Python代码阅读(第1篇):列表映射后的平均值
本篇阅读的代码实现了将列表进行映射,并求取映射后的平均值。
本篇阅读的代码片段来自于30-seconds-of-python。
average_by
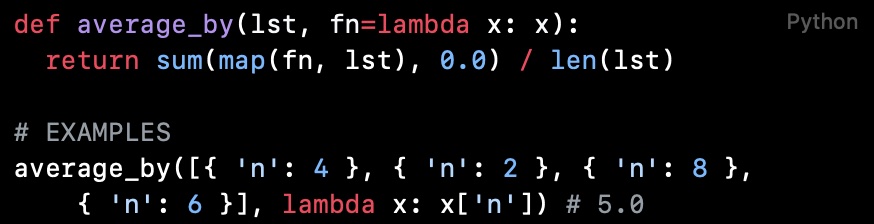
def average_by(lst, fn=lambda x: x):
return sum(map(fn, lst), 0.0) / len(lst)
# EXAMPLES
average_by([{ 'n': 4 }, { 'n': 2 }, { 'n': 8 }, { 'n': 6 }], lambda x: x['n']) # 5.0
该函数用于在列表中求取平均数。该代码片段中主要使用了lambda表达式和map函数。该函数的主要逻辑是使用lambda表达式和map函数提取由待计算的数值组成的迭代器,然后使用sum函数计算列表的和,再除以列表长度。
lambda表达式
形如lambda parameters: expression的表达式可以创建一个匿名函数。在该代码片段中,lambda表达式出现在函数average_by的参数定义中,作为一个参数传给了fn。因此在average_by函数体中fn作为刚刚在参数中定义的函数发挥作用。
函数average_by的默认参数中的lambda表达式是一个直接返回输入参数的函数。在例子中,向average_by传入的匿名函数返回字典中key值为n项的值。
map函数
map函数是Python内置的一个高阶函数,这个函数很有意思,它的参数是一个函数以及一个可迭代对象。它会返回一个迭代器,这个迭代器会将参数中的函数应用在参数中可迭代对象上。
其他类似函数
在30-seconds-of-python中还有一些类似的代码片段。在理解了average_by函数之后,这些都很容理解。
max_by
def max_by(lst, fn):
return max(map(fn, lst))
# EXAMPLES
max_by([{ 'n': 4 }, { 'n': 2 }, { 'n': 8 }, { 'n': 6 }], lambda v : v['n']) # 8
min_by
def min_by(lst, fn):
return min(map(fn, lst))
# EXAMPLES
min_by([{ 'n': 4 }, { 'n': 2 }, { 'n': 8 }, { 'n': 6 }], lambda v : v['n']) # 2
sum_by
def sum_by(lst, fn):
return sum(map(fn, lst))
# EXAMPLES
sum_by([{ 'n': 4 }, { 'n': 2 }, { 'n': 8 }, { 'n': 6 }], lambda v : v['n']) # 20
Python代码阅读(第1篇):列表映射后的平均值的更多相关文章
- Python代码阅读(第8篇):列表元素逻辑判断
Python 代码阅读合集介绍:为什么不推荐Python初学者直接看项目源码 本篇阅读的三份代码的功能分别是判断列表中的元素是否都符合给定的条件:判断列表中是否存在符合给定的条件的元素:以及判断列表中 ...
- Python代码阅读(第11篇):展开嵌套列表
Python 代码阅读合集介绍:为什么不推荐Python初学者直接看项目源码 本篇阅读的代码实现了展开嵌套列表的功能,将一个嵌套的list展开成一个一维list(不改变原有列表的顺序). 本篇阅读的代 ...
- Python代码阅读(第12篇):初始化二维数组
Python 代码阅读合集介绍:为什么不推荐Python初学者直接看项目源码 本篇阅读的代码实现了二维数组的初始化功能,根据给定的宽高初始化二维数组. 本篇阅读的代码片段来自于30-seconds-o ...
