logstash数据处理及格式化功能详解
Grok正则提取日志
环境延续我上一篇ELK单机版的filebeat-->redis-->logstash-->elasticsearch-->kibana环境,详情请参考:
Elasticsearch + Logstash + Kibana +Redis +Filebeat 单机版日志收集环境搭建
正则表达式
普通正则表达式
. 任意一个字符
* 前面一个字符出现0次或者多次
[abc] 中括号内任意一个字符
[^abc] 非中括号内的字符
[0-9] 表示一个数字
[a-z] 小写字母
[A-Z] 大写字母
[a-zA-Z] 所有字母
[a-zA-Z0-9] 所有字母+数字
[^0-9] 非数字
^xx 以xx开头
xx$ 以xx结尾
\d 任何一个数字
\s 任何一个空白字符
扩展正则表达式,在普通正则符号再进行了扩展
? 前面字符出现0或者1次
+ 前面字符出现1或者多次
{n} 前面字符匹配n次
{a,b} 前面字符匹配a到b次
{,b} 前面字符匹配0次到b次
{a,} 前面字符匹配a或a+次
(string1|string2) string1或string2
在Kibana的grokdebugger上进行测试
在编写grok提取正则配置前可以在Kibana的grokdebugger上进行测试:
比如我想提取一个如下的Nginx日志:
192.168.237.1 - - [24/Feb/2019:17:48:47 +0800] "GET /shijiange HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
那么可以按照正则表达式和grok语法在grokdebugger进行如下测试:
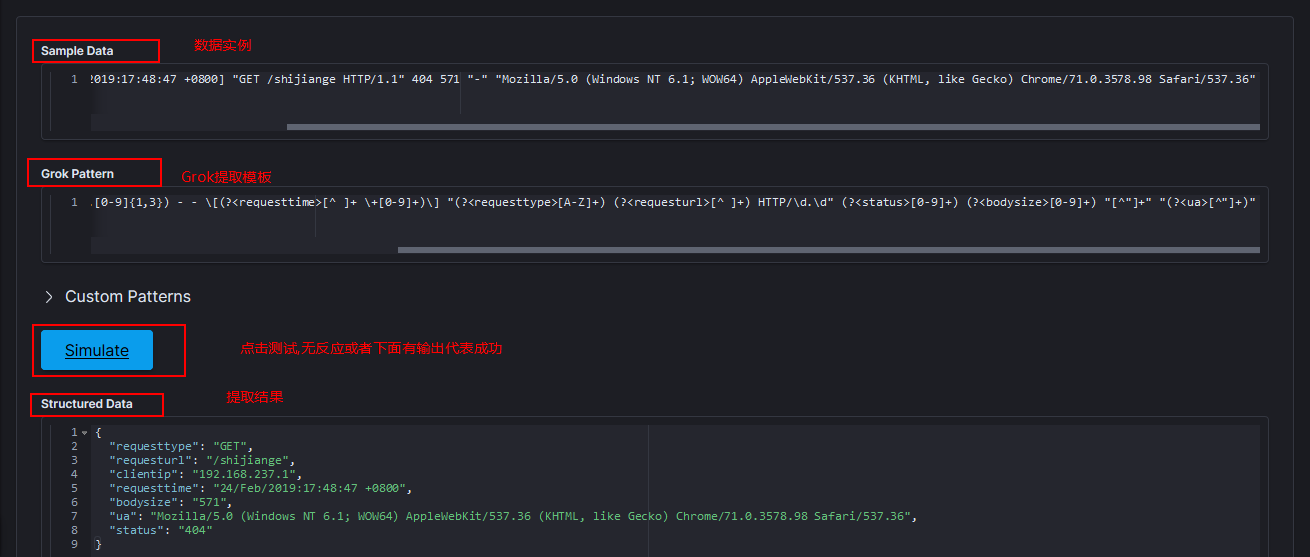
可以看到我的Grok成功提取了我想要的内容,我的Grok匹配规则如下:
(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"
(?<字段名>正则)表示将匹配的内容提取为字段,其他不用提取为字段的地方原样写上或者用正则匹配即可。
在配置文件中引入Grok提取规则
vim ./logstash_grok.conf
# logstash_grok.conf内容
input {
