遗传算法 TSP(Python代码)
该代码是本人根据B站up主侯昶曦的代码所修改的。
原代码github地址:https://github.com/Houchangxi/heuristic-algorithm/blob/master/TSP问题遗传算法/Genetic Algorithm.py
遗传算法步骤不用讲了,将再多还是不会写代码,倒不如花一上午读懂下面的代码。不仅明白了具体步骤还能写出代码。
#!/usr/bin/env python
# coding: utf-8
# Author:侯昶曦 & 孟庆国
# Date:2020年5月19日 21点16分
# * 本代码中使用的城市坐标需要保存在一个`csv`类型的表中。
# * 下面的代码可以生成随机的指定数量的城市坐标,保存到当前目录的`cities.csv`文件中。
# * 如果需要本地数据,请在`main()`中修改文件路径。
# * 相关参数在`main()`中可以修改。
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import time
# 生成城市坐标
city_num = 10 # 城市数量
name = ["city's name"] * city_num # 这个并没什么用,但是不要省,省了的话还要修改代码
x = [np.random.randint(0, 100) for i in range(city_num)]
y = [np.random.randint(0, 100) for i in range(city_num)]
with open("cities.csv", "w") as f:
for i in range(city_num):
f.write(name[i]+","+str(x[i])+","+str(y[i])+"\n")
f.write(name[0]+","+str(x[0])+","+str(y[0])+"\n") # 最后一个节点即为起点
# 打印城市的坐标
position = pd.read_csv("cities.csv", names=['ind','lat','lon'])
plt.scatter(x=position['lon'], y=position['lat'])
plt.show()
position.head()
def create_init_list(filename):
data = pd.read_csv(filename,names=['index','lat','lon']) # lat->纬度 lon->经度
data_list = []
for i in range(len(data)):
data_list.append([float(data.iloc[i]['lon']),float(data.iloc[i]['lat'])])
return data_list
def distance_matrix(coordinate_list, size): # 生成距离矩阵,邻接矩阵
d = np.zeros((size + 2, size + 2))
for i in range(size + 1):
x1 = coordinate_list[i][0]
y1 = coordinate_list[i][1]
for j in range(size + 1):
if (i == j) or (d[i][j] != 0):
continue
x2 = coordinate_list[j][0]
y2 = coordinate_list[j][1]
distance = np.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)
if (i == 0): # 起点与终点是同一城市
d[i][j] = d[j][i] = d[size + 1][j] = d[j][size + 1] = distance
else:
d[i][j] = d[j][i] = distance
return d
def path_length(d_matrix, path_list, size): # 计算路径长度
length = 0
for i in range(size + 1):
length += d_matrix[path_list[i]][path_list[i + 1]]
return length
def shuffle(my_list):#起点和终点不能打乱
temp_list=my_list[1:-1]
np.random.shuffle(temp_list)
shuffle_list=my_list[:1]+temp_list+my_list[-1:]
return shuffle_list
def product_len_probability(my_list,d_matrix,size,p_num): # population, d, size,p_num
len_list=[] # 种群中每个个体(路径)的路径长度
pro_list=[]
path_len_pro=[]
for path in my_list:
len_list.append(path_length(d_matrix,path,size))
