c++性能测试
程序分析是以某种语言书写的程序为对象,对其内部的运作流程进行分析。程序分析的目的主要有三点:一是通过程序内部各个模块之间的调用关系,整体上把握程序的运行流程,从而更好地理解程序,从中汲取有价值的内容。二是以系统优化为目的,通过对程序中关键函数的跟踪或者运行时信息的统计,找到系统性能的瓶颈,从而采取进一步行动对程序进行优化。最后一点,程序分析也有可能用于系统测试和程序调试中。当系统跟踪起来比较复杂,而某个BUG又比较难找时,可以通过一些特殊的数据构造一个测试用例,然后将分析到的函数调用关系和运行时实际的函数调用关系进行对比,从而找出错误代码的位置。
程序分析工具不同于调试器,它只产生程序运行时某些函数的调用次数、执行时间等等宏观信息,而不是每条语句执行时的详细信息。Gprof是Linux下一个强有力的程序分析工具。对于C、Pascal或者Fortran77语言的程序,它能够以“日志”的形式记录程序运行时的统计信息:程序运行中各个函数消耗的时间和函数调用关系,以及每个函数被调用的次数等等。从而可以帮助程序员找出众多函数中耗时最多的函数,也可以帮助程序员分析程序的运行流程。相信这些功能对于分析开源代码的程序员来说,有着相当大的诱惑力。
用gprof分析程序
用gprof对程序进行分析主要分以下三个步骤:
l 用编译器对程序进行编译,加上-pg参数。
l 运行编译后的程序。
l 用gprof命令查看程序的运行时信息。
先以一个简单的例子演示一下吧。随便找一个能够运行的程序的源代码,比如下面的文件test.c:

1
2 int IsEven(int x)
3
4 {
5
6 return 0 == x & 1;
7
8 }
9
10 int main(int argc, char *argv[]
11
12 {
13
14 int i = 0;
15
16 while(++i < 1000) IsEven(i);
17
18 }
首先,用以下命令进行编译:
[root@localhost]#gcc –o test –pg test.c
然后,运行可执行文件test.
[root@localhost]#./test
运行后,在当前目录下将生成一个文件gmon.out,这就是gprof生成的文件,保存有程序运行期间函数调用等信息。
最后,用gprof命令查看gmon.out保存的信息:
[root@localhost]#gprof test gmon.out –b
这样就有一大堆信息输出到屏幕上,有函数执行单间,函数调用关系图等等,如下:
Flat profile:
Each sample counts as 0.01 seconds.
no time accumulated
% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
0.00 0.00 0.00 1000 0.00 0.00 IsEven(int)
Call graph
granularity: each sample hit covers 2 byte(s) no time propagated
index % time self children called name
0.00 0.00 1000/1000 main [7]
[8] 0.0 0.00 0.00 1000 IsEven(int) [8]
-----------------------------------------------
Index by function name
[8] IsEven(int)
以上介绍了gprof最简单的使用方法,下面针对其使用过程中的三个步骤详细说明。
编译和链接
上面的例子中,程序比较简单,只有一个文件。如果源代码有多个文件,或者代码结构比较复杂,编译过程中先生成若干个目标文件,然后又由链接器将这些目标文件链接到一起,这时该怎么使用gprof呢?
