css3 3d效果
css3 3d学习心得 卡片反转 魔方 banner图 首先我们要学习好css3 3d一定要有一定的立体感 通过这个图片应该清楚的了解到了x轴 y轴 z轴是什么概念了. 首先先给大家看一个小例子: 卡 ...
- Mrc.EOF
Mrc 是我们定义的一个变量,用来存放数据等同于 ADODB.Recordset而eof 是mrc也就是recordset的一个属性. 通常我们在程序中编写代码来检验BOF与EOF属性,从而得知目前指 ...
- oracle 11G RAC会话故障转移测试
目前接手的几个项目中,默认使用的oracle RAC数据库服务,均不能实现自动的会话转移,尤其是对于应用的长连接,一旦发生数据库故障,需要重启应用.实际11G具备会话迁移机制,为此做了如下配置测试,供 ...