max_len=max(len_list)+1e-10
gen_best_length=min(len_list) # 种群中最优路径的长度
gen_best_length_index=len_list.index(gen_best_length) # 最优个体在种群中的索引
# 使用最长路径减去每个路径的长度,得到每条路径与最长路径的差值,该值越大说明路径越小
mask_list=np.ones(p_num)*max_len-np.array(len_list)
sum_len=np.sum(mask_list) # mask_list列表元素的和
for i in range(p_num):
if(i==0):
pro_list.append(mask_list[i]/sum_len)
elif(i==p_num-1):
pro_list.append(1)
else:
pro_list.append(pro_list[i-1]+mask_list[i]/sum_len)
for i in range(p_num):
# 路径列表 路径长度 概率
path_len_pro.append([my_list[i],len_list[i],pro_list[i]])
# 返回 最优路径 最优路径的长度 每条路径的概率
return my_list[gen_best_length_index],gen_best_length,path_len_pro
def choose_cross(population,p_num): # 随机产生交配者的索引,越优的染色体被选择几率越大
jump=np.random.random() # 随机生成0-1之间的小数
if jump<population[0][2]:
return 0
low=1
high=p_num
mid=int((low+high)/2)
# 二分搜索
# 如果jump在population[mid][2]和population[mid-1][2]之间,那么返回mid
while(low<high):
if jump>population[mid][2]:
low=mid
mid=(low+high) // 2
elif jump<population[mid-1][2]: # 注意这里一定是mid-1
high=mid
mid=(low+high) // 2
else:
return mid
def product_offspring(size, parent_1, parent_2, pm): # 产生后代
son = parent_1.copy()
product_set = np.random.randint(1, size+1)
parent_cross_set=set(parent_2[1:product_set]) # 交叉序列集合
cross_complete=1
for j in range(1,size+1):
if son[j] in parent_cross_set:
son[j]=parent_2[cross_complete]
cross_complete+=1
if cross_complete>product_set:
break
if np.random.random() < pm: #变异
son=veriation(son,size,pm)
return son
def veriation(my_list,size,pm):#变异,随机调换两城市位置
ver_1=np.random.randint(1,size+1)
ver_2=np.random.randint(1,size+1)
while ver_2==ver_1:#直到ver_2与ver_1不同
ver_2 = np.random.randint(1, size+1)
my_list[ver_1],my_list[ver_2]=my_list[ver_2],my_list[ver_1]
return my_list
def main(filepath, p_num, gen, pm):
start = time.time()
coordinate_list=create_init_list(filepath)
size=len(coordinate_list)-2 # 除去了起点和终点
d=distance_matrix(coordinate_list,size) # 各城市之间的邻接矩阵
path_list=list(range(size+2)) # 初始路径
# 随机打乱初始路径以建立初始种群路径
population = [shuffle(path_list) for i in range(p_num)]
# 初始种群population以及它的最优路径和最短长度
gen_best,gen_best_length,population=product_len_probability(population,d,size,p_num)
# 现在的population中每一元素有三项,第一项是路径,第二项是长度,第三项是使用时转盘的概率
son_list = [0] * p_num # 后代列表
best_path=gen_best # 最好路径初始化