redis {
host => '192.168.1.4'
port => 6379
key => "queue"
data_type => "list"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
}
}
启动logstah:
/opt/es/logstash-7.2.0/bin/logstash -f ./logstash_grok.conf
测试是否成功:
echo '192.168.237.1 - - [24/Feb/2019:17:48:47 +0800] "GET /shijiange HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"' >> example.log
在Kinaba中配置index,方便查看:
点击Management-->Kibana-->Index patterns会出现如下提示:
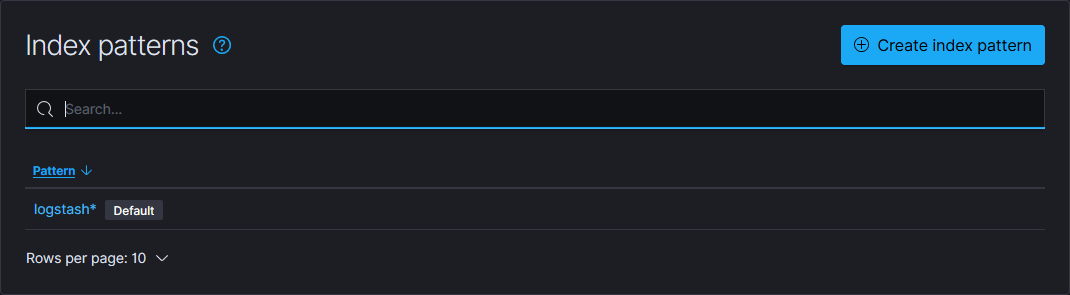
点击Create Index Pattern按照如下步骤创建新的Kibana索引:

输入索引匹配规则,如logstash*会匹配所有logstash开头的ES索引数据,然后点击下一步选择时间字段用于按时间戳筛选数据:
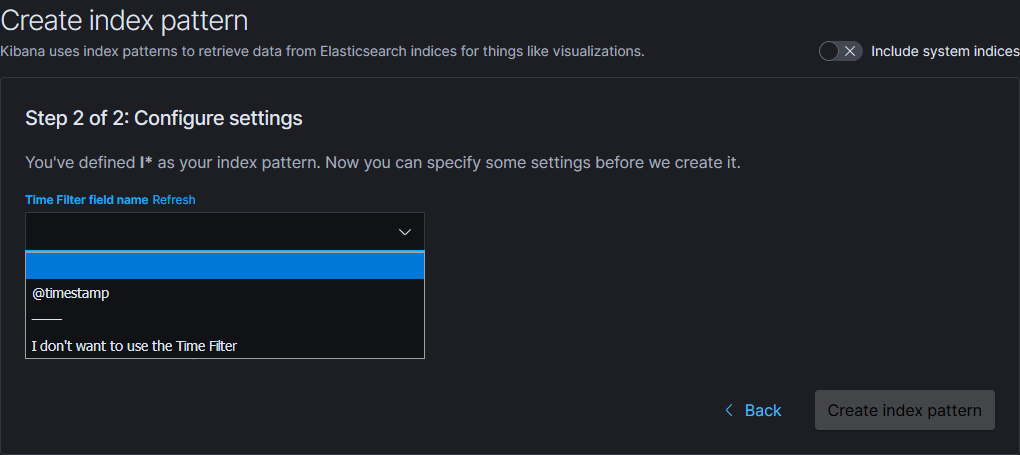
选择@timestamp将会根据@timestamp字段的时间过滤数据,点击Create index pattern即可在Discover页面选择你创建的Kibana索引来查看数据:
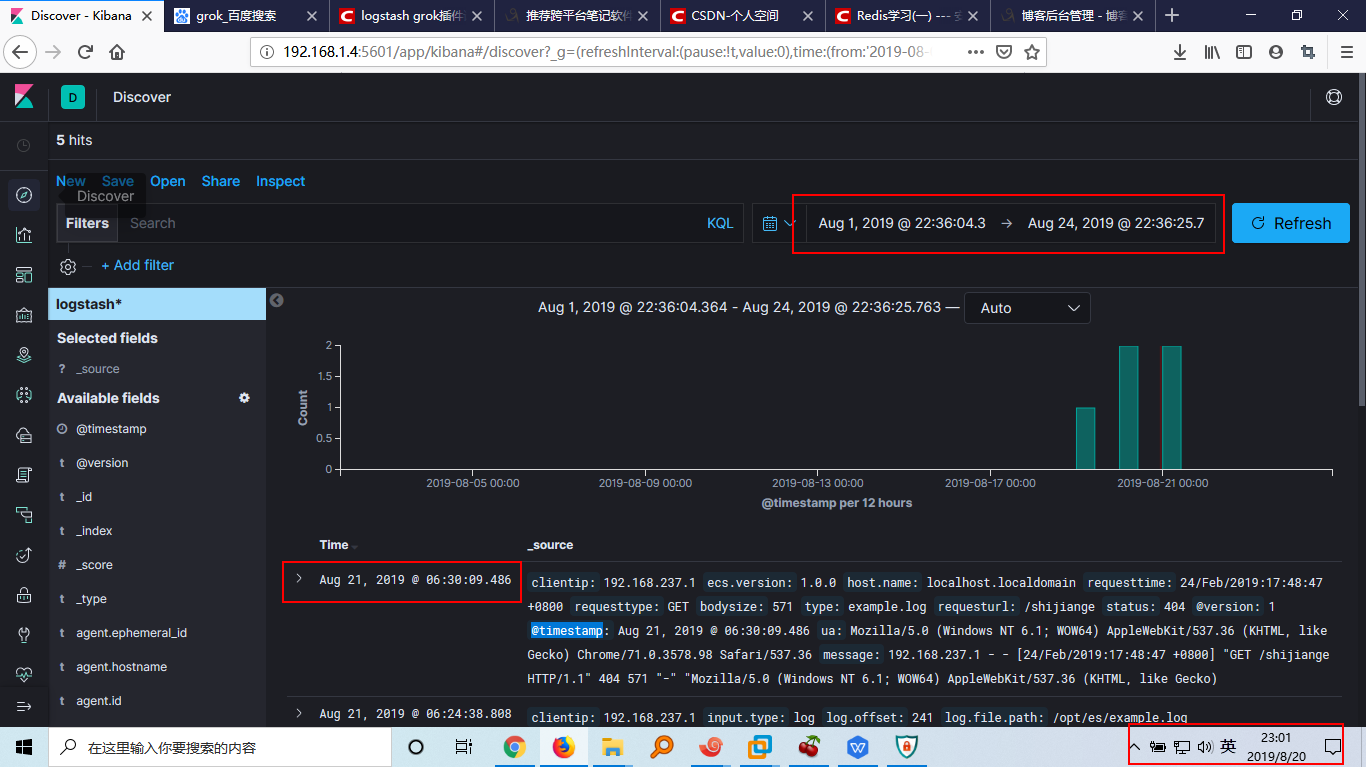
可以看到我配置的Kibana起作用了。这里要注意的是Kibana采用的是UTC时间,比东八区时间要快8个小时,所以在筛选时间范围的时候我将范围往后扩大了一点,否则可能看不到数据。
展开最上方的记录可以看到我刚才插入的数据被成功提取了:
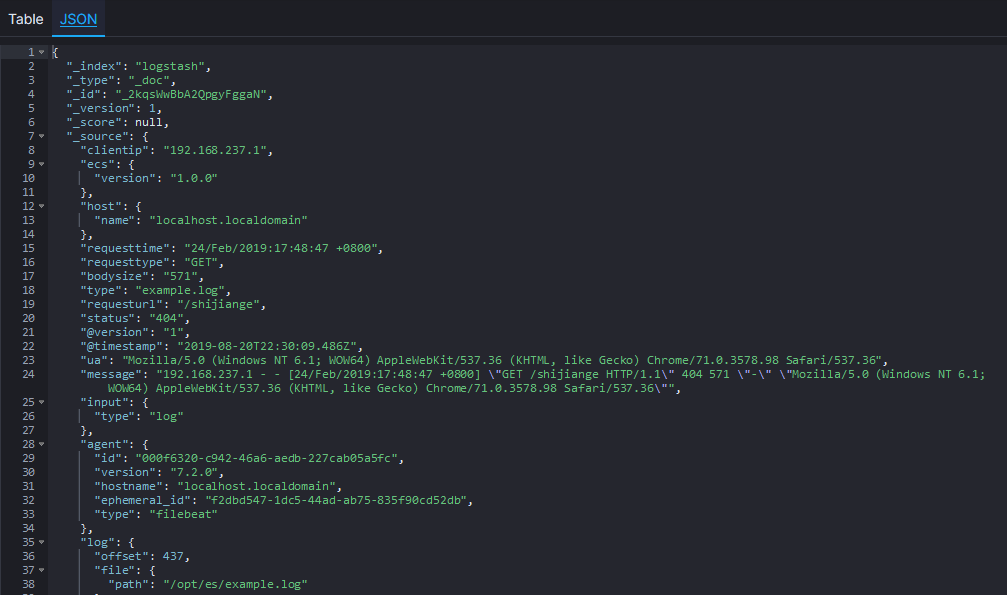
去除字段
通过上面的图可以看到Grok配置的确起作用了,但是Logstash给我们添加了很多字段,有时候这些字段是不必要的,这时候就要可以使用remove_field配置来去除一些字段。
修改配置文件如下:
