浅读tomcat架构设计之tomcat容器Container(3)
浅读tomcat架构设计和tomcat启动过程(1)
https://www.cnblogs.com/piaomiaohongchen/p/14977272.html
浅读tomcat架构设计之tomcat生命周期(2)
https://www.cnblogs.com/piaomiaohongchen/p/14982770.html
Container是tomcat容器的接口,接口位置org.apache.catalina.Container
Container一共有4个子接口,分别是:Engine,Host,Context,Wrapper和一个默认实现类ContainerBase:
截图看下就会清晰很多:
不知道为啥,截图后画质那么的马赛克... 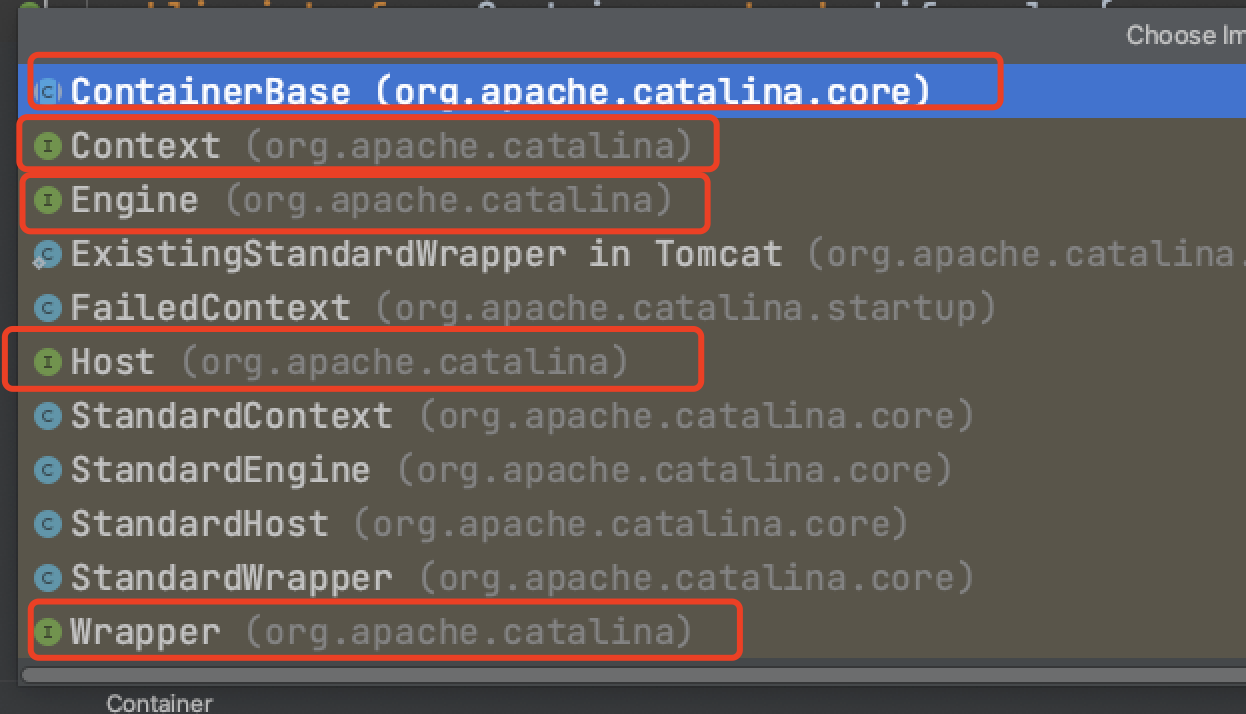
每个子接口都是一个容器,这四个子容器都有一个对应的Standard***实现类:

红线标出来的Standard***对应的是具体子容器的的实现类,并且这些子容器实现类都继承自ContainerBase类,以其中一个子容器实现类为例:

而ContainerBase又继承自LifecycleMBeanBase

所以四个子容器都是tomcat生命周期管理模式,看完子容器和子容器的接口实现类后,给我的感觉就是无限套娃
下面讲讲四个子容器的作用含义,它们和我们的tomcat部署项目/发布项目息息相关,具有很强的关联性
Engine:引擎,用于管理多个站点,一个Service最多只能有一个Engine
Host:代表一个站点,也可以叫虚拟主机,通过配置host就可以添加站点 www.xxx.com就是Host,代表我们的站点,oa.xxx.com是我们的另外一个Host,他指向了另一个站点
Context:代表一个应用程序,对应着我们开发的系统,或者是WEB-INF目录及下面的web.xml文件,通俗易懂点来说www.xxx.com/xxx,xxx应用就是Context
Wrapper:每个Wrapper封装着一个Servlet 其实就是web.xml中配置的Servlet
4种容器的配置方法:
Engine和Host的配置都在tomcat conf/server.xml中,server.xml是tomcat最重要的配置文件,tomcat大部分功能都可以在这个文件中配置
<Engine name="Catalina" defaultHost="localhost">
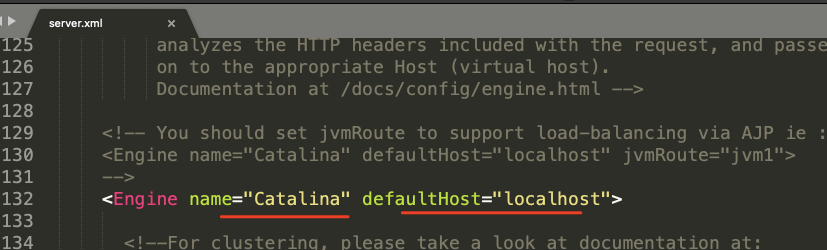
我安装tomcat,默认Engine的设置是Catalina,默认的Host站点使用是localhost,这里可以自己设置成别的Host站点.
Context有三种配置方法 (1)通过文件配置 (2)war包上传放到Host目录下,tomcat会自动查找自解压 (3)将应用的文件夹放在Host目录下,tomcat会自动查找并添加到Host中
tocmat部署不想长篇大论讲了, tomcat部署参考:https://www.cnblogs.com/ysocean/p/6893446.html ,里面讲了好几种方法.
Wrapper的配置就是我们web.xml中配置的Servlet,一个Servlet对应一个Wrapper.
Container的启动是通过init和start方法来完成的,Container的四个子容器的共同父类都是ConatinerBase,ConatinerBase类定义了两个方法,分别是:startInternal和initInternal
先聊聊ContainerBase类的这两个方法的具体实现:
org.apache.catalina.core.ContainerBase:
protected void initInternal() throws LifecycleException {
BlockingQueue<Runnable> startStopQueue = new LinkedBlockingQueue();
this.startStopExecutor = new ThreadPoolExecutor(this.getStartStopThreadsInternal(), this.getStartStopThreadsInternal(), 10L, TimeUnit.SECONDS, startStopQueue, new ContainerBase.StartStopThreadFactory(this.getName() + "-startStop-"));
this.startStopExecutor.allowCoreThreadTimeOut(true);
super.initInternal();
}
initInternal方法主要是先是初始化,创建对象,然后创建一个线程池来管理启动和关闭内部线程
ThreadPoolExecutor继承自Executor用于管理线程,一直往上回溯,会发现是Executor

接着看startInternal方法:
protected synchronized void startInternal() throws LifecycleException {
this.logger = null;
this.getLogger();
Cluster cluster = this.getClusterInternal();
if (cluster != null && cluster instanceof Lifecycle) {
((Lifecycle)cluster).start();
}
Realm realm = this.getRealmInternal();
if (realm != null && realm instanceof Lifecycle) {
((Lifecycle)realm).start();
}
Container[] children = this.findChildren();
List<Future<Void>> results = new ArrayList();
for(int i = 0; i < children.length; ++i) {
results.add(this.startStopExecutor.submit(new ContainerBase.StartChild(children[i])));
}
boolean fail = false;
Iterator i$ = results.iterator();
while(i$.hasNext()) {
Future result = (Future)i$.next();
try {
result.get();
} catch (Exception var9) {
log.error(sm.getString("containerBase.threadedStartFailed"), var9);
fail = true;
}
}
if (fail) {
throw new LifecycleException(sm.getString("containerBase.threadedStartFailed"));
} else {
if (this.pipeline instanceof Lifecycle) {
((Lifecycle)this.pipeline).start();
}