best_path_length=gen_best_length # 最好路径长度初始化
every_gen_best=[gen_best_length] # 每一代的最优值
for i in range(gen): #迭代gen代
son_num=0
while son_num < p_num: # 循环产生后代,一组父母亲产生两个后代
father_index = choose_cross(population, p_num) # 获得父母索引
mother_index = choose_cross(population, p_num)
father = population[father_index][0] # 获得父母的染色体
mother = population[mother_index][0]
son_list[son_num] = product_offspring(size, father, mother, pm) # 产生后代加入到后代列表中
son_num += 1
if son_num == p_num:
break
son_list[son_num] = product_offspring(size, mother, father, pm) # 产生后代加入到后代列表中
son_num += 1
# 在新一代个体中找到最优路径和最优值
gen_best, gen_best_length,population = product_len_probability(son_list,d,size,p_num)
if(gen_best_length < best_path_length): # 这一代的最优值比有史以来的最优值更优
best_path=gen_best
best_path_length=gen_best_length
every_gen_best.append(gen_best_length)
end = time.time()
print(f"迭代用时:{(end-start)}s")
print("史上最优路径:", best_path, sep=" ")#史上最优路径
print("史上最短路径长度:", best_path_length, sep=" ")#史上最优路径长度
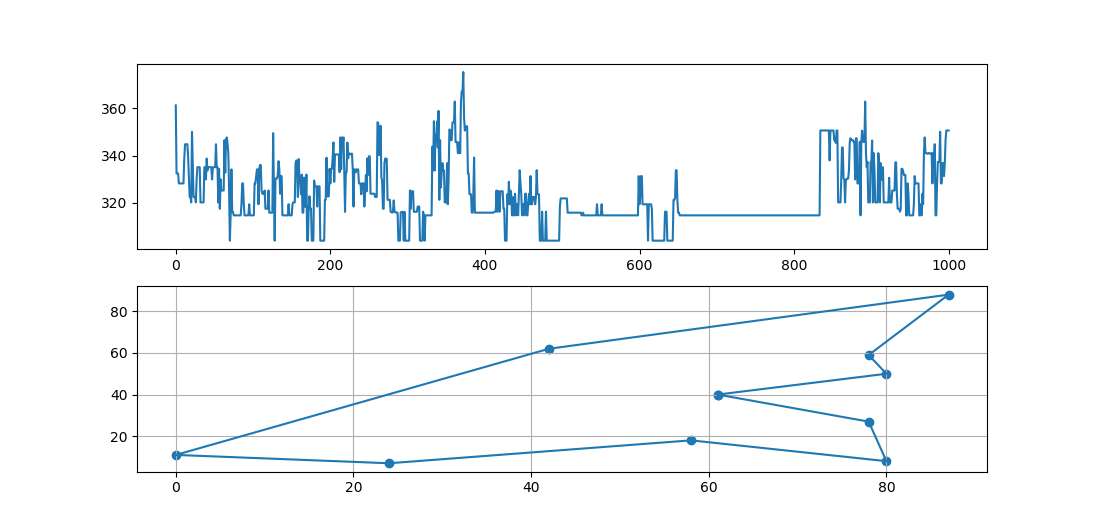
# 打印各代最优值和最优路径
x = [coordinate_list[point][0] for point in best_path] # 最优路径各节点经度
y = [coordinate_list[point][1] for point in best_path] # 最优路径各节点纬度
plt.figure(figsize=(8, 10))
plt.subplot(211)
plt.plot(every_gen_best) # 画每一代中最优路径的路径长度
plt.subplot(212)
plt.scatter(x,y) # 画点
plt.plot(x,y) # 画点之间的连线
plt.grid() # 给画布添加网格
plt.show()
if __name__ == '__main__':
filepath = r'cities.csv' # 城市坐标数据文件
p_num = 200 #种群个体数量
gen = 1000 #进化代数
pm = 0.1 #变异率
main(filepath, p_num, gen, pm)
运行结果:
迭代用时:3.543527126312256s
史上最优路径: [0, 8, 1, 9, 7, 5, 4, 3, 2, 6, 10]
史上最短路径长度: 303.83238696200436
遗传算法 TSP(Python代码)的更多相关文章
- 可爱的豆子——使用Beans思想让Python代码更易维护
title: 可爱的豆子--使用Beans思想让Python代码更易维护 toc: false comments: true date: 2016-06-19 21:43:33 tags: [Pyth ...
- if __name__== "__main__" 的意思(作用)python代码复用
if __name__== "__main__" 的意思(作用)python代码复用 转自:大步's Blog http://www.dabu.info/if-__-name__ ...
- Python 代码风格
1 原则 在开始讨论Python社区所采用的具体标准或是由其他人推荐的建议之前,考虑一些总体原则非常重要. 请记住可读性标准的目标是提升可读性.这些规则存在的目的就是为了帮助人读写代码,而不是相反. ...
- 一行python代码实现树结构
树结构是一种抽象数据类型,在计算机科学领域有着非常广泛的应用.一颗树可以简单的表示为根, 左子树, 右子树. 而左子树和右子树又可以有自己的子树.这似乎是一种比较复杂的数据结构,那么真的能像我们在标题 ...
- [Dynamic Language] 用Sphinx自动生成python代码注释文档
用Sphinx自动生成python代码注释文档 pip install -U sphinx 安装好了之后,对Python代码的文档,一般使用sphinx-apidoc来自动生成:查看帮助mac-abe ...