# logstash_grok.conf内容
input {
redis {
host => '192.168.1.4'
port => 6379
key => "queue"
data_type => "list"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
}
}
重启重复上述测试,数秒后查看Kibana:
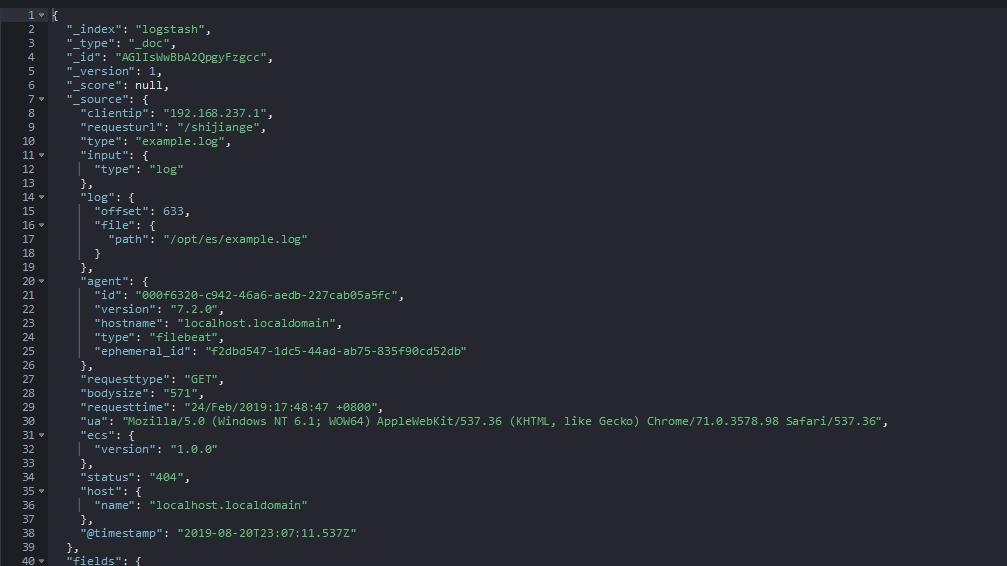
Logstash确实为我们去除了我们不需要的字段。
使用日志时间而非插入时间
由于日志输出和消息队列同步以及ELK中的数据传输都是需要时间的,使用ES自动生成的时间戳可能和日志产生的时间并不一致,而且由于时区问题会产生更大的影响,所以需要自定义时间字段,而非使用自动生成的时间字段。
更改配置文件如下:
# logstash_grok.conf内容
input {
redis {
host => '192.168.1.4'
port => 6379
key => "queue"
data_type => "list"
}
}
filter {
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<requesttime>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
} output {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
}
}
重复上述测试,扩大时间范围只2018年某月可以看到有一条2019年2月的数据:

提取json格式的数据
Grok对于提取非结构化的数据是很方便的,但是对于json格式的数据如果还用Grok来提取未免也太麻烦了点,毕竟采用json这种半结构化数据来输出日志本来就是为了方便处理。还好Logstash早就考虑到了这点,并提供了json格式数据的提取规则。
修改配置文件以提取json数据:
# logstash_json.conf
input {
redis {
host => '192.168.1.4'
port => 6379
key => "queue"
data_type => "list"
}
}