this.setState(LifecycleState.STARTING);
this.threadStart();
}
}
startInternal方法很长,拆分下代码讲解:
Cluster cluster = this.getClusterInternal();
if (cluster != null && cluster instanceof Lifecycle) {
((Lifecycle)cluster).start();
} Realm realm = this.getRealmInternal();
if (realm != null && realm instanceof Lifecycle) {
((Lifecycle)realm).start();
}
如果cluster和realm不为null,并且cluster/realm引用指向LIfecycle,就调用start方法
继续往下拆分看:
Container[] children = this.findChildren();
List<Future<Void>> results = new ArrayList(); for(int i = 0; i < children.length; ++i) {
results.add(this.startStopExecutor.submit(new ContainerBase.StartChild(children[i])));
}
这部分代码是调用所有子容器的start方法来启动子容器,跟进ContainerBase.StartChild函数看看:
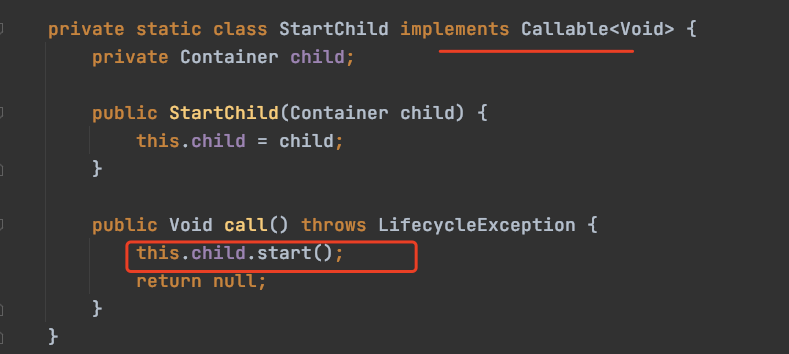
继续往下拆分代码:
if (fail) {
throw new LifecycleException(sm.getString("containerBase.threadedStartFailed"));
} else {
if (this.pipeline instanceof Lifecycle) {
((Lifecycle)this.pipeline).start();
}
this.setState(LifecycleState.STARTING);
this.threadStart();
}
这段代码大致就是调用管道中start方法,启动完成后将生命周期设置成LifecycleState.STARTING,最后启动后台线程:

Engine:
前面我们讲了,四大子容器的实现类是Standard***类.那么Engine的默认实现类是StandardEngine类:
org.apache.catalina.core.StandardEngine:
如果使用Engine就会调用Engine默认实现类StandardEngine的initInternal和startInternal方法:
我们来看看:
protected void initInternal() throws LifecycleException {
this.getRealm();
super.initInternal();
}
protected synchronized void startInternal() throws LifecycleException {
if (log.isInfoEnabled()) {
log.info("Starting Servlet Engine: " + ServerInfo.getServerInfo());
}
super.startInternal();
}
代码不是很多,发现他是调用他父类的方法,他的父类是ContainerBase,我们一开始就分析过ContainerBase类的initInternal和startInternal方法了.