对于由多个源文件组成的程序,编译时需要在生成每个.o文件的时候加上-pg参数,同时在链接的时候也要加上-pg参数。对于链接器不是GCC的情况,如ld,又有特殊的要求。
同时,-pg参数只能记录源代码中各个函数的调用关系,而不能记录库函数的调用情况。要想记录每个库函数的调用情况,链接的时候必须指定库函数的动态(或者静态)链接库libc_p.a,即加上-lc_p,而不是-lc。
还要说明的是,如果有一部分代码在编译时指定了-pg参数,而另一部分代码没有指定,则生成的gmon.out文件中将缺少一部分函数,也没有那些函数的调用关系。但是并不影响gprof对其它函数进行记录。
运行
编译好的程序运行时和运行一般的程序没有什么不同,只是比正常的程序多生成了一个文件gmon.out。注意,这个文件名是固定的,没法通过参数的设置进行改变。如果程序目录中已经有一个gmon.out,则它会被新的gmon.out覆盖掉。
关于生成的gmon.out文件所在的目录,也有以下约定:程序退出时所运行的文件所在目录就是生成的gmon.out文件所在的目录。如果一个程序执行过程中调用了另一个程序,并在另一个程序的运行中终止,则gmon.out会在另一个程序所在的目录中生成。
还有一点要注意的就是当程序非正常终止时不会生成gmon.out文件,也因此就没法查看程序运行时的信息。只有当程序从main函数中正常退出,或者通过系统调用exit()函数而退出时,才会生成gmon.out文件。而通过底层调用如_exit()等退出时不会生成gmon.out。
查看
查看程序运行信息的命令是gprof,它以gmon.out文件作为输入,也就是将gmon.out文件翻译成可读的形式展现给用户。其命令格式如下:
gprof [可执行文件] [gmon.out文件] [其它参数]
方括号中的内容可以省略。如果省略了“可执行文件”,gprof会在当前目录下搜索a.out文件作为可执行文件,而如果省略了gmon.out文件,gprof也会在当前目录下寻找gmon.out。其它参数可以控制gprof输出内容的格式等信息。最常用的参数如下:
l -b 不再输出统计图表中每个字段的详细描述。
l -p 只输出函数的调用图(Call graph的那部分信息)。
l -q 只输出函数的时间消耗列表。
l -e Name 不再输出函数Name 及其子函数的调用图(除非它们有未被限制的其它父函数)。可以给定多个 -e 标志。一个 -e 标志只能指定一个函数。
l -E Name 不再输出函数Name 及其子函数的调用图,此标志类似于 -e 标志,但它在总时间和百分比时间的计算中排除了由函数Name 及其子函数所用的时间。
l -f Name 输出函数Name 及其子函数的调用图。可以指定多个 -f 标志。一个 -f 标志只能指定一个函数。
l -F Name 输出函数Name 及其子函数的调用图,它类似于 -f 标志,但它在总时间和百分比时间计算中仅使用所打印的例程的时间。可以指定多个 -F 标志。一个 -F 标志只能指定一个函数。-F 标志覆盖 -E 标志。
l -z 显示使用次数为零的例程(按照调用计数和累积时间计算)。
不过,gprof不能显示对象之间的继承关系,这也是它的弱点.
linux环境下 C++性能测试工具 gprof + kprof + gprof2dot
1.gprof
很有名了,google下很多教程
g++ -pg -g -o test test.cc
./test //会生成gmon.out
gprof ./test > prof.log
看一下对于我前面提到的huffman编码压缩+解码解压缩全部过程的一个程序
对于生成的prof.log ,wow, 很有用处的但是看起来有点累,不是吗:)

 Code
Code
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
32.51 1.71 1.71 13127166 0.00 0.00 glzip::HuffTree<unsigned char, glzip::decode_hufftree>::decode_byte(unsigned char, glzip::Buffer&, glzip::HuffNode<unsigned char>*&, int)
18.73 2.69 0.98 105017328 0.00 0.00 glzip::Buffer::write_bit(int)
16.63 3.57 0.88 24292128 0.00 0.00 glzip::Buffer::write_string(std::string const&)
7.22 3.95 0.38 61711820 0.00 0.00 glzip::Buffer::read_byte(unsigned char&)
5.80 4.25 0.30 37419691 0.00 0.00 glzip::Buffer::write_byte(unsigned char)
5.51 4.54 0.29 1 0.29 2.48 glzip::Encoder<unsigned char>::do_encode_file(glzip::char_tag)
5.13 4.82 0.27 105017721 0.00 0.00 glzip::HuffNode<unsigned char>::is_leaf()
3.04 4.97 0.16 1 0.16 0.31 glzip::Encoder<unsigned char>::do_caculate_frequency(glzip::char_tag)