filter {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
}
}
测试是否配置成功:
以logstash_json.conf启动Logstash:
/opt/es/logstash-7.2.0/bin/logstash -f ./logstash_json.conf
向example.log追加一条json数据:
echo '{"@timestamp":"24/Feb/2019:21:08:34 +0800","clientip":"192.168.1.5","status":0,"bodysize":"1m","referer":"http_referer","ua":"http_user_agent","handletime":"request_time","url":"uri"}' >> example.log
数秒后在kibana查看数据:

可以看到我们的配置是生效的。
filebeat监视多个日志
修改filebeat配置文件:
vim ./filebeat-7.2.0-linux-x86_64/filebeat.yml
# filebeat.yml内容
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /opt/es/example.log
fields:
type: example
fields_under_root: true
- type: log
tail_files: true
backoff: "1s"
paths:
- /opt/es/example2.log
fields:
type: example2
fields_under_root: true
output:
redis:
hosts: ["192.168.1.4:6379"]
key: 'queue'
修改logstash配置文件:
vim ./logstash-7.2.0/config/logstash_muti.conf
# logstash_muti.conf内容
input {
redis {
host => '192.168.1.4'
port => 6379
key => "queue"
data_type => "list"
}
}
filter {
if [type] == "example" {
json {
source => "message"
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}else if [type] == "example2"{
grok {
match => {
"message" => '(?<clientip>[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) - - \[(?<timestamp>[^ ]+ \+[0-9]+)\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\d.\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"'
}
remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
}
}
以新的配置启动filebeat和logstash:
# 以logstash_muti.conf启动logstash
/opt/es/logstash-7.2.0/bin/logstash -f ./logstash_muti.conf
# 以filebeat.yml启动filebeat
./filebeat-7.2.0-linux-x86_64/filebeat -e -c ./filebeat-7.2.0-linux-x86_64/filebeat.yml
新建一个example2.log文件,路径要和filebeat配置的路径一致,然后在终端执行以下命令进行测试:
# 测试example.log收集情况
echo '{"timestamp":"11/Apr/2019:21:08:34 +0800","clientip":"192.168.1.5","status":0,"bodysize":"1m","referer":"http_referer","ua":"http_user_agent","handletime":"request_time","url":"uri"}' >> example.log