- 上传自己的Python代码到PyPI
一.需要准备的事情 1.当然是自己的Python代码包了: 2.注册PyPI的一个账号. 二.详细介绍 1.代码包的结构: application \application __init__.py m ...
- 如何在batch脚本中嵌入python代码
老板叫我帮他测一个命令在windows下消耗的时间,因为没有装windows那个啥工具包,没有timeit那个命令,于是想自己写一个,原理很简单: REM timeit.bat echo %TIME% ...
- ROS系统python代码测试之rostest
ROS系统中提供了测试框架,可以实现python/c++代码的单元测试,python和C++通过不同的方式实现, 之后的两篇文档分别详细介绍各自的实现步骤,以及测试结果和覆盖率的获取. ROS系统中p ...
- 让计算机崩溃的python代码,求共同分析
在现在的异常机制处理的比较完善的编码系统里面,让计算机完全崩溃无法操作的代码还是不多的.今天就无意运行到这段python代码,运行完,计算机直接崩溃,任务管理器都无法调用,任何键都用不了,只能强行电源 ...
随机推荐
- 27、Tomcat服务的安装与配置
服务器名称 ip地址 slave-node1 172.16.1.91 27.1. Tomcat简介: Tomcat是Apache软件基金会(Apache Software Foundation)的Ja ...
- ansible 常用命令
ansible 命令集 #Ansibe AD-Hoc 临时命令执行工具,常用于临时命令的执行 /usr/bin/ansible #Ansible 模块功能查看工具 /usr/bin/ansible-d ...
- shiro框架基础
一.shiro框架简介 Apache Shiro是Java的一个安全框架.其内部架构如下: 下面来介绍下里面的几个重要类: Subject:主体,应用代码直接交互的对象就是Subject.代表了当前用 ...
- 可执行jar包在windows server2008下的自启动
最近要部署项目的服务端在windows server2008下面,所以把项目打包成可执行的jar包,然后希望它能开机自启动,毕竟每次都在cmd下输入java -jar xxx.jar才能启动太繁琐了. ...
- 因为它,我差点删库跑路:js防抖与节流
前言 前端踩雷:短时间内重复提交导致数据重复. 对于前端大佬来说,防抖和节流的技术应用都是基本操作.对于"兼职"前端开发的来说,这些都是需要躺平的坑. 我们今天就来盘一盘js防抖与 ...
- TCP/IP 5层协议簇/协议栈
TCP/IP 5层协议簇/协议栈 数据/PDU 应用层 PC.防火墙 数据段/段Fragment 传输层 防火墙 报文/包/IP包packet 网络层 路由器 帧Frame 数据链路层 交换机.网卡 ...
- YAOI Round #1 题解
前言 比赛网址:http://47.110.12.131:9016/contest/3 总体来说,这次比赛是有一定区分度的, \(\text{ACM}\) 赛制也挺有意思的. 题解 A. 云之彼端,约 ...
- c++中的继承关系
1 什么是继承 面向对象的继承关系指类之间的父子关系.用类图表示如下: 2 为什么要有继承?/ 继承的意义? 因为继承是面向对象中代码复用的一种手段.通过继承,可以获取父类的所有功能,也可以在子类中重 ...
- AI 预测蛋白质结构「GitHub 热点速览 v.21.29」
作者:HelloGitHub-小鱼干 虽然 AI 领域藏龙卧虎,但是本周预测蛋白质结构的 alphafold 一开源出来就刷爆了朋友圈,虽然项目与我无关,但是看着科技进步能探寻到生命机理,吃瓜群众也有 ...
- ES6 对象定义简写及常用的扩展方法
1.ES6 对象定义简写 es6提供了对象定义里的属性,方法简写方式: 假如属性和变量名一样,可以省略,包括定义对象方法function也可以省略 <script type="text ...