Host:
Host接口的默认实现类是org.apache.catalina.core.StandardHost:
跟进类,发现StandardHost没有重写父类的initInternal,只有startInternal方法被重写:
如果他没有,初始化会默认会调用它父类的initInternal
startInternal方法代码如下:
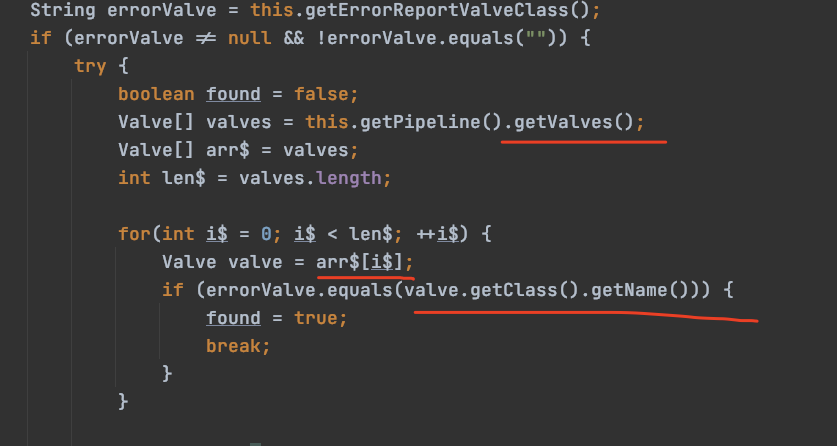
protected synchronized void startInternal() throws LifecycleException {
String errorValve = this.getErrorReportValveClass();
if (errorValve != null && !errorValve.equals("")) {
try {
boolean found = false;
Valve[] valves = this.getPipeline().getValves();
Valve[] arr$ = valves;
int len$ = valves.length;
for(int i$ = 0; i$ < len$; ++i$) {
Valve valve = arr$[i$];
if (errorValve.equals(valve.getClass().getName())) {
found = true;
break;
}
}
if (!found) {
Valve valve = (Valve)Class.forName(errorValve).newInstance();
this.getPipeline().addValve(valve);
}
} catch (Throwable var8) {
ExceptionUtils.handleThrowable(var8);
log.error(sm.getString("standardHost.invalidErrorReportValveClass", new Object[]{errorValve}), var8);
}
}
super.startInternal();
}
代码也是好多一大块.