# 测试example2.log收集情况
echo '192.168.237.1 - - [24/Apr/2019:17:48:47 +0800] "GET /shijiange HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"' >>example2.log
数秒后查看kibana数据:
example.log输入产生的数据:
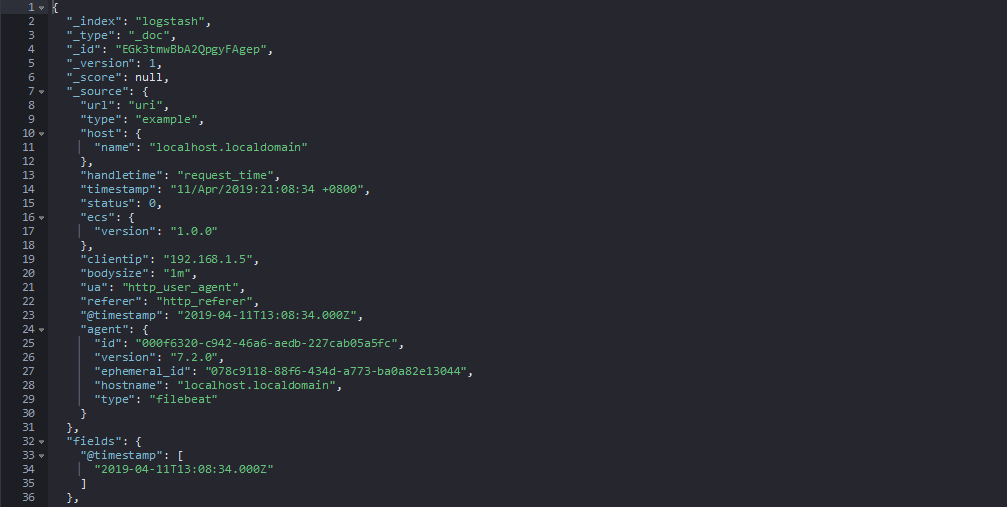
example2.log测试产生的数据:
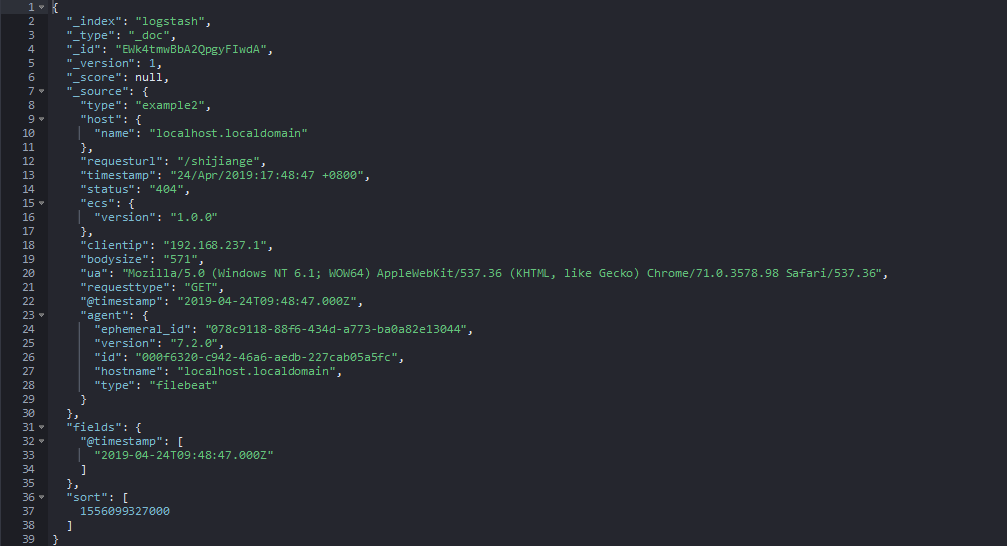
可以看到我们的配置是成功的。
这里我们把两个日志都输出到了同一个索引下,生产中一般都会加以区分的,一般是每个日志对应一个索引,要实现这种效果可以在logstash的配置文件的output中进行如下配置:
output{
if [type] == "example" {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
index => "example-%{+YYYY.MM.dd}"
}
}
else if [type] == "example2" {
elasticsearch {
hosts => ["http://192.168.1.4:9200"]
index => "example2-%{+YYYY.MM.dd}"
}
}
logstash数据处理及格式化功能详解的更多相关文章
- 转载]IOS LBS功能详解[0](获取经纬度)[1](获取当前地理位置文本 )
原文地址:IOS LBS功能详解[0](获取经纬度)[1](获取当前地理位置文本作者:佐佐木小次郎 因为最近项目上要用有关LBS的功能.于是我便做一下预研. 一般说来LBS功能一般分为两块:一块是地理 ...
- 【转】 /etc/fstab功能详解
[转] /etc/fstab功能详解 最近去客户现场时,遇到 了一个关于挂载文件/etc/fstab文件的问题,就写了一下/etc/fstab文件的作用一个文件中各个参数的含义.供大家参考有不正确的地 ...
- Linux命令-自动挂载文件/etc/fstab功能详解
Linux命令-自动挂载文件etcfstab功能详解 一./etc/fstab文件的作用 磁盘被手动挂载之后都必须把挂载信息写入/etc/fstab这个文件中,否则下次开机启动时仍然需要重新挂载. 系 ...