- Python代码阅读(第21篇):将变量名称转换为蛇式命名风格
Python 代码阅读合集介绍:为什么不推荐Python初学者直接看项目源码 本篇阅读的代码实现将变量名称转换为蛇式命名风格(snake case)的功能. 本篇阅读的代码片段来自于30-second ...
- Python代码阅读(第10篇):随机打乱列表元素
本篇阅读的代码实现了随机打乱列表元素的功能,将原有列表乱序排列,并返回一个新的列表(不改变原有列表的顺序). 本篇阅读的代码片段来自于30-seconds-of-python. shuffle fro ...
- Python代码阅读(第2篇):数字转化成列表
本篇阅读的代码实现了将输入的数字转化成一个列表,输入数字中的每一位按照从左到右的顺序成为列表中的一项. 本篇阅读的代码片段来自于30-seconds-of-python. digitize def d ...
- SourceInsight支持Python代码阅读
这个话题,很简单,主要是要有一个插件Python.CLF,这个文件可以从我的GitHub上下载.然后,参照下面的图片显示的步骤,就很快搞定! 具体的步骤,看下面的三张图片,顺序编号了,从1到9,对照着 ...
- python基础知识第三篇(列表)
列表 list 类 中提供的方法 li=[1,5,dhud,dd,] 通过list类创建的对象 中括号括起来 逗号分隔每个元素 列表中的元素可以是数字,字符串,也可以是列表,也可以是布尔值 所有的都能 ...
- 【Python代码】随机抽取文件名列表NameList中的Name作为训练集
#!/usr/bin/env python #coding=utf-8 #随机抽取一部分图片作为测试集 import random NameList=[]#存储所有图片名字 ''' NameListP ...
随机推荐
- Leetcode1.两数之和——简洁易懂
> 简洁易懂讲清原理,讲不清你来打我~ 输入一个数组和一个整数,从数组中找到两个元素和为这个整数,输出下标 的序列,每次操作可以将一个数异或上相邻的一个数,求将序列改为严格单调递增序列或严格单调不降序列的操作次 ...
- 【模拟】报名签到 luogu-4445
AC代码 #include <bits/stdc++.h> using namespace std; #define ms(a,b) memset(a,b,sizeof(a)) typed ...
- 规模化敏捷LeSS(二):LeSS*队实践指南
Scrum 能够帮助一个5-9人的小*队以迭代增量的方式开发产品,在每一迭代结束时,交付潜在的可交付的产品增量.正是由于其灵活性,Scrum 方法现已成为*队软件交付方法的首选,近期发布的15届敏捷状 ...
- [考试总结]noip模拟17
爆零了! 菜爆了 弱展了 垃爆了 没有什么可以掩饰你的菜了 这次考试为我带来了第一个 \(\color{red}{ \huge{0}}\) 分,十分欣慰.... 最近的暴力都打不对,你还想什么正解?? ...
- 第七篇--如何改变vs2017版的背景
改变背景 C:\Users\zsunny\AppData\Local\Microsoft\VisualStudio\15.0_9709afbe\Extensions\o0g0c52k.3od\Imag ...
- DNS的原理和解析过程
DNS的解析原理和过程: 在Internet上域名和IP是对应的,DNS解析有两种:一种是正向解析,另外一种是反向解析. 正向解析:正向解析就是将域名转换成对应的 IP地址的过程,它应用于在浏览器地址 ...
- 深入刨析tomcat 之---第8篇 how tomcat works 第11章 11.9应用程序,自定义Filter,及注册
writed by 张艳涛, 标签:全网独一份, 自定义一个Filter 起因:在学习深入刨析tomcat的学习中,第11章,说了调用过滤链的原理,但没有给出实例来,自己经过分析,给出来了一个Filt ...
- K-Fold 交叉验证
转载--原文地址 www.likecs.com 1.K-Fold 交叉验证概念 在机器学习建模过程中,通行的做法通常是将数据分为训练集和测试集.测试集是与训练独立的数据,完全不参与训练,用于最终模型的 ...