2.47 5.11 0.13 1 0.13 2.42 glzip::HuffTree<unsigned char, glzip::decode_hufftree>::decode_file()
1.14 5.17 0.06 24292227 0.00 0.00 std::vector<std::string, std::allocator<std::string> >::operator[](unsigned int)
0.95 5.21 0.05 1 0.05 0.05 glzip::HuffTree<unsigned char, glzip::encode_hufftree>::do_serialize_tree(glzip::HuffNode<unsigned char>*, glzip::Buffer&)
0.29 5.23 0.01 24292133 0.00 0.00 glzip::HuffTreeBase<unsigned char>::root() const
0.29 5.25 0.01 574 0.00 0.00 glzip::Buffer::flush_buf()
0.19 5.25 0.01 6 0.00 0.00 glzip::Buffer::~Buffer()
0.10 5.26 0.01 unsigned int const& std::min<unsigned int>(unsigned int const&, unsigned int const&)
0.00 5.26 0.00 12901 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::_Deque_iterator(std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**> const&)
0.00 5.26 0.00 6065 0.00 0.00 std::__deque_buf_size(unsigned int)
0.00 5.26 0.00 6056 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::_S_buffer_size()
0.00 5.26 0.00 5656 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::operator*() const
0.00 5.26 0.00 5656 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::operator+=(int)
0.00 5.26 0.00 4871 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::operator+(int) const
0.00 5.26 0.00 3126 0.00 0.00 glzip::HuffNode<unsigned char>::weight() const
0.00 5.26 0.00 1465 0.00 0.00 glzip::HuffTree<unsigned char, glzip::encode_hufftree>::HuffNodePtrGreater::operator()(glzip::HuffNode<unsigned char> const*, glzip::HuffNode<unsigned char> const*)
0.00 5.26 0.00 946 0.00 0.00 glzip::Buffer::fill_buf()
0.00 5.26 0.00 785 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::operator-(int) const
0.00 5.26 0.00 785 0.00 0.00 std::_Deque_iterator<glzip::HuffNode<unsigned char>*, glzip::HuffNode<unsigned char>*&, glzip::HuffNode<unsigned char>**>::operator-=(int)
0.00 5.26 0.00 590 0.00 0.00 glzip::HuffNode<unsigned char>::left() const
0.00 5.26 0.00 590 0.00 0.00 glzip::HuffNode<unsigned char>::right() const
0.00 5.26 0.00 453 0.00 0.00 operator new(unsigned int, void*)  .
.
2.Kprof
sudo apt-get install kprof
kprof -f ./test //注意已经按照前面的用gprof生成 gmont.out 了。
将gprof , GUI化了,更加友好,还是很方便的,它也利用而来graphviz绘制了运行时流程图,但是对于大的程序,
似乎效果不太好,流程图感觉完全乱掉了,而且对于大程序,kprof运行的有点慢,在我的破机器上跑半天才出来。
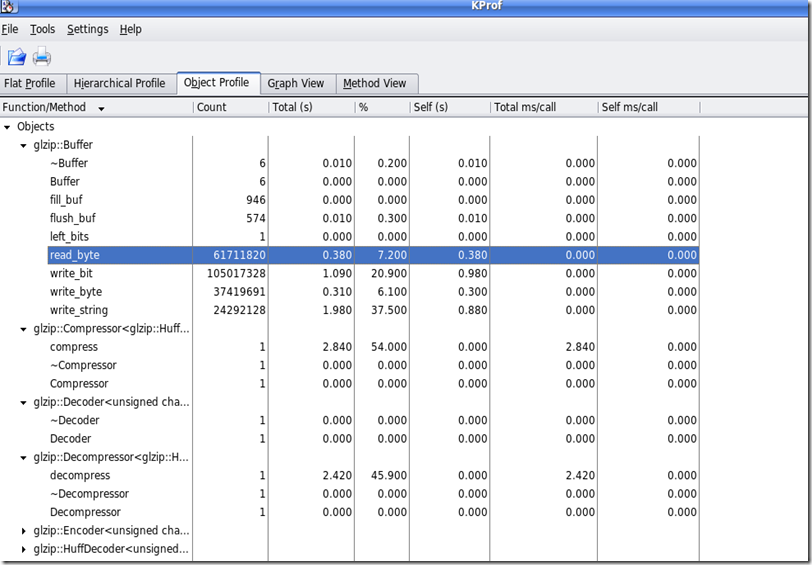
总的来说它的object profile还是很方便有用的。
object profile 示意图
graph view 示意图,这个仅作参考吧,同样是用graphviz怎么和gprof2dot差距这么大呢?:)对比下下面gprof2dot的生成图吧!