拆开一部分:
截图的是重点,主要做的就是获取管道的值,然后判断管理里面是否有指定的Valve
如果没找到管道值,就调用addValve方法,加入到管道中,代码如下:
if (!found) {
Valve valve = (Valve)Class.forName(errorValve).newInstance();
this.getPipeline().addValve(valve);
}
这是个重点,对我们后续讲解tomcat 内存马提供很大的帮助,valve的内存马注入是一定要调用addValue的,否则匹配不到!
Host的启动除了调用StandardHost的startInternal方法,还会调用HostConfig中的一些方法:
对应位置:org.apache.catalina.startup.HostConfig
这个类主要作用就是Host站点的配置
比较重要的就是部署应用了,deployApps方法,代码如下
protected void deployApps() {
File appBase = this.host.getAppBaseFile();
File configBase = this.host.getConfigBaseFile();
String[] filteredAppPaths = this.filterAppPaths(appBase.list());
this.deployDescriptors(configBase, configBase.list());
this.deployWARs(appBase, filteredAppPaths);
this.deployDirectories(appBase, filteredAppPaths);
}
上面介绍了三种方法来部署tomcat项目,
(1)通过xml:
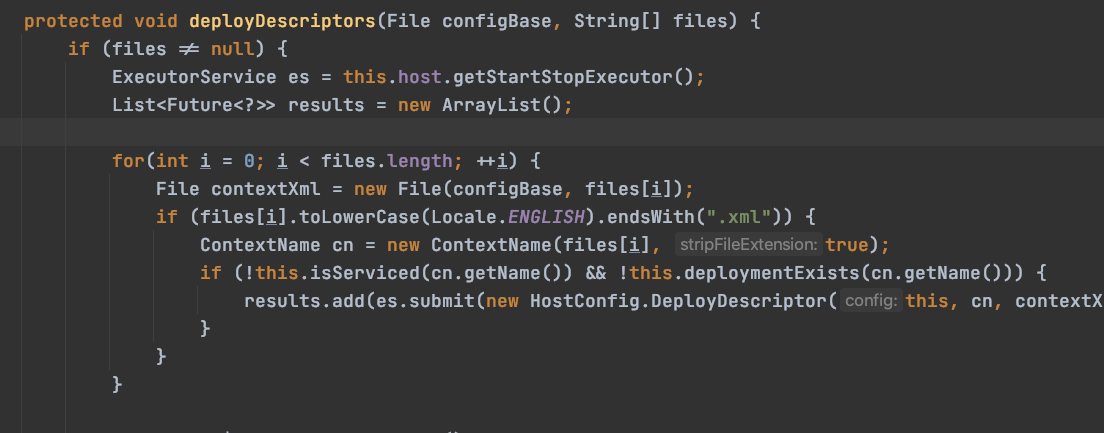
(2):war包部署
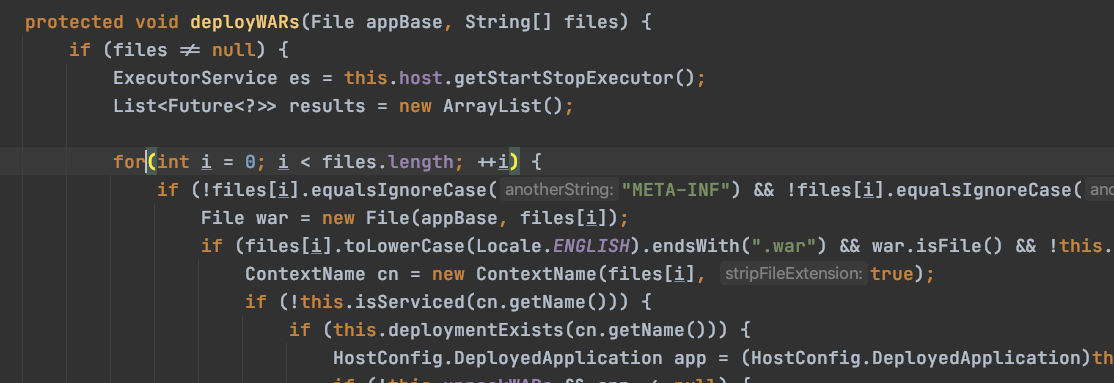
(3)文件夹部署:
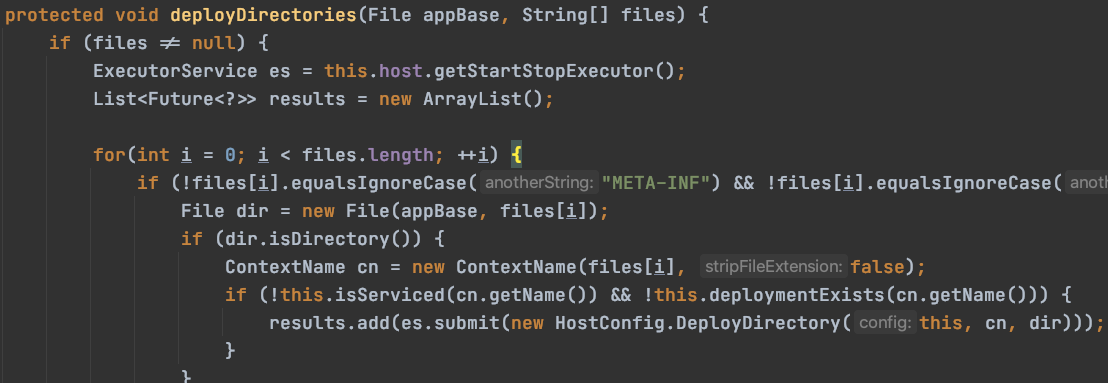
Context:
Context的默认实现类是org.apache.catalina.core.StandardContext:
startInternal方法如下:
拆取比较重要部分,方法内容实在是太多了:
if (ok && !this.listenerStart()) {
log.error("Error listenerStart");
ok = false;
}
if (ok) {
this.checkConstraintsForUncoveredMethods(this.findConstraints());
}
try {
Manager manager = this.getManager();
if (manager != null && manager instanceof Lifecycle) {
((Lifecycle)manager).start();
}
} catch (Exception var19) {
log.error("Error manager.start()", var19);
ok = false;
}
if (ok && !this.filterStart()) {
log.error("Error filterStart");
ok = false;
}
if (ok && !this.loadOnStartup(this.findChildren())) {
log.error("Error loadOnStartup");
ok = false;
}
主要含义就是调用了web.xml中定义的Listener,另外还初始化了filterStart和loadOnStartup
filterStart:org.apache.catalina.core.StandardContext:
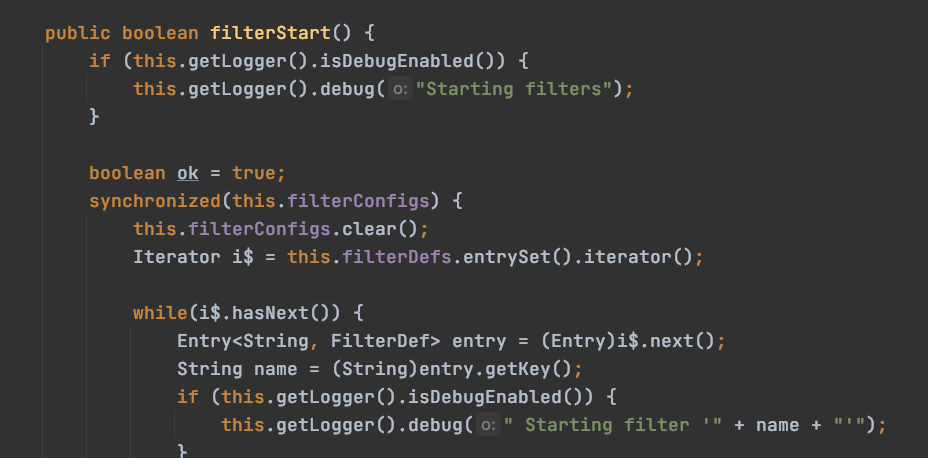
使用filterConfigs存储键值对,前面简单看了hostConfig,filterConfig同理:
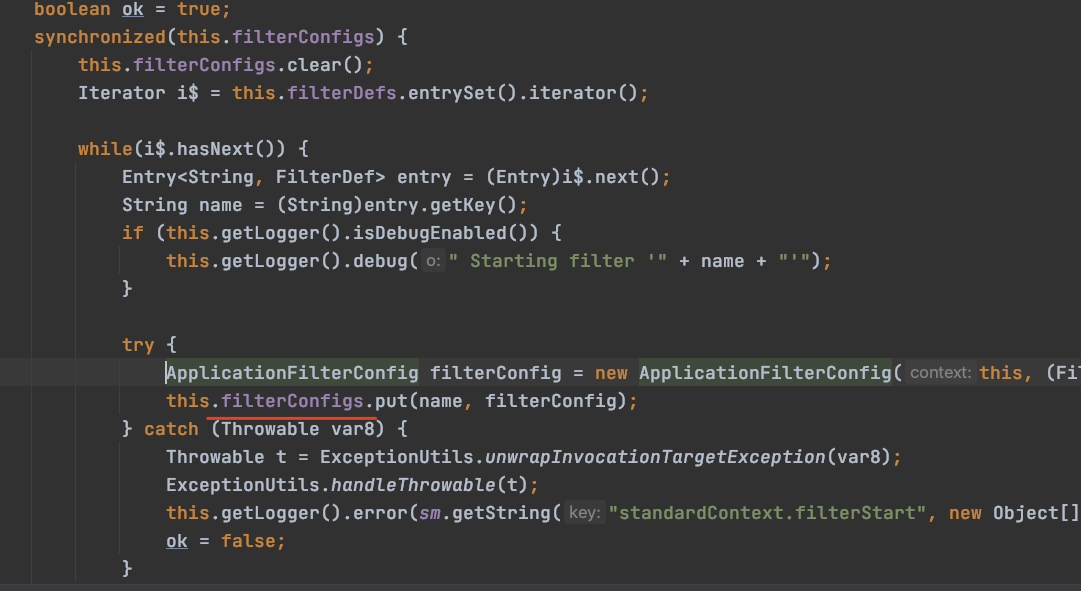
他的实例类是:org.apache.catalina.core.ApplicationFilterConfig,等我讲Filter内存马的时候再详细解释它,这个先放一边.