- 【转载】Linux命令-自动挂载文件/etc/fstab功能详解[转]
博客园 首页 新随笔 联系 订阅 管理 随笔 - 322 文章 - 0 评论 - 19 Linux命令-自动挂载文件/etc/fstab功能详解[转] 一./etc/fstab文件的作用 ...
- iOS之UI--使用SWRevealViewController实现侧边菜单功能详解实例
使用SWRevealViewController实现侧边菜单功能详解 下面通过两种方法详解SWRevealViewController实现侧边菜单功能: 1.使用StoryBoard实现 2.纯代 ...
- SVN功能详解
SVN功能详解 TortoiseSVN是windows下其中一个非常优秀的SVN客户端工具.通过使用它,我们可以可视化的管理我们的版本库.不过由于它只是一个客户端,所以它不能对版本库进行权限管理. ...
- UIViewController中各方法调用顺序及功能详解
UIViewController中各方法调用顺序及功能详解 UIViewController中loadView, viewDidLoad, viewWillUnload, viewDidUnload, ...
- MySQL的用户密码过期功能详解
MySQL的用户密码过期功能详解 作者:chszs,未经博主允许不得转载.经许可的转载需注明作者和博客主页:http://blog.csdn.net/chszs 先说明两个术语. Payment Ca ...
- 在ASP.NET 5应用程序中的跨域请求功能详解
在ASP.NET 5应用程序中的跨域请求功能详解 浏览器安全阻止了一个网页中向另外一个域提交请求,这个限制叫做同域策咯(same-origin policy),这组织了一个恶意网站从另外一个网站读取敏 ...
随机推荐
- 【2.0 递归 Recursion 01】
[介绍] Java的一个方法可以调用它自己,Java和所有编程语言都可以支持这种情况,我们把它叫做递归Recursion 递归方法是一种调用自身的方法 那么使用递归方法是是怎么样的呢,让我们看看下面这 ...
- spring-cloud-consul 服务注册发现与配置
下面是 Spring Cloud 支持的服务发现软件以及特性对比(Eureka 已停止更新,取而代之的是 Consul): Feature euerka Consul zookeeper etcd 服 ...
- C#与Python交互方式
前言: 在平时工作中,需求有多种实现方式:根据不同的需求可以采用不同的编程语言来实现.发挥各种语言的强项 如:Python的强项是:数据分析.人工智能等 .NET 开发桌面程序界面比Python更简单 ...
- 消息中间件-ActiveMQ
转播给所有订阅这个topic的使用者 package com.study.mq.b7_transaction; import org.apache.activemq.ActiveMQConnectio ...
- 【笔记】《Redis设计与实现》chapter12 事件
12.1 文件事件 Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为文件时间处理器: 文件时间处理器使用IO多路复用程序来同时监听多个套接字,并根据套接字目前执行的任务来为 ...
- 开源Influxdb2高性能客户端
前言 最近我在了解时序数据库Influxdb 2.x版本,体验一翻之后,感觉官方的出品的.net客户端还有很多优化的地方,于是闭关几天,不吃不喝,将老夫多年练就的高性能网络通讯与高性能Buffer操作 ...
- VUE+Element 前端应用开发框架功能介绍
前面介绍了很多ABP系列的文章<ABP框架使用>,一步一步的把我们日常开发中涉及到的Web API服务构建.登录日志和操作审计日志.字典管理模块.省份城市的信息维护.权限管理模块中的组织机 ...
- 计算机网络-已知IP地址和子网掩码,求广播地址
首先说结论--广播地址=该IP所在的下一跳-1 例题: 已知IP地址是192.72.20.111,子网掩码是255.255.255.224,求广播地址 要知道下一跳就需要先求出网段间隔,网段间隔=25 ...
- 1.4.19- HTML标签之注释标签
有的时候我们输入的代码,让你别人看,别人不知道你的思路,可能就看不懂,或者或一段时间自己就看不懂了,这个时候我们需要对代码进行注释,解释我们的代码什么意思: <!DOCTYPE html> ...
- Android进程的so注入--Poison(稳定注入版)
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/53869796 Android进程的so注入已经是老技术了,网上能用的Android ...