3.gprof2dot.py
这个脚本太TMD的牛X了,速度快效果好,怪不得底下评论一片叫好,这就是life_saving的工具啊!
首先就是运行时的程序流程图,网上有很多工具有些就是利用gprof的,有很多文章介绍,都不用看了,就用这个吧。
然后很直观的看出每个步骤的占用时间百分比,函数调用次数,颜色能直观的表示出瓶颈所在。
gprof2dot安装看这里吧
http://www.51testing.com/?uid-13997-action-viewspace-itemid-79952
gprof ./test | gprof2dot.py | xdot
恩 去下载那个xdot.py吧 看dot文件,太方便了,不需要先生成图像了。
直接看效果图吧!
1.整体图
清晰多了吧,上面那么多冗余的东西。

2.局部图
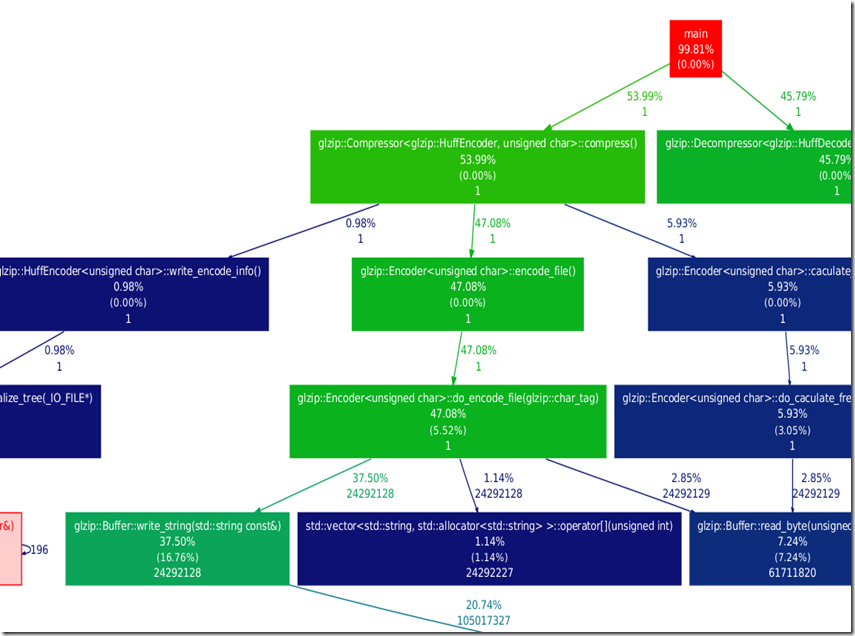
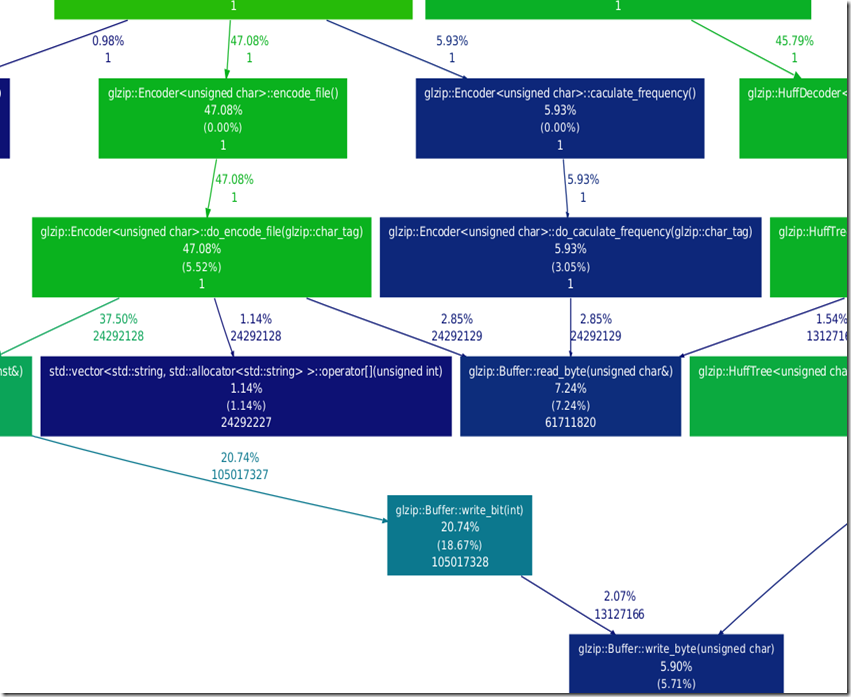
和我的程序执行过程完全对应,清晰明了,太赞了!
每个方框内部显示函数名称,函数整体包括内部子函数占用时间%比,函数自身,不包括内部子函数占用时间%比,函数执行次数。
边表示父函数调用该子函数占用的时间%比,调用次数。
之所以清晰是因为,gprof2dot默认是部分函数调用图,对性能影响不大的函数调用都不显示,例如上图中没有出现类的构造,析构函数,
如果想要显示全部的函数调用,可以 gprof2dot -n0 -e0 ,默认是n0.5即影响小于5%的函数就不显示了。
当然这样图片会很乱,因为显示内容很多,可以 gprof2dot -n0 -e0 -s #-s表示不显示诸如模板,函数入口参数等等,使得
函数名称显示更加精简。
恩,如果用户能决定只输出某个函数及其关联函数的显示信息图就更好了,例如上面有两个
独立的过程compress()和decompress()如果用户能够决定只是显示compress()就好了,