Wrapper:
Wrapper是封装Servlet的包装器,Wrapper的默认实现类,没有重写initInternal,他默认调用父类的initInternal方法,startInternal方法代码如下:
org.apache.catalina.core.StandardWrapper:
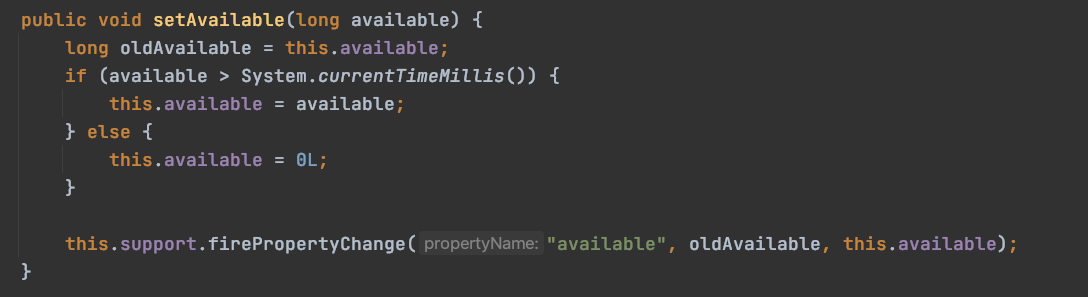
protected synchronized void startInternal() throws LifecycleException {
Notification notification;
if (this.getObjectName() != null) {
notification = new Notification("j2ee.state.starting", this.getObjectName(), (long)(this.sequenceNumber++));
this.broadcaster.sendNotification(notification);
}
super.startInternal();
this.setAvailable(0L);
if (this.getObjectName() != null) {
notification = new Notification("j2ee.state.running", this.getObjectName(), (long)(this.sequenceNumber++));
this.broadcaster.sendNotification(notification);
}
}
代码很简单,(1)使用broadcaster发送消息 (2)调用父类的startInternal (3)调用setAvailate方法,设置Servlet的有效时间
浅读tomcat架构设计之tomcat容器Container(3)的更多相关文章
- 浅读tomcat架构设计之tomcat生命周期(2)
浅读tomcat架构设计和tomcat启动过程(1) https://www.cnblogs.com/piaomiaohongchen/p/14977272.html tomcat通过org.apac ...
- 浅读tomcat架构设计和tomcat启动过程(1)
一图甚千言,这张图真的是耽搁我太多时间了: 下面的tomcat架构设计代码分析,和这张图息息相关. 使用maven搭建本次的环境,贴出pom.xml完整内容: <?xml version=&qu ...
- Tomcat详解系列(2) - 理解Tomcat架构设计
Tomcat - 理解Tomcat架构设计 前文我们已经介绍了一个简单的Servlet容器是如何设计出来,我们就可以开始正式学习Tomcat了,在学习开始,我们有必要站在高点去看看Tomcat的架构设 ...
- Tomcat架构解析(一)-----Tomcat总体架构
Tomcat是非常常用的应用服务器,了解Tomcat的总体架构以及实现细节,对于理解整个java web也是有非常大的帮助. 一.Server 1.最简单的服务器结构 最简单的服务器结构如图所示: ...