不过考虑到模板之类的稍微有点麻烦,但是应该也是能实现的!
4. google 还有一个开源的能测试工具
以后尝试一下
http://code.google.com/p/google-perftools/wiki/GooglePerformanceTools
http://blog.csdn.NET/stanjiang2010/article/details/5655143
c++性能测试的更多相关文章
- Ignite性能测试以及对redis的对比
测试方法 为了对Ignite做一个基本了解,做了一个性能测试,测试方法也比较简单主要是针对client模式,因为这种方法和使用redis的方式特别像.测试方法很简单主要是下面几点: 不作参数优化,默认 ...
- 性能测试工具 wrk 安装与使用
介绍 今天给大家介绍一款开源的性能测试工具 wrk,简单易用,没有Load Runner那么复杂,他和 apache benchmark(ab)同属于性能测试工具,但是比 ab 功能更加强大,并且可以 ...
- .NET Core性能测试组件BenchmarkDotNet 支持.NET Framework Mono
.NET Core 超强性能测试组件BenchmarkDotNet 支持Full .NET Framework, .NET Core (RTM), Mono. BenchmarkDotNet支持 C# ...
- C#中实现并发的几种方法的性能测试
C#中实现并发的几种方法的性能测试 0x00 起因 去年写的一个程序因为需要在局域网发送消息支持一些命令和简单数据的传输,所以写了一个C/S的通信模块.当时的做法很简单,服务端等待链接,有用户接入后开 ...
- 「视频直播技术详解」系列之七:直播云 SDK 性能测试模型
关于直播的技术文章不少,成体系的不多.我们将用七篇文章,更系统化地介绍当下大热的视频直播各环节的关键技术,帮助视频直播创业者们更全面.深入地了解视频直播技术,更好地技术选型. 本系列文章大纲如下: ...
- PostgreSql性能测试
# PostgreSql性能测试 ## 1. 环境+ 版本:9.4.9+ 系统:OS X 10.11.5+ CPU:Core i5 2.7G+ 内存:16G+ 硬盘:256G SSD ## 2. 测试 ...
- Web系统性能测试术语简介
并发用户 并发一般分为两种情况.一种是严格意义上的并发,即所有的用户在同一时刻做同一件事情或者操作.这种操作一般指做同一类型的业务,比如在信用卡审批业务中,一定数目的用户在同一时刻对已经完成的审批业务 ...
- Web前端性能测试-性能测试知多少---深入分析前端站点的性能
针对目前接手的web前端的性能,一时间不知道从什么地方入手,然后经过查找资料,发现其实还是蛮简单的. 前端性能测试对象: HTML.CSS.JS.AJAX等前端技术开发的Web页面 影响用户浏览网页速 ...
- 基于webdriver的jmeter性能测试-通过jmeter实现jar录制脚本的性能测试
续接--基于webdriver的jmeter性能测试-Eclipse+Selenium+JUnit生成jar包 在进行测试前先将用于支持selenium录制脚本运行所需的类包jar文件放到jmeter ...
- Probe在性能测试中的使用方式简介
简介: Lambda Probe(以前称为Tomcat Probe)是一款实时监控和管理的Apache Tomcat实例的基本工具. Lambda Probe 是基于 Web + AJAX 的强大的免 ...
随机推荐
- Winserver2008R2 .netframework4.5 asp.netmvc 访问出现的是文件列表。
Winserver2008R2 .netframework4.5 asp.netmvc 访问出现的是文件列表,服务器需要安装如下的补丁,才可正常访问. http://www.microsoft.com ...
- Linux使用常见错误集锦
1. scp拷贝文件失败问题 当在 shell startup script (比如 profile , bashrc)自动执行过程中产生了任何内容输出时, scp / sftp会把这些 echo 回 ...
- Collection集合之六大接口(Collection、Set、List、Map、Iterator和Comparable)
首先,我们先看一下Collection集合的基本结构: 1.Collection接口 Collection是最基本集合接口,它定义了一组允许重复的对象.Collection接口派生了两个子接口Set和 ...
- phonegap android3.5.1 Crosswalk
1. your phonegap platform for android update 3.5.1 cordova platform add android@3.5 2. download cros ...
- PAT1075. PAT Judge
//终于A了,不难却觉着坑多的的题,注意-1的处理,感觉我是受memset置0的束缚了,可以把初试成绩置-1.就不用debug怎么久,注意对于-1的处理,不然漏洞百出 #include<cstd ...
- PAT1076. Forwards on Weibo(标准bfs模板)
//标准的层次遍历模板 //居然因为一个j写成了i,debug半天.....解题前一定要把结构和逻辑想清楚,不能着急动手,理解清楚题意,把处理流程理清楚再动手,恍恍惚惚的写出来自己慢慢debug吧 # ...
- svn 检出代码报ssl错误问题的解决
svn: OPTIONS of 'https://192.168.11.185/svn/ahwater-cloud': SSL handshake failed: SSL error: Key usa ...
- IEF could not decode Chinese character in IE history well
My friend is working on some case, and she looks not in the mood. I ask her what's going on. She wan ...
- 码农谷 球从M米高度自由下落第N次落地时反弹的高度
题目描述 一球从M米高度自由下落,每次落地后返回原高度的一半,再落下.它在第N次落地时反弹多高?共经过多少米? 保留两位小数. 输入描述 M N 输出描述 它在第N次落地时反弹多高?共经过多少米? 保 ...
- -webkit-filter属性用来干什么
这两天有看到国外网站纷纷介绍-webkit-filter,开始很迷惑,丫是想要学IE吗?今天看了下,和IE的滤镜没一毛关系啊,而且,效果很赞! 这些滤镜效果最初是用于SVG的,W3C引入到CSS中,然 ...