- Tomcat架构解析(五)-----Tomcat的类加载机制
类加载器就是根据类的全限定名(例如com.ty.xxx.xxx)来获取此类的二进制字节流的代码模块,从而程序可以自己去获取到相关的类. 一.java中的类加载器 1.类加载器类别 java中的类加 ...
- 浅读tomcat架构设计之Pipeline-Valve管道(4)
tomcat Container容器处理请求是使用Pipeline-Valve管道来处理的,后续写的tomcat内存马,和他紧密结合 Pipeline-Valve是责任链模式,责任链模式是指在一个请求 ...
- Tomcat 架构原理解析到架构设计借鉴
Tomcat 发展这么多年,已经比较成熟稳定.在如今『追新求快』的时代,Tomcat 作为 Java Web 开发必备的工具似乎变成了『熟悉的陌生人』,难道说如今就没有必要深入学习它了么?学习它我们又 ...
- 理解Tomcat架构、启动流程及其性能优化
PS:but, it's bullshit ! 备注:实话说,从文档上扒拉的,文档地址:在每一个Tomcat安装目录下,会有一个webapps文件夹,里面有一个docs文件夹,点击index.html ...
- tomcat架构分析-索引
出处:http://gearever.iteye.com tomcat架构分析 (概览) tomcat架构分析 (容器类) tomcat架构分析 (valve机制) tomcat架构分析 (valve ...
随机推荐
- Linux基本原则
Bash特性 Shell shell(外壳),广义的shell可以理解为是用户的工作环境,在windows看来桌面就是一个shell,在linux看来终端就是shell 常见的shell有两种,一种是 ...
- BogoMips 和cpu主频无关 不等于cpu频率
http://tinylab.org/explore-linux-bogomips/ 内核探索:Linux BogoMips 探秘 Tao HongLiang 创作于 2015/05/12 打赏 By ...
- Ansible_利用系统角色重用内容
一.红帽企业Linux系统角色 1.RHEL系统角色 名称 状态 角色描述 rhel-system-roles.kdump 全面支持 配置kdump崩溃恢复服务 rhel-system-roles.n ...
- OS_FLAG_GRP_DEPLETED
178 * OS_FLAG_GRP_DEPLETED 系统没有剩余的空闲事件标志组,需要更改OS_CFG.H中 179 * 的事件标志组数目配置创建 标志组的时候返回这个错误 打印出错误代码后发现是1 ...
- 彻底弄懂HTTP缓存机制及原理【转载】
前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个基础环节,同时对于有志成为前端架构师的同学来说是必备的知识技能.但是对于很多前端同 ...
- 一次线上事故,让我对MySql的时间戳存char(10)还是int(10)有了全新的认识
美好的周五 周五的早晨,一切都是那么美好. 然鹅,10点多的时候,运营小哥哥突然告诉我后台打不开了,我怀着一颗"有什么大不了的,估计又是(S)(B)不会连wifi"的心情,自信的打 ...
- [leetcode] 117. 填充同一层的兄弟节点 II
117. 填充同一层的兄弟节点 II 与116. 填充同一层的兄弟节点完全一样,二叉树的层次遍历..这是这次不是完美二叉树了 class Solution { public void connect( ...
- Python单元测试简介及Django中的单元测试
Python单元测试简介及Django中的单元测试 单元测试负责对最小的软件设计单元(模块)进行验证,unittest是Python自带的单元测试框架. 单元测试与功能测试都是日常开发中必不可少的部分 ...
- pytest - 失败重运行机制:rerun
失败重运行机制 用例失败的情况下,可以重新运行用例 一旦用例失败,马上重新运行 安装插件:pip install pytest-rerunfailures 使用命令:--reruns 重试次数 如 - ...
- camera中LENS和SENSOR的CRA是如何搭配的?
camera中LENS和SENSOR的CRA是如何搭配的? camera中,lens和sensor的搭配是非常关键的问题.但这两者是如何搭配的呢? 一般在Sensor data sheet中会附有